1. 소개 (Introduction)
이 논문은 ResNet(Residual Network)을 제안한 것으로, 아주 깊은 신경망을 효율적으로 학습할 수 있도록 돕기 위한 방법론을 소개하고 있습니다. 아래에 주요 내용을 쉽게 설명해 드릴게요:
배경 문제: 왜 ResNet이 필요한가?
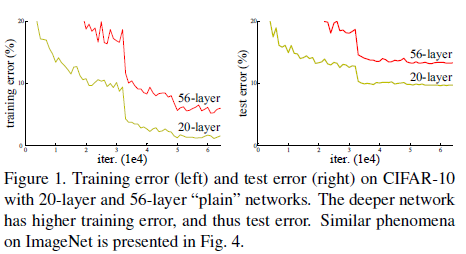
- 깊은 신경망 = 성능 향상: 일반적으로 레이어를 많이 쌓은(=깊은) 신경망은 더 복잡한 문제를 잘 풀 수 있습니다.
- 하지만 너무 깊으면 문제 발생:
- 학습이 어려워짐 (Vanishing/Exploding Gradient 문제)
- 학습 오류가 줄지 않음 (오히려 더 깊게 만들수록 성능이 나빠지는 degradation problem)
예: 20층짜리 네트워크보다 56층짜리 네트워크가 학습 성능이 더 나쁠 수 있음.
해결책: Residual Learning
- 일반적인 딥러닝은 각 레이어가 입력값을 바탕으로 직접 출력값을 학습합니다.
- ResNet은 이 과정을 다르게 합니다:
- 각 레이어가
출력 = 입력 + 변화량(F(x))을 학습합니다. - 즉, "입력에서 얼마나 바뀌어야 하는지"(잔차, residual)만 학습합니다.
- 이런 방식이 훨씬 학습이 쉽고 안정적이라는 것이 논문의 주장입니다.
- 각 레이어가
기술적으로는 어떻게?
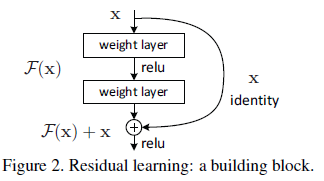
- Shortcut connection (지름길 연결, 위 그림 참고):
- 몇 개의 레이어를 건너뛰어 입력을 그대로 다음 레이어에 더해줍니다.
- 별도의 학습 파라미터 없이도 구현 가능.
- 성능을 높이고 학습도 쉬워집니다.
실험 결과
- ImageNet 데이터셋에서 최대 152층의 ResNet을 성공적으로 학습시킴.
- 8배 더 깊지만, 복잡도는 낮고 성능은 뛰어남.
- ILSVRC 2015 이미지 분류 대회에서 1등 차지.
- COCO 데이터셋에서도 탐지, 분할 등 다양한 과제에서 1등.
- 1000층짜리 네트워크도 실험적으로 학습 가능했음.
결론
- Residual Learning은 깊은 네트워크의 학습 문제를 극복하고,
- 다양한 시각 인식 문제에 효과적이며 일반적인 방식으로 적용 가능함.
2. Related Work
2.1. Residual Representations (잔차 표현)
요점:
- 잔차(residual)를 사용하는 개념은 이미지 인식, 저수준 비전, 컴퓨터 그래픽스 등 여러 분야에서 사용되고 있었습니다.
주요 예시:
- VLAD, Fisher Vector:
- 이미지의 특징을 딕셔너리에 대해 잔차 벡터(residual vector)로 표현하는 방식.
- Fisher Vector는 확률적인 버전.
- 이미지 검색이나 분류에 효과적.
- Residual Vector Encoding:
- 원래의 벡터를 직접 인코딩하는 것보다 잔차 벡터를 인코딩하는 것이 더 효과적이라는 연구도 있음.
- Multigrid Method (PDE 해결):
- 여러 해상도에서 문제를 나눠서 해결하는데, 각 단계가 잔차 문제를 푸는 방식으로 동작함.
- Hierarchical Basis Preconditioning:
- 서로 다른 해상도 간의 잔차를 변수로 표현함.
