안녕하세요😀 선한 데이터 사이언티스트를 꿈꾸는 Hayley 입니다~!
오늘은 일하면서 새롭게 보게된 Pandas 함수 ✂ truncate ✂에 대해 소개하고자 합니다.
문법
먼저 한 눈에 문법을 보여드릴게요!
데이터 프레임 뒤에 . 을 붙이고 사용하시는 함수입니다.
DataFrame.truncate(before=None, after=None, axis=None, copy=True)정의
데이터 프레임에서 명시된 index값 (또는 컬럼명) 전과 후를 없앤 데이터 프레임을 반환하는 함수
정의를 하나하나 살펴 볼까요?
먼저, "반환"하는 것이기 때문에 함수를 호출한 데이터프레임 자체가 바뀌지 않습니다. (inplace operation이 아님)
또한, "전"과 "후"를 없애기 때문에 before, after 인자로 입력된 index는 남고, 그 전 또는 후의 index가 없어집니다.
마지막으로, 이건 제가 직접 확인한 부분인데요. Documentation에는 적혀있지 않지만, truncate를 사용하기 위해서는 index (또는 column명) 가 반드시 오름차순으로든 내림차순으로든 정렬(sort) 되어 있어야 합니다.
처음에는 DataFrame.loc 함수와 거의 같은 것 같은데 왜 굳이 이런 함수를 별도로 만들었나 싶었는데, 정렬이 필요한 부분을 보니 작동 방식이 완전히 같지는 않은 것 같습니다.
Parameters
그럼 어떤 인자를 받는지 볼까요?
- before (date, str, int): Truncate all rows before this index value.
- after (date, str, int): Truncate all rows after this index value.
- axis ({0 or ‘index’, 1 or ‘columns’}, optional, default is 0): Axis to truncate. Truncates the index (rows) by default.
- copy (bool, default is True): Return a copy of the truncated section.
before, after에는 truncate(절삭)하고 싶은 기준 index를 쓰면 됩니다. 이미 말씀드렸지만, before이나 after에 적은 index값의 전, 후를 truncate 하는 것이기 때문에 before, after index 자체는 남아요.
그리고, axis 를 인자로 받아, row 뿐만 아니라 column 도 truncate 할 수 있다는 것을 알 수 있습니다.
마지막으로, copy 인자가 있어 copy=False로 하게 되면 DataFrame의 copy가 아니라 slice를 반환할 수도 있습니다. 예를 들어, 원본 데이터 프레임에 값을 변경하면 truncate 로 반환 받아서 저장해놓은 데이터 프레임의 값도 바뀌었으면 좋겠다 한다면 copy=False로 지정해야 겠죠!
작동 예시
이제 한번 실제로 사용해 보겠습니다.
✨ scikit-learn 패키지에서 아이리스 데이터를 불러왔습니다.
총 150개 Row 에 4개 Column이 있네요.
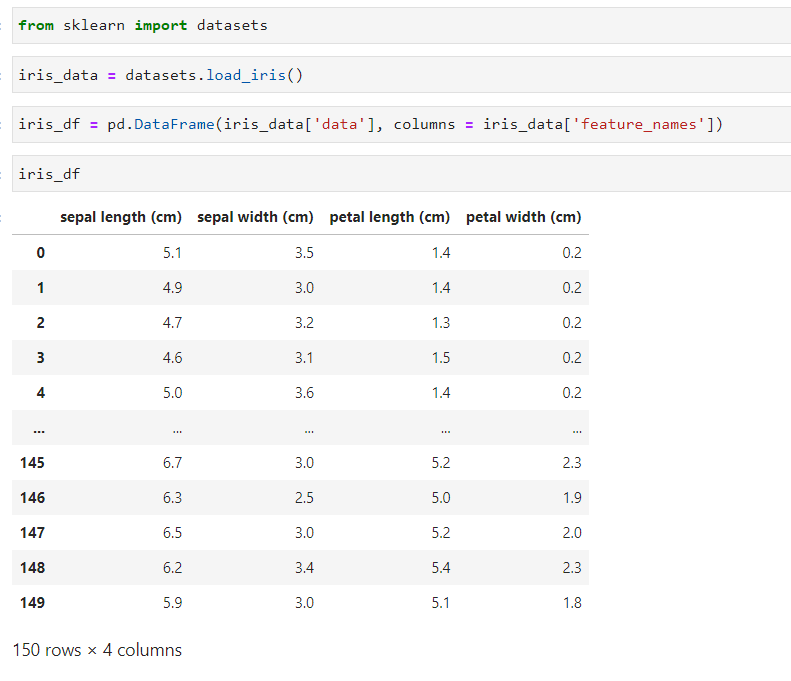
✨ 이제 Row를 10번 index 후로 없애 보겠습니다.
