EfficientPose: Efficient Human Pose Estimation with Neural Architecture Search 리뷰
논문 리뷰
논문 "EfficientPose: Efficient Human Pose Estimation with Neural Architecture Search"는 2020년 12월 13일 arXiv에 최초로 제출되었습니다 . 현재까지 다른 학회나 저널에 공식적으로 출판되었다는 정보는 확인되지 않습니다.(DBLP)
- 제목: EfficientPose: Efficient Human Pose Estimation with Neural Architecture Search
- 저자: Wenqiang Zhang, Jiemin Fang, Xinggang Wang, Wenyu Liu
- arXiv 제출일: 2020년 12월 13일
- arXiv 링크: https://arxiv.org/abs/2012.07086(DBLP)
간단한 설명:
이 논문은 인간 자세 추정(Human Pose Estimation)을 위한 효율적인 프레임워크인 EfficientPose를 제안합니다. 기존의 많은 자세 추정 모델들이 이미지 분류를 위해 설계된 백본(backbone)을 그대로 사용하는 반면, EfficientPose는 신경망 구조 탐색(Neural Architecture Search, NAS)을 활용하여 자세 추정에 최적화된 백본과 헤드(head)를 자동으로 설계합니다.
주요 구성 요소:
- Efficient Backbone: NAS를 통해 자세 추정에 특화된 경량화된 백본을 설계하여 계산 비용을 줄이면서도 정확도를 유지합니다.
- Efficient Head: 전치 합성곱(transposed convolution)을 슬림화하고, 공간 정보 보정 모듈(Spatial Information Correction Module)을 도입하여 예측 성능을 향상시킵니다.(arXiv)
성능:
- 가장 작은 모델은 0.65 GFLOPs의 연산량으로 MPII 데이터셋에서 88.1% PCKh\@0.5의 정확도를 달성합니다.
- 가장 큰 모델은 2 GFLOPs의 연산량으로, HRNet과 같은 기존 대형 모델(9.5 GFLOPs)과 유사한 정확도를 보입니다.(Fugu Machine Translator)
요약:
EfficientPose는 NAS를 활용하여 인간 자세 추정에 최적화된 경량화된 네트워크를 자동으로 설계함으로써, 높은 정확도를 유지하면서도 연산 효율성을 크게 향상시킨 모델입니다. 특히, 모바일이나 실시간 응용 분야에서의 적용 가능성이 높습니다.(DBLP)
1. Introduction (소개)
이 글은 인간 자세 추정(Human Pose Estimation)을 효율적으로 수행하기 위한 네트워크 검색 프레임워크인 EfficientPose에 관한 연구를 소개합니다. 이 연구는 효율적인 인간 자세 추정을 위한 방법을 제시하며, 기존의 모델들이 겪는 정확도와 효율성의 문제를 해결하려고 합니다.
핵심 내용:
-
인간 자세 추정의 필요성:
- 인간 자세 추정은 가상 현실, 게임 상호작용, 그리고 생활 지원 시스템 등에서 중요한 역할을 합니다. 이는 이미지에서 인간의 주요 부위나 관절의 위치를 예측하는 문제입니다.
- 전통적인 방법은 확률적 그래픽 모델이나 그림 구조에 기반했으며, 최근 딥러닝 기법은 주요 관절의 위치를 예측하거나 히트맵을 통해 위치를 추정하는 방식으로 발전했습니다. 하지만 기존 모델들은 이미지 분류를 위한 네트워크 구조를 그대로 사용하여 최적화되지 않은 경우가 많고, 효율성 문제를 간과한 채 정확도만을 추구해 왔습니다.
-
효율성 문제:
- 최신의 멀티미디어 응용 프로그램에서는 자원 제약이 있는 디바이스에서 사용할 수 있도록 효율적인 자세 추정이 필요하지만, 기존의 알고리즘은 이 요구를 충족시키지 못하고 있습니다.
-
Neural Architecture Search (NAS):
- 최근에는 Neural Architecture Search(NAS)라는 기술이 등장하여 신경망 설계의 발전을 가속화했습니다. NAS는 이미지 분류, 객체 탐지 등 다양한 분야에서 성능을 최적화하는 네트워크 아키텍처를 자동으로 찾는 데 사용됩니다.
- 하지만 기존의 자세 추정에서는 NAS를 사용하여 백본 네트워크(backbone network)를 자동으로 설계하는 방법은 잘 연구되지 않았습니다.
-
EfficientPose의 제안:
- 이 연구에서는 효율적인 인간 자세 추정을 위한 EfficientPose라는 새로운 프레임워크를 제안합니다. EfficientPose는 효율적인 백본 네트워크와 효율적인 헤드 네트워크로 구성됩니다.
