인공지능
1.은닉층이 있는 경우 신경망 학습 예시

은닉층(Hidden layer)이 1개 있는 경우의 간단한 신경망으로 경사 하강법 예시를 보여드리겠습니다.
2.체인 룰(Chain rule)과 경사 하강법(Gradient descent)의 관계
신경망의 출력 𝐿 (손실 Loss)은 여러 층을 거쳐 계산됩니다.따라서 특정 가중치 𝑤가 Loss에 어떻게 영향을 주는지 계산하려면 체인 룰(Chain Rule)을 사용해야 합니다.
3.역전파와 Loss 최적화: 간단한 예제와 원리
Loss (손실)모델의 예측값과 실제값의 차이를 수치화한 값의 예시 (Pytorch 코드 첨부)
4.Self-Attention 설명 및 예시
Self-Attention의 개념 및 간단한 예제에 대한 내용입니다.
5.레이어 정규화 (Layer Normalization)
Layer Normalization은 딥러닝 모델, 특히 Transformer에서 아주 중요한 역할을 합니다.
6.Self-Attention, RNN, CNN, Restricted Attention 연산 특성 비교
각 레이어의 연산 특성을 비교합니다.
7.2D CNN 연산 복잡도 (Complexity)
2D CNN의 연산 복잡도에 대한 설명과 예시 입니다.
8.Checkpoint Averaging, Ensemble Model, Single Model 비교 설명
모델 성능을 올리기 위한 네트워크 Weight 튜닝 기법들의 설명입니다.
9.CNN과 Attention 복잡도 (Complexity) 비교
2D CNN의 연산 복잡도 및 Self-attention layer의 비교 글입니다.
10.NAS (Neural Architecture Search) 설명
NAS는 딥러닝 모델의 구조(architecture)를 자동으로 설계하는 방법입니다.
11.Covariate shift 설명
Batch Normalization(BN)이 해결하려는 "covariate shift", 특히 internal covariate shift에 대한 설명입니다.
12.딥러닝과 통계에서 자주 나오는 데이터 '30개' 기준, 이유는?
"왜 데이터가 적어도 30개 이상 있어야 할까?"에 대해 정규분포와 중심극한정리(Central Limit Theorem, CLT)는 실제로 연관이 있습니다.
13.Batch vs. Linear normalization 차이
Batch Normalization(BN)과 Layer Normalization(LN)의 차이에 대한 설명입니다.
14.Linear layer에 대한 설명 및 예시
Linear layer(선형 레이어)는 인공지능 모델에서 입력을 받아 "한 번 곱하고 더하는" 역할을 합니다.
15.Convolution layer에 대한 설명 및 예시
Convolution Layer(합성곱 층)에 대한 설명 글 입니다.
16.Grid Pooling 설명
Grid Pooling은 쉽게 말하면,포인트 클라우드를 격자(grid)로 나눠서, 같은 칸에 들어간 포인트들을 요약하는(pooling하는) 방법입니다.
17.Grid Pooling vs. Furthest Point Sampling (FPS) 비교
Grid Pooling과 Furthest Point Sampling(FPS) 을 비교한 글 입니다.
18.Positional Encoding (PE) 설명
Transformer 모델에서 Positional Encoding (PE)은 입력 데이터의 순서를 모델이 인식할 수 있도록 하는 기법입니다.
19.Receptive Field 설명 및 예시
Receptive field (수용 영역)는 CNN의 특정 뉴런(또는 피처)의 출력이 입력 이미지의 어느 영역을 참조하고 있는지를 의미합니다.
20.지식 증류(Knowledge Distillation)의 개념과 원리 완벽 정리
지식 증류(knowledge distillation)는 큰 모델(teacher)의 지식을 작은 모델(student)로 전달하여, 작은 모델도 높은 성능을 내도록 만드는 모델 압축 기법입니다.
21.1D CNN에서 수식으로 이해하는 Backpropagation
본 글은 1D CNN에서 수식을 기반으로 한 backpropagation 과정을 간단한 예제를 포함합니다.
22.NMS (Non-Maximum Suppression) 설명
NMS(Non-Maximum Suppression)에 대한 설명입니다.
23.Trilinear Interpolation을 이용한 Mesh Vertex Label 보간 방법
3D Segmentation: Mesh Vertex에 Voxel Label을 Trilinear Interpolation으로 할당하기
24.딥러닝 Validation Loss, 단순 평균 vs 가중 평균
Validation Loss 평균 계산법에 따라 성능 비교가 달라질까요?
25.Batch Size, 얼마나 줘야 좋을까? 딥러닝 성능과 일반화의 균형 찾기
너무 크거나 너무 작으면? Batch Size가 딥러닝에 미치는 영향 정리
26.딥러닝 모델 일반화 성능을 높이는 오버피팅 방지 전략
오버피팅 방지를 위한 실전 테크닉 8선: Regularization부터 Early Stopping까지
27.단순 앙상블을 넘어서: XGBoost 기반 Stacking으로 성능 극대화하기
단순 앙상블을 넘어서: XGBoost 기반 Stacking으로 성능 극대화하기
28.확률적 경사 하강법(SGD)와 Momentum, Adam 최적화 알고리즘 이해하기
SGD에서 Adam까지, 손실 최소화를 위한 알고리즘 진화 과정 정리
29.Cross Entropy Loss와 MSE의 차이, 언제 어떤 손실 함수를 써야 할까?
손실 함수 완전 정복: Cross Entropy vs MSE
30.초기화가 중요한 이유와 딥러닝에서 꼭 알아야 할 He 초기화
딥러닝 학습 안정성의 비밀, 파라미터 초기화와 He 초기화 이해하기
31.Conv & Linear Layer는 어떻게 초기화될까? (PyTorch)
딥러닝 성능을 좌우하는 시작점, 파라미터 초기화 A to Z
32.Ablation Study 제대로 알기: 구성 요소의 힘을 밝히는 실험
Ablation Study는 딥러닝 모델의 구성 요소 중 일부를 제거하거나 변경하여, 그 요소가 모델 성능에 얼마나 기여하는지를 분석하는 실험 방법입니다.
33.코사인 유사도(Cosine Similarity)란? 쉽게 배우는 개념과 예제
코사인 유사도(Cosine Similarity) 완벽 정리: 개념부터 코드 예시 포함
34.Attention vs MLP vs Linear Layer: 연산 복잡도 비교와 효율적인 선택
Transformer 구조를 이해하다 보면 꼭 마주하게 되는 질문이 있습니다. 바로 "Attention Layer는 얼마나 연산량이 많을까?", "MLP는 상대적으로 가볍나?" 하는 궁금증입니다.
35.Degradation Problem: 딥러닝이 깊어질수록 성능이 떨어지는 이유
깊게 쌓았는데 왜 성능이 나빠질까? 딥러닝 Degradation 문제 알아보기
36.Semantic vs Instance Segmentation: 뭐가 다를까?
시맨틱 vs 인스턴스 세분화, 이미지에서 객체를 구분하는 두 가지 방식
37.Pooling vs Convolution: 공간은 줄이고, 채널은 유지하는 이유
Max Pooling이 채널 수는 왜 안 바꿀까? 채널을 바꾸는 연산은 따로 있습니다.
38.귀납적 편향(Inductive Bias)이란? 머신러닝 모델의 일반화
학습하지 않은 것도 맞추는 AI의 비결, 귀납적 편향이란?
39.SGD와 Adam의 차이점은? 딥러닝 최적화 알고리즘 쉽게 이해하기
딥러닝 학습 효율 올리기: SGD와 Adam의 원리와 장단점
40.딥러닝 실전 팁: Attention 출력과 클래스 수의 관계 (ViT 예시 포함)
CNN + Attention or ViT로 이미지 분류할 때 Output은 어떻게 설정할까?
41.Transformer의 핵심, Attention과 Cross Attention 쉽게 구현하기
PyTorch로 Self-Attention부터 Cross-Attention까지 실전 구현
