Gemini Flash 최신 사용 제한 해제
- Gemini Flash API는 최근 일일 요청 제한이 제거되어, 현재는 1분당 1,000회(RPM) 요청 제한만 존재합니다.
- 다만, 일반 웹/모바일 Gemini 사용자의 경우, 요금제(Free/Pro/Ultra 등)에 따라 프롬프트 수나 기능 제한이 존재할 수 있습니다.
- 교육 기관이나 단체 계정에서는 별도 월간 사용량 제한(예: 월 1,000회 등)이 있을 수 있으니, 사용 환경 확인이 필요합니다.
🔗 관련 문서: Gemini API Rate Limits
LLM 3대장 성능 비교: Gemini Flash vs GPT-4o Mini vs Claude 3.5 Sonnet
| 모델 | 주요 특징 | 대표 벤치마크 | 속도 | 추론 가격 | 맥락 길이 |
|---|---|---|---|---|---|
| Gemini Flash | 초고속, 저렴, 100만 토큰 맥락 | MMLU 78.9%, MMMU 56.1% | ✅ 매우 빠름 | 💰 매우 저렴 | 🧠 1M 토큰 (소설 여러권) |
| GPT-4o Mini | 최신 멀티모달, 균형 잡힌 성능 | MMLU 82.0%, HumanEval 87.2% | ✅ 빠름 | 💰 저렴 | 🧠 128K+ (소설 한권) |
| Claude 3.5 Sonnet | 고급 reasoning 및 코드 특화 | MMLU 79~81%, HumanEval 92.0% | ⚠️ 보통 | 💰 상대적으로 비쌈 | 🧠 200K (소설 한권) |
여기서 "추론 가격"은 사용자가 지불하는 금액이 아니라, 모델 제공사(Google, OpenAI, Anthropic 등) 입장에서의 추론당 비용(Cost-per-Inference)을 의미합니다.
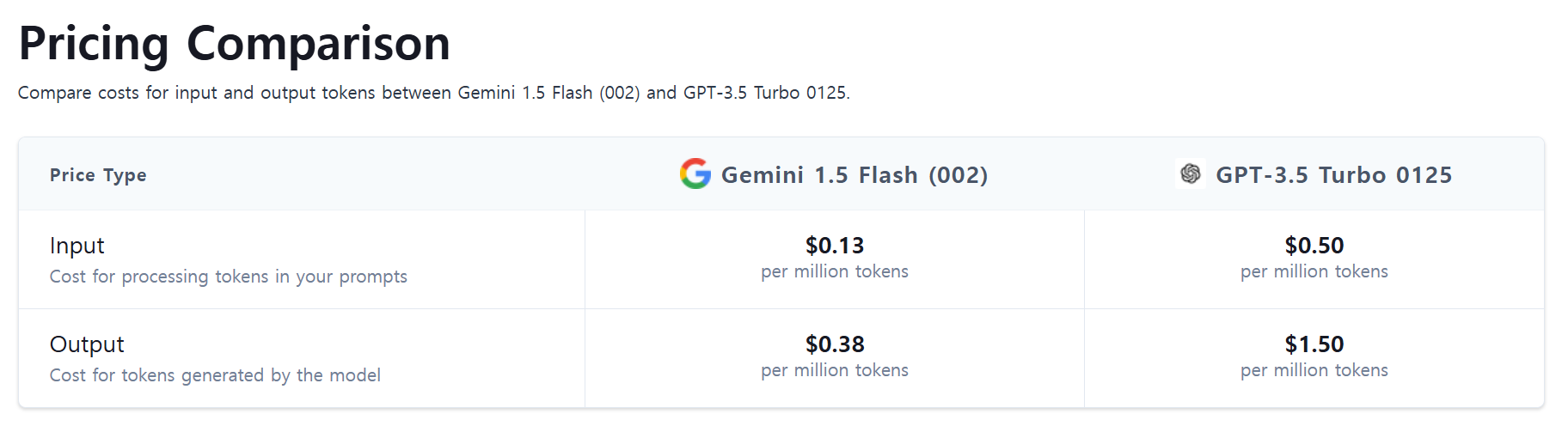
벤치마크 상세 비교
| 모델 | 🧠 MMLU (지식/추론) | 👨💻 HumanEval (코드) | 📸 MMMU (멀티모달) |
|---|---|---|---|
| Gemini Flash | 78.9% | 71.5% | 56.1% |
| Claude 3.5 Sonnet | 79~81% | 92.0% | 54~58% |
| GPT-4o Mini | 82.0% | 87.2% | 59.4% |
상황별 추천 가이드
Gemini Flash
-
추천 용도: 대용량 문서 처리, 대화형 UI, 빠른 응답이 중요한 서비스
-
장점:
- 최고 수준의 속도
- 가장 저렴한 토큰 단가
- 최대 100만 토큰 맥락 처리 (긴 소설 여러 권 합친 분량)
-
주의점:
- 복잡한 추론, 고난이도 코딩은 상대적으로 약할 수 있음
GPT-4o Mini
-
추천 용도: 멀티모달 입력(텍스트+이미지), 실시간 서비스, 고성능이 필요한 웹앱
-
장점:
- 전반적으로 가장 균형 잡힌 성능
- 멀티모달 인식 가능
- 저렴하면서도 높은 추론 성능
-
주의점:
- Claude에 비해 코드 정확도는 살짝 낮음
Claude 3.5 Sonnet
-
추천 용도: 정교한 코드 생성, 복잡한 추론, 고신뢰 텍스트 작업
-
장점:
- 코드 정확도 압도적
- 복잡한 추론 문제에 강함
- 긴 맥락 유지력 우수
-
주의점:
- 속도와 비용 측면에서는 다소 불리
결론
| 목적 | 추천 모델 |
|---|---|
| 대규모 맥락/속도/저비용 | 🔥 Gemini Flash |
| 멀티모달, 실용성과 속도 균형 | 🚀 GPT-4o Mini |
| 고급 reasoning/코드 정확도 | 🧠 Claude 3.5 Sonnet |
“가장 좋은 모델”은 없습니다. 업무 목적에 따라 최적의 LLM은 달라집니다.
Flash는 실시간과 대규모 데이터를,
Claude는 복잡하고 정밀한 업무를,
GPT-4o Mini는 멀티모달과 실용성을 겨냥합니다.

AI developer