- 이들 방식은 최적화가 더 빠르게 수렴하는 것으로 알려져 있음.
요약:
- 잔차를 사용하는 방식은 기존에도 최적화를 단순화시키는 유용한 방식으로 사용되어 왔음.
- ResNet도 같은 철학을 따름: "직접 학습하는 대신, 변화량(잔차)을 학습하자."
2.2. Shortcut Connections (지름길 연결)
요점:
- 레이어를 건너뛰는 지름길 연결 아이디어도 새로운 개념은 아니며, 예전부터 여러 방식으로 시도되어 왔습니다.
주요 예시:
- 초기 MLP에서는 입력을 출력에 바로 연결하는 선형 레이어를 추가하기도 했음.
- Auxiliary classifier 사용 (GoogLeNet 등):
- 중간 레이어에 작은 분류기를 붙여 기울기 소실 문제를 해결함.
- Centering 방법 :
- 레이어의 출력, 기울기, 에러를 정규화시키기 위해 지름길 연결을 사용함.
- Inception 구조:
- 여러 가지 블록 중 하나가 shortcut 역할을 함.
- Highway Network :
- 게이트(gate)가 달린 지름길 연결 사용.
- gate는 학습 가능한 파라미터로 입력을 통과시킬지 말지 결정함.
- 하지만 이 구조는 ResNet과는 다름:
- 게이트가 닫히면 shortcut이 막히고, 그 레이어는 비잔차 함수를 학습함.
- ResNet은 항상 잔차 함수만 학습하며, 지름길 연결은 항상 열려 있고 항상 정보를 통과시킴.
요약:
- ResNet은 기존의 지름길 연결 방식과 비슷하지만 항상 정보를 통과시키며, 항상 잔차를 학습한다는 점에서 독창적입니다.
- 특히 ResNet은 100층 이상의 매우 깊은 네트워크에서도 성능 향상을 보여주는데, Highway Network는 그렇지 못했음.
3. Deep Residual Learning
3.1. Residual Learning
요약
"신경망이 어떤 함수 를 직접 배우는 것보다, 그 함수와 입력의 차이 를 배우는 것이 더 쉽다."
이 아이디어가 ResNet의 핵심입니다.
배경 설명
- 일반적인 신경망에서는 입력 를 넣고, 여러 층을 거쳐서 원하는 출력 를 학습합니다.
- 그런데 층이 많아질수록 (딥해질수록) 학습이 더 어려워지고, 오히려 성능이 떨어지는 현상이 발견되었습니다. 이걸 "degradation problem (성능 저하 문제)"라고 합니다.
- 이유 중 하나는, 여러 비선형 레이어가 모여서 "항등 함수(identity mapping)" — 즉 입력을 그대로 출력하는 단순한 함수조차도 잘 학습하지 못하는 경우가 있다는 겁니다.
Residual Learning 방식
그래서 이 논문에서는 새로운 방식으로 문제를 재정의합니다:
- 를 직접 학습하는 대신,
- 를 학습하도록 만듭니다.
- 즉, 를 로 표현하고, 신경망이 만 학습하게 하는 것이죠.
이렇게 하면 두 가지 장점이 생깁니다:
1. 학습이 쉬워집니다.
만약 가 입력과 거의 비슷한 함수라면 (), 는 거의 0에 가까운 작은 값이 됩니다. 즉, 신경망이 아주 작은 변화(잔차)만 학습하면 되므로 더 빠르고 안정적으로 학습할 수 있습니다.
2. 항등 함수도 잘 표현할 수 있습니다.
최적 함수가 항등 함수라면, 신경망의 가중치를 0으로 만들기만 하면 되므로 훨씬 쉽게 구현됩니다.