- 백본 네트워크는 NAS 기법을 사용해 효율성을 높이고, 헤드 네트워크는 빠른 추론과 빠른 아키텍처 검색을 지원하는 구조로 설계됩니다.
- 또한, 슬림한 전치 합성곱(transposed convolution)과 공간 정보 수정(SIC) 모듈을 도입하여 히트맵 품질을 향상시킵니다.
-
결과 및 성과:
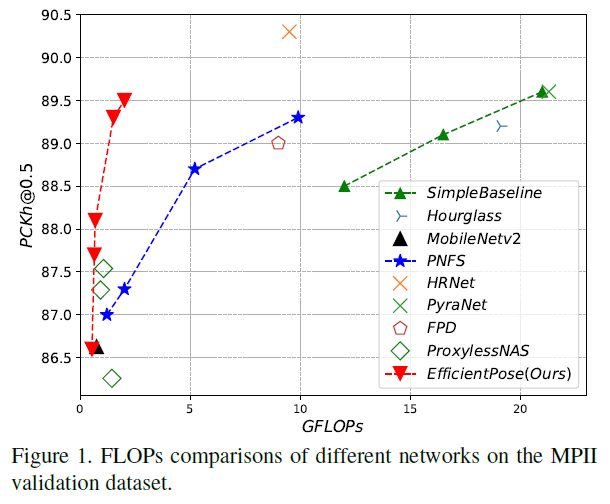
- EfficientPose는 낮은 GFLOPs (계산량)로 높은 성능을 보입니다. 예를 들어, 0.65 GFLOPs만 소모하면서도 88.1% PCKh@0.5의 성능을 기록했습니다. 이는 기존의 HRNet 모델(9.5 GFLOPs)과 비교했을 때 상대적으로 적은 계산량으로 비슷한 수준의 성능을 보입니다.
- 또한, COCO 데이터셋에서 뛰어난 일반화 능력을 보여주었습니다.
결론:
- EfficientPose는 인간 자세 추정에 최적화된 백본 네트워크를 자동으로 설계하고, 계산 비용과 정확도의 균형을 맞추는 방법을 제시한 중요한 연구입니다. 이를 통해 더 효율적이고 빠른 자세 추정 시스템을 구현할 수 있습니다.
2. Related Work (선행 연구)
논문의 2장: Related Work (선행 연구) 부분으로, 두 가지 주요 주제를 다룹니다:
2.1. Human Pose Estimation (사람 자세 추정)
2.1.1. 기존 연구 흐름 요약:
초기 접근:
- DeepPose [35]: 사람 자세 추정에 딥러닝을 처음 적용한 연구.
- 자세 추정을 회귀 문제(regression)로 보고, 신경망이 keypoint 좌표를 직접 출력함.
Heatmap 기반 접근:
- 대부분의 최신 방법은 keypoint를 직접 예측하기보다 heatmap을 출력함.
- heatmap은 각 keypoint가 있을 확률을 나타냄.
- 공간 정보를 잘 보존할 수 있어 정확도 향상에 효과적.
대표적인 모델들:
- Hourglass: 여러 개의 U-Net(모래시계 구조)를 스택해서 성능 향상.
- PyraNet: 다중 해상도 정보를 얻기 위해 피라미드 잔차 구조 사용.
- CPN:
- GlobalNet으로 keypoint의 대략적인 위치 파악,
- RefineNet으로 어려운 keypoint 정밀하게 추정.
- SimpleBaseline: 단순한 구조 + transposed convolution으로 고해상도 heatmap 생성.
- HRNet: 항상 고해상도 특징을 유지하여 매우 높은 정확도 달성 (단, 연산량 매우 큼).
- RSN: attention 메커니즘과 같은 레벨의 특징 통합으로 정확한 keypoint 추정.
2.1.2. 한계:
- 대부분의 방법이 정확도에 집중했지만, 계산량이 많고 지연(latency)이 큼.
- 실제 디바이스(예: 모바일, IoT)에 적용하기 어려움.
- 이에 따라, Bulat et al. , DU-Net , FPD 등은 다음을 시도함:
- 모델 경량화 (양자화, 이진화, 지식 증류 등)를 통해 정확도 vs 속도 균형 맞추기.
2.2. Neural Architecture Search (NAS, 신경망 구조 탐색)
2.2.1. NAS 발전 흐름:
초창기 방법:
- 강화학습 또는 진화 알고리즘 사용.
- 사람이 직접 설계한 네트워크보다 더 나은 성능을 보이는 구조를 찾아냄.
- 하지만 탐색 비용(시간, 연산) 매우 큼.
최근 방법:
- One-shot NAS 또는 Differentiable NAS (차별가능 NAS):
- 네트워크 전체를 한 번에 학습하듯 탐색.
