1. 소개 (Introduction)

이 논문의 목적은 간단한 방법이 얼마나 효과적일 수 있는지에 대한 질문을 던지고, 이를 통해 기존의 복잡한 방법들을 단순화하고 평가하기 쉬운 기준을 제시하는 것입니다. 구체적으로, 간단한 베이스라인 방법을 통해 포즈 추정과 추적의 성능을 높이려는 목표를 가지고 있습니다.
1. 인간 자세 추정(Human Pose Estimation)의 발전
- 딥러닝의 도입으로 인간 자세 추정 기술이 크게 향상되었음.
- MPII 데이터셋에서는 3년 만에 정확도가 약 80% → 90% 이상으로 증가.
- COCO 데이터셋에서도 mAP 기준으로 1년 사이 60.5 → 72.1로 급속한 발전.
2. 새로운 도전 과제
- 기술이 성숙함에 따라, 이제는 실제 환경에서의 자세 탐지 및 추적과 같은 더 복잡한 문제로 연구가 확장되고 있음.
3. 복잡해진 모델 구조와 비교의 어려움
- 최신 방법들은 구조나 실험 설정이 매우 복잡해졌고, 성능은 비슷하지만 세부 구현 방식은 매우 다름.
- 때문에 어떤 요소가 성능 향상에 중요한지 분석하기 어려움.
- 추적(tracking) 분야도 마찬가지로, 문제 차원이 커져 시스템이 더 복잡해질 것으로 예상됨.
4. 간단한 방법으로 성능 향상
-
포즈 추정 (Pose Estimation):
- ResNet을 기반으로 몇 개의 디컨볼루션 레이어를 추가한 간단한 구조로, 히트맵(heat map)을 추정합니다.
- 이 방법은 COCO 데이터셋에서 mAP 73.7을 기록하며, COCO 2017 Keypoint Challenge에서 우승한 모델에 비해 1.6%와 0.7% 성능 향상을 보였습니다.
-
포즈 추적 (Pose Tracking):
- ICCV 2017 PoseTrack Challenge 우승자의 방법을 따르며, 광학 흐름(optical flow)을 사용해 포즈 전파 및 유사도 측정을 개선.
- 이 방법으로 mAP 74.6과 MOTA 57.8을 기록하며, 우승자의 성능에 비해 각각 15%와 6% 성능 향상되었습니다.
5. 논문의 접근 방식
- 이 연구는 이론적 근거보다는 간단한 기술들을 사용하고, 종합적인 실험을 통해 성능을 검증하였습니다.
- 주된 기여는 간단하면서도 효과적인 베이스라인 방법을 제공하는 것입니다.
결론
- 간단한 방법이 고성능을 낼 수 있음을 보여주고, 이를 통해 새로운 아이디어를 유도하고, 연구 평가를 단순화할 수 있는 기초를 마련하려고 했습니다.
2. Deconvolution Head Network을 활용한 Pose Estimation
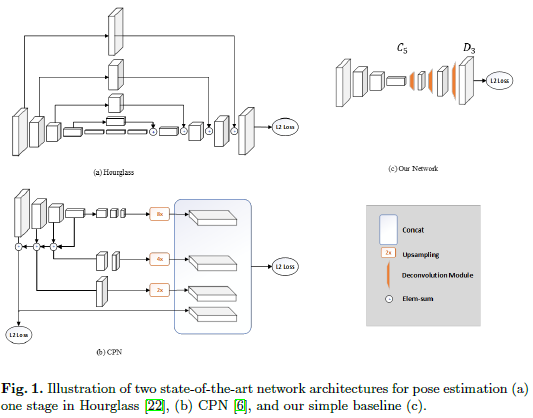
2.1. 기본 구조
- Backbone: 일반적으로 이미지 특징 추출에 많이 쓰이는 ResNet 사용.
- 방법: ResNet의 마지막 층(C5) 위에 디컨볼루션(deconvolution) 레이어 몇 개를 추가해서 히트맵(heatmap)을 생성.
- 이 구조는 간단하면서도 효과적인 방식이며, Mask R-CNN에서도 채택된 바 있음.