실험 결과도 제시됨
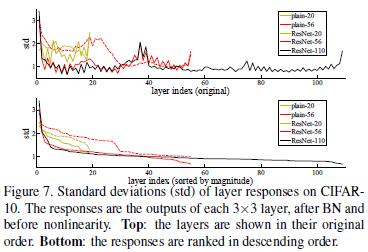
"Fig. 7에서 보여주듯, 실제 실험에서 학습된 의 출력은 작다. 즉, 라는 가정이 그럴듯하며, 잔차 학습이 유리하다는 것을 보여준다."
한 문장 요약
ResNet은 함수를 직접 학습하지 말고, 입력과 출력의 차이(잔차, residual)를 학습하자는 아이디어를 통해, 깊은 신경망에서도 성능 저하 없이 효율적인 학습이 가능하도록 했습니다.
3.2. Identity Mapping By Shortcuts
3.2.1. 핵심 아이디어: 지름길 연결 (Shortcut Connections)
이전 섹션(3.1)에서 우리는 다음과 같은 잔차 학습 형태를 배웠습니다:
- 여기서 는 입력 에 대해 신경망이 학습할 "잔차 함수(residual function)"
- 는 "그냥 그대로 더해주는 입력"
- 구조 덕분에 학습이 쉬워지고 성능도 향상됩니다.
3.2.2. 이 구조를 어떻게 신경망에 적용하나?
기본 블록 (building block)
-
이 구조를 몇 개의 레이어마다 한 번씩 적용합니다.
-
예를 들어, 아래와 같은 2개의 레이어로 구성된 블록이 있다고 해봅시다:
-
전체 출력은:
-
여기서 는 실제 학습할 대상이고, 는 shortcut connection으로 입력을 그대로 더해주는 역할입니다.
-
마지막에 ReLU 같은 비선형 함수를 하나 더 붙일 수 있습니다 (즉, 형태).
3.2.3. 중요한 포인트들
1. 추가 계산이 거의 없다
- 는 단순한 원소별 덧셈(element-wise addition)이기 때문에 매우 빠르고 가볍습니다.
- 그래서 모델 파라미터 수나 계산량 증가 없이 ResNet을 구현할 수 있습니다.
2. 입력과 출력의 차원이 같아야 한다
-
와 는 차원이 같아야 더할 수 있습니다.
-
만약 차원이 다르다면? → 선형 변환()을 통해 맞춰줍니다:
- 여기서 는 주로 1x1 convolution 등을 써서 차원을 바꿉니다.
- 하지만 가능한 한 identity mapping (그냥 더하기)를 선호합니다. 그게 더 간단하고 효과도 좋기 때문입니다.
3. 잔차 함수 는 유연하게 구성 가능
- 는 2개나 3개의 레이어로 만들 수 있고, 더 많아도 괜찮습니다.
- 단, 한 개의 레이어만 쓴 경우는 효과가 별로 없었습니다.
- 이때는 사실상 단순한 선형 함수 라 학습 성능 향상에 큰 기여를 하지 못합니다.
4. 이 개념은 CNN에도 적용 가능
- 비록 수식에서는 Fully-connected (완전 연결) 레이어를 쓰는 듯 보이지만, 실제 실험에서는 Convolutional Layer에 적용됩니다.
- 이때 덧셈은 채널별로 특성 맵(feature map)을 더하는 방식입니다.
요약 한 줄
ResNet은 입력을 그대로 다음 층에 더해주는 지름길 연결(shortcut connection)을 사용하여, 신경망이 학습해야 할 부분(F(x))을 줄이고 효율적이고 안정적인 학습을 가능하게 합니다.
3.3. 네트워크 아키텍처 (Network Architectures)
이번 섹션에서는 다양한 plain network(기본 네트워크)와 residual network(잔차 네트워크)를 실험해본 결과를 공유합니다. 이 중 ImageNet 데이터셋을 기준으로 테스트한 두 가지 모델을 소개합니다.
