텍스트의 다양한 변신
정규식
^.[가-힣].$ 하나라도 한글이 들어간 것 찾기
[^가나다] "가나다"가 한글자라도 포함되지 않은 단어
[^안녕]하십니까 앞에 "안녕"이 한 글자라도 포함되지 않은 단어, 단 "하십니까"는 매칭ㄴ\b가나다\b 가나다 앞뒤에 다른 문자가 붙지 않은 단어만 검색함.(문장부호는 가능)
(?<!파|쉰)김치 파, 쉰으로 시작하지않는 김치 검색
(?<=파|쉰)김치 파, 쉰으로 시작하는 김치 검색
(파|배추|쉰)(?!김치) 뒤에 김치라는 말이 붙지않는 파, 배추 , 쉰 검색
^((?!김치).)*$ 김치를 제외한 모든 문장 검색
^(?=.*?김치)((?!돈까스).)*$ 김치를 포함하고 돈까스를 제외한 모든 문장 검색
2. Deep Learning for Computer Vision Lecture 3: Linear Classifiers

아래의 이미지들은 강의 유투브의 캡쳐이다.
강의주소
가장 기초가 되는 선형 claissifier
대수적 관점
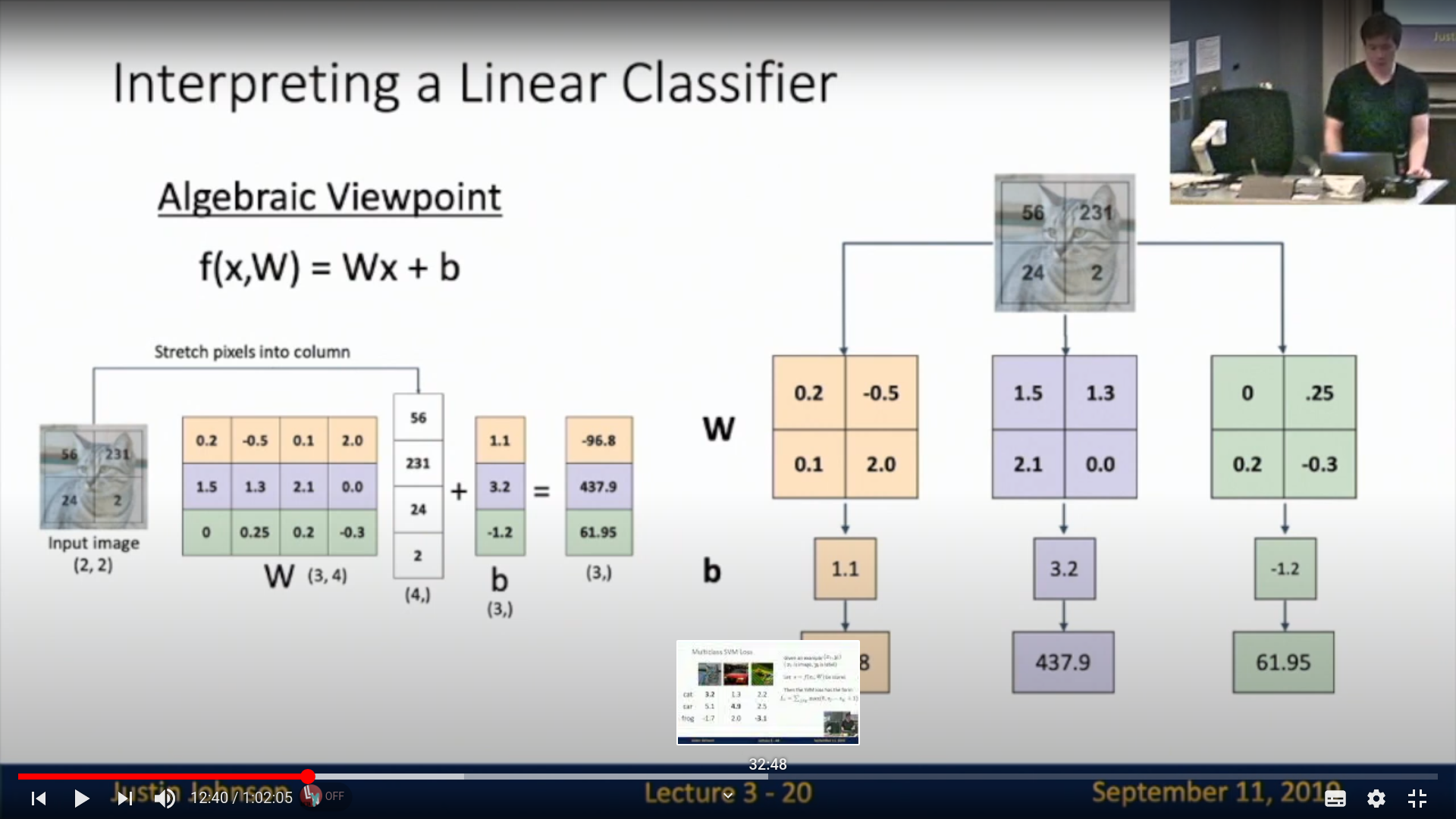
가장 기초적이라고할수있는 대수적 관점
bias인 1.1, 3.2, -1.2는 없애고 벡터에 한번에 처리할수도있다. (bias trick)