42.딥러닝 Feature, 어디서 추출해야 성능이 잘 나올까?
모델 간 연동을 위한 딥러닝 Feature 추출법
43.AI가 치아를 얼마나 잘 알아볼까? 성능 지표 3가지로 확인하기
정량적으로 평가하는 치아 AI 분할 성능, TLA, TSA, TIR이란?
44.GPU 메모리 부족? VRAM 최적화 완벽 가이드 (Pytorch)
딥러닝 모델의 VRAM 사용량을 줄이는 10가지 방법
45.PyTorch 모델, VRAM 사용량 분석해보니…
VRAM 2배 증가? 파라미터가 아닌 feature map 때문입니다
46.딥러닝의 모델 구조: Cascade, 피라미드, Hourglass, 그리고 오토인코더까지 한눈에 정리!
딥러닝 모델 구조 완전 정복: Cascade, Pyramid, Hourglass, Autoencoder의 차이점은?
47.Variational Autoencoder(VAE) 완벽 정리: 구조, 수식, 활용까지 한눈에!
Variational Autoencoder(VAE) 완벽 정리!
48.KL Divergence란? VAE에서의 역할과 수식까지 한눈에 정리!
KL Divergence란?
49.LibTorch JIT 추론 최적화: InferenceMode부터 Executor 설정까지 한눈에!
PyTorch C++에서 추론 성능을 끌어올리는 4가지 핵심 설정
50.Foundation Model과 LLM, LAM, MLLM, VLAM 정리
AI 핵심 개념: Foundation Model과 그 파생 모델 총정리
51.쉽게 이해하는 KL Divergence Loss와 VAE 예시
KL Divergence 개념부터 VAE 예제까지 한 번에 이해하기
52.머신러닝 필수 개념: Regularization과 Generalization 정리
과적합 방지부터 모델 안정화까지! Regularization & Generalization 한눈에 보기
53.과적합을 잡고 일반화를 높이는 8가지 정규화 기법과 Dropout 원리
Regularization 기법 완전 정복 & Dropout의 앙상블 효과 이해하기
54.머신러닝 학습 방식 총정리: Supervised vs Semi-Supervised vs Unsupervised
Machine Learning 필수 개념: 지도 학습, 반지도 학습, 비지도 학습 완벽 이해
55.반지도 학습 (Semi-Supervised Learning) 정리: 핵심 전략 & 대표 기법
라벨 부족 시대의 해결책: 반지도 학습 핵심 기법들
56.GPT는 어떻게 학습하나요? Loss 함수부터 이해하기
언어 모델이 다음 단어를 예측하는 수학적 원리
57.[GTP-1] 언어모델 손실 함수의 비밀: 지도학습 + 언어모델링을 함께 쓰는 이유
언어모델, 손실 함수 두 개 써도 될까?
58.GPT 손실 함수 완전 분석: GPT-1부터 GPT-4까지
GPT에서 Supervised Loss는 사라졌을까?
59.BERT, GPT 필수! Delimiter Token 정리
Delimiter Token 완전 정리 — Transformer 모델 핵심 토큰
60.BERT와 GPT의 숨은 비밀, Segment Embedding 쉽게 이해하기
Segment Embedding 완벽 이해: 문장 관계를 아는 Transformer의 비밀
61.Fine-tuning의 모든 것: 전략별 차이점과 선택 기준 정리
Fine-tuning의 대표적인 5가지 방법을 소개합니다.
62.GPT-1 직접 학습해보기: GPU 사양부터 학습 시간까지 현실 가이드
GPT-1 모델을 직접 학습해보려면? 필요한 GPU 사양과 학습 시간 총정리!
63.GPT-1/2/3 모델을 학습하려면 GPU가 몇 개나 필요할까? 현실 자원 총정리
GPT-3 이상의 초거대 언어모델, 왜 GPU가 수천 개나 필요할까?
64.딥러닝에서 GPU 메모리는 무엇을 저장할까? 학습 vs 추론 VRAM 완전 정복
딥러닝에서 GPU 메모리(VRAM)는 무엇을 저장할까?
65.Learning Rate 완전 정복! 딥러닝 학습률의 모든 것
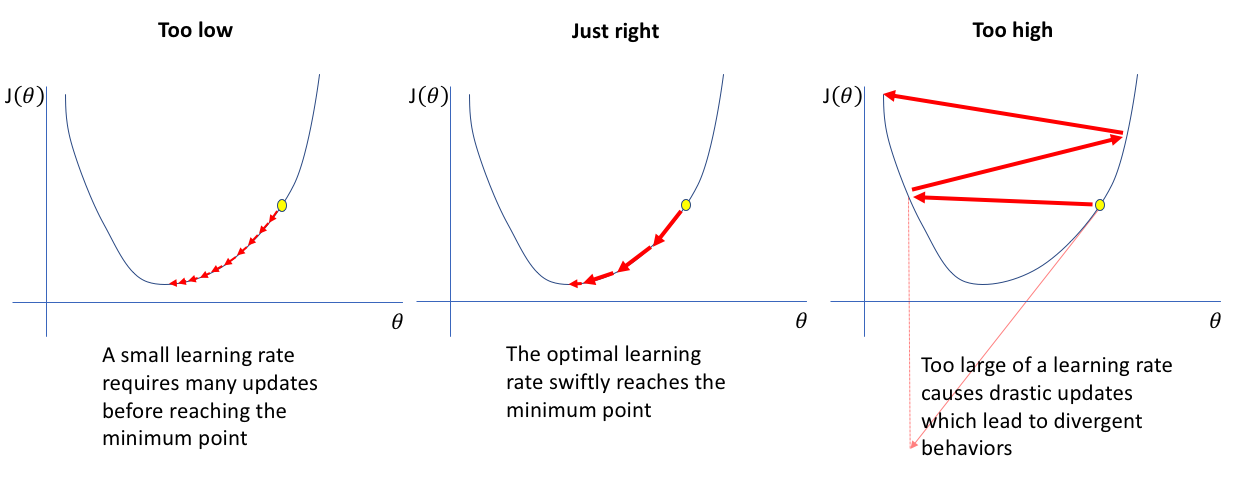
Learning Rate 완전 정복!
66.GPU vs TPU 완전 정리: 딥러닝에 어떤 프로세서를 써야 할까?
개념, 장단점, 쓰임새까지 한 번에 이해하기
67.AI는 GPU가 먹여 살린다: 글로벌 기업과 국가의 GPU 확보 전쟁
GPT-4 시대, 수만 개 GPU가 경쟁력이다
68.A100, H100, RTX 4090 완전 비교! AI용 GPU, 어떤 게 다를까?
딥러닝용 GPU의 VRAM, 아키텍처, 용도, 가격까지 한눈에 총정리!
69.딥러닝 속도·메모리 최적화의 핵심! Automatic Mixed Precision(AMP) 정리
AMP는 32비트(float32)와 16비트(float16) 연산을 자동으로 섞어서 수행하는 기술입니다.
70.딥러닝 파라미터 수 이해하기: Linear와 Conv로 예시로 설명
딥러닝 파라미터 수, 어떻게 계산할까?
71.입력값에 역전파를? 적대적 공격의 핵심 메커니즘
딥러닝을 속이는 간단한 수식: FGSM과 sign()의 비밀
72.적대적 이미지란? 딥러닝을 속이는 공격과 방어의 모든 것
사람은 못 보고, AI는 속는다: 적대적 공격 완전 정복
73.신경망이 비선형이어야 하는 이유: 표현력을 풍부하게 만드는 핵심
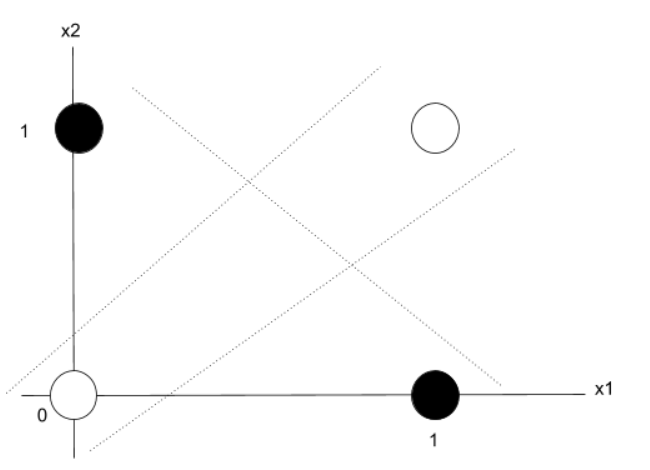
신경망의 표현력, 왜 '비선형'이 핵심인가?
74.Zero-shot, One-shot, Few-shot이 뭐야? | 프롬프트 토큰까지 한 번에 이해하기
프롬프트에 예제를 몇 개 보여주느냐에 따라 달라지는 모델의 추론 방식과 입력 토큰의 길이
75.GPT는 왜 멀티태스크처럼 동작할까? — ‘출력 통일성’에 숨겨진 비밀
하나의 모델로 번역부터 감정 분석까지, 프롬프트만 바꾸면 가능한 이유와 그 한계
76.자연어의 본질, 조건부 확률로 풀어보기
GPT는 어떻게 문장을 이해하고 생성할까? 언어의 순차성과 조건부 확률을 연결해보면, 언어 모델의 핵심 원리가 보입니다.
77.모든 작업은 텍스트다: GPT의 통합 학습 방식 이해하기
자연어로 모든 태스크를 통일하는 GPT의 사고방식
78.GPT의 진화: 단순한 언어 모델에서 범용 AI로
GPT는 어떻게 지시 없이도 작업을 처리할 수 있을까?
79.사람처럼 대답하는 AI의 비밀: RLHF란 무엇인가?
GPT가 지시를 이해하고 더 나은 답변을 생성하는 비결, ‘사람의 피드백’에서 찾다
80.LLM에서 Reasoning(추론)이란 무엇인가?
GPT는 단순한 문장 생성기를 넘어서, 이제 "생각할 수 있는" 언어모델이 되었습니다
81.유니코드와 UTF-8, 그리고 GPT의 토크나이저가 바이트를 다루는 법
UTF-8은 왜 바이트는 256개뿐인데 유니코드를 다 표현할 수 있을까?
82.GPT는 왜 바이트부터 시작할까? 유니코드 기반 토크나이저와의 비교
BPE 토크나이저, 문자 기반 vs 바이트 기반 완벽 정리
83.GPT에서는 왜 한글이 깨질까?
바이트 기반 토크나이저의 한계와 Google Gemini와의 차이
84.딥러닝의 시작은 ‘가중치 초기화’부터! GPT는 왜 1/√N으로 초기화했을까?
Transformer에서 안정적인 학습을 위한 핵심 전략: 잔차 연결과 가중치 스케일링
85.Residual Connection 완전 정복: ResNet vs GPT 차이점은?
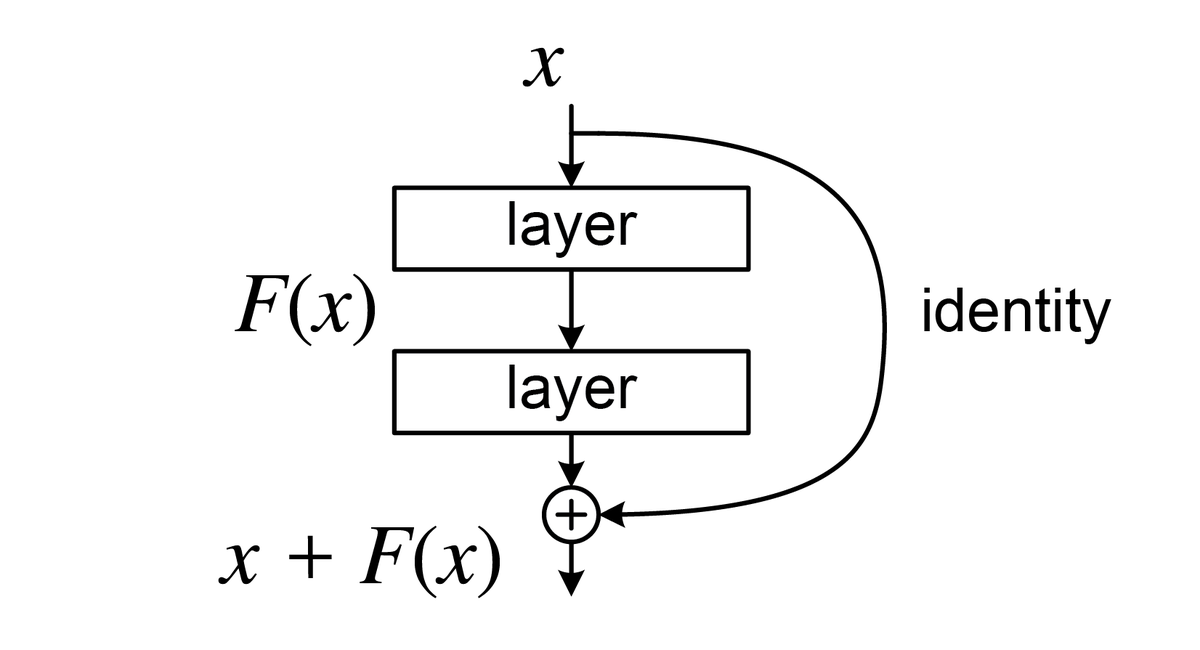
CNN과 Transformer가 모두 선택한 기술, 왜 그럴까?
86.Pointer Network, GPT, BERT: 구조와 용도 완벽 비교
NLP에서 ‘어떻게 읽고, 어떻게 답할 것인가’를 결정하는 세 가지 구조
87.딥러닝 양자화 완전 정복: Static Quantization, Dynamic Quantization, QAT까지 한 번에 이해하기
모델 경량화 시대, 우리가 알아야 할 양자화 개념 총정리
88.정적 vs 동적 양자화: 모델 용량 차이의 원인
PyTorch 양자화가 모델 크기를 줄이는 진짜 이유
89.PyTorch 2.7 양자화 완벽 정리: 모델은 어떻게 저장되고 동작할까?
Static vs Dynamic Quantization, int8 연산의 실제 흐름과 저장 방식까지!