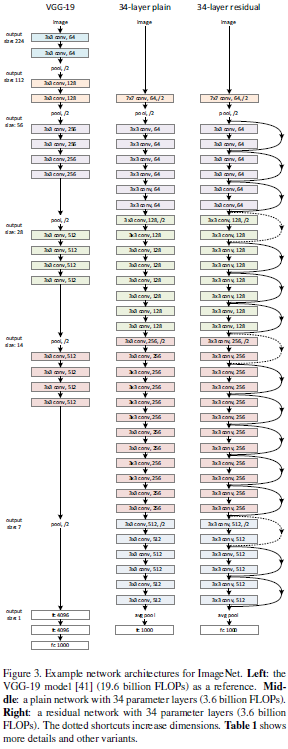
3.3.1. Plain Network (기본 네트워크)
Plain 네트워크는 VGG 네트워크의 설계 철학을 참고해서 만들었습니다. (Fig. 3 왼쪽 참고)
(VGG 네트워크는 간단한 구조로 유명한데, 3x3 크기의 작은 필터를 반복해서 쌓는 방식입니다.)
설계 규칙
Plain 네트워크는 다음과 같은 간단한 두 가지 규칙을 따릅니다.
- 출력 feature map 크기가 같으면, 같은 수의 필터(채널)를 사용한다.
- feature map 크기가 절반으로 줄어들면, 필터 수를 두 배로 늘린다.
→ 이렇게 하면, 레이어별로 계산량(연산량, FLOPs)이 비슷하게 유지됩니다.
다운샘플링 방법
- 다운샘플링(해상도를 줄이는 작업)은 별도의 풀링 레이어를 쓰지 않고,
- stride가 2인 convolution layer로 직접 처리합니다.
네트워크 구조
- 네트워크의 마지막은 Global Average Pooling 레이어로 feature map의 평균을 구합니다.
- 이어서 1000개의 클래스를 분류하는 fully-connected 레이어(FC)와 softmax를 거쳐 최종 출력을 만듭니다.
- 전체 네트워크에는 학습 가능한 weighted layer가 총 34개 있습니다.
VGG 네트워크와 비교
Plain 네트워크는 VGG 네트워크에 비해 훨씬 가볍습니다.
- 34-layer plain network의 연산량은 약 3.6 billion FLOPs입니다.
- 반면 VGG-19는 약 19.6 billion FLOPs입니다.
- 즉, plain network는 VGG-19 대비 18% 수준의 연산량만으로 동작합니다.
→ 더 적은 계산으로 효율적인 성능을 낼 수 있도록 설계된 것이 특징입니다.
요약
- Plain 네트워크는 VGG 스타일을 따르면서, 더 가벼운 구조로 설계되었습니다.
- 34개 층으로 구성되었고, 다운샘플링은 stride 2 convolution으로 수행합니다.
- VGG-19보다 훨씬 적은 연산량으로도 효율적인 네트워크를 구성했습니다.
3.3.2. Residual Network (잔차 네트워크)
Residual Network에서는 기존 plain 구조에 shortcut connection(지름길 연결)을 추가합니다.
(Fig. 3 오른쪽 참고)
Shortcut Connection이란?
- 간단히 말하면, 입력 값을 다음 레이어로 바로 더해주는 연결입니다.
- 이렇게 하면 네트워크가 더 깊어져도 학습이 잘 되도록 도와줍니다.
- Residual Network의 핵심 아이디어는 "학습해야 하는 것을 직접 다 배우는 대신, 변화량(residual)만 학습하자"는 것입니다.
Shortcut의 종류
Shortcut을 넣을 때 상황에 따라 두 가지 경우가 있습니다.
(1) 입력과 출력 차원이 같을 때
- 그냥 입력을 그대로 더해주기만 하면 됩니다.
- 추가 계산이나 파라미터가 필요 없습니다.
- → 실선(shortcut)으로 표현 (Fig. 3 참고)
(2) 출력 차원이 커질 때
- feature map 크기(또는 채널 수)가 커지면 그냥 더할 수 없기 때문에 방법을 선택해야 합니다.
옵션은 두 가지입니다:
| 옵션 | 설명 |
|---|---|
| (A) 제로 패딩 (Zero Padding) | shortcut을 그대로 사용하고, 부족한 부분은 0으로 채운다. 추가 파라미터가 없다. |
| (B) 프로젝션(Projection) | 1x1 convolution을 사용해서 shortcut 경로도 출력 차원에 맞게 변환한다. (아래 식 참고) |
- 두 옵션 모두, feature map의 공간 크기(width/height)가 줄어들 때는 stride 2를 사용해 downsampling을 수행합니다.
