이번주는 제가 진행하는 "가볍게 시작하는 통계학습 스터디"가 절반가량 진행되었기에
스터디의 파수꾼으로 제가 느꼇던 점에 대해서 적어보겠습니다.
스터디의 목적
DeepML에서는 제대로 배우지 못했던, 딥러닝의 기반이 되
통계학적 방법론이나 모델에 대해서
교재를 통독하면서 공부하는 스터디입니다. 통계프로그램 R에 대해서도 간단하게 맛 볼 수 있습니다.
즉 딥러닝 for computer vision에서 딥러닝을 배우면서 기반이 되는 통계학적 방법론과 모델에 대해 An Introduction to Statistical Learning with Applications in R를 통독하면서 공부하는 스터디를 목표로 삼았습니다.
즉 스터디는
머신러닝, 딥러닝을 공부하는 조원들과 통계학습 스터디를 한 내용입니다.
스터디 방법
매주 금요일 제가 그 주에 읽을 내용의 pdf에 주의해야할점. 같은걸 필기해서 올립니다.

이런식으로 정리합니다.
6주차 필기 전체는 아래와 같습니다.
그러면 조원분들께서 그 분량을 읽어오시면
매주 월요일 저녁 7시에 구글 MEET에서 스터디를 시작합니다.
7시 30분까지 책을 읽으면서 질문을 정리하고 저희 NOTION의 질문방에다 질문을 올립니다.
그후 9시까지 계속 다같이 논의하면서 답을 찾아 나가아갑니다.
딥러닝과 통계학의 용어 차이
일단 딥러닝과 머신러닝은 비슷한 개념을 다른 용어를 통해 쓰기도하고
완전하게 다른 용어를 같은 명칭이라고 부르는 경우가 많습니다.
비슷한 개념인데 다르게 쓰는 경우
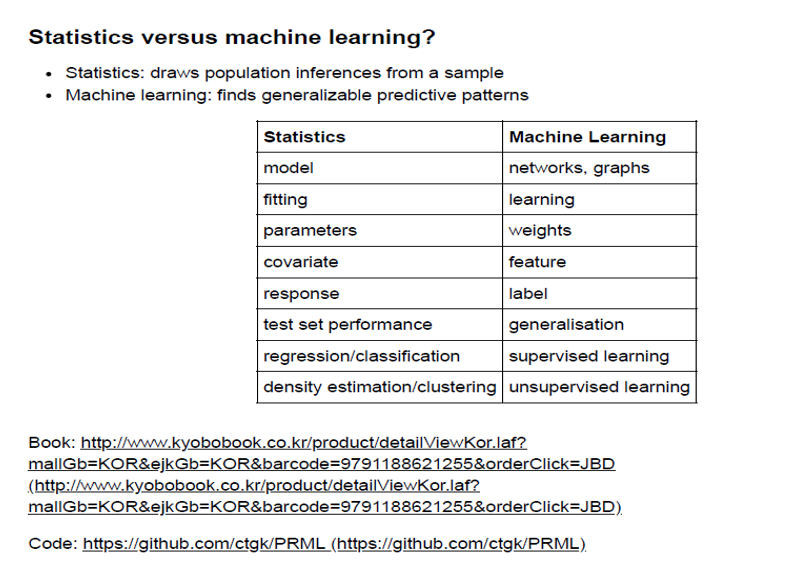
대표적인 차이들..
One Hot Coding vs dummy variable
Label vs Y
사실 이런 경우는 비슷한 개념이라는 것만 알면 되기 때문에 큰 문제는 아니라고 생각합니다.
다른 개념인데 같은 용어를 쓰는 경우
이게 가장 큰 문제였습니다.
본인이 알고있는 딥러닝 관련 용어와 통계학 용어가 겹치는데 전혀 다른 개념이니
혼동오시는 분들이 매우 많았습니다.
예를 들어 딥러닝에서의 bias와 통계학의 bias는 전혀 다른 개념입니다.
통계학에서 bias는 추정값의 평균이 실제 참값과 일치하지않음을 보여주는 개념입니다.
딥러닝 모델에서 bias를 넣어주는것은
통계학모델의 intercept에 가까운 개념입니니다.
그런데 통계학책에서 model의 bias와 variance에 대해 설명을 하니 대부분의 조원들이 딥러닝의 bias라고 오독하셔서 이해를 못하시는 분들이 매우 많았습니다. 통계학을 전공한 저에게는 model bias라는 개념이 너무나도 당연하여 왜 이해를 못하는지 몰랐는데 이런 용어의 혼동때문에 그랬던 것이었습니다.
즉 공부하실 때 이런 용어의 차이에 대해서 항상 유의하시고 구별하여 설명하시면 좋을 것 같습니다.
소고
-
사실 복잡한 딥러닝 기법들의 놀라운 정확도에 비하면 초라해질수도 있는 통계학습들인데 다들 열심히 읽어오시고 토론해주시고 질문해주셔서 제가 제일 즐겁습니다.
-
항상 설명을 할때 저희 AIFFEL 노드에서 있던 예시를 가지고 설명하려하려고 노력하고있습니다.
이제 절반 남은 만큼 다들 더 배워갈 수 있도록 더 준비하려고 노력하겠습니다. -
스터디 중 질문을 기록하지않아 휘발되는게 안타까웠는데 질문방을 만들어 기록하는게 정말 좋은 것같습니다. 다른 분들도 온라인 스터디를 하신다면 꼭 추천하는 방식입니다.
번외
교재 PDF판은 무료로 이용할 수 있습니다. 일반적으로 통계학과 3,4학년의 전공과목의 교재라고 보시면 됩니다.
An Introduction to Statistical Learning with Applications in R(교재)
