원문 : https://arxiv.org/abs/1409.1556
Very Deep Convolutional Networks for Large-Scale Image Recognition 논문을 리뷰해보겠다.
앞서 나는 무언가를 잘 안다면 아무것도 모르는 초등학생에게도 설명이 가능할 수 있어야 잘 안다고 말할 수 있다고 생각한다. 그러니 정말정말 쉽게 풀어보려고 한다. 너무 겁먹지 말고 잘 읽어보길 바란다.
그리고 틀린점이 충분히 있을 수 있다. 발견하신다면 여지없이 댓글달고 혼내주세요. 많이 배우겠습니다.
왜 이 논문이 중요한가?
이 논문이 중요한 점은 Alexnet이 나온이후 CNN에 대한 관심은 증가하였으나, layer depth(레이어의 층 갯수)는 고작 8개에 지나지 않았다. 그러나 이 논문에서 층을 깊게(19,22 층) 쌓으면서도 효과는 더욱 좋아졌음을 발표했다.
- layer(층)을 더욱 깊게 쌓아서 정확도를 높혔다.
- layer(층)을 깊게 쌓으면서도 vanishing/exploding 문제를 해결할 수 있는 방법을 소개했다.
본격적으로 시작하기 전, 영어가 너무 어려우면 한글 설명만 읽자.
물론 영어에 익숙해지는 것이 가장 좋지만, 영어때문에 논문읽기를 포기하는것보다는 훨씬 나은 결과를 얻을 것이라고 생각한다.
따라서 영어가 어려운 사람들을 위해 옆에 괄호로 최대한 한글 설명을 적어보겠다.
모두 한글로 번역해서 적지 않는 이유는 영어가 익숙하지 않은 사람들에게 최대한 영어를 익숙하게 하기 위함이다.
또한 용어를 잘 모르겠는 사람를 생각하여, 필요한 용어를 정리하겠다. 모르겠다면 중간중간 가장 아래의 단어설명을 가서 보자.
논문 리뷰 시작
1. Abstart(요약)

이 논문의 연구자들은 대규모 이미지 처리에 있어 convolutinal network depth(컨볼루션 네트워크의 깊이)가 정확도에 미치는 영향을 조사했다.
Main contribution(주요한 기여점)
- 3x3 convolution filters를 16-19개 정도로 deep 하게 쌓아서 정확도를 높혔다는 것!
2. Introduction(논문 초록)

연구자들은 depth(깊이)에 특히 신경을 썼고,convolutional layers(모든 층에 3x3, 왜인지는 밑에 나온다!)를 쌓으며 깊이를 늘려갔다.
2-1. Configuration(구성)

input은 모두 224x224 RGB로 구성하였고, 전처리 작업은 mean RGB(RGB의 평균)을 빼주었다.
-3x3 convolutional layers(픽셀들의 위,아래, 오른쪽, 왼쪽을 알기위한 최소의 사이즈)
-1x1 convolutional layers(입력 채널 조정)
-maxpooling 은 2x2으로 5개의 층, conv layer 뒤에 시행되었음!

FC(Fully-Connected) layers 는 총 3개로 구성됨.
1번, 2번 FC layer = 4096개의 채널
3번 FC layer = 1000개의 채널
그리고 마지막은 sotfmax layer로 마무리(classification을 위함)
모든 각각의 hidden layers는 모두 ReLU를 사용하였다.
(역시나 모두 ReLU 앞에서는 평등하다. 잘 모르겠다면 ReLU를 사용해주자.)
그리고 AlexNet에 나온 LRN이라는 기법이 있어서 사용해봤는데 별로여서 사용하지 않았다고 한다.
2-2. 각각의 CONFIGURATIONS