- 속도 향상 + 성능 유지 가능.
추가 최적화 방향:
- 효율성 향상에 집중 (예: FLOPs, latency 최적화)
- 다양한 비전 과제에 적용됨: semantic segmentation, object detection 등
2.2.2. 이 논문의 접근:
- 기존 연구들은 Pose Estimation의 backbone 구조를 사람이 설계했지만,
- 이 논문에서는 differentiable NAS를 이용해 자동으로 backbone을 최적화함.
- 결과적으로 정확도와 효율성 사이에서 더 나은 trade-off를 달성했다고 주장함.
2.3. 요약:
사람 자세 추정 기술은 발전해왔지만 계산 효율은 부족했습니다. 본 논문은 이를 해결하기 위해 NAS를 이용해 경량화되면서도 정확한 pose estimation 네트워크를 자동으로 설계하고자 합니다.
3. 방법 (Method)
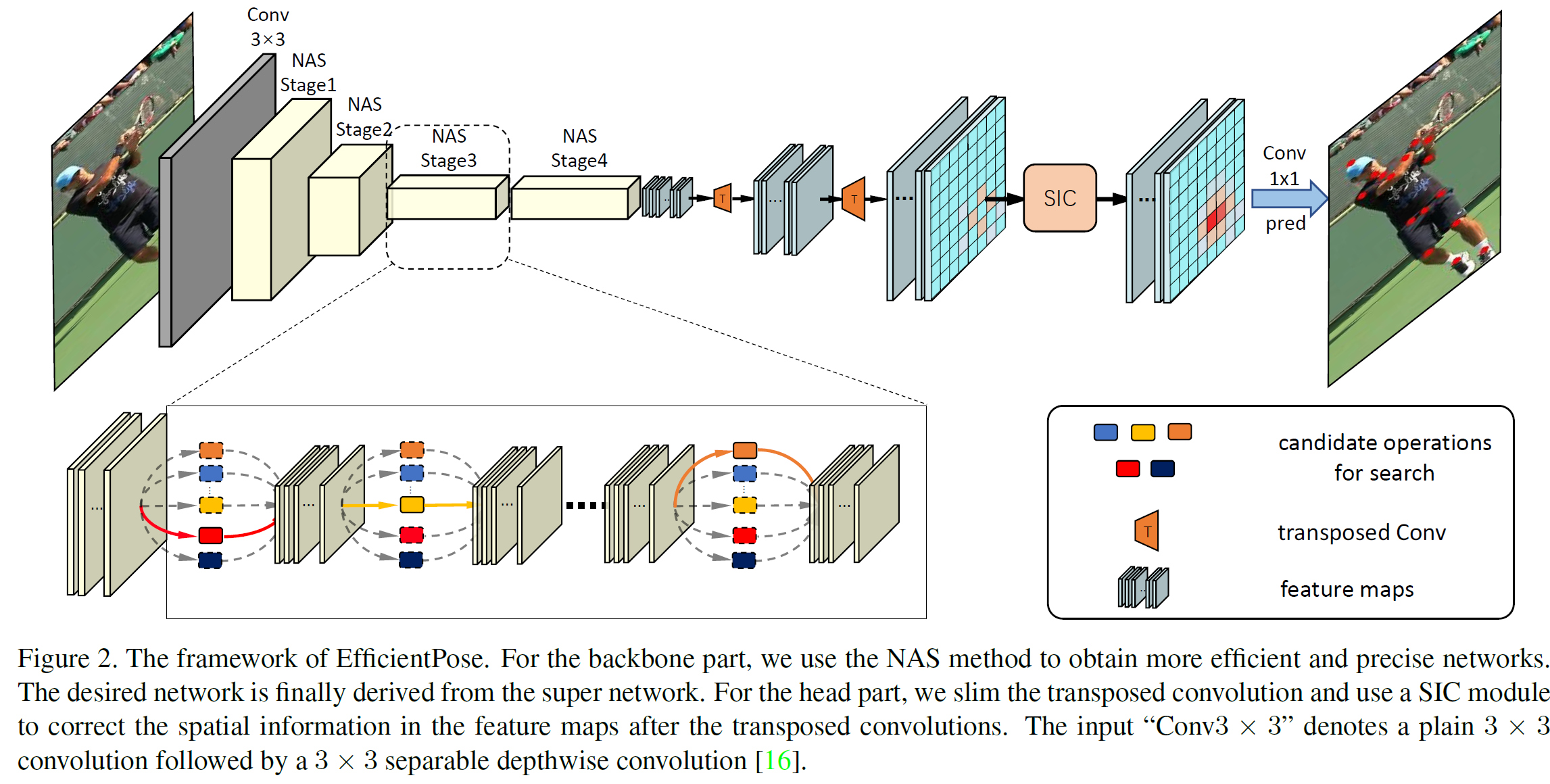
이 글은 **자세 추정(pose estimation)**을 위한 신경망 구조 자동 설계 방법에 대한 설명입니다. 특히, Differentiable Neural Architecture Search (D-NAS) 기법을 사용해 **백본 네트워크(backbone network)**를 자동으로 설계하는 방법을 소개합니다.