90.양자화 모델, 어디서 쓰면 좋을까? — QNNPACK과 런타임 엔진까지 완전 정복
"양자화는 좋다는데... 어디서 진짜 효과를 보나요?" 이 글에서는 양자화 모델의 실제 적용 환경, 그리고 QNNPACK/XNNPACK과 같은 엔진의 역할까지 정리해드립니다.
91.특정 Libtorch version에서 양자화 모델이 동작하지 않는 이유는?
CPU 차이? 백엔드 설정? Fallback 제거? 한 번에 정리해드립니다
92.양자화에서의 Activation, Weight, Bias 차이와 역할
딥러닝에서 양자화(Quantization)는 float32 모델을 **메모리 효율적이고 연산이 빠른 정수(int8) 기반 모델**로 바꾸는 기술입니다. 이
93.Gemini, Perplexity, 그리고 RAG – 생성형 AI의 진화
LLM + RAG = 정확하고 신뢰할 수 있는 AI 대화의 미래
94.Gemini Flash, GPT-4o Mini, Claude 3.5 Sonnet 비교 분석: 속도, 가격, 용도별 장단점 총정리!
Gemini Flash vs GPT-4o Mini vs Claude 3.5 Sonnet: 최적의 선택은?
95.AI 코딩 도구 완벽 가이드: Cursor vs Copilot 비교 분석
AI 코딩 도구 완벽 가이드: Cursor vs Copilot 비교 분석
96.2025년 AI 코딩 도구 완벽 가이드: 모델별 비교와 최적 선택법 (ChatGPT, Gemini, Claud)
ChatGPT vs Gemini vs Claude - 상황별 최적 모델 선택 전략
97.Latent Vector vs Embedding Vector: 차이와 개념 한눈에 정리
머신러닝의 핵심인 잠재 벡터(Latent Vector)와 임베딩 벡터(Embedding Vector), 그 의미와 차이점을 명확하게 알아봅니다.
98.PyTorch JIT와 TorchScript 완전 정복: 성능 최적화와 배포까지
PyTorch의 동적 그래프 유연성은 유지하면서도, 성능과 배포 효율성을 챙기는 방법? 정답은 바로 JIT(Just-In-Time) 컴파일과 TorchScript입니다.
99.GRPO와 DeepSeek-R1: Critic 없는 LLM 강화학습 혁신
PPO의 진화, 그리고 LLM의 자가 학습 시대
100.Transformer 구조 및 Cross-Attention 개념 정리
Self-Attention, Encoder-Decoder, Cross-Attention의 관계부터
101.Transformer FFN 완전 정복
Position-wise MLP로 이해하는 Transformer의 핵심 구성
102.스케일 법칙이란?
모델 파라미터와 데이터 크기의 균형이 왜 중요한지, 스케일 법칙이 성립하는 조건과 실제 예시를 통해 명확히 이해해봅니다.
103.Dense vs Sparse 모델 완전 정리: 연산, 메모리, 최적화까지 한눈에 비교
딥러닝/머신러닝 모델은 그 연산 구조와 파라미터 표현 방식에 따라 크게 Dense Model(조밀 모델)과 Sparse Model(희소 모델)로 나눌 수 있습니다.
104.Adam 최적화 완전 정복: Adaptive Learning Rate의 핵심 원리
모멘텀부터 RMSProp까지, 왜 Adam이 딥러닝의 대표 최적화 알고리즘인지 제대로 이해해보자
105.float16 연산 최적화: CUDA, MPS, CoreML 환경에서의 실전 가이드
딥러닝 성능과 효율성을 극대화하는 정밀도 전략
106.Transformer 모델 경량화와 VRAM 소모량
파라미터 수, 활성화 값, KV 캐시가 만드는 VRAM 사용량
107.LLM 추론 비용 구조 완벽 이해: 인풋과 아웃풋은 왜 다르게 과금될까?
GPU 연산, KV 캐시, 병렬 처리 효율로 풀어보는 LLM 요금의 비밀
108.한 GPU로 여러 딥러닝 모델 동시 학습 시 CPU 과부하 해결 가이드
멀티태스킹 환경에서 num_workers, 배치 사이즈, 그리고 리소스 제어 전략
109.지식 증류(Knowledge Distillation) 쉽게 이해하기
Teacher 모델에서 Student 모델로 지식을 전달하는 방법
110.PyTorch에서 다른 모델 구조 간 Weight 불러오기 방법
예시로 보는 `state_dict` 활용 전략
111.AWS Inferentia 완벽 가이드: PyTorch 모델로 고성능 AI 추론 서비스 구축하기
딥러닝 모델 배포 비용 걱정 끝! Inferentia 도입 가이드
112.Task-agnostic이란? 범용성을 가진 딥러닝 전략 이해하기
Task-agnostic의 정의와 기본 개념
113.Process Reward Model(PRM): 결과가 아닌 과정에 보상을 주는 학습
Process Reward Model(PRM): 과정에 보상을 주는 새로운 학습 패러다임
114.Monte Carlo Tree Search (MCTS): 게임 AI의 혁신을 이해하다
확률과 탐색의 만남, 알파고를 만든 핵심 알고리즘
115.Latent Diffusion Models (LDM) 설명: 효율적인 이미지 생성의 혁신
Diffusion의 핵심 개념과 3단계 파이프라인 설명
116.Claude 프롬프트 가이드라인: Anthropic 공식 문서 정리와 활용 팁
효과적인 프롬프트 구조 설계
117.Instruction Tuning vs Dense Fine-tuning: 차이와 DeepSeek-R1의 역할
사용자 친화형 학습 vs 추론 특화형 학습
118.Gemini 1.5 Pro 특징: 초장문맥과 멀티모달을 아우르는 AI 모델
1천만 토큰 문맥 길이 지원
119.AI 패러다임의 전환: 프롬프트 엔지니어링을 넘어선 컨텍스트 엔지니어링 시대
GPU와 NPU 발전이 가져온 AI 활용의 새로운 패러다임
120.왜 GPT-5는 GPT-4보다 느리게 느껴질까?
GPT-5 속도 저하의 기술적 원인과 해결 방법
121.딥러닝에서 Logit, Soft Probability, Hard Probability의 차이와 활용법
학습과 평가에서 왜 Soft Probability와 Hard Prediction을 구분해서 써야 할까?
122.Point Transformer의 핵심: Scalar Attention vs Vector Attention
채널 단위까지 조절하는 벡터 어텐션의 힘
123.“Homogeneous”란? — 신경망 구조에서 ‘균질성’을 이해하기
딥러닝에서 말하는 homogeneous 의 진짜 의미는?
124.Point-cloud 모델에서 MLP는 왜 Permutation Invariant할까?
점군(Point Cloud)에서 순서가 바뀌어도 결과가 변하지 않는 이유
125.Point cloud에서의 MLP — Point-wise인가, Channel-wise인가?
MLP가 점 단위로 작동한다는 의미를 깊이 이해하기
126.Anthropic의 헌법적 AI(Constitutional AI) 한눈에 보기
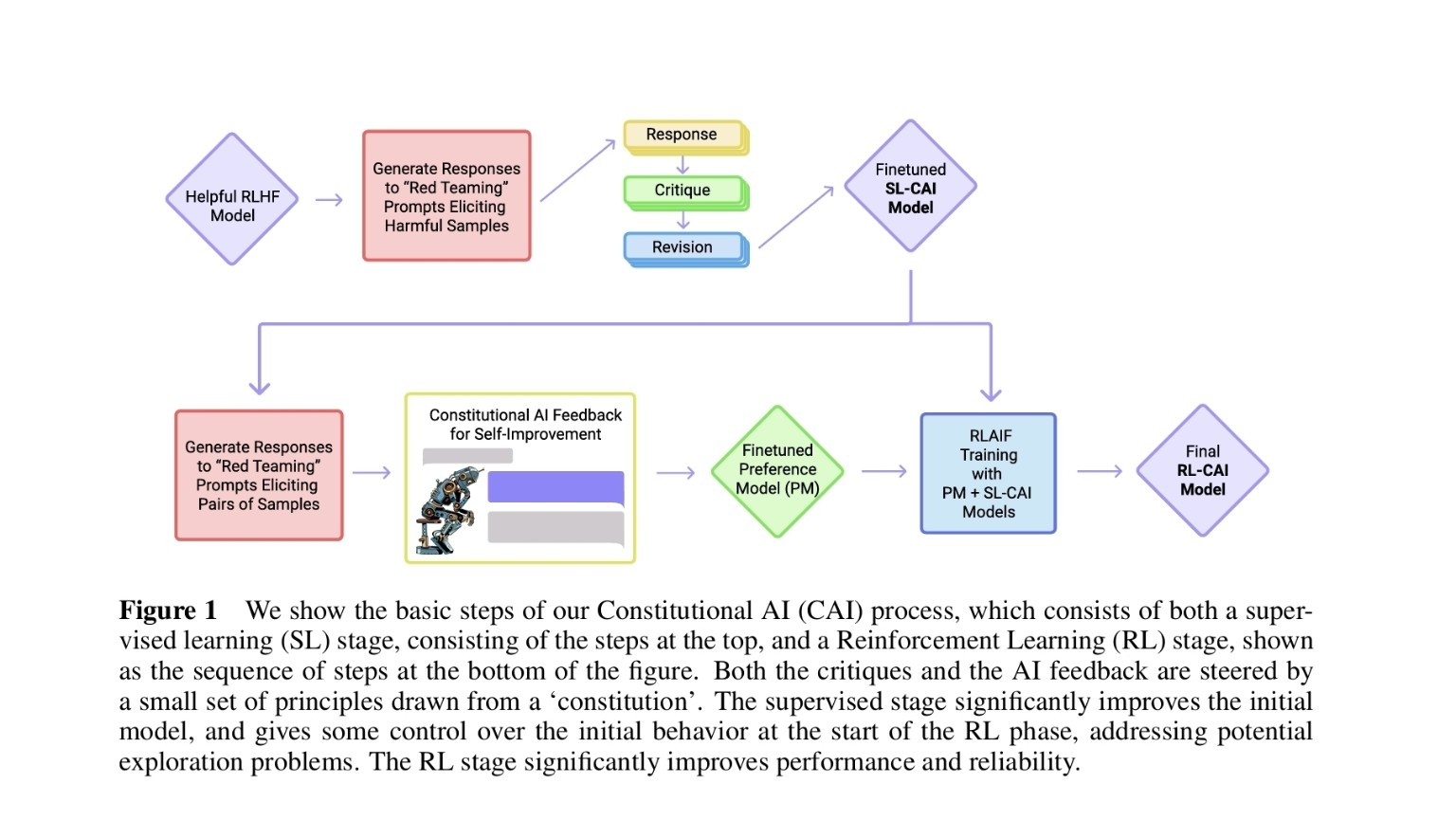
AI 스스로 비판하고 보상으로 학습한다: SL → Self-Critique → PM 기반 RLAIF로 이어지는 전 과정 해설
127.Anthropic의 헌법적 AI: “유용함과 무해함”의 균형
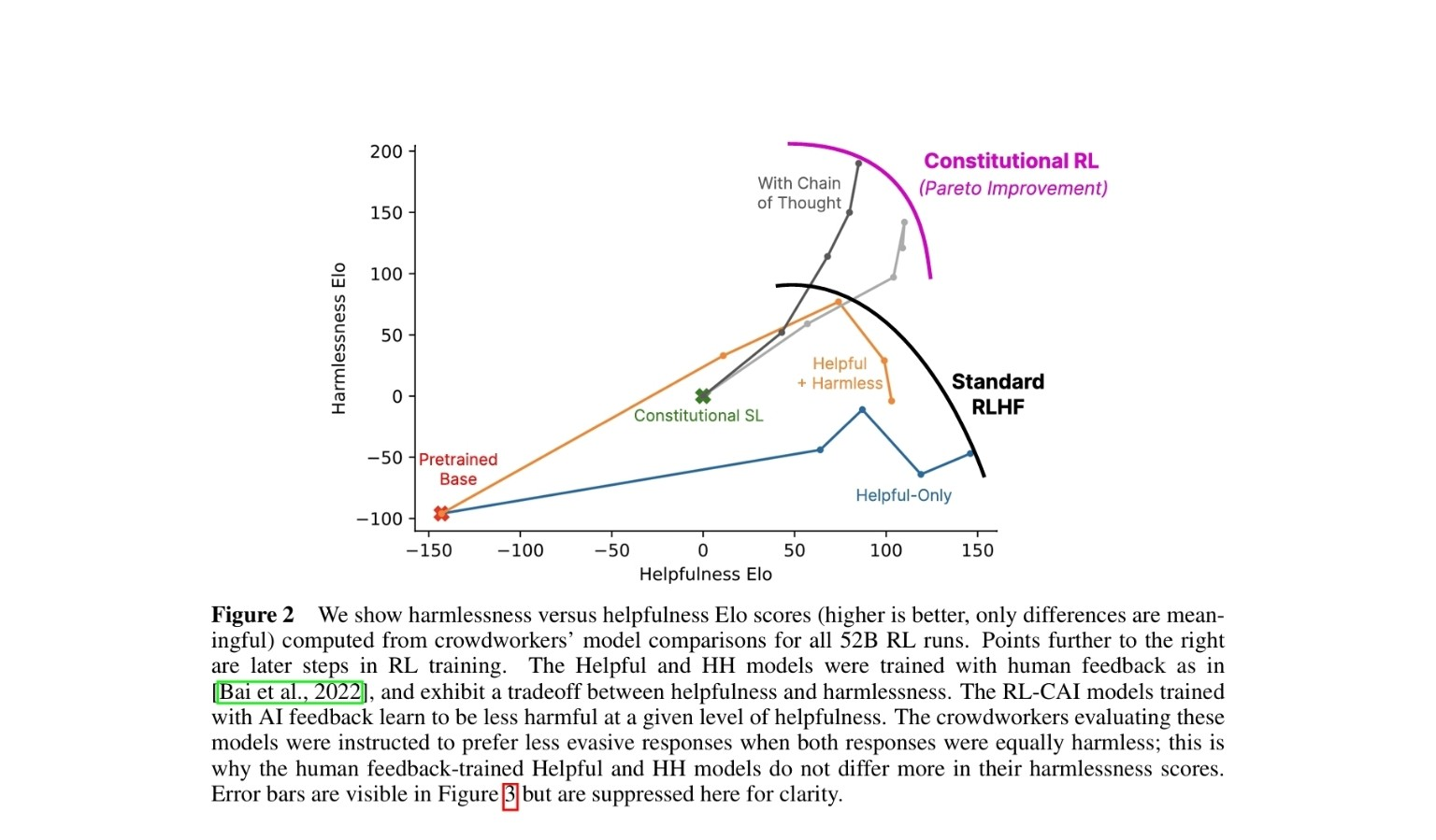
RLHF의 한계를 넘어, AI가 스스로 배우는 새로운 학습 패러다임
128.AI의 머릿속을 들여다보다 — Anthropic의 “Tracing Thoughts in Language Models”
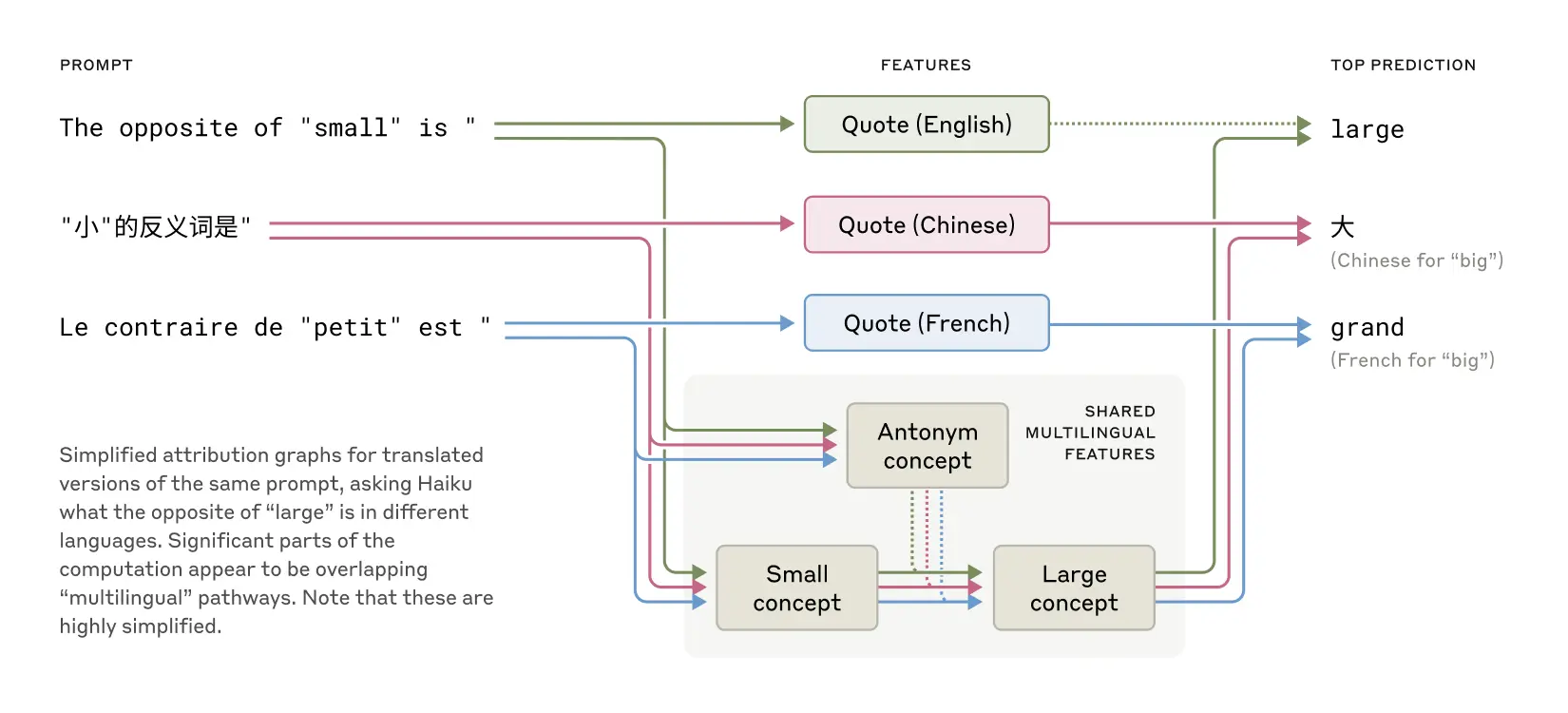
laude는 어떻게 생각할까? AI의 내부 사고 구조를 해부한 Anthropic의 혁신적 연구 요약
129.AI는 왜 ‘환각’을 일으킬까? ― Claude가 지어내는 이유와 그 내부 메커니즘
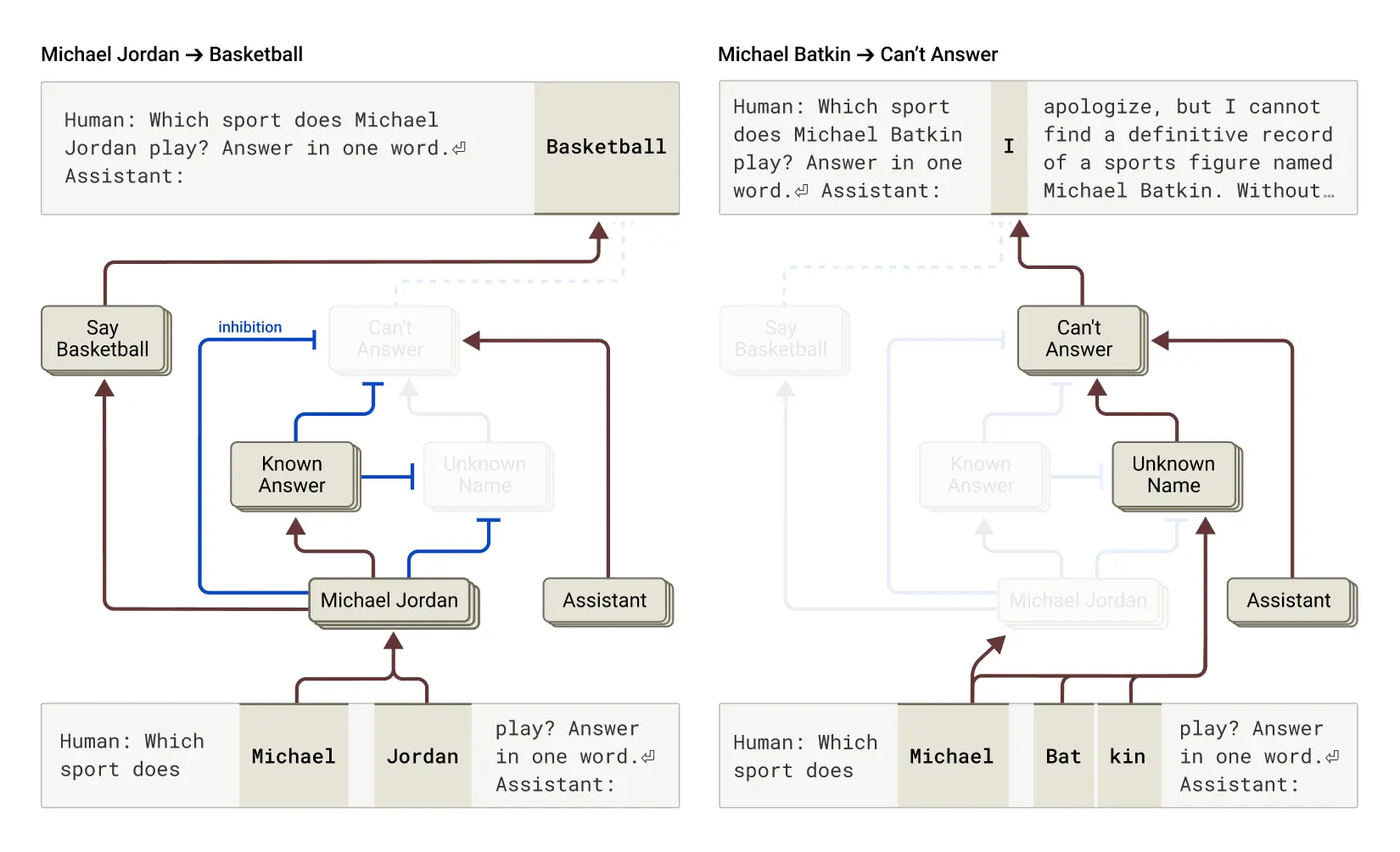
‘모른다’고 말해야 할 순간에 ‘안다’고 착각하는 인공지능의 뇌 속을 들여다보다
130.왜 LLM은 ‘Jailbreak’에 속아 위험한 문장을 내보낼까 — Claude 사례로 본 메커니즘