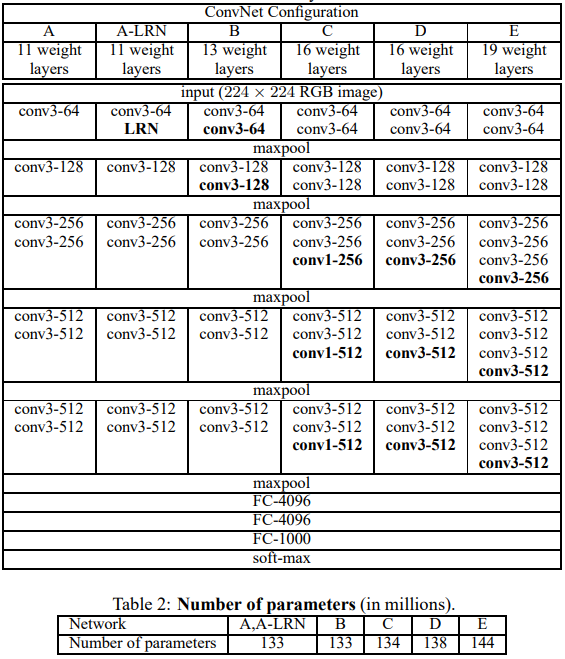
총 6개의 그룹을 만들었다고 한다.
- A(11개의 층)
- A-LRN(11개의 층 +LRN적용)
- B(13개의 층)
- C(16개의 층, 중간에 conv 1x1을 섞음)
- D(16개의 층)
- E(19개의 층)
여기서 아까 말한 3x3을 쓴 이유가 나온다.
층을 많이 쌓았음에도 불구하고 얕은 층 + 넓은 conv 보다 더 파라미터 수가 적어져서, 연산량이 감소했다고 나와있음!
잠시만요!!! 3x3 x (여러번) = 5x5, 7x7, ...인데 왜why? 3x3을 굳이 사용하는가?


3x3을 여러번하면서 중간중간 ReLU를 더 많이 거치게 되기 때문에 복잡한 구조를 더 잘 풀 수 있게 한다. 이를 non-linear 해진다고 말한다.
또한 parameter 개수도 줄이면서 overfitting을 막아주는 경향이 있다.
여기에 1x1 convolution layer 까지 활용하며 더욱 non linear해진다.(1x1 conv 에 대한 설명은 단어집에 적어놓겠다)
3. CLASSIFICATION FRAMEWORK
3-1. TRAINING

Hyper parameter 설정이다.
- cost function : Multinomial logistic regression objective(Cross Entropy)
- mini batch : 256
- optimizer : momentum(0.9)
- Regularization : L2(5.10^-4), Dropout(0.5)
- Learning rate : 10^-2(validation error가 낮아질수록 10^-1씩 감소)
이렇게 하여 AlexNet 보다 더 깊고, parameter 도 더 많지만 더 빨리 훈련을 종료시킬 수 있었다(epoch이 더 적게 종료)
그 이유로,
1. 3x3을 써서 parameter를 줄인것.
2. pre-intialization : 모델 학습 시, 전 모델의 학습된 layer를 통해 초깃값을 설정하는 것
을 뽑았다.
트레이닝 이미지 사이즈는 224x224로 고정되어 있다.
그러나 이 논문에서는 이를 256~512으로 rescaled하여 horizental filp, random RGB colour shift 한 후 무작위로 crop하는 방법을 소개하고 있다.
왜why?
1. training data를 augmentation 할 수 있다.
2. 한 객체(예를 들어 사슴, 고릴라 등등)에 대해서 다양한 부분을 학습할 수 있다.(ex 사슴의 눈, 머리, 몸, 다리 등)

S = train 시 트레이닝 이미지 스케일러
만약 이미지의 가로,세로 중 224보다 적은 값이 있다면, 적은 값을 원본 사이즈를 유지하며 224로 늘려준다.
예를 들어서 100 x 200 이라면, 224 x 448로 늘려준다는 이야기다.(이를 isotropically-rescaled 이라고 함)
근데 그럼 남는 부분은 어떡하냐?
랜덤으로 crop하여(잘라서) 사용한다.