구체적인 구성
- 디컨볼루션 레이어: 3개 사용
- 각 레이어는 256 필터, 커널 크기 4×4, 스트라이드 2
- BatchNorm + ReLU 활성화 적용
- 마지막에 1×1 컨볼루션 레이어로 키포인트(k개)의 히트맵 출력
- 손실 함수(Loss):
- Mean Squared Error (MSE)
- 정답 히트맵은 각 관절 위치에 2D 가우시안 분포를 얹어 생성
2.2. 기존 방법과의 비교
-
비교 대상:
- Hourglass: 반복적인 업/다운 샘플링 구조 + 스킵 연결 사용
- CPN: 피라미드 구조 + 어려운 키포인트 학습 방식 포함
-
차이점:
- 기존 방법들은 업샘플링 후 별도 블록에서 처리하거나 스킵 연결을 통해 고해상도 정보 복원
- 본 논문 방법은 업샘플링과 파라미터 학습을 단순한 디컨볼루션 레이어 안에서 처리, 훨씬 단순함
- 스킵 연결 없음
2.3. 핵심 결론
- 세 가지 방법 모두 고해상도 특징 맵을 만들기 위해 3번의 업샘플링과 비선형성 처리를 사용함
- 중요한 것은 어떻게든 고해상도 히트맵을 만드는 것, 그 방식이 반드시 복잡할 필요는 없음
- 단, 이 비교는 예비적이며 직관적일 뿐이고, 어떤 구조가 더 우수한지 단정짓는 것이 목적은 아님
3. 실험 (Experiments)
3.1 COCO 데이터셋에서의 자세 추정
3.1.1. COCO Keypoint Challenge 소개
- 다중 인물의 관절 위치 예측이 목적.
- 총 20만 개 이상의 이미지, 25만 개 인물 인스턴스 포함.
- 이 중 약 15만 개 인스턴스를 학습/검증에 사용 가능.
- 본 논문은 train2017 데이터셋(57K 이미지, 150K 인물)만 사용해 학습.
- 성능 평가는 val2017 세트로 ablation study, test-dev2017 세트로 최종 결과 보고.
평가지표
- OKS (Object Keypoint Similarity): 포즈 예측의 정확도를 측정하는 지표.
→ 객체 탐지에서의 IoU와 유사한 개념. - 평균 정밀도(AP): 여러 OKS 임계값에서 평균을 내어 사용.
3.1.2. Ablation Study (성능 영향 요인 분석)
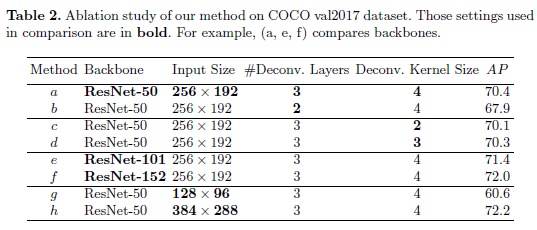
1. 히트맵 해상도
- 3개의 디컨볼루션 층 → 64×48 해상도 (방법 )
- 2개의 디컨볼루션 층 → 32×24 해상도 (방법 )
- 결과: 해상도가 높을수록 AP 2.5 상승, 기본은 3개 층 사용
-
커널 크기
- 4 → 2로 줄일 때 성능 0.3 포인트 하락 (방법 )
- 기본값: 커널 크기 4
-
백본 네트워크
- ResNet-50 → ResNet-101: AP 1.0 상승 (방법 )
- ResNet-50 → ResNet-152: AP 1.6 상승 (방법 )
-
입력 이미지 크기
- 이미지 크기 감소 시 성능 하락하지만 75% 연산 절감 (방법 )
- 큰 이미지 사용 시 AP 1.8 상승, 계산 비용 증가 (방법 )
3.1.2. 학습 설정
- 이미지 전처리: 인물 박스를 4:3 비율로 고정, 256×192 크기로 리사이즈
- 데이터 증강: 스케일 ±30%, 회전 ±40°, 좌우 플립
- 백본 초기화: ImageNet에서 사전 학습된 ResNet
- 하이퍼파라미터
- 학습률: → (90 epoch) → (120 epoch)
- 총 140 epoch
- Optimizer: Adam, 배치 사이즈: 128
- GPU 4개 사용
테스트 설정
- 탑다운 방식 2단계
- 1단계: Faster R-CNN으로 사람 감지 (AP 56.4)
- 2단계: 본 논문의 네트워크로 관절 예측
- 예측 시 좌우 반전 이미지 평균, 히트맵 내 응답 강도 기반 보정 오프셋 사용
결론
- 높은 해상도, 깊은 백본, 큰 입력 이미지가 성능 향상에 기여
- 간단한 구조에도 불구하고 강력한 성능을 달성하며, 다양한 ablation 실험을 통해 설계 선택이 정당화됨