it's nice to be aware of as you think about building different types of
machine learning systems but in fact in computer vision this bias trick >is less
common to use in practice because it doesn't carry over so nicely as we move
from linear classifiers to convolutions later on and furthermore it's nice
sometimes to separate the weight and the bias into separate parameters so we can
treat them differently and how they're initialized or regularize or other
things like that but nevertheless this bias trick is a fairly nice thing to be
aware of for linear classifiers and it's totally obvious when you think about it
다른 분야의 머신러닝에서는 고려할때가 있지만 컴퓨터 비젼 실무에서는 잘 그렇게 쓰지 않는다고 한다. convolution이나 다른 모델로 변형할때 불편하기 때문이라고한다.
비쥬얼적 관점

linear classifer는 범주별로 한 template만 가지게 되는 성향이 있다고한다.
그러므로 배경의 영향을 많이 받으며, 좌측을 보는 말, 우측을 보는 말을 동시에 학습시키니
말의 template으로 좌측, 우측에 둘다 머리를 가진 말로 학습된것을 확인할 수 있다.
geomatric한 관점

다른 픽셀을 고정시켜놨을때 어떤 범주로 포함될지에 대한 score을 계산가능하다. \
1차원은 재미가 없으니 2차원으로 확장한다면

이런식으로 2차원으로 표현할수있고, 각 score는 hyperplane을 그리게 된다.
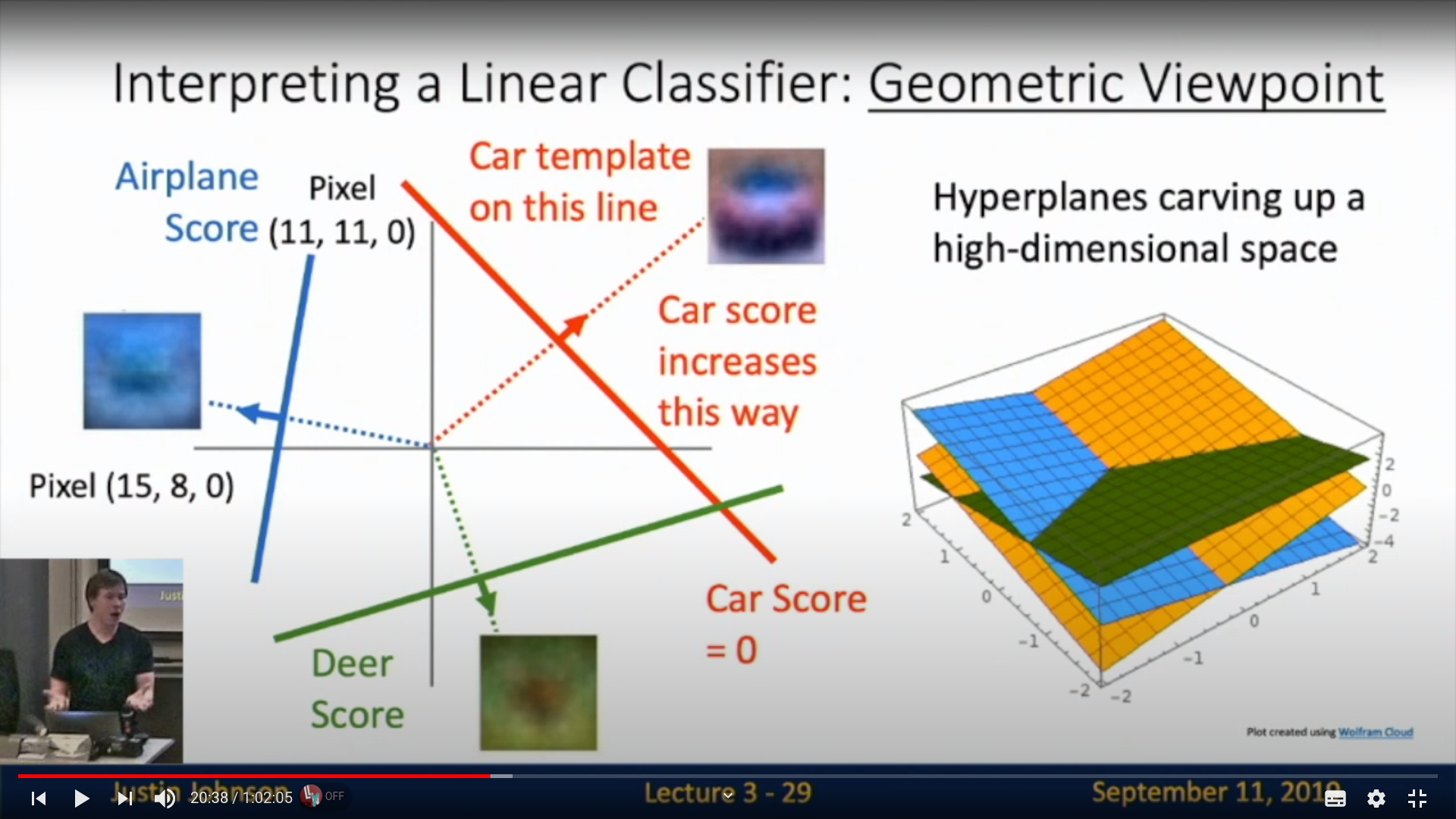
이런식으로도 표현가능해진다. 3차원 픽셀에선 2차원의 hyperplane으로 나타나게되고
각각 aiplane으로 판단하는 공간, deer로 나타나는 공간등이 분리되게 된다. (물론 선형적으로)
카메라 스티커 앱 만들기
.png)
솔직히 처음에 난해했다. 기본 픽셀이랑 RGB 채널 정도는 알고있었는데 python내에서 dimension이 어떤형태로 이루어지는지 잘 모르겠고 사실 지금도 잘 모르겠다. 조금 더 공부가 필요한 분야
Data 표현 array와 table
pandas는 참 좋은 library인거같다.
파이썬 알고리즘 인터뷰-6장 문자열 조작
어려웠던 leetcode 93 번
문제링크
def restoreIpAddresses(self, s: str) -> List[str]:
def splitAddress(dots: int, s: str) -> List[str]:
if (not s) or (len(s) <= dots) or (len(s) > dots * 3 + 3) :
return []
if dots == 0:
if len(s) > 1 and s[0] == '0':
return []
elif int(s) > 255:
return []
else:
return [[s]]
else:
result = []
first_splits = splitAddress(dots-1, s[1:])
for first_split in first_splits:
first = [s[:1]]
first.extend(first_split)
result.append(first)
if s[0] != '0' :