문법적 일관성, “방법 설명” 성향, 그리고 거부 기능의 충돌이 만드는 짧은 취약성의 순간
131.Claude 3 모델 패밀리: AI 지능의 새로운 기준을 세우다

부제: Opus, Sonnet, Haiku — 세 가지 모델로 본 Anthropic의 차세대 AI 전략
132.LLM의 창의성 조절기, Temperature란?
모델의 온도를 올리면 창의력이 올라간다?
133.LLM 비용을 줄이는 비밀: Prefix와 Prompt Caching 이해
“매번 같은 말을 반복할 필요가 있을까?” — LLM 효율화의 핵심 개념
134.“LangChain `max_concurrency` : 속도와 안정성을 동시에 잡는 병렬 처리 설정법”
동시에 몇 개까지 처리할까? 속도와 안정성의 균형 잡기
135.기울기 소실 (Vanishing Gradient): 왜 깊은 신경망이 학습을 못할까?
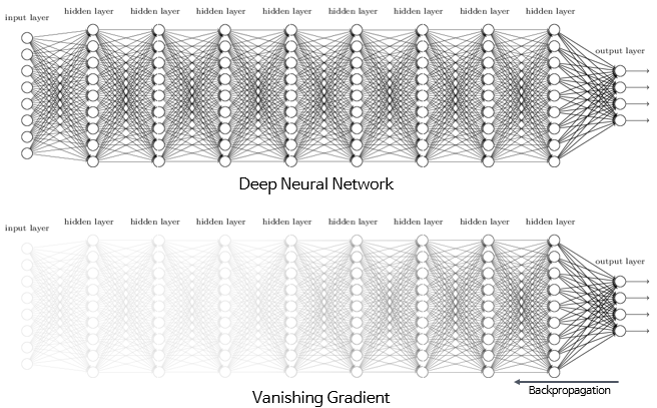
활성화 함수·역전파·잔차 연결까지 — 왜 깊은 신경망이 학습을 못 하는지, 그리고 어떻게 해결하는지 쉽게 정리합니다.
136.프롬프트 vs 컨텍스트: RAG를 이해하는 가장 쉬운 방법
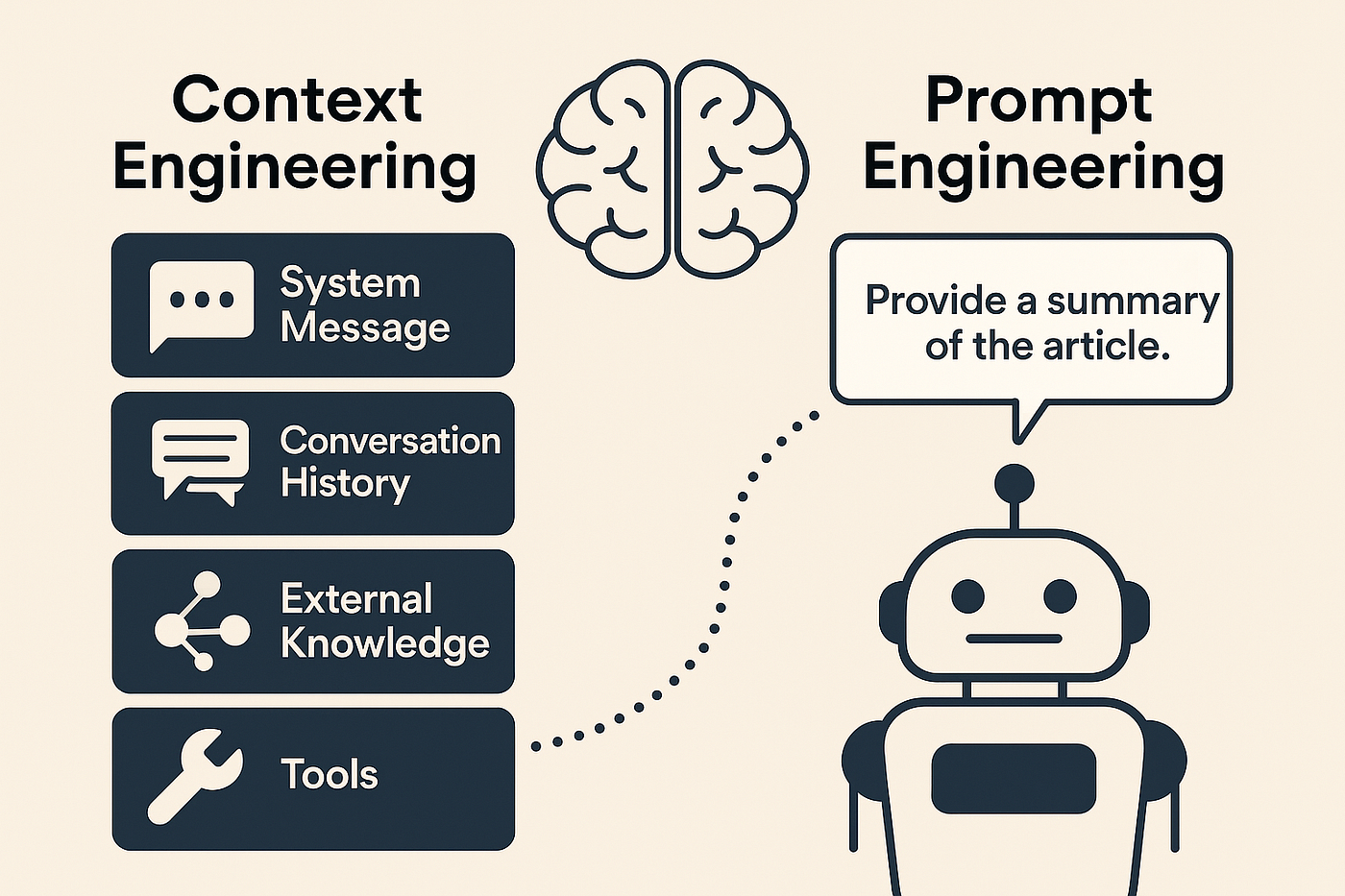
오픈북 시험 비유로 쉽게 풀어보는 RAG 입력 구조
137.LLM의 입력과 출력은 왜 가격이 다를까? (Prefill, KV 캐시, Auto regression)
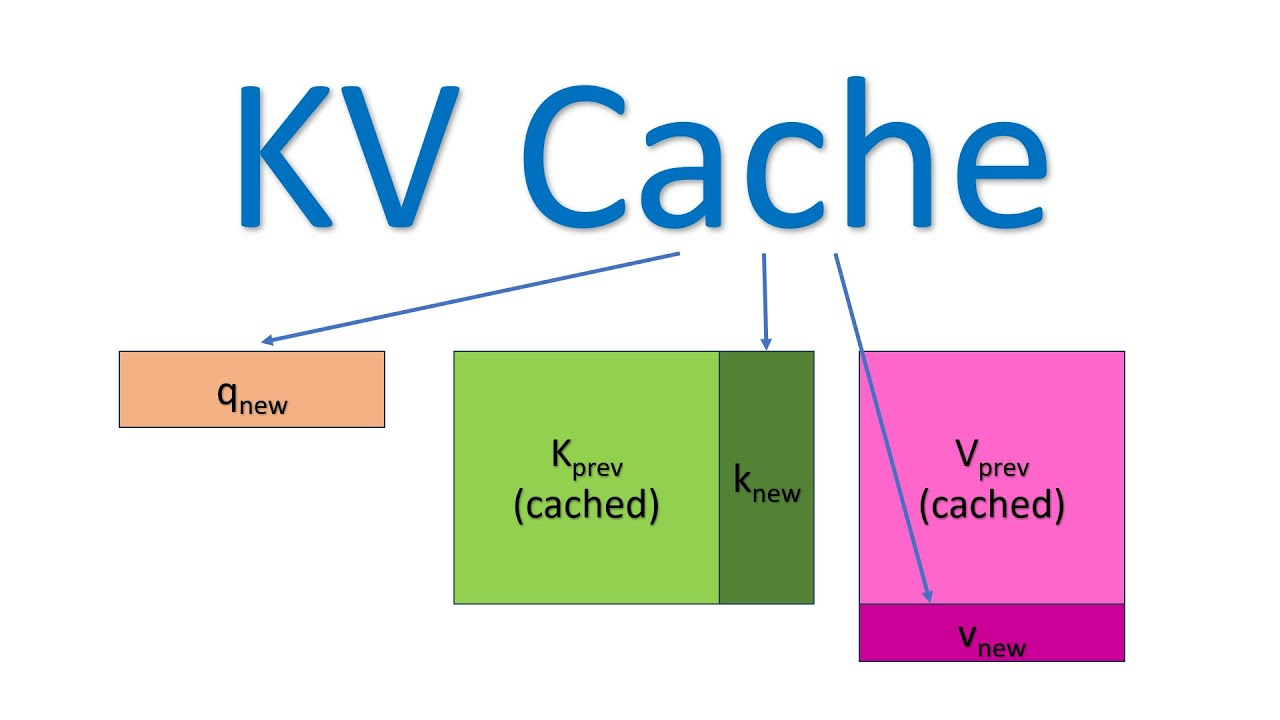
LLM의 비용 구조, 내부 동작, KV 캐시까지 한 번에 이해하는 가장 쉬운 설명
138.LLM 내부 해부: Prefill, Decoding과 QKV의 진짜 작동 원리
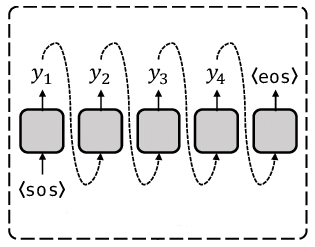
왜 Q는 버리고 K,V는 저장할까? LLM 구조 핵심 개념 정리
139.앙상블 모델을 늘려도 왜 속도는 그대로일까? AI 추론 최적화의 비밀
선형적으로 증가하지 않는 추론 시간의 원인과 TorchScript 병렬 처리의 오해와 진실
140.의료데이터 3D 생성에서 결정론적 모델과 확률론적 모델의 차이

정확도 중심 접근과 불확실성 기반 생성의 구조적 비교
141.High Frequency와 Spectral Bias로 이해하는 3D 형상 학습의 한계와 해법

