🧠 환각(Hallucination)이란 무엇인가
AI의 ‘환각’은 사람이 보는 환상과는 조금 다릅니다.
언어 모델에게 환각이란, 모르는 정보를 ‘그럴듯하게’ 지어내는 현상을 뜻합니다.
언어 모델은 기본적으로 “다음 단어를 예측”하도록 훈련됩니다.
즉, 언제나 답을 내야 하는 구조이기 때문에 모르는 상황에서도 추측을 내뱉는 경향이 생깁니다.
이 때문에 연구자들은 “AI가 환각을 하지 않도록 만드는 것”을 중요한 과제로 보고 있죠.
Anthropic의 모델 Claude는 이 문제를 막기 위해 비교적 성공적인 환각 방지 훈련(anti-hallucination training)을 거쳤습니다.
즉, 모르는 질문에는 억지로 답하지 않고 “잘 모르겠습니다”라고 거절하도록 설계된 것이죠.
⚙️ 환각이 생기는 내부 원리
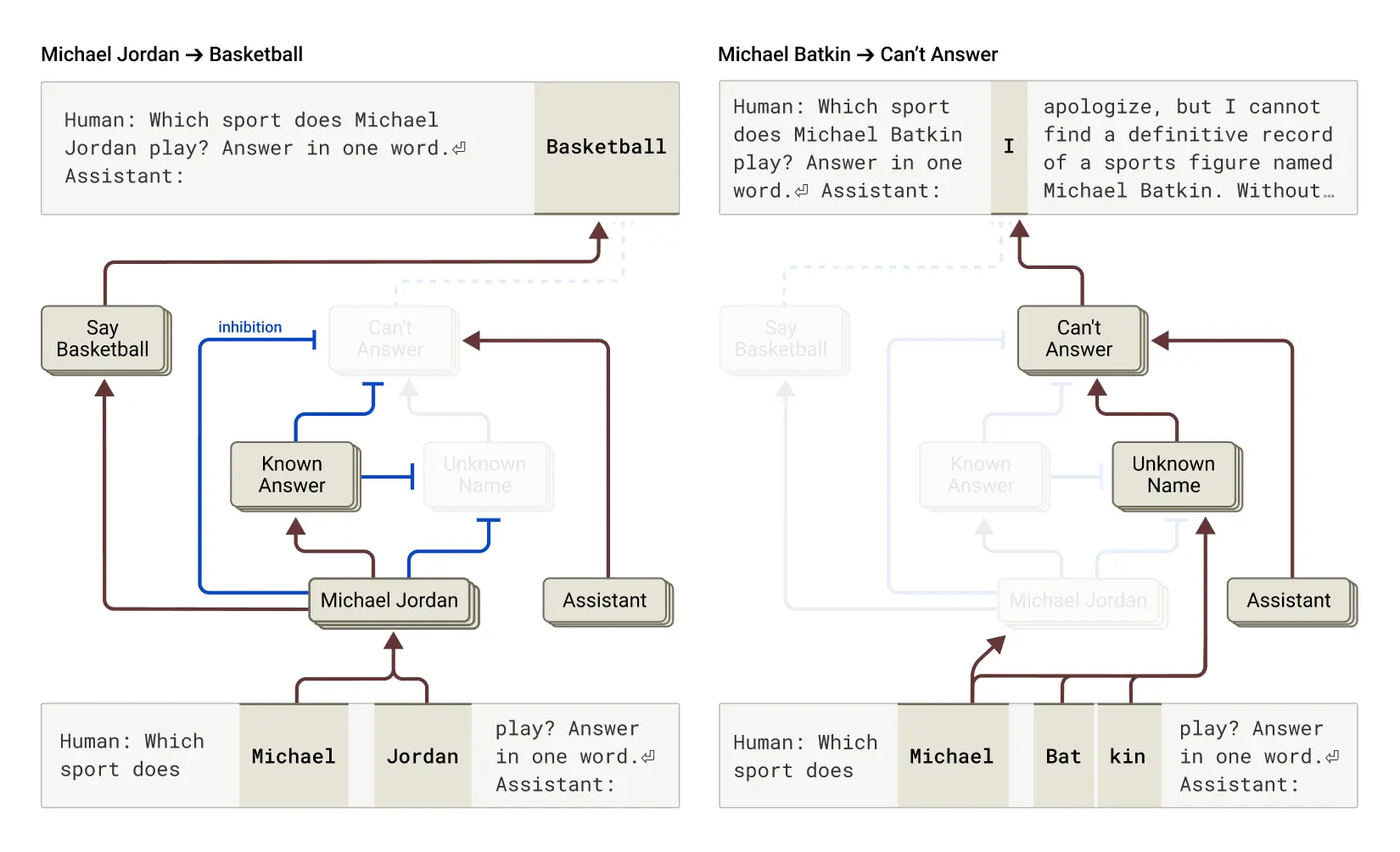
이번 연구에서 밝혀진 흥미로운 사실은, Claude의 기본값(default)이 “답변 거부(refusal to answer)”라는 점입니다.