요약
- Residual Network는 plain 구조에 shortcut connection을 추가해 학습을 더 쉽게 만든 구조입니다.
- 입력과 출력 차원이 같으면 그냥 더하고, 다를 경우에는 제로 패딩 또는 프로젝션으로 맞춰줍니다.
- 이 방법으로 네트워크를 훨씬 깊게 쌓아도 학습이 잘 되는 효과를 얻을 수 있습니다.
4. Experiments (실험)
4.1. 18-layer, 34-layer 네트워크 실험
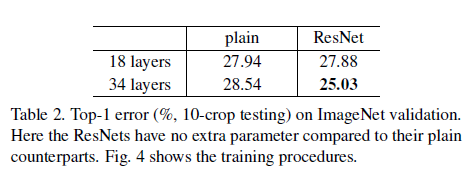
- Plain Net (기존 네트워크): 단순히 레이어만 쌓은 모델입니다.
- ResNet: 각 두 개의 3x3 convolution 사이에 shortcut connection (skip connection)을 추가한 모델입니다. 이 shortcut은 주로 identity mapping (그냥 입력을 더해주는 것)입니다.
- 결과:
- Plain Net에서는 깊어질수록 오히려 성능이 떨어졌습니다.
- ResNet에서는 34층이 18층보다 2.8% 더 좋은 성능을 보였고, 학습 오차(training error)도 더 낮았습니다.
- 즉, ResNet은 층이 깊어져도 성능이 좋아진다는 것을 증명했습니다.
4.2. Plain Net vs ResNet
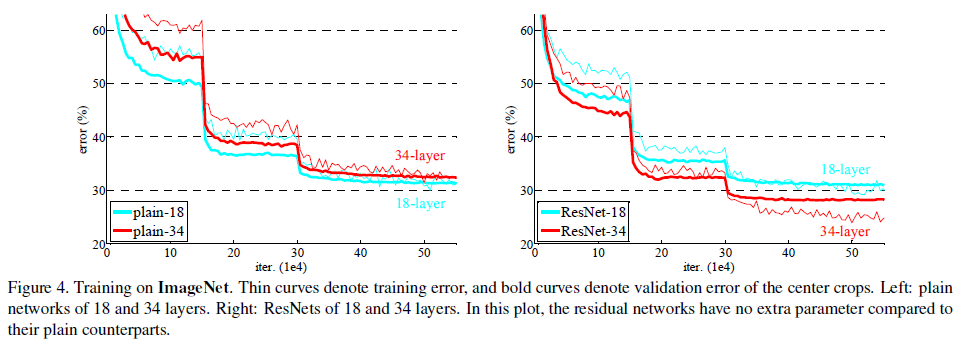
- 34층 네트워크 기준:
- ResNet은 Plain Net 대비 Top-1 에러를 3.5% 감소시켰습니다.
- 이는 residual learning 덕분에 학습 최적화가 쉬워졌기 때문입니다.
- 18층 네트워크 기준:
- Plain과 ResNet 모두 비슷한 정확도를 보였지만, ResNet이 더 빠르게 수렴했습니다.
4.3. Shortcut 방법 비교 (Identity vs Projection)
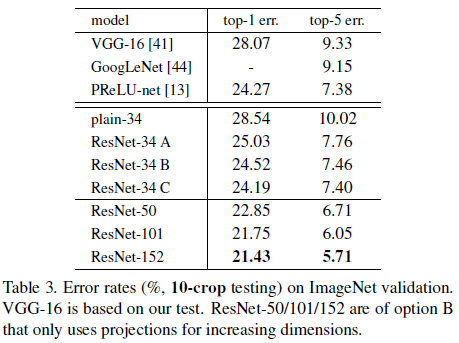
- 세 가지 방법을 비교했습니다:
- (A) Zero-padding shortcut (차원 증가 시만 0을 채움)
- (B) Projection shortcut (차원 증가 시 projection 사용, 나머지는 identity)
- (C) 모든 shortcut에 projection 사용
- 결과:
- 세 가지 모두 Plain Net보다 성능이 좋았습니다.