왜 딥러닝은 미세한 변화를 어려워할까?
142.Cascaded Diffusion Models: 고해상도 이미지 생성을 가능하게 만든 결정적 설계
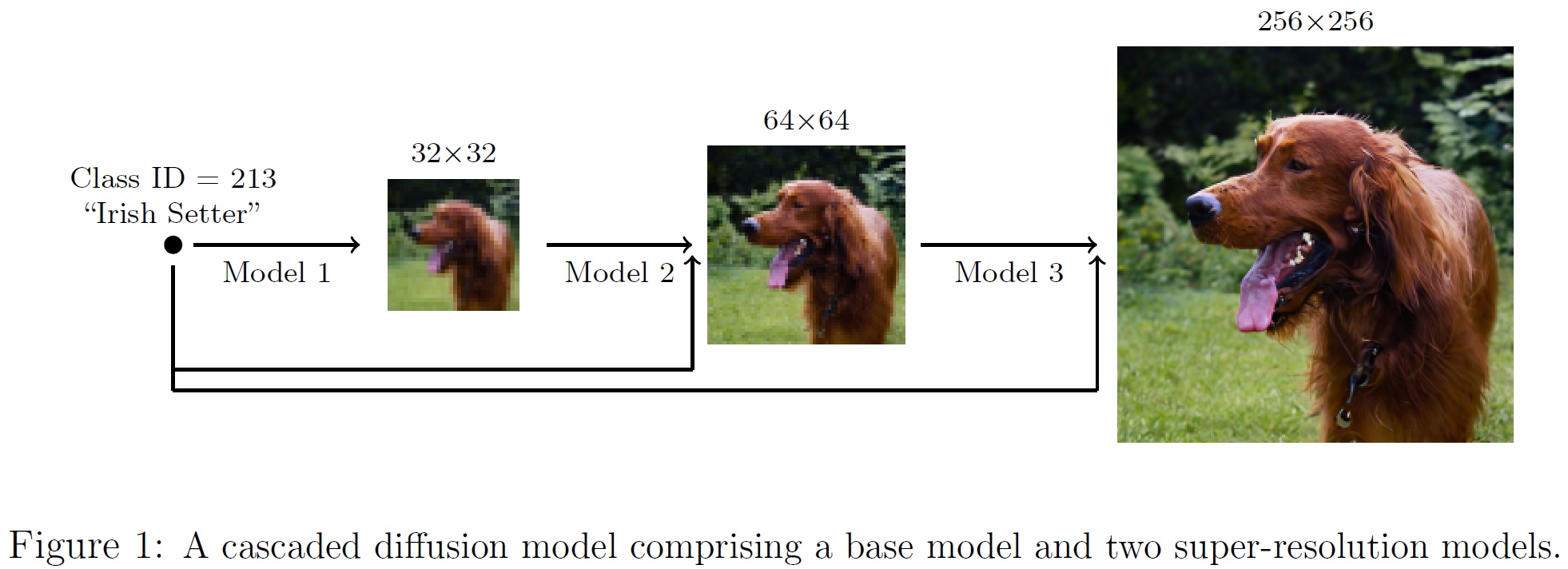
디퓨전 모델이 ‘한 번에’가 아니라 ‘단계적으로’ 진화한 이유
143.Latent Diffusion vs Cascaded Diffusion
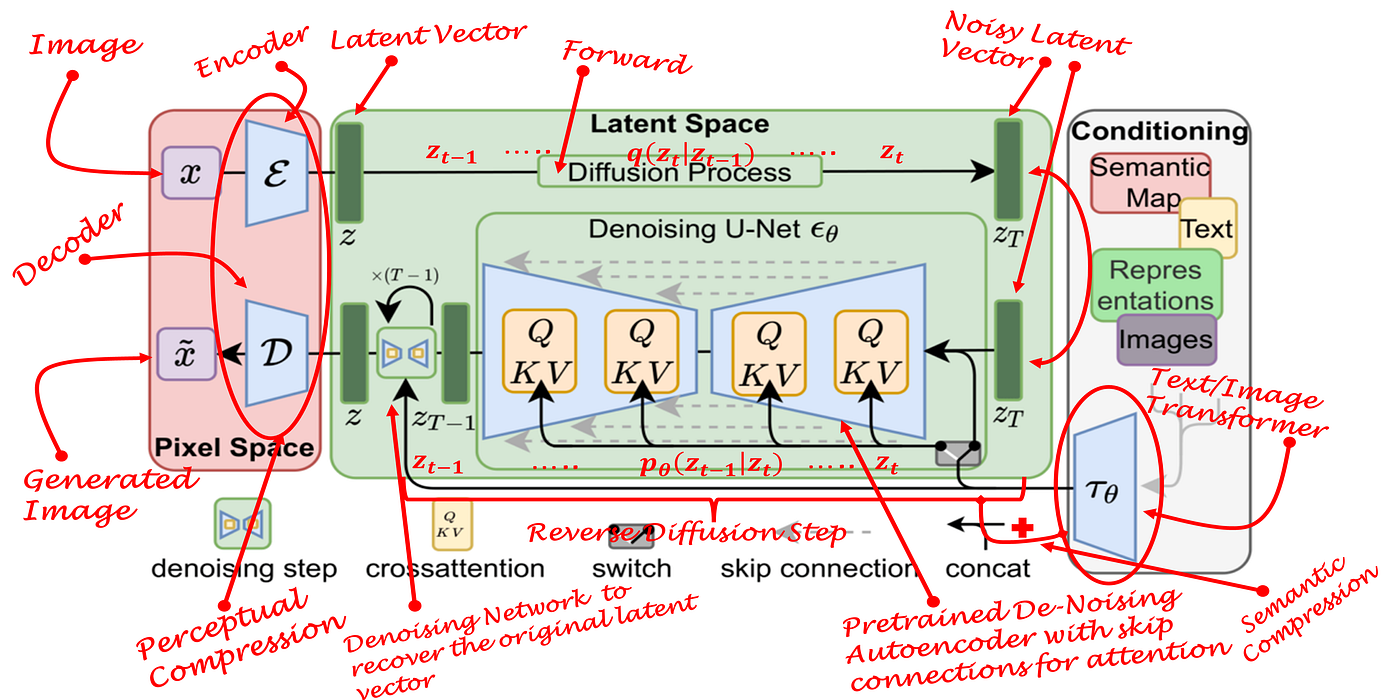
왜 어떤 모델은 빠르고, 어떤 모델은 끝까지 고화질을 고집할까
144.고해상도 이미지 생성(Cascade Diffusion)에는 U-Net이 쓰일까?
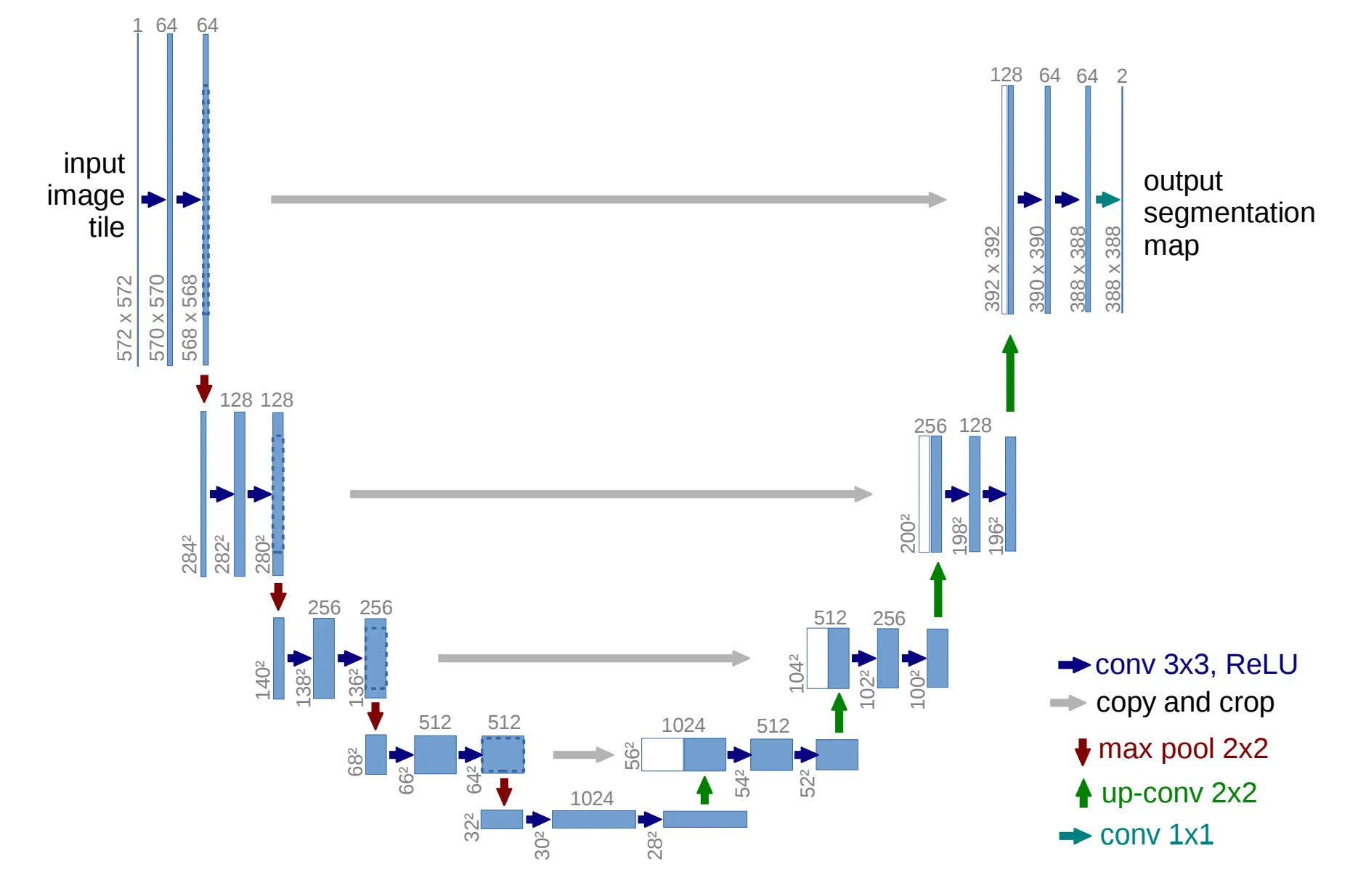
최신 이미지 생성 모델, 특히 Cascade Diffusion Model들이 공통적으로 채택하는 네트워크 구조가 있습니다. 바로 U-Net입니다.
145.고해상도 생성 모델 학습 전략: 노이즈 대신 '블러(Blur)'를 써야 하는 이유
추론 속도 10배 향상과 품질 개선을 위한 실전 최적화 가이드
146.Diffusion 모델이 '이미지'가 아니라 '노이즈'를 학습하는 진짜 이유
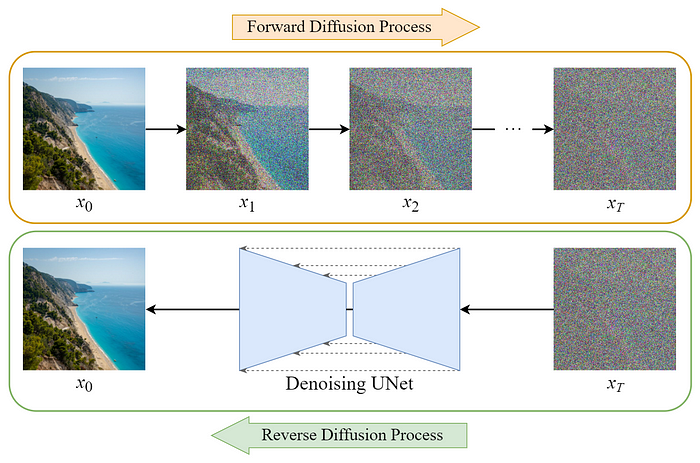
MSE Loss는 똑같은데, 정답지(Target)가 완전히 다르다?
147.최신 Diffusion 모델들이 Batch Norm을 버리고 Group Norm을 선택한 이유
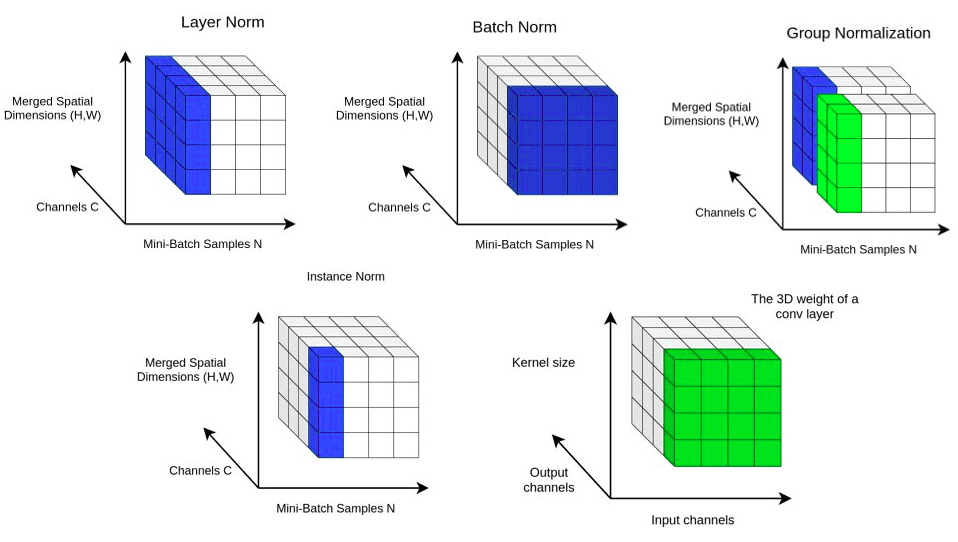
3D 데이터와 생성 모델에서의 Normalization 기법 설명
148. Diffusion 모델은 왜 원본을 망가뜨릴까? (Forward Process의 수학적 이해)
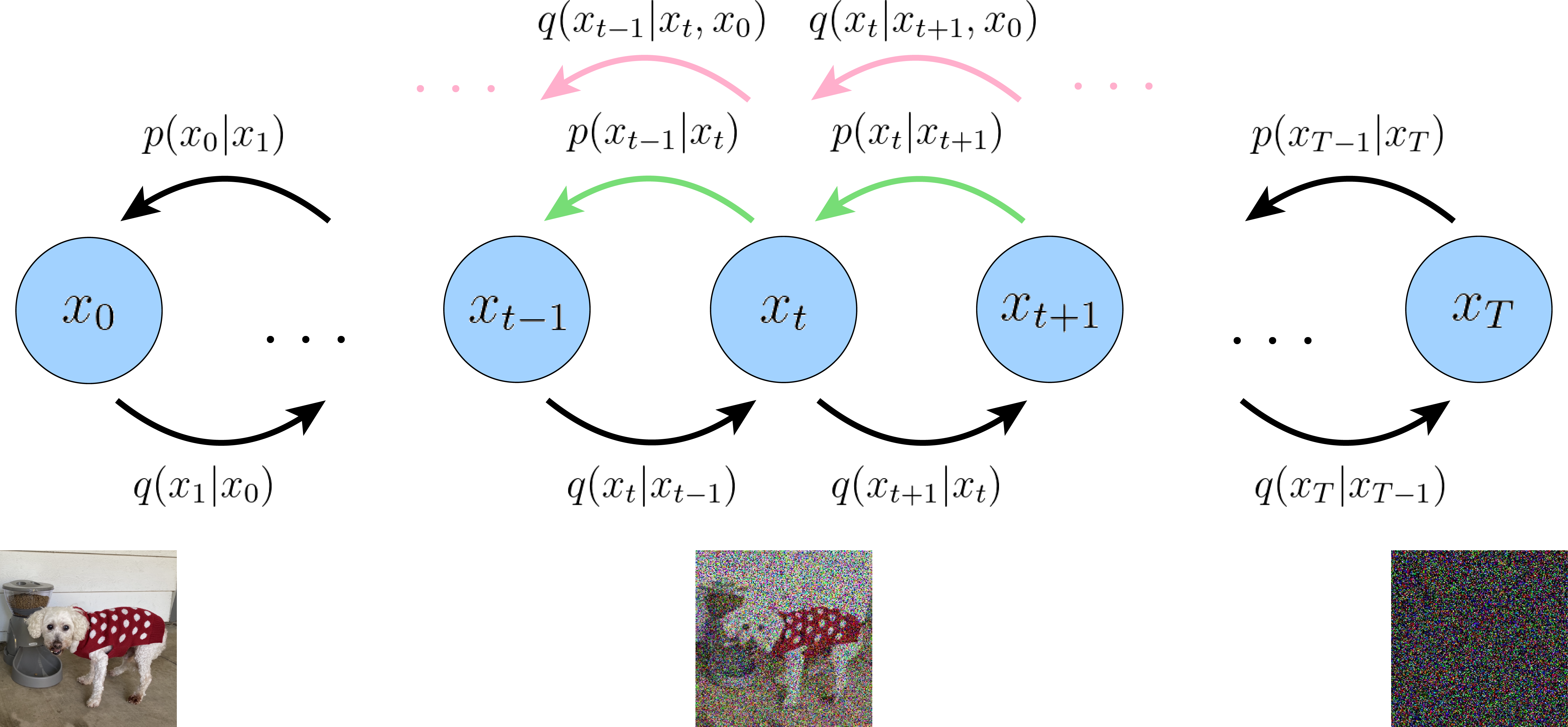
마르코프 체인부터 분산 보존을 위한 제곱근의 법칙까지, 수식 한 줄에 담긴 의미 풀이
149.마르코프 체인: "과거는 잊고 현재만 본다" (ft. Diffusion 모델의 진화)
개구리 점프 예시부터 DDPM vs DDIM의 결정적 차이까지 설명
150.과적합을 잡는 가장 세련된 방법, Weight Decay 설명
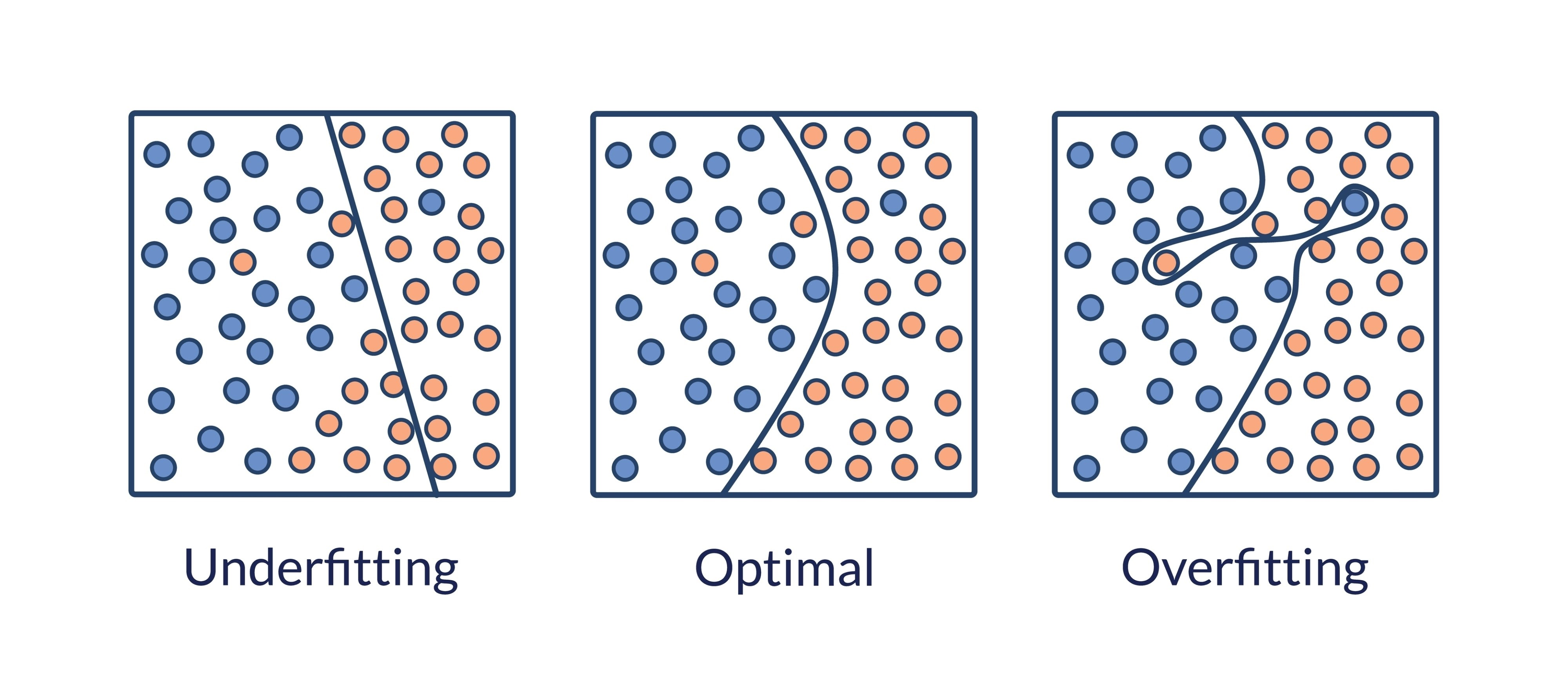
Weight Decay(가중치 감쇠)는 모델의 가중치가 너무 커지지 않도록 인위적으로 제약을 가하는 규제(Regularization) 기법입니다.
151.Positional Encoding: 딥러닝의 '디테일'을 놓치지 않기.
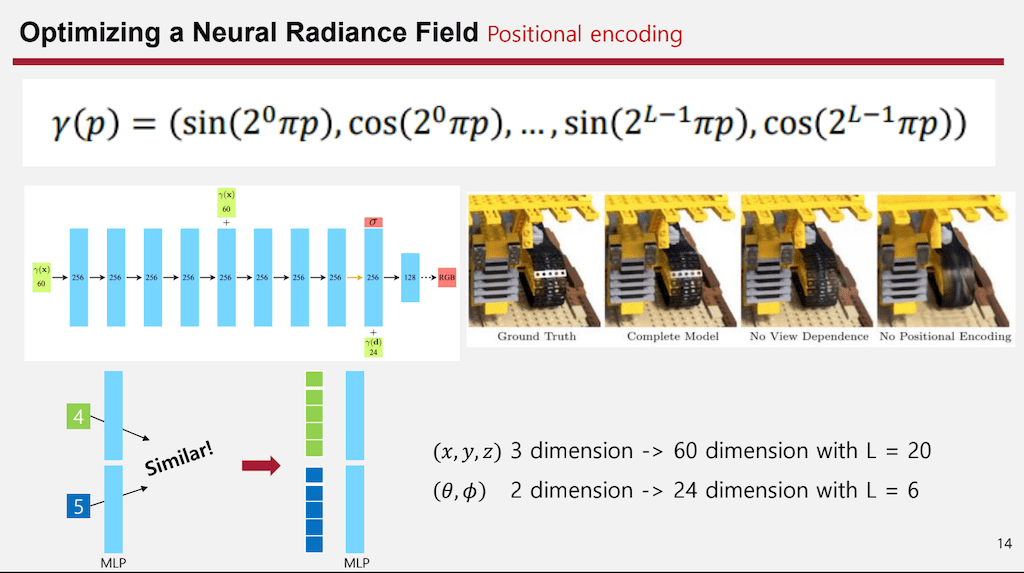
3D 비전이나 생성 모델(Generative Models)을 다루다 보면, 단순히 좌표값 $(x, y, z)$를 네트워크에 넣었을 때 결과물이 뭉개지거나 흐릿하게 나오는 현상을 자주 겪게 됩니다. 이때 마법 같은 해결책이 바로 **Positional Encoding**
152.AI 학습 한계를 넘는 열쇠: 웨이브릿 변환(Wavelet Transform) 활용 가이드
VRAM은 줄이고 정확도는 높이는 3차원 데이터 학습의 효율 극대화 전략
153.할루시네이션의 진짜 이유와 활용법: GPT, Gemini, Claude, Grok 내게 맞는 AI 모델은?