그래서 S의 크기를 무엇으로 설정했느냐? 이 논문에서는 2가지로 설정했다고 한다.
1. 256 아니면 384((256+512)/2인 값)로 고정!(Single-scale training)
-처음에는 256으로 하다가 학습이 좀 진행되고 384로 진행하여 학습시간을 줄인다.
2. 256 ~ 512로 랜덤하게 설정!(Multi-scale training)
-애초에 이미지 자체가 크기가 랜덤하기에 Multi-scale training이 더 효과적이고, 속도를 높히기 위해 S = 384로 pre-trained 시켜 fine-tuning 한다.
3-2. TESTING

training scale = S 라면, testing scale이 따로 필요할 것이다. 이를 Q라고 지정한다.
여기서, S와 Q가 꼭 같을 필요는 없다.
그래서 S에 대해서 다양한 값의 Q를 적용한다.
앞에서 FC layer는 총 3가지였다. 허나 이미지 전체 크기(uncropped)에 대해서 다르게 적용한다.
- 1,2번째 : 4096 , 3번째 : 1000
에서
- 1번쨰 -> 7x7 conv layer, 2,3번째 1x1conv layer
로 수정한다.
왜 why?
위 처럼 layer을 바꿔주면, 어떤 input size가 들어오더라도 신경망을 통과할 수 있으며, 다양한 사이즈로 image를 rescale해서 사용할 수 있기 때문이다.(이러면 해당 이미지에 대해서 더욱 다양한 부분을 학습할 수 있다)
아니 그러면 input size에 따라서 output size가 달라지는것 아닌가요?
맞다. 신경망을 지나고 나면 class score map 을 뽑아내게 되는데 이는 1개의 값이 아닐수도 있다. 따라서 spatially averaged(sum-pooled)을 적용시킨다.
3-3. IMPLEMENTATION DETAILS

Mutil GPU training 방식으로 여러 GPU batch들로 병렬 처리하였다.
이때 Gradient 계산시, GPU 전체에 걸쳐 동시에 진행되었다고 한다. 이는 GPU 1개를 돌릴때와 같은 결과를 얻게 한다.
결과 : GPU 1개로 돌림 -> GPU 4개로 돌림 : 속도 3.75배 향상!
4. CLASSIFICATION EXPERIMENTS


데이터는 ILSVRC-2012 dataset을 사용하였으며, class(종류 or 분류)는 1000개이고,
-training (1.3M images)
-validation (50K images)
-testing (100K images with held-out class labels)
으로 나누었다고 한다.
error는
- top-1 error(고릴라라고 판단했는데 고릴라가 아닌것)
- top-5 error(softmax를 통과하기 때문에 class별로 확률로 나타나게 됨. ex) 사슴 :50%, 고릴라 : 20%, 인간 : 10% 등등... 그런데 여기서 가장 높게 판단한 상위 5개의 항목중에 정답이 없는 경우를 top-5 error 라고 함.)
4-1. SINGLE SCALE EVALUATION