second_splits = splitAddress(dots-1, s[2:])
for second_split in second_splits:
second = [s[:2]]
second.extend(second_split)
result.append(second)
if int(s[:3]) < 256:
third_splits = splitAddress(dots-1, s[3:])
for third_split in third_splits:
third = [s[:3]]
third.extend(third_split)
result.append(third)
return result
splitedAddresses = splitAddress(3, s)
result = []
for splited in splitedAddresses:
result.append('.'.join(splited))
print(result)
return result내가 풀고도 신기했던 풀이
leetcode3 93번
import typing
class Solution:
def firstUniqChar(self, s: str) -> int:
b = [s.find(a) for a in "abcdefghijklmnopqrstuvwxyz" if s.count(a) == 1 ]
if len(b) == 0 :
return -1
else :
return min(b)이 문제는 많은 긴 문자열을 넣어서 실행시간을 측정했다.
그러므로 문자열을 일일히 따지면 오히려 속도가 느려진다.
알파벳으로 26개로 한바퀴 돌리는게 더 빠른 속도를 보여줌
영화리뷰 텍스트 감성 분석
한국어 리뷰와 영어리뷰의 차이점이 잘 와닿지가 않아서 어려웠다. 자세한 포스팅은 내일 진행하겠다.
딥러닝과 인공신경망의 본질
죠슈아 벤지오의 딥러닝 정의가 매우 신기했다.
단순히 딥러닝을 하나의 거대한 모델이고, 수없이 많은 가중치들을 loss function을 통해 최적화한것을 뱉어내는 도구로만 생각하던 나에게 조슈아 벤지오의 내재적 표현이라는 말이 신비롭고 다르게 다가온다.
(원문)Deep learning is inspired by neural networks of the brain to build learning machines which discover rich and useful internal representations, computed as a composition of learned features and functions.
(번역) 뇌의 신경 구조로부터 영감을 받아 신경망 형태로 설계된 딥러닝의 목표는, '합성된 함수를 학습시켜서 풍부하면서도 유용한 '내재적 표현'을 찾아내는 machine을 구축하는 것'이다.
lime
결과에 대해 해석이 가능하다면 훨씬 더 유용하게 쓸 수 있다.
학생의 교육성과 모델이 만들어졌다고 하자.
교육성과를 높이는 긍정적인 요소를 해석할 수 있다면 이 긍정적인 요소들을
정책적으로 강화하면 국가의 교육성과를 상승시킬수 있을것이다.
즉 모델에 대한 해석이 가능하다면 긍정적인 변수를 사람이 변화시킬수 있게되고 그 변화를 통해서 보다 나아갈수있게 된다.
이렇게 해석가능한 모델은 여러가지 장점을 가지고 있기 때문에 사람들이 관심가지는 분야인데
이 lime 기법은 상당히 직관적이고 간단한 변화로 다양한 모델에 변화시킬수있어 신기했다.
SSAC 과정에서 수행하고있는 영화리뷰 텍스트 감성분석에도 한번 활용해보고 다음주 내에 올리도록 하겠다.
볼만한 링크들
saskorea 블로그
머신러닝 모델의 블랙박스 속을 들여다보기 : LIME
scikit-learn을 통해 생성한 모델일때 쉽게 쓰는 라임 코드
뭔가 바쁘긴한데 제대로 공부되는게 없는 느낌이다. 다음주는 좀 더 밀도있게 공부해야겠다.