방법 개요
이 섹션에서는 크게 세 가지를 다룹니다:
- 자세 추정을 위해 신경망 구조를 자동으로 설계하는 NAS 기법
- NAS가 탐색할 수 있도록 정의된 **서치 공간(search space)**과 정확도/지연시간 간의 균형
- 새로 설계한 **경량 헤드 구조(lightweight head)**의 설계 원칙
3.1. Differentiable Neural Architecture Search (D-NAS)
핵심 개념:
Differentiable NAS는 기존의 NAS보다 효율적으로 신경망 구조를 찾기 위한 방법입니다.
1. 문제 정식화 (수식 1)
NAS 문제는 다음과 같은 이중 최적화 문제로 정식화됩니다:
- : 가능한 신경망 구조들의 집합 (서치 공간)
- : 선택된 아키텍처
- : 해당 아키텍처의 가중치
- : 손실 함수 (Loss)
즉, 가중치와 구조를 동시에 최적화하여 손실을 최소화하는 구조를 찾는 것이 목표입니다.
2. 연속적 표현으로 서치 공간 완화 (수식 2)
구조를 탐색할 때 가능한 선택지를 모두 discrete하게 다루는 대신, 다음과 같이 연속 확률 분포로 표현합니다:
- 각 레이어마다 가능한 연산들(operation) 중 하나를 선택하는 대신, softmax를 사용해 각 연산의 확률을 계산합니다.
- : 후보 연산의 집합 (여기서 연산은 레이어 설정 옵션을 말합니다. ex. 커널 크기, stride, padding 등)
- : 레이어 에 속한 연산 의 아키텍처 파라미터
3. 출력 계산 방식 (수식 3)
- 실제 출력은 가능한 연산들의 출력들을 **확률 가중 합(weighted sum)**으로 계산합니다:
- : 현재 레이어의 입력
- : 연산 를 적용한 결과
4. 학습 과정
-
학습 중에는:
- **연산 가중치()**와 **아키텍처 파라미터()**를 번갈아가며 **Stochastic Gradient Descent(SGD)**로 최적화
-
마지막에 구조를 선택할 때는 아키텍처 파라미터의 분포를 기반으로 가장 가능성 높은 연산을 선택해 최종 구조를 결정
요약
이 방법은 전통적인 NAS보다 훨씬 효율적입니다. 왜냐하면 discrete한 조합을 하나하나 탐색하지 않고, 연속적인 확률 기반의 표현으로 구조 탐색을 미분 가능한 방식으로 최적화하기 때문입니다.
3.2. Efficient Backbone
이 Section은 효율적인 백본(backbone) 네트워크 설계에 대한 설명입니다.
문제 배경
기존의 자세 추정 방식들은 일반적으로 이미지 분류에 사용되던 네트워크 구조(ResNet, MobileNetV2 등) 를 백본으로 사용했습니다.
하지만 이미지 분류와 자세 추정은 요구되는 특성이 다르기 때문에, 이런 네트워크를 그대로 사용하는 것은 비효율적일 수 있습니다.
해결 방법
논문에서는 이 문제를 해결하기 위해, NAS(Neural Architecture Search) 를 활용하여 자세 추정에 특화된 백본을 새로 설계합니다.
3.2.1. Search Space (탐색 공간)
-
MobileNetV2 구조를 기반으로 탐색 공간을 구성했습니다. 이 구조는 성능이 뛰어나면서 연산량이 적어 NAS에서도 자주 사용됩니다.
-
MBConv (Inverted Residual Block) 들을 쌓아서 네트워크를 구성하고, 다음과 같은 다양한 설정을 허용합니다:
- 커널 크기(kernel size): 3, 5, 7
- 확장 비율(expansion ratio): 3, 6
-
Skip connection 을 포함시켜 네트워크 깊이(depth)를 다양하게 탐색할 수 있게 함
-
Dropping-path 전략을 사용해 서로 다른 구조 간의 간섭(coupling)을 줄임
다운샘플링 전략
-
기존 대부분의 방법은 5번 down-sampling을 하지만, 이 논문에서는 4번만 down-sampling을 수행합니다.