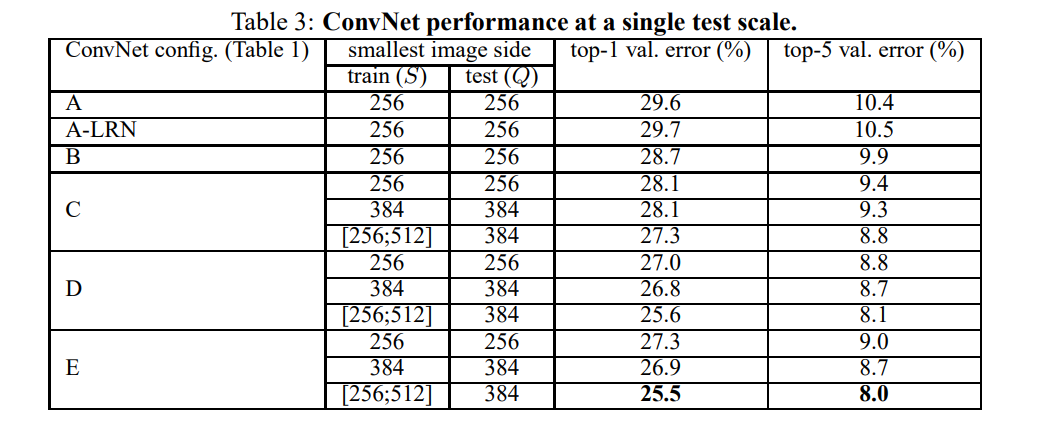
첫번째, A 그룹에서 LRN 기법을 적용했을때 결과가 좋지 않아서 더 깊은 층들인 B,C,D,E에서는 LRN기법을 적용하지 않았다고 한다.
두번째로, A -> E 로 갈수록, 즉 신경망이 깊어지면 깊어질수록 error가 낮아졌다고 한다.
여기서 C(중간에 1x1 conv를 적용한 그룹)와 D(모두 3x3 conv를 적용한 그룹)을 비교한 것이 인상적이다.
C보다 D가 더 정확했는데, 이유는 D가 3x3 conv를 한번더 적용하면서 spatial 한 정보를 더 많이 학습했다는 것이 연구자들의 설명이다.(1x1conv 은 channel에만 적용되고 공간 정보는 담지 못하기 때문!)
또 B(3x3 conv를 적용한 그룹)과 5x5 conv를 사용했지만 shallow(신경망이 얕은)한 그룹을 비교해 보았는데 5x5 conv 그룹이 B그룹보다 무려 7%의 높은 오류를 보였다고 한다. 결과적으로 얕지만 넓은 conv를 쓰는것보다 깊지만 좁은 conv를 쓰는것이 더 도움이 된다고 한다!
마지막으로, C,D,E 그룹에서 S의 값을 256~512으로 하는 것이 모든 경우에 대해서 더 정확한 결과를 도출했다고 한다. 연구자들은 augmentation을 했으니 더 결과에 도움이 됐다고 말한다!
4-2. MULTI-SCALE EVALUATION
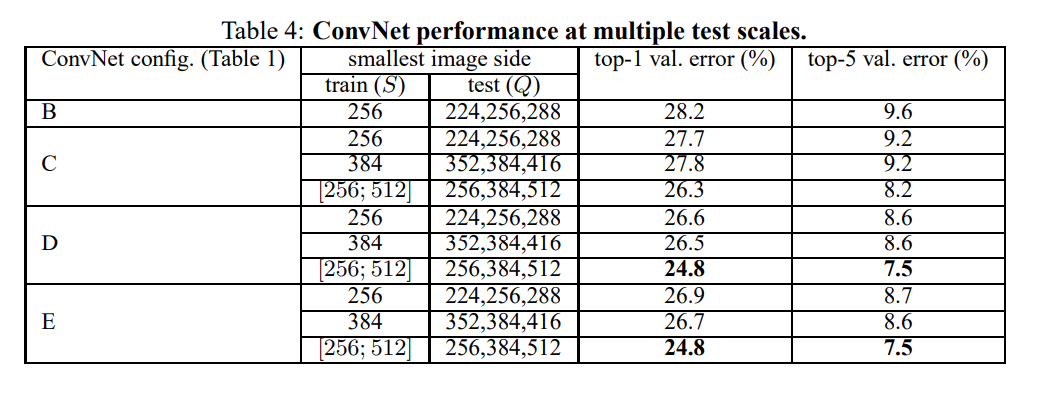
이번에는 multi scale 이다.
single scale 은 Q가 고정된 값이었지만, 이번에는 여러가지 Q를 적용한 후 평균값으로 결과를 지정한다.
결과를 보면 알겠지만, single 보다 multi scale이 더 좋다!(top-1 : 24.8% , top-5 : 7.5%)
4-3. MULTI-CROP EVALUATION
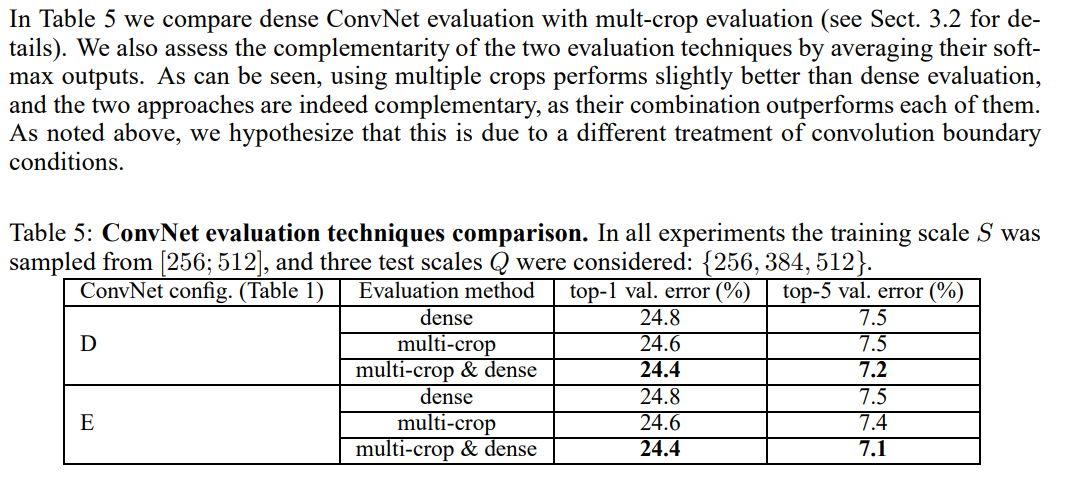
위 표는 dense가 높은 그룹과 mutli-crop을 한 그룹, 두개를 합친 그룹을 비교했다.
dense가 높은 것과 multi-crop이 상보성을 띄기 때문에 둘을 합친 그룹이 가장 정확도가 높았다.(top-1 : 24.4% , top-5 : 7.1%)
4-4. CONVNET FUSION