AI 내부에는 일종의 ‘회로(circuit)’가 있어서, 이 회로가 켜져 있으면 Claude는 “정보가 부족합니다”라고 말합니다.
그런데 여기엔 또 하나의 경쟁 회로, 즉 ‘알려진 개체(known entity)’ 기능이 있습니다.
이 기능은 모델이 ‘잘 아는 대상’을 인식할 때 활성화되어, 기본 거부 회로를 억제합니다.
예를 들어,
- “Michael Jordan”을 묻는다면 → ‘알려진 개체’ 회로가 켜져서 답변을 허용합니다.
- “Michael Batkin”처럼 낯선 이름을 묻는다면 → ‘알려진 개체’ 회로가 꺼져 있어서 답변을 거부합니다.
즉, Claude는 “아는 것만 대답하고, 모르면 거절하는 구조”를 가지고 있습니다.
🧩 실험: 강제로 환각을 만들어내기
연구팀은 모델 내부의 신호를 조작하여 흥미로운 실험을 진행했습니다.
‘알려진 답변(known answer)’ 회로를 인위적으로 활성화하거나,
‘모름(unknown name)’·‘답변 불가(can’t answer)’ 회로를 강제로 억제하면
Claude는 일관되게 “Michael Batkin은 체스 선수입니다”라고 말하기 시작했습니다.
즉, 회로 하나만 잘못 켜져도 AI는 스스로 “아는 것처럼” 행동하며,
존재하지 않는 사실을 지어내는 ‘환각’이 발생한다는 것이죠.
🔄 자연스러운 오작동 ― 진짜 환각의 순간
이런 회로의 “오작동(misfire)”은 인위적 조작 없이도 자연스럽게 일어날 수 있습니다.
Claude가 어떤 이름은 알아보지만, 그 사람에 대한 구체적 정보는 없을 때가 그렇습니다.
예를 들어, 이름이 익숙하게 들린다는 이유만으로
AI가 ‘알려진 개체’ 회로를 잘못 켜 버리면,
“모른다”는 기본 회로가 억제되어 버립니다.
그 순간 Claude는 지어내기(confabulate)를 시작합니다.
그럴듯하지만, 사실이 아닌 답변을 자신 있게 내놓는 것이죠.
🪄 우리가 배울 수 있는 것
이 연구는 “AI의 환각은 단순한 오류가 아니라, 내부 판단 회로의 오작동”임을 보여줍니다.
즉, AI는 “모름”과 “앎”의 경계를 스스로 판단하며,
이 판단이 흐려질 때 현실과 다른 세계를 만들어냅니다.
언어 모델의 진화는 단순히 데이터를 더 넣는 것이 아니라,
“언제 모른다고 말할지”를 가르치는 과정이라는 사실이 새삼 중요하게 느껴집니다.
🧭 요약하자면:
AI의 환각은 ‘지식의 착각’에서 비롯됩니다.
Claude는 스스로 ‘아는 것처럼 착각하는 순간’에 현실이 아닌 대답을 만들어냅니다.
그리고 그 착각의 뒤에는, ‘알려진 개체 회로’라는 작은 신호의 불균형이 숨어 있습니다.
📚 참고 출처:
Anthropic Research — Tracing Thoughts in Language Models
👉 https://www.anthropic.com/research/tracing-thoughts-language-model