-
이유:
- 너무 많이 축소된 (즉, 1/32 크기) 특징 맵은 정보 손실이 크고, 예측에 기여가 적다
- 대신 더 해상도가 높은 1/16 크기(feature map 4× downsampled) 를 활용해 up-sampling을 수행함
- 자세한 내용은 아래 표 참고
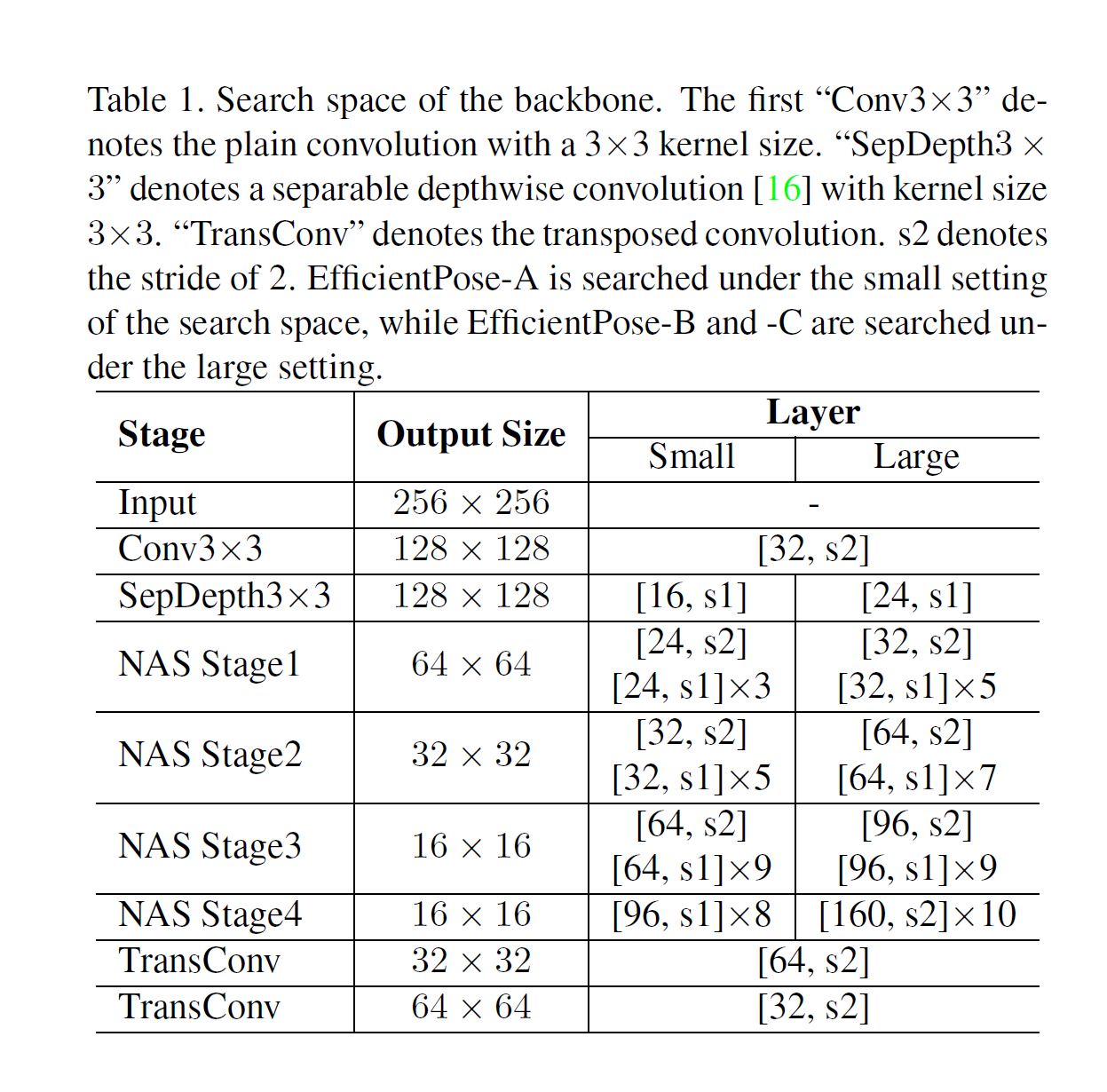
정리하면
자세 추정에 적합한 백본 구조를 만들기 위해:
- NAS로 경량화된 백본을 새로 설계
- 모바일 구조 기반(MobileNetV2)에서 MBConv를 변형해 탐색
- 기존보다 다운샘플링 횟수를 줄여 해상도 유지
라는 전략을 사용했음을 설명했습니다.
3.2.2. Cost Optimization
신경망 구조 탐색(NAS) 과정에서 정확도뿐 아니라 연산 비용(예: latency, FLOPs) 도 함께 고려하여 효율적인 네트워크를 설계하는 방법을 설명합니다.