그 결과, 10번 index의 row까지는 남아있고, 11번 부터 없어진 것을 확인하실 수 있습니다.
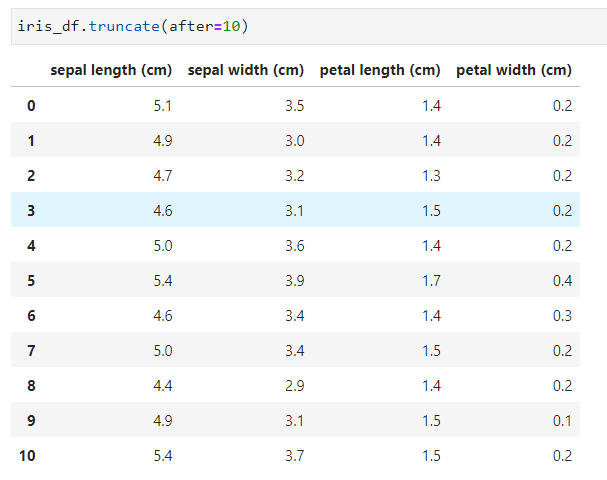
✨ Before도 사용해볼까요?
역시 10번 index는 남아있고, 그 전의 0~9 index의 row 들이 없어졌네요.
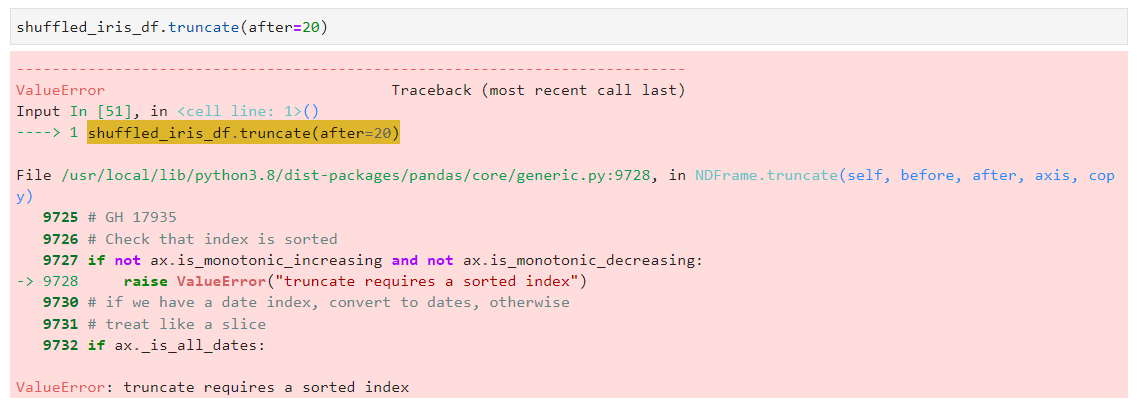
✨ 다음은, index가 sorting이 되어야만 적용이 가능하다는 것을 보여드리겠습니다.
처음 불러왔을 때는 index가 0부터 오름차순으로 잘 정렬이 되어 있었죠.