우리가 챗GPT나 제미나이 같은 생성형 AI를 사용할 때 가장 당황스러운 순간은 언제일까요? 바로 AI가 천연덕스럽게 **거짓말(Hallucination, 할루시네이션)**을 할 때입니다.
154.SDEdit: 디퓨전 모델로 실사와 의도를 동시에 잡는 법

SDEdit의 핵심은 사용자가 준 가이드(Guide)를 "얼마나 믿을 것인가(Faithfulness)"와 결과물이 "얼마나 진짜 같은가(Realism)" 사이의 황금 밸런스를 찾는 것입니다.
155.코딩은 끝났다? 아니, 이제 '진짜' 시작이다: 앤드류 응의 2026 개발자 생존법

AI 분야의 선구자, 앤드류 응(Andrew Ng) 교수가 최근 스탠포드 강의와 2026 다보스 포럼에서 던진 메시지가 화제입니다.
156.[CS229] 머신러닝의 뿌리, 선형 회귀 완벽 정복: 경사 하강법부터 정규 방정식까지

데이터 속 숨은 규칙을 찾는 가장 강력하고 기초적인 도구 이해하기
157.할리우드를 발칵 뒤집은 중국 AI의 무서운 질주: 씨댄스 2.0부터 딥시크 V4까지

미국의 강력한 규제 속에서도 글로벌 오픈소스 생태계를 장악해 나가는 중국 AI의 놀라운 현주소
158.U-Net의 시대는 끝났는가? Diffusion Transformer(DiT) 설명

이미지 생성 AI의 새로운 패러다임, 트랜스포머(Transformer)를 입은 디퓨전 모델
159.딥러닝 이미지 모델 완벽 비교: U-Net vs VAE, 무엇이 다를까?
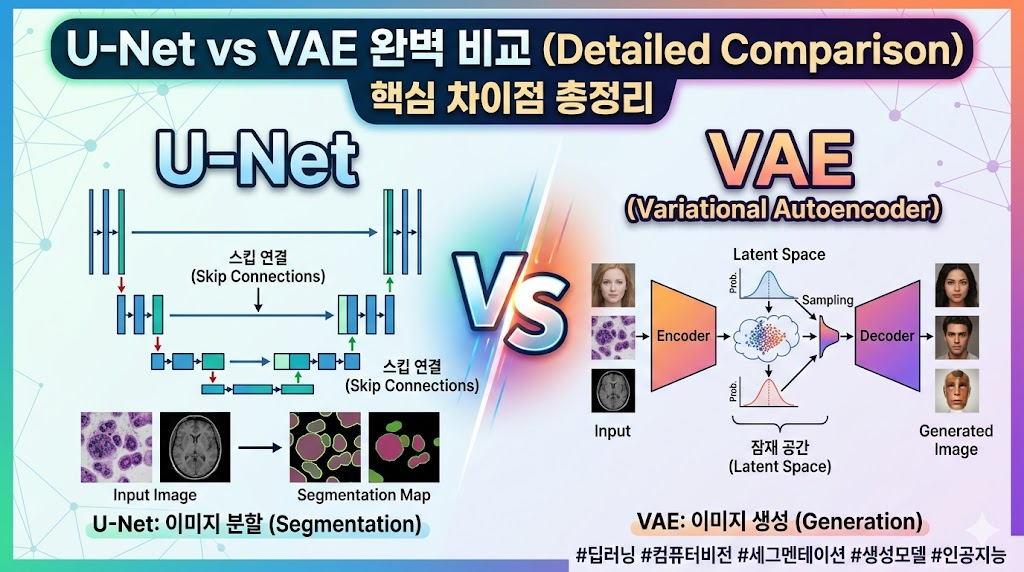
이미지 픽셀을 예측하는 U-Net과 새로운 이미지를 만들어내는 VAE의 원리와 핵심 차이점 알아보기
160.DiT vs U-Net: 이미지 생성 모델의 연산량과 효율성 역설
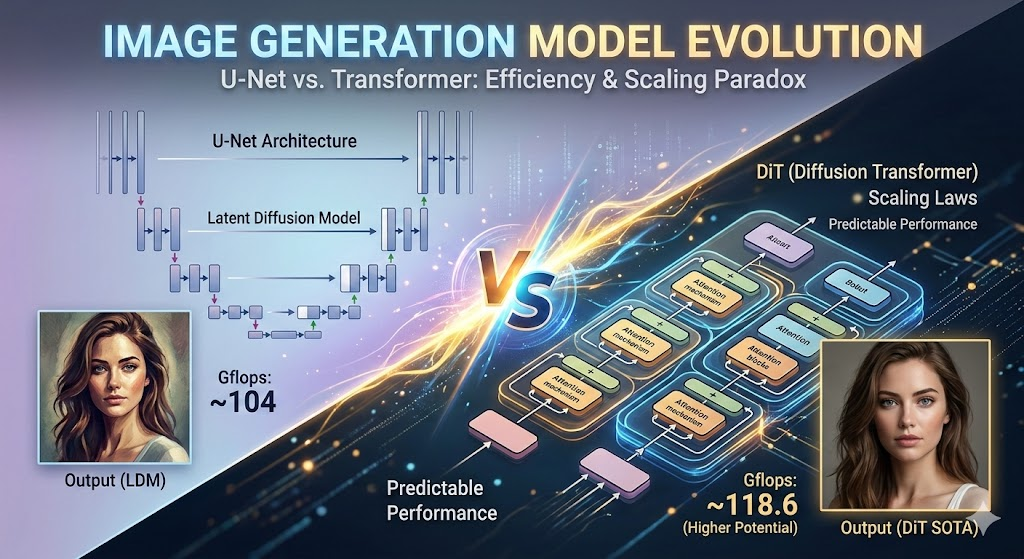
무거운 트랜스포머가 오히려 더 효율적인 이유와 주요 AI 서비스들의 현주소
161.확산 모델의 마법, Classifier-Free Guidance (CFG) 완벽 가이드

최근 Stable Diffusion, DALL-E 3, Midjourney 등 최신 AI 이미지 생성기들을 써보셨다면, 모델이 사용자의 프롬프트를 기가 막히게 잘 따르는 것을 보셨을 겁니다. 이 놀라운 결과물의 배경에는 Classifier-Free Guidance (C
162.Cross-Attention 완벽 이해: 오리지널 트랜스포머부터 DiT의 adaLN까지

Q, K, V는 각각 누가 만들까? 인코더-디코더 구조부터 확산 모델의 조건부 힌트 주입 원리까지 가장 직관적인 설명
163.DiT (Diffusion Transformer): adaLN-Zero 완벽 이해: '0'이 만들어낸 생성 AI의 최적화 학습

아무것도 안 함으로써 모든 것을 가능하게 만들다. 학습 안정성의 핵심인 Zero-initialization과 항등 함수의 시각적 비유 및 수학적 원리
164.DiT(Diffusion Transformer) 학습 방법: EMA (Exponential Moving Average)

새로운 딥러닝 아키텍처가 발표될 때마다 연구자들을 괴롭히는 것이 하나 있습니다. 바로 '하이퍼파라미터 튜닝'이죠. 성능을 쥐어짜내기 위해 학습률을 깎고, 웜업(Warmup) 스케줄을 조정하며 며칠 밤낮을 새우는 것이 일상입니다.하지만 DiT(Diffusion Trans
165.CNN과 Transformer의 완벽한 조화, 3D TransUNet 아키텍처 리뷰
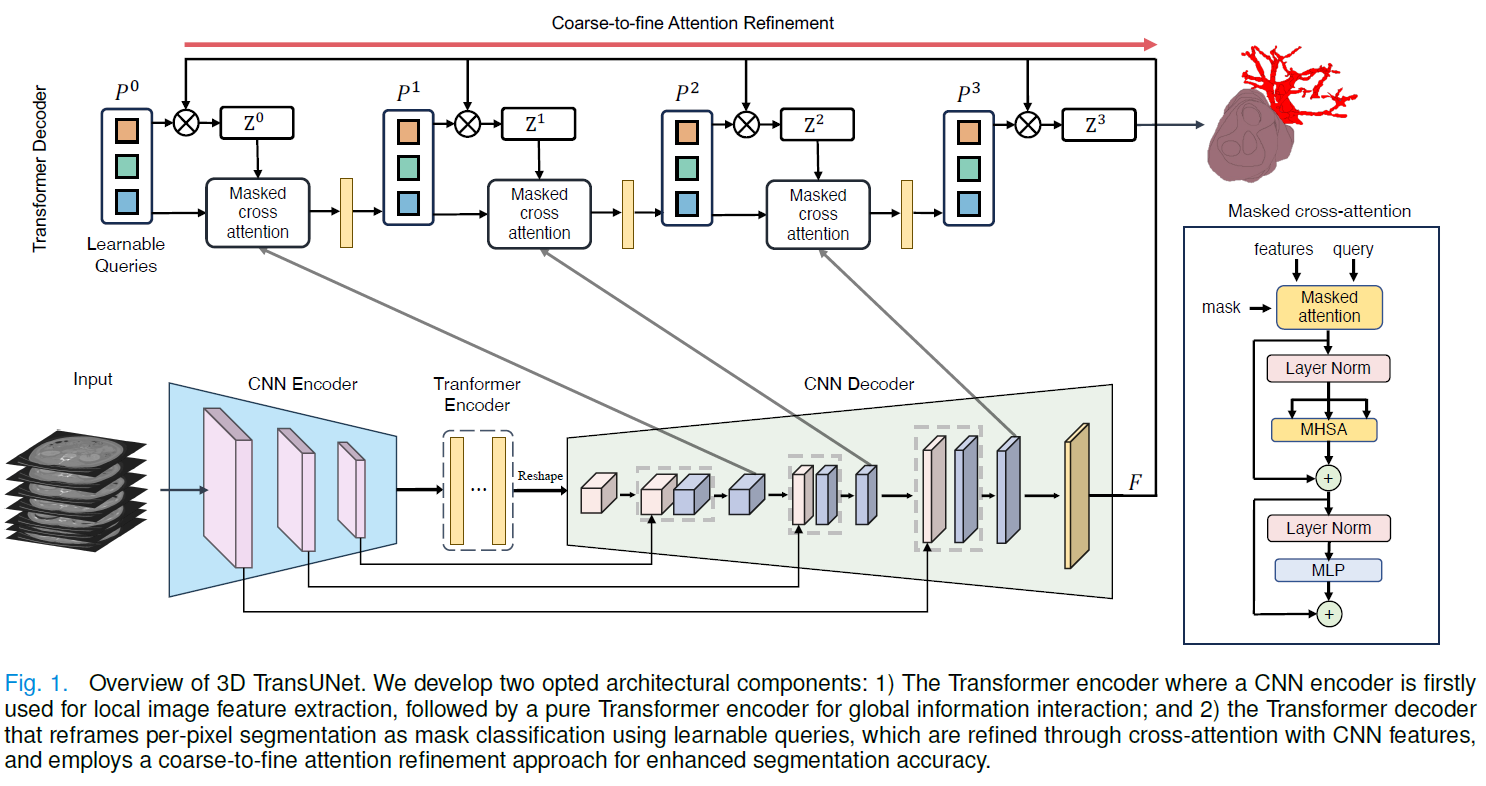
기존 U-Net의 국소성 한계를 극복하고 글로벌 컨텍스트와 정밀한 디테일을 모두 잡은 혁신적인 3D 의료 이미지 분할 모델을 소개합니다.
166.[PyTorch] 전이학습할 때 Optimizer 상태도 같이 불러와야 할까? (Weight vs Optimizer 로드)
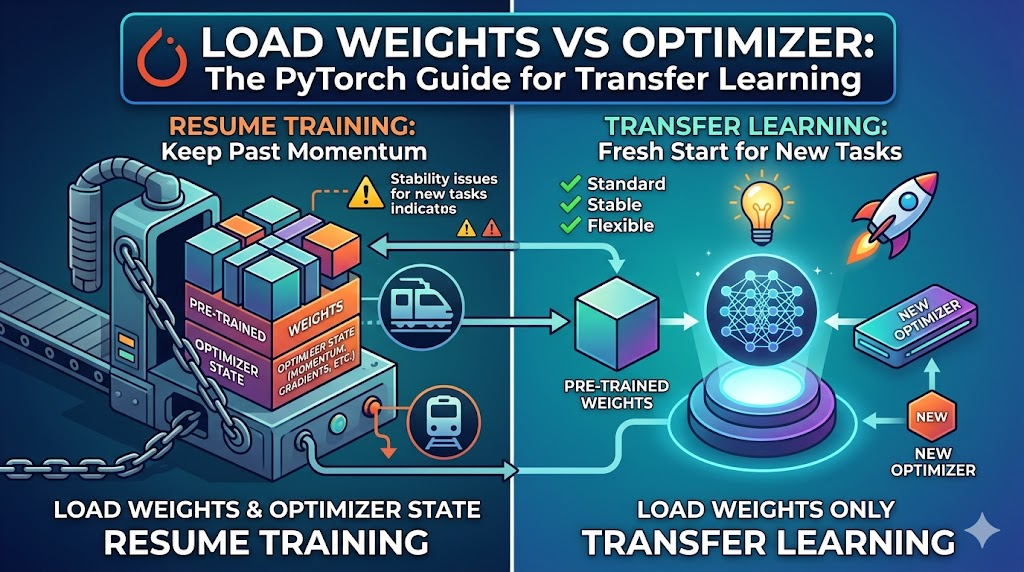
학습 재개(Resume Training)와 전이학습(Transfer Learning)의 차이점 및 올바른 모델 로드 방법
167.딥러닝 최적화를 위한 Learning Rate(학습률) 설정 가이드