전체 내용 요약
-
왜 비용 최적화가 중요한가?
모델의 정확도뿐 아니라, 실제 사용 시 속도(latency)나 연산량(FLOPs) 같은 비용 지표도 중요합니다. NAS에서는 이 비용을 고려해 정확하면서도 빠르고 가벼운 모델을 찾고자 합니다. -
어떻게 비용을 예측하는가?
NAS는 실제 모든 모델을 실행해볼 수 없기 때문에, 각 레이어에 대해 선택 가능한 연산들의 비용을 미리 측정해둔 lookup table을 사용합니다.
구조 파라미터로 계산된 연산 선택 확률을 기반으로 기대 비용(expectation) 을 계산합니다. -
비용을 손실 함수에 반영해 최적화
최종적으로, 정확도 손실(MSE)과 비용(log-scaled latency)을 함께 포함한 손실 함수를 정의하여, 정확도와 효율성의 균형을 맞추는 방식으로 학습을 진행합니다.
수식 설명
(1) 레이어별 비용 계산
- : 해당 레이어에서 선택 가능한 연산들의 집합 (예: Conv3x3, Conv5x5 등)
- : 연산 가 선택될 확률 (architecture parameter로부터 softmax 등으로 계산됨)
- : 연산 의 latency 또는 FLOPs
→ 이 수식은 각 연산의 선택 확률 × 연산 비용의 합으로, 레이어의 기대 비용을 구합니다.
(2) 전체 네트워크 비용 계산
- 모든 레이어의 비용을 합산하여 전체 네트워크의 비용을 계산합니다.
(3) NAS 학습용 손실 함수
- : 예측된 keypoint heatmap과 정답의 평균 제곱 오차
- : 하이퍼파라미터 (정확도와 비용 간의 균형을 조절)
- : 위 (5)에서 계산된 전체 네트워크 비용
→ 이 손실 함수는 정확도(MSE) 를 높이면서도 낮은 latency 를 유도하도록 설계되어 있습니다.
(4) MSE 손실 정의
- : 관절 수
- : k번째 관절의 정답 히트맵
- : 예측된 히트맵
→ 포즈 추정에서 히트맵 예측 정확도를 계산하는 기본 손실입니다.
정리
이 방식은 NAS의 탐색 기준에 정확도와 비용을 모두 반영하여, 실제 사용 가능한 수준의 고성능·저비용 네트워크를 자동으로 설계하도록 유도하는 접근입니다.
이 글은 포즈 추정(pose estimation) 네트워크의 헤드(head) 부분을 효율적으로 설계한 방법을 설명하는 내용입니다. 주요 내용을 쉽게 설명드리면 다음과 같습니다:
3.3. Efficient Head
포즈 추정 네트워크에서 헤드는 고해상도 heatmap을 생성하는 역할을 합니다. Heatmap은 사람의 관절 위치 등을 예측할 때 사용하는 시각적 지표입니다. 이 글에서는 계산량은 줄이고 성능은 유지 또는 향상시키기 위한 두 가지 방법을 제안합니다.
3.3.1. Slim Transposed Convolutions
-
기존 방법들보다 출력 채널 수가 적은 feature map을 백본(backbone)에서 출력하도록 구성했습니다.
-
이 때문에 **transposed convolution의 너비(width)**를 줄여 계산량을 크게 감소시켰습니다.
-
또한, separable depthwise convolution 같은 더 효율적인 업샘플링 방법도 실험적으로 적용하여 좋은 성능을 얻었습니다.
- 이는 일반적인 convolution보다 파라미터 수와 계산량이 적습니다.
3.3.2. Spatial Information Correction (SIC) 모듈
-
Transposed convolution을 사용하면 종종 checkerboard artifact라는 격자 모양 노이즈가 생깁니다.
- 이는 필터의 겹침이 고르지 않아서 생기는 현상입니다.
-
이를 해결하기 위해 SIC 모듈을 제안했는데, 이는 단순한 3x3 depthwise convolution입니다.
-
이 모듈을 사용하면 checkerboard artifact가 거의 사라지며, 결과적으로 heatmap의 품질과 예측 정확도가 향상됩니다.
-
계산량은 거의 늘어나지 않습니다.
요약
- Slim Transposed Convolutions: 채널 수를 줄이고 효율적인 업샘플링으로 계산량 절감.
- SIC Module: checkerboard 노이즈 제거로 heatmap 품질 향상.
- 전체적으로 효율성과 성능을 동시에 잡은 설계입니다.