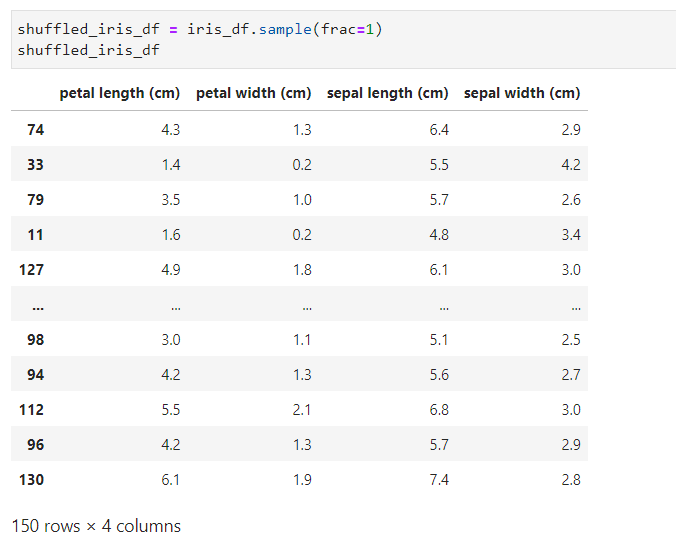
이 index를 pandas.DataFrame.sample() 함수를 이용해서 순서를 랜덤하게 섞어 볼게요. (참고로, pandas.DataFrame.sample(frac=1)을 사용하면 데이터 프레임의 row가 랜덤하게 섞인 데이터 프레임이 반환됩니다.)
그리고 나서 truncate를 수행하려고 하면 이렇게 ValueError: truncate requires a sorted index 라고 에러가 납니다.
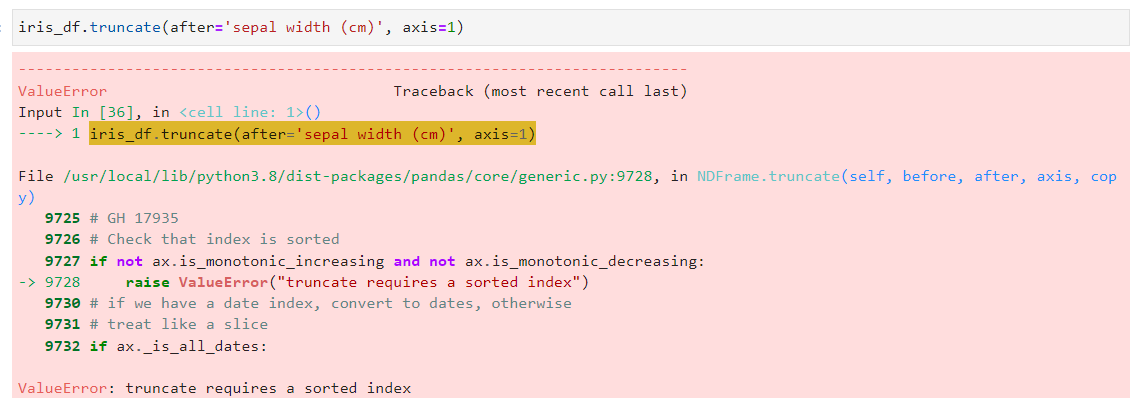
✨ truncate 적용 전 Sorting이 필요한 것은 Columns 단위로 적용하실 때도 마찬가지 입니다. Iris 데이터셋은 row의 index는 가지런히 정렬 되어 있지만, column 명은 보시면 sepal length(cm), sepal width (cm), petal length (cm), petal width (cm) 으로 오름차순 정렬도 내림차순 정렬도 아닙니다.
그래서, column 기준으로 truncate를 수행하려고 하면 에러가 나죠.