지금까지는 각각의 개별 모델에 대해서 평가했지만, 이번에는 앙상블(모델들을 이것저것 합치기)을 해보자!
예상했겠지만, multi scale을 적용한 D와 E를 합친 모델이 가장 정확도가 높았다!(top-1 : 23.7% , top-5 : 6.8%)
4-5. COMPARISON WITH THE STATE OF THE ART
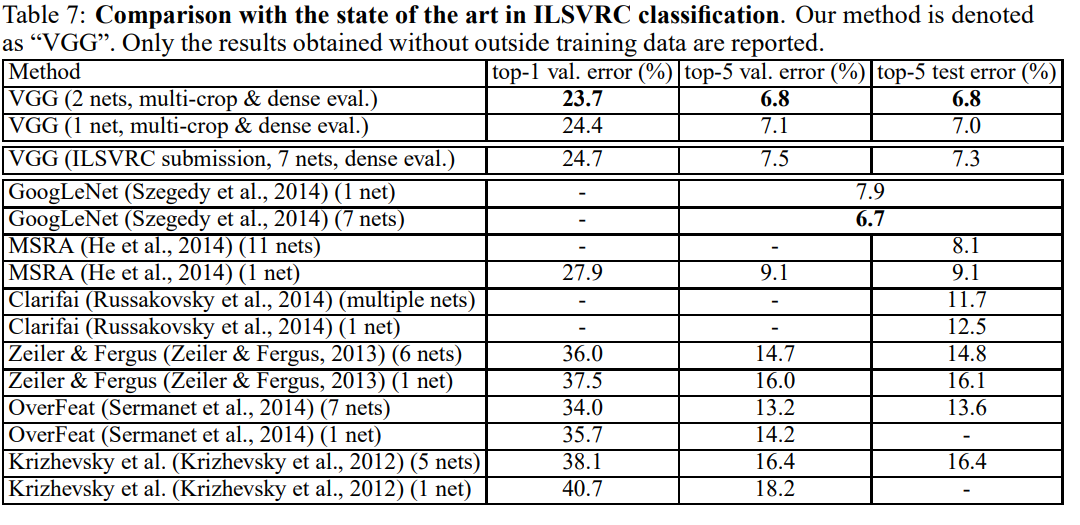
진짜 마지막으로, 다른 논문의 모델들과 비교를 해봅시다.
위의 convnet fusion에서 다룬 multi scale을 적용한 D와 E를 합친 모델을 사용했을때 Googlenet을 제외한 어떤 모델들보다도 정확도가 높은 것을 알 수 있다!
5. CONCLUSION

결론이다.
conv층을 19층 까지 깊게 쌓아 올려서 평가해보았으며, 아무튼 크고 넓은 dataset에 대해서도 얕은 층의 모델보다 정확도가 높게 측정되었다.
층을 깊게 깊게 쌓아보자!
6. 마치며
이렇게 논문분석이 끝이났다.
사실 읽는데에는 별 문제가 없었지만 이렇게 정리하려고 하니 여간 힘든일이 아닌것같다.
모르는 단어, 개념들은 밑에 단어장에 적어놓으려 하니, 모르시는 분들은 가서 보면 좋을 것 같다.
7. 단어장