4. Results (결과)


4.1. Ablation studies
4.1.1. Effectiveness of SIC module
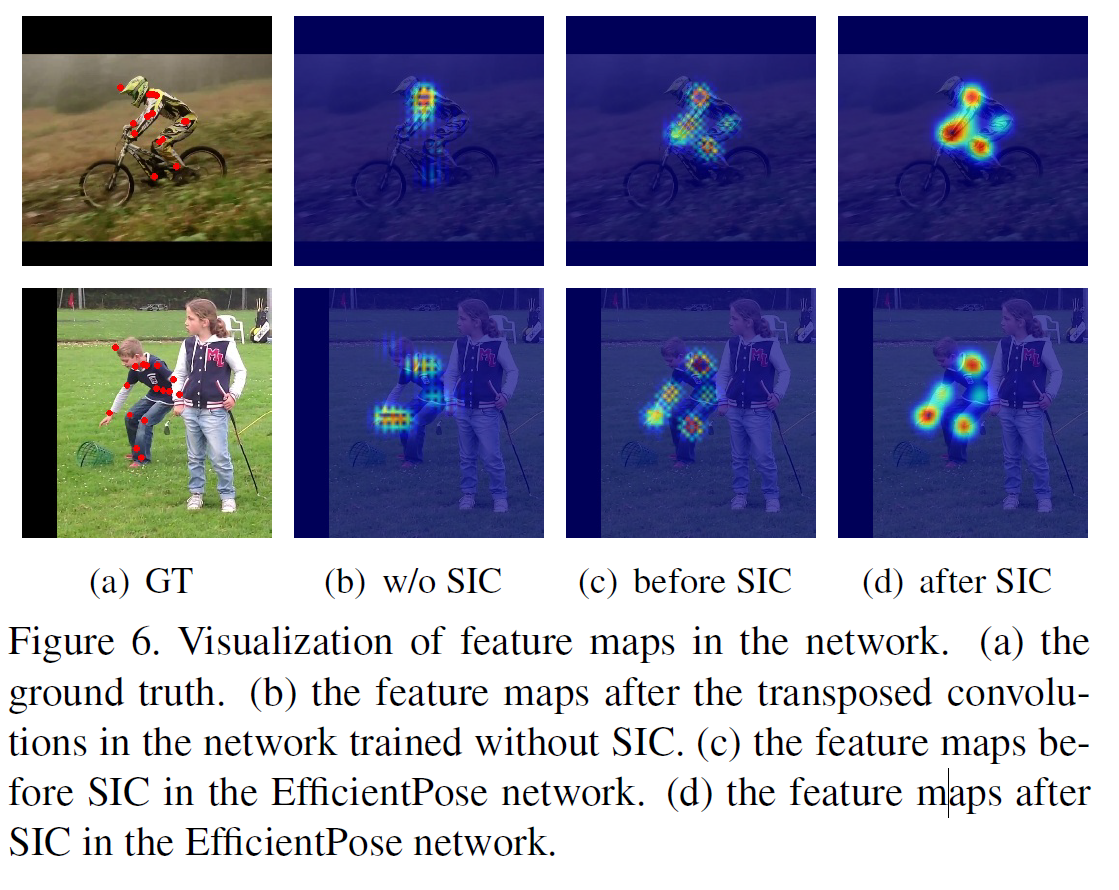
SIC 모듈(Spatial Information Correction module)의 효과를 분석하고 시각화 및 실험 결과로 증명합니다.
글 전체 요약
SIC 모듈은 **transpose convolution 이후 생기는 checkerboard artifact(체커보드 노이즈 패턴)**를 제거하여 피처 맵을 더 집중적이고 정확하게 만들어주는 역할을 합니다. 이 모듈이 실제로 얼마나 효과적인지를 시각화와 실험을 통해 입증하고 있습니다.
시각화 결과 설명 (Fig. 6 참고)
- Transpose convolution을 사용하면 피처 맵에 체커보드처럼 보이는 잡음 패턴(artifact)이 생기는데,
SIC 모듈을 적용하면 이 패턴이 제거되고, 관심 부위(interested field)가 더 선명하고 집중적으로 나타납니다. - 이는 결국 예측 정확도 향상에 기여합니다.
- SIC 모듈을 적용했을 때와 안 했을 때의 정확도(PCKh@0.5)를 비교합니다.
| 모델 | SIC 적용 | PCKh\@0.5 |
|---|---|---|
| MobileNetV2 | ❌ 미적용 | 86.34 |
| MobileNetV2 | ✅ 적용 | 86.63 (+0.29) |
| EfficientPose-A | ❌ 미적용 | 87.62 |
| EfficientPose-A | ✅ 적용 | 88.10 (+0.48) |
| EfficientPose-B | ❌ 미적용 | 88.55 |
| EfficientPose-B | ✅ 적용 | 89.27 (+0.72) |
| EfficientPose-C | ❌ 미적용 | 88.61 |
| EfficientPose-C | ✅ 적용 | 89.49 (+0.88) |
해석
- 모든 모델에서 SIC를 적용한 경우 정확도(PCKh@0.5)가 상승했습니다.