고정할까, 줄일까? Transformer부터 DiT 모델까지 네트워크별 최적의 스케줄러 총정리
168.생성형 모델에서 Validation Loss가 튈 때 내리는 결단
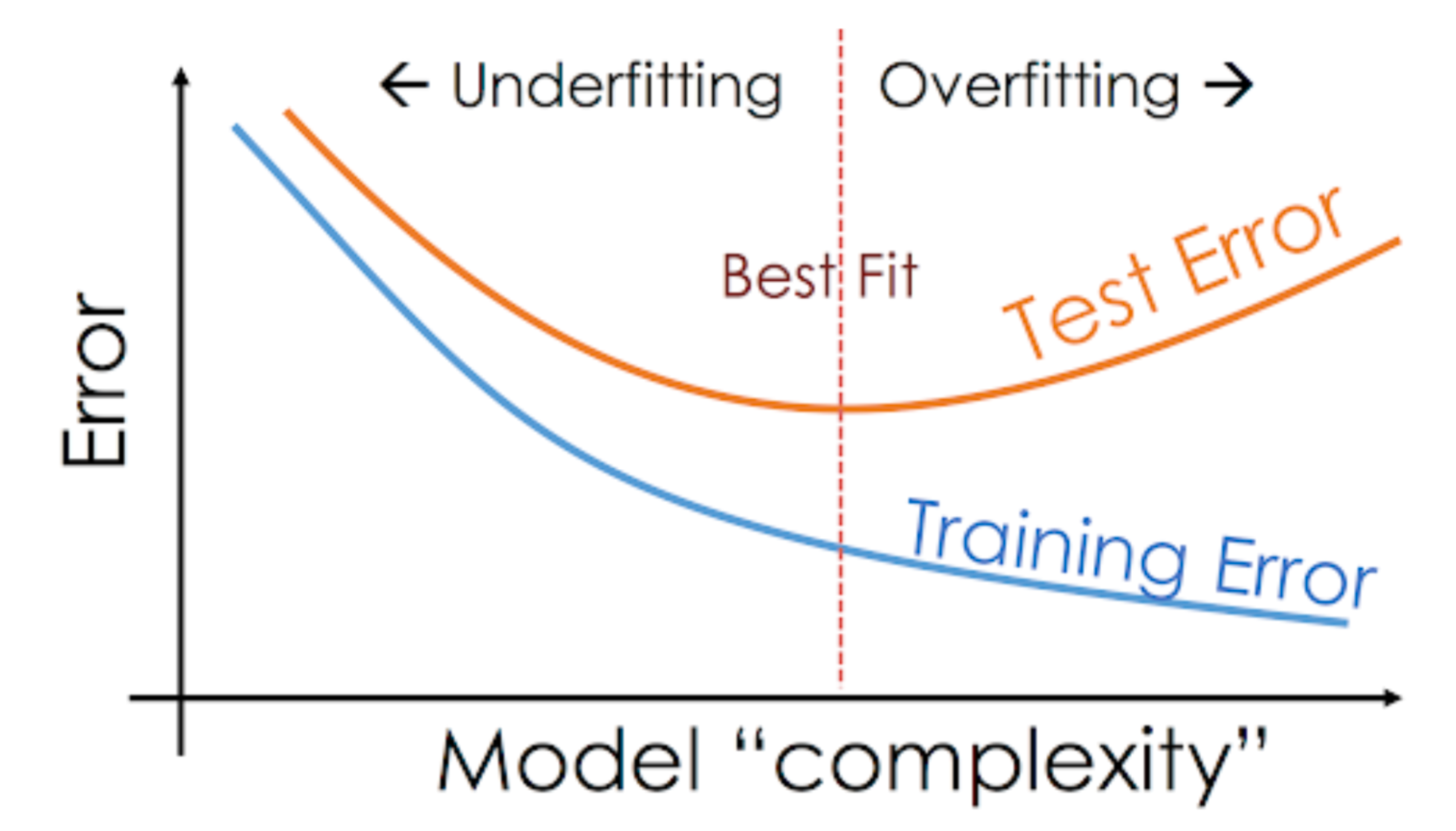
딥러닝 모델을 학습시키다 보면 누구나 한 번쯤 'U자형 곡선의 저주'를 만납니다. Training Loss는 바닥을 향해 예쁘게 내려가는데, 어느 순간 Validation Loss가 고개를 치켜들며 우상향하는 현상이죠.
169.생성형 AI 모델의 핵심 평가 지표: FID 스코어와 공분산 완벽 이해하기
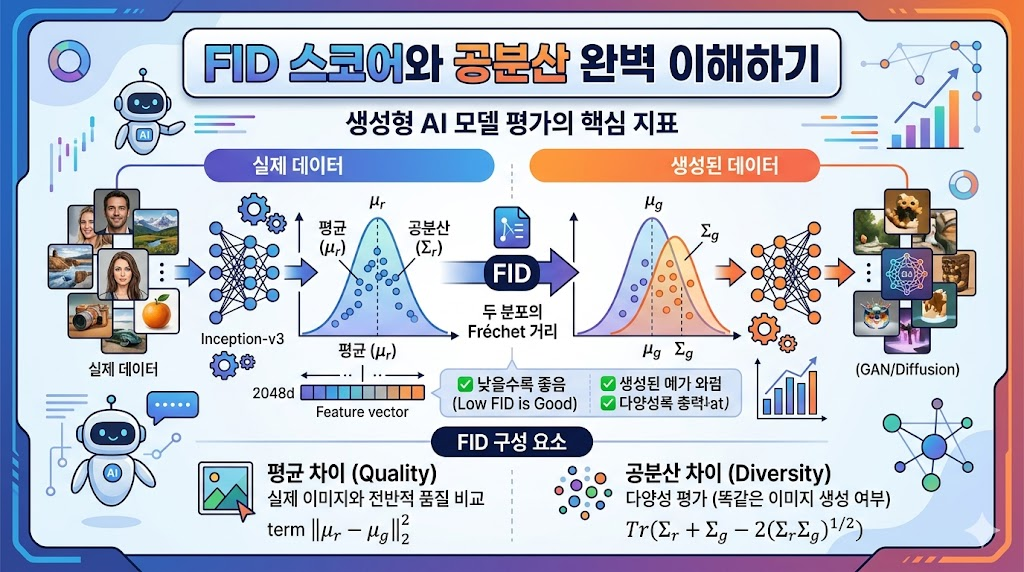
픽셀을 넘어 특징(Feature) 공간으로! 모델이 실제 세계를 얼마나 잘 흉내 내는지 숫자로 확인하는 방법
170.숲을 보는 트랜스포머, 나무를 보는 CNN: Local vs Global Feature 정리

컴퓨터 비전 논문에 매번 등장하는 핵심 개념, 직관적인 비유로 쉽게 이해하기
171.매개변수는 그대로, 성능은 극대화! Recurrent와 Residual의 시너지 (feat. R2U-Net)
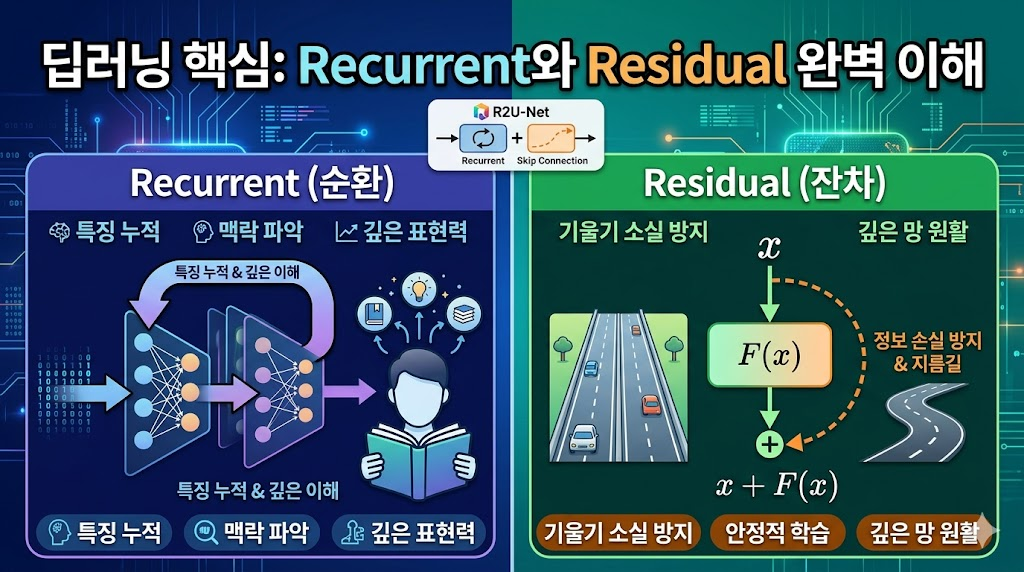
반복 누적을 통한 깊은 이해와 지름길을 통한 정보 손실 방지의 수학적 원리 알아보기
172.[의료영상 AI 개요] 딥러닝은 어떻게 의사의 눈이 되었나: 이미지 분류(Classification)에서 분할(Segmentation)까지

AlexNet에서 FCN까지, 픽셀 단위로 병변을 찾아내는 의료 AI의 진화 과정
173.모래사장에서 바늘 찾기: AI의 극단적 클래스 불균형을 해결하는 Dice Loss

99:1의 압도적인 데이터 불균형 상황에서 인공지능이 병변을 정확히 찾아내는 수학적 원리와 Cross-Entropy와의 완벽한 시너지
174.딥러닝이 이미지를 요약하는 방법: CNN 인코더의 특징 추출 원리