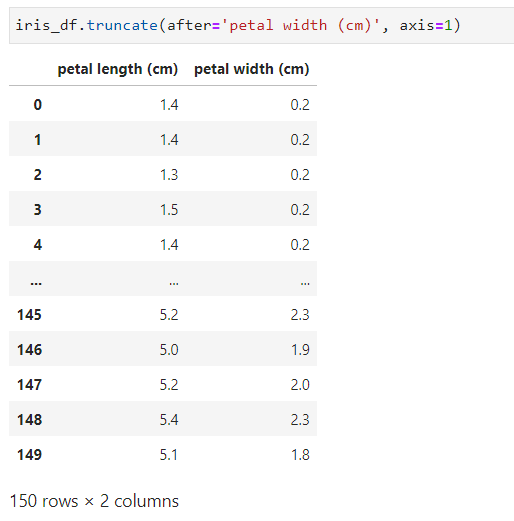
✨ 따라서 pandas.DataFrame.sort_index(axis=1) 호출 후에 다시 실행해야, 문제없이 truncate할 수 있습니다.
다만, 이번에는 컬럼 순서가 petal length, petal width, sepal length, sepal width 이다 보니 sepal width 가 아니라 petal width 후를 truncate 하는 것으로 명령어를 조금 바꿨습니다.
마치며
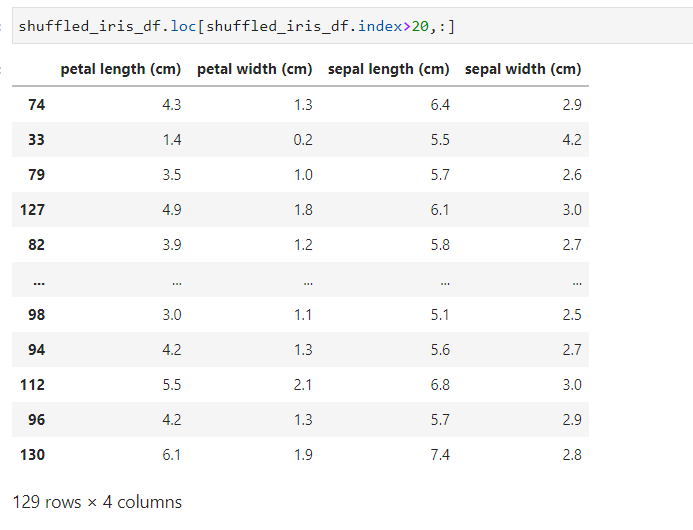
참고로 확인해보니, DataFrame.loc 을 사용하면 index가 뒤죽박죽으로 섞인 경우에도 index 의 값이 20 보다 큰 index들을 삭제할 수 있습니다.
그러면 왜 DataFrame.loc으로도 할 수 있는 기능을, 아니 오히려 index를 sort한 경우에만 사용할 수 있으니 더 제한이 있는데도 truncate로 만들었을까요?
Pandas 개발자의 뜻을 제가 정확히 알진 못하지만 Documentation에 따르면,
This is a useful shorthand for boolean indexing based on index values above or below certain thresholds.(이것은 특정 값보다 크거나 작은 인덱스 값을 기준으로 하는 불리언 인덱싱에 대한 유용한 간략한 표현법이다.)
라고 합니다. truncate가 영어 문장과 비슷하다 보니, 마치 문장을 작성하듯 쓸 수 있어서 indexing 보다 더 간편하다고 생각했기 때문일까요? (sorting을 해야해서 약간 번거롭긴 하지만 데이터 인덱스가 대부분 sorting이 되어 있고 대부분 truncate를 index에 대해서만 쓴다고 하면 sorting을 굳이 신경쓰지 않아도 되겠네요.)
아무튼 한마디로 정의해보면,
DataFrame.truncate = DataFrame.loc[DataFrame.index > val] given DataFrame.sort_index(inplace=True) is done.
이네요! 그럼 오늘 글은 마치겠습니다.
궁금하거나 더 알고 싶으신 내용이 있으시면 댓글로 달아주세요!😁
참고문서