- 특히 EfficientPose-C에서는 약 +0.88%p의 향상이 있었고, 이는 포즈 추정 분야에서는 꽤 의미 있는 개선입니다.
- 따라서 SIC 모듈은 가볍지만 성능 향상에 효과적인 구성 요소로 평가됩니다.
정리
- 문제: Transposed convolution 후 checkerboard artifact 발생.
- 해결책: 3×3 depthwise convolution으로 구성된 SIC 모듈 추가.
- 결과: 시각적으로 artifact 제거됨. 성능(PCKh@0.5)도 모든 모델에서 향상됨.
- 의미: 계산 비용은 거의 들지 않으면서도 정확도 향상에 효과적인 모듈임.
4.1.2. Studies on Efficient Transposed Convolutions
슬림한(Slim) Transposed Convolution이 얼마나 효율적인지를 보여주는 실험 결과를 설명합니다. 특히, Transposed Convolution의 채널 수(width)를 늘릴 때 연산량(FLOPs)이 어떻게 증가하고, 성능(PCKh@0.5)은 어떤 영향을 받는지를 다룹니다.
Table 7. Comparisons with larger width settings of the transposed convolutions. TConv denotes the transposed convolution.
| TConv1 | TConv2 | Backbone FLOPs | Head FLOPs | PCKh\@0.5 |
|---|---|---|---|---|
| 64 | 32 | 405M | 264M | 88.100 |
| 64 | 64 | 405M | 369M | 88.095 (거의 동일) |
| 96 | 96 | 405M | 755M | 87.918 (오히려 감소) |
배경
- 기존 연구(SimpleBaseline 등)에서는 Transposed Convolution의 채널 수를 256 정도로 매우 크게 설정했지만, 이 논문에서는 훨씬 더 작은 값인 64와 32로 설정했습니다.
- 이것이 연산량(MFLOPs)을 크게 줄이면서도 성능을 유지하거나 오히려 향상시킬 수 있는지를 실험합니다.
실험 결과 요약
-
64/32 설정은 연산량이 적고 성능(PCKh@0.5)이 가장 높음.
-
64/64 설정은 연산량이 134M 늘지만 성능 향상은 없음.
-
96/96 설정은 연산량이 520M 더 많아지고, 성능은 오히려 떨어짐.
- 오히려 오버피팅(overfitting) 때문일 수 있음.
- 특히, head의 연산량이 backbone보다 커지는 비효율적인 상황 발생.
결론 요약
- Slim한 (채널 수가 적은) Transposed Convolution은 연산량 대비 성능이 뛰어남.
- Head가 너무 무거우면 오히려 성능이 떨어지고 overfitting 우려도 있음.
- 따라서 경량화된 네트워크에서는 가볍고 효율적인 head 설계가 매우 중요함.
4.1.3. Studies on Efficient Transposed Convolutions
Transpose Convolution을 더 가볍게 만들기 위한 방법들을 실험한 결과를 설명합니다. 목표는 연산량(FLOPs)을 줄이면서도 정확도(PCKh@0.5)를 최대한 유지하는 것입니다.
Table 8 Studies of more efficient transposed convolutions.
| Transposed Conv 방식 | 연산량 (MFLOPs) | 정확도 (PCKh\@0.5) |
|---|---|---|
| Plain (기본 방식) | 669M | 88.10 |
| MBV1 스타일 | 469M | 87.91 |
| MBV2 스타일 | 600M | 87.94 |
실험 목적
-
Transpose Convolution을 계산 효율적으로 구현하는 방식을 실험했습니다.
-
구체적으로 MobileNet에서 쓰이는 두 가지 스타일을 적용해 봤습니다:
- MBV1 스타일: MobileNetV1의 Separable Depthwise Convolution 사용
- MBV2 스타일: MobileNetV2의 Inverted Residual Block 사용
실험 결과 해석
- Plain 방식이 가장 정확도는 높지만, 연산량이 가장 큼 (669M FLOPs).
- MBV1 스타일은 정확도는 약간 떨어지지만 연산량이 크게 줄어듦 (469M, -200M 가까이 감소).
- MBV2 스타일은 중간 정도의 연산량과 성능을 보여줌.
결론 요약
- Separable Depthwise Convolution (MBV1 스타일)은 연산량을 줄이는 데 효과적이며, 정확도 손실도 크지 않아서 효율적인 대안이 될 수 있음.
- 따라서 정확도보다 연산 효율이 중요한 상황에서는 MBV1 스타일을 사용하는 것이 좋은 선택이 될 수 있음.