원은 줄이고 피처 맵은 늘리는 '공간적 압축과 특징 다각화'의 비밀**
175.딥러닝 초보자를 위한 분류(Classification) vs 분할(Segmentation) 완벽 가이드
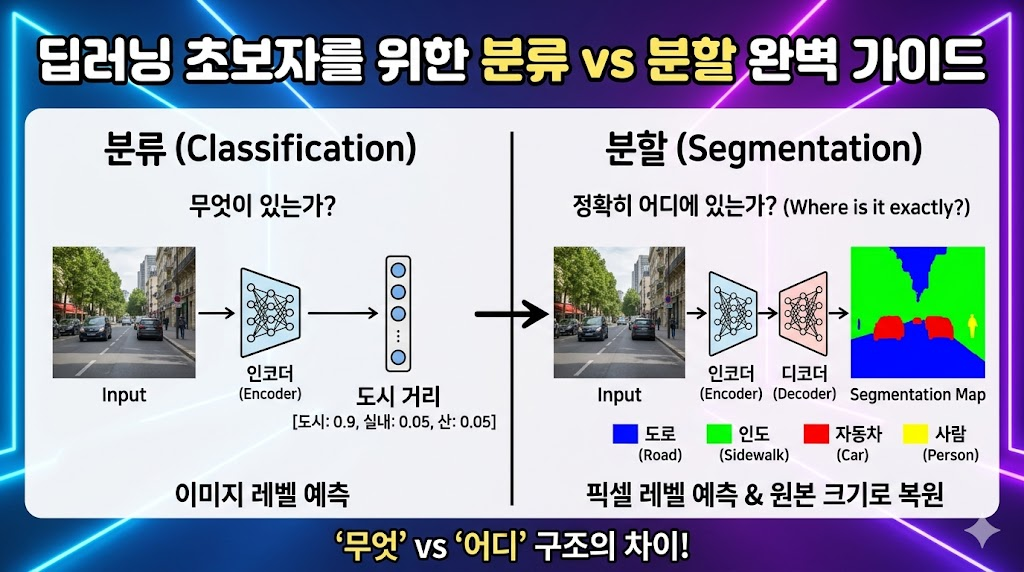
'무엇이 있는가?' vs '어디에 있는가?' CNN의 두 가지 핵심 임무 비교
176.[의료 AI] 딥러닝 분할(Segmentation), 언제 패치를 쓰고 언제 전체를 쓸까?
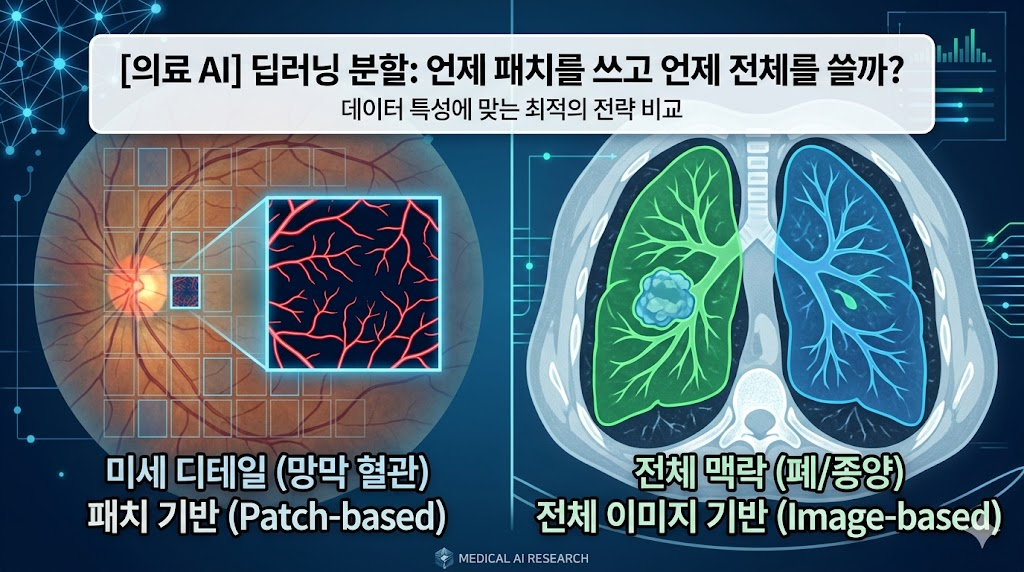
데이터 특성과 GPU 메모리 한계를 극복하는 전략: 망막 혈관부터 폐, 종양까지 타겟에 맞는 최적의 AI 모델링 방법론
177.[AI 기초] 딥러닝의 뼈아픈 한계, '기울기 소실(Vanishing Gradient)'을 극복한 두 가지 방법
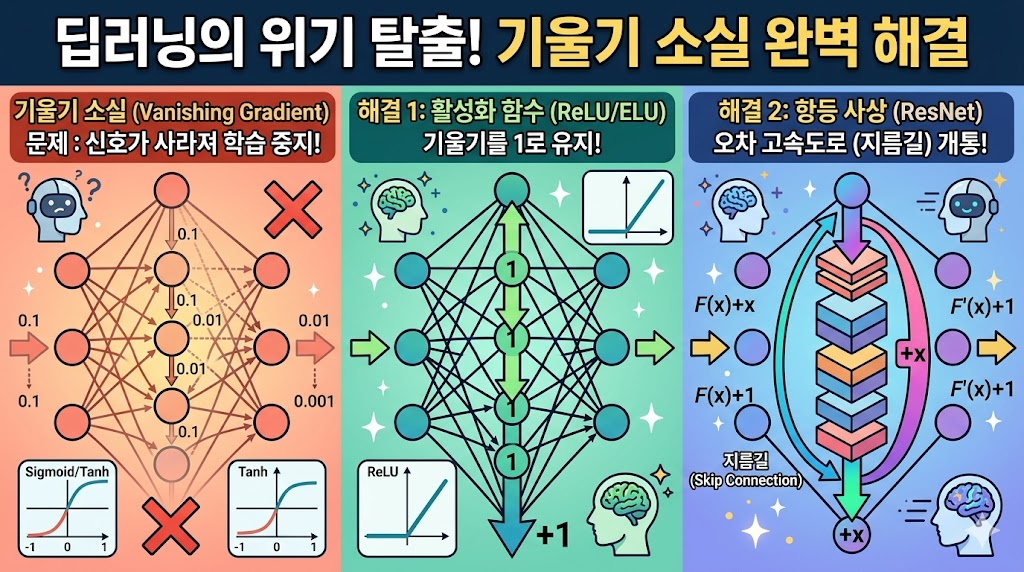
역전파의 덫에 빠진 신경망, 활성화 함수와 지름길(Skip Connection)로 한계를 돌파하다.
178.의료 영상 분할의 바이블, U-Net 아키텍처의 핵심 원리 이해하기
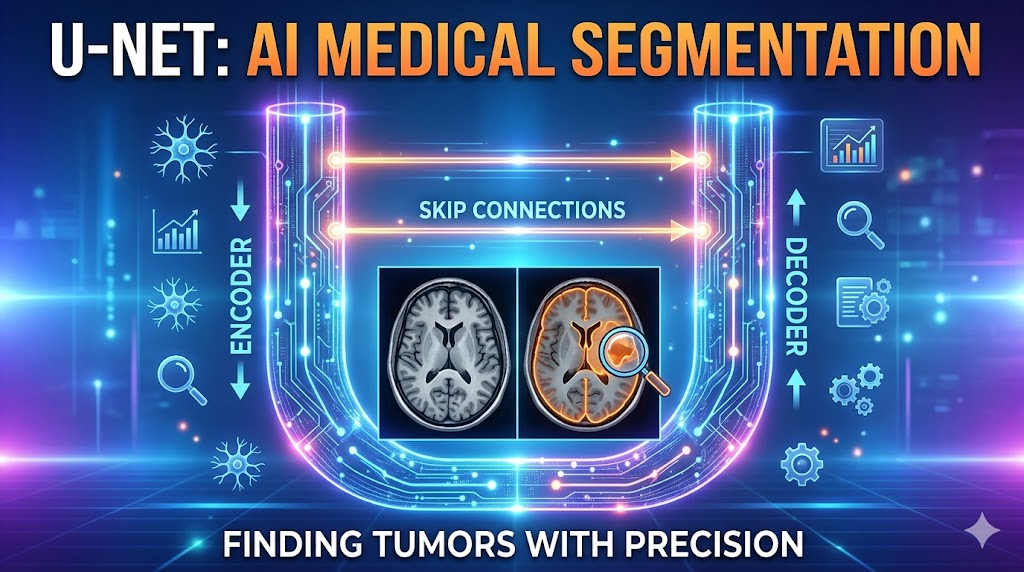
Global Location과 Context를 동시에 잡는 모델의 구조와 최신 변형 기법(Summation)
179.딥러닝을 똑똑하게 키우는 스파르타식 학습법: 일반 지도 학습 vs 심층 지도
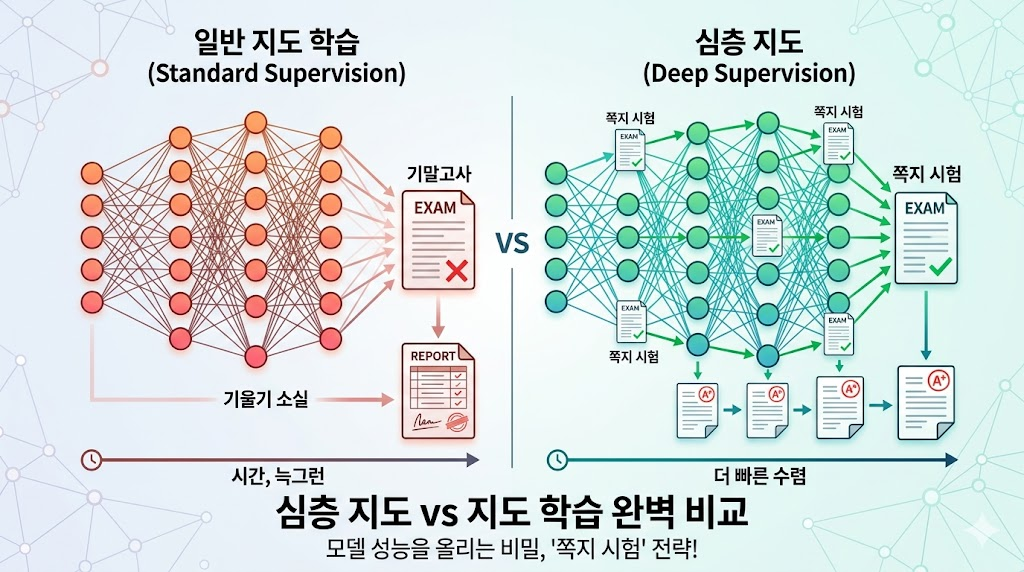
기울기 소실(Gradient Vanishing)을 극복하고 학습 효율을 극대화하는 아키텍처 설계법
180.컴퓨터 비전과 자연어 처리를 완성하는 CRF(Conditional Random Field)
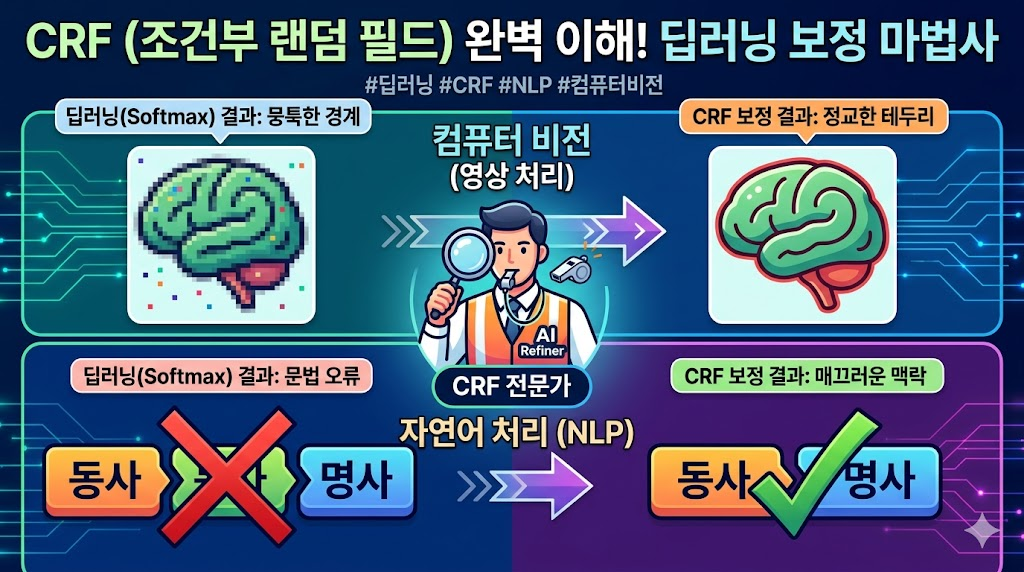
Softmax가 놓친 문맥과 뭉툭한 경계선, CRF가 완벽하게 다듬어드립니다.
181.[이슈] 앤트로픽 '클로드 미토스' 유출 사태: 전 세계 금융권이 발칵 뒤집힌 이유

사이버 보안의 룰이 바뀐다! 비공개 AI '미토스(Mythos)'의 압도적 위력
182."서울대 간판도 끝?" 월 3만 원 AI에 밀려난 박사 학위의 씁쓸한 현실

코딩부터 물리 법칙까지 씹어먹는 AI, '논문 공장' 한국 교육에 던지는 경고
183.딥러닝은 이미지를 어떻게 이해할까? 저수준 피처(Low-level Feature) 설명
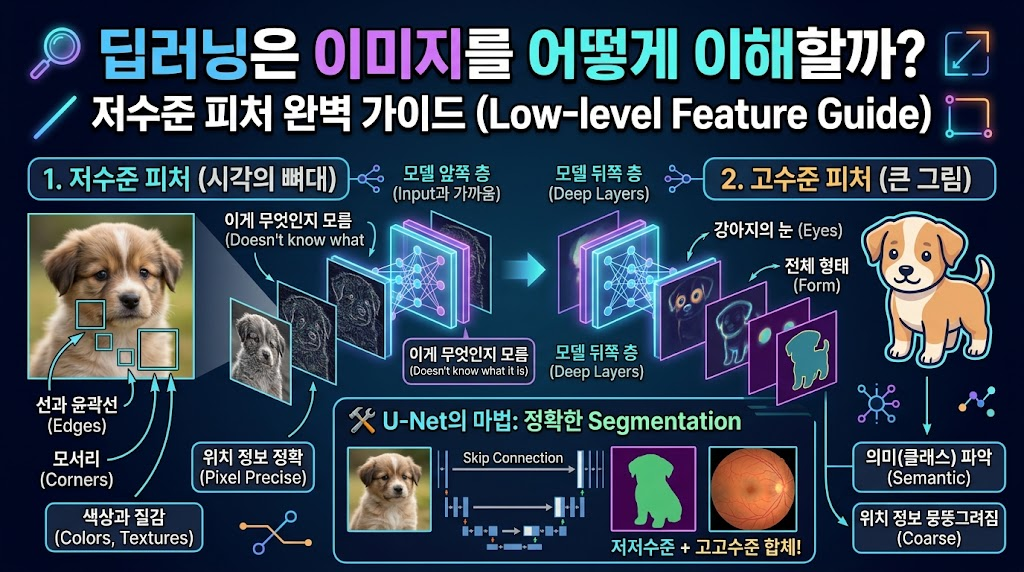
점과 선을 보는 '저수준 피처'부터 숲을 보는 '고수준 피처'까지, 그리고 U-Net이 똑똑한 이유
184.순환 합성곱(Recurrent Convolution)이란?
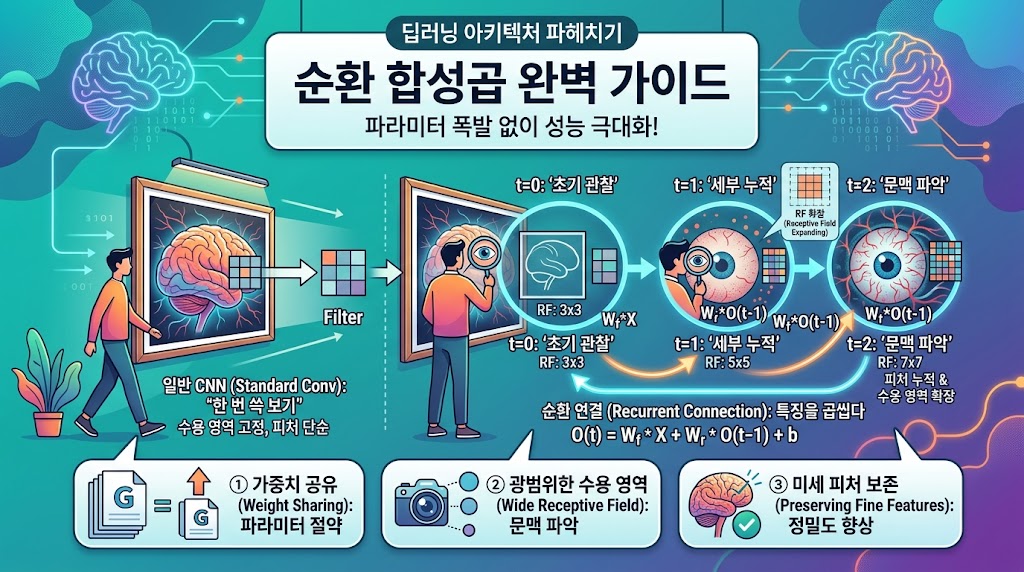
CNN과 RNN의 만남: 파라미터 폭발 없이 모델의 성능을 극대화하는 마법의 테크닉
185.신경망 암시적 표현(Neural Implicit): 그래디언트가 법선(Normal)이 되는 과정

최근 3D 컴퓨터 비전과 기하학 처리 분야에서 '신경망 암시적 표현(Neural Implicit Representation)'은 가장 뜨거운 연구 주제 중 하나입니다. 신경망을 이용해 3D 형상을 학습하고 추출하는 이 기술은 어떻게 발전하고 있을까요?