3.2. COCO val2017 데이터셋 비교 (Table 3)
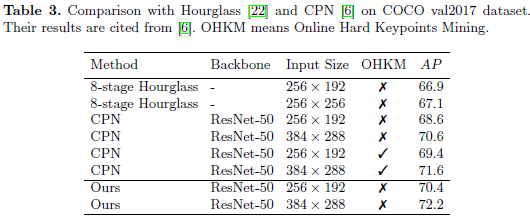
- 비교한 모델: 8-stage Hourglass, CPN, 그리고 저자들의 baseline 모델
- 모두 top-down, 2단계 방식 사용 (즉, 먼저 사람을 감지한 뒤에 그 사람의 자세를 추정하는 방식)
사람 감지 성능(AP):
- Hourglass & CPN: 55.3
- 저자 모델: 56.4 → 비슷한 수준
Hourglass 대비:
- 저자 모델이 AP 3.5만큼 더 높음
- 동일한 입력 이미지 크기 사용 (256×192)
- OHKM(Online Hard Keypoints Mining)은 사용하지 않음
CPN과의 비교:
- 백본(Backbone)은 모두 ResNet-50 사용
- OHKM 미사용 시:
- 입력 크기 256×192: 저자 모델이 CPN보다 1.8 AP 높음
- 입력 크기 384×288: 저자 모델이 1.6 AP 높음
- OHKM 사용 시(CPN 기준):
- 두 입력 크기 모두에서 저자 모델이 0.6 AP 높음
주의: Hourglass와 CPN 결과는 저자들이 직접 구현한 것이 아니라, 다른 논문 [6]에서 인용한 것임. 따라서 성능 차이는 구현 차이 때문일 수도 있음. 하지만 전체적으로 저자 모델은 더 단순하면서도 성능이 비슷하거나 더 좋다고 판단.
3.3. COCO test-dev 데이터셋 비교 (Table 4)
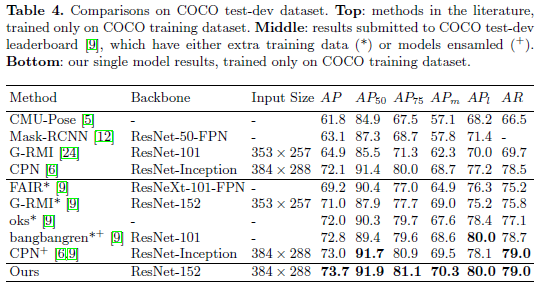
- 저자 모델의 사람 감지 AP: 60.9 (COCO std-dev 기준)
- CPN의 사람 감지 AP: 62.9 (COCO minival 기준)
Bottom-up 방식인 CMU-Pose 보다 훨씬 성능이 좋음
Top-down 방식 모델들과 비교:
- G-RMI: ResNet 백본 사용 → 같은 ResNet-101 사용 시 저자 모델이 더 우수함
- CPN: 더 강력한 백본인 ResNet-Inception 사용
ResNet-Inception의 ImageNet top-1 에러율: 18.7%,
ResNet-152의 에러율: 21.4% → 즉, CPN이 더 성능 좋은 백본 사용
하지만,
- 입력 크기 384×288 기준으로:
- 저자 모델 AP: 73.7
- CPN (single model): 72.1
- CPN (ensemble model): 73.0
즉, 저자 모델이 더 단순한 구조임에도 불구하고 더 강력한 백본을 사용하는 CPN보다 성능이 더 좋음.
요약 정리
- 저자 모델은 구조가 단순함에도 성능이 우수함
- CPN이나 Hourglass 같은 기존 방법보다 같은 조건에서는 더 높은 성능
- 더 좋은 백본(ResNet-Inception)을 사용한 모델보다도 좋은 결과를 냄
- 따라서 이 모델은 효율성과 성능을 모두 잡은 모델이라고 볼 수 있음
4. 결론 (Conclusion)
결론 요약
-
간단하면서도 강력한 기준 모델(baseline)을 제시함
→ 복잡한 구조가 아니더라도 뛰어난 성능을 낼 수 있는 자세 추정(pose estimation)과 추적(tracking) 방법을 소개 -
최신(state-of-the-art) 성능을 달성
→ 저자들의 방법이 여러 까다로운 벤치마크 테스트에서 최고의 성능을 보였음 -
다양한 실험(ablations)을 통해 검증
→ 단순히 성능만 강조한 게 아니라, 어떤 요소가 성능에 영향을 주는지도 체계적으로 분석 -
향후 연구자들에게 도움이 되기를 기대
→ 이 베이스라인이 다른 연구자들이 새로운 아이디어를 시험하고 비교할 때 유용하게 사용되길 바람
핵심 메시지
“복잡하지 않아도 충분히 좋은 성능을 낼 수 있다. 우리의 단순한 방법이 앞으로 이 분야의 발전에 도움이 되길 바란다.”