- (B)가 (A)보다 약간 더 좋고, (C)는 (B)보다 아주 조금 더 좋았습니다.
- 그러나 (C)는 매 shortcut마다 파라미터가 추가되어 모델이 커지고 비효율적이 되기 때문에, 실용적인 측면에서 (B) 또는 (A)를 선호했습니다.
4.4. 더 깊은 Bottleneck 구조
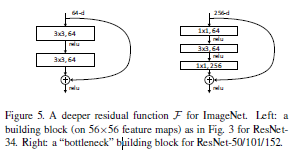
- 50층 이상의 네트워크에서는 시간과 메모리 효율을 고려해 Bottleneck 구조를 사용했습니다.
- 하나의 residual block을 1x1, 3x3, 1x1 convolution 3단계로 구성합니다.
- 1x1 conv로 차원을 줄였다가, 3x3 conv에서 처리하고, 다시 1x1 conv로 차원을 복구합니다.
- Identity shortcut을 사용하면 모델 크기와 연산량을 줄일 수 있습니다.
4.5. 50/101/152-layer ResNet
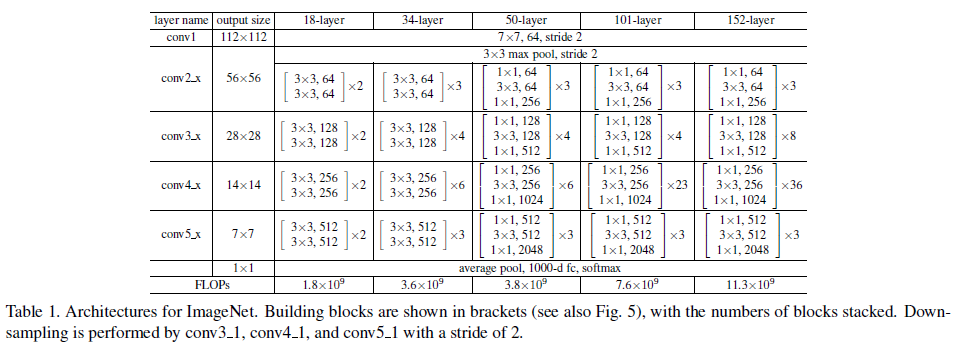
- 50-layer, 101-layer, 152-layer ResNet을 제작했습니다.
- 152-layer 모델은 VGG-16, VGG-19보다 연산량이 적음에도 불구하고, 훨씬 더 좋은 성능을 보였습니다.
- 깊이가 늘어나면서도 성능 저하 없이 정확도가 계속 상승했습니다.
6. 대회 성과
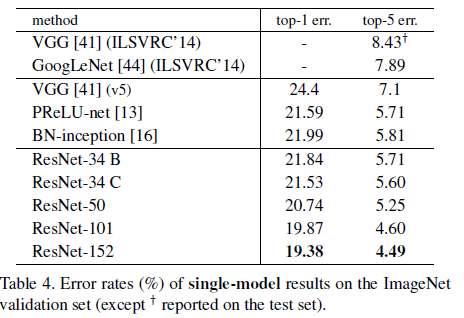
- 단일 모델로 4.49% top-5 validation error를 기록했습니다 (기존 ensemble 모델보다 좋음).
- 여러 깊이의 모델을 앙상블해서 3.57%까지 줄였고, ILSVRC 2015 대회에서 1등을 차지했습니다.
요약
ResNet은 shortcut 연결을 통해 층이 깊어지더라도 학습이 어려워지는 문제(성능 저하 문제)를 해결하고, 더 깊은 네트워크를 만들 수 있게 해줍니다. 이를 통해 기존 네트워크보다 훨씬 좋은 성능을 달성했습니다.
