
최근 몇 년간 우리가 열광해 온 놀라운 AI 이미지 생성 모델들은 대부분 'U-Net'이라는 특정 신경망 아키텍처에 의존해 왔습니다. 하지만 변화가 빠른 인공지능 분야에서, 판도를 뒤흔들 새로운 강자가 등장했습니다. 바로 Diffusion Transformer(DiT)입니다.
디퓨전(Diffusion) 과정에서 U-Net을 덜어내고 그 자리를 트랜스포머로 대체한다면 어떤 일이 벌어질까요? 이 단순하면서도 혁신적인 아이디어가 어떻게 작동하는지, 왜 중요한지, 그리고 DiT가 어떻게 이미지 생성의 새로운 'State-of-the-Art'가 되었는지 자세히 파헤쳐 보겠습니다.
DiT의 핵심 구조 (The Anatomy of a Diffusion Transformer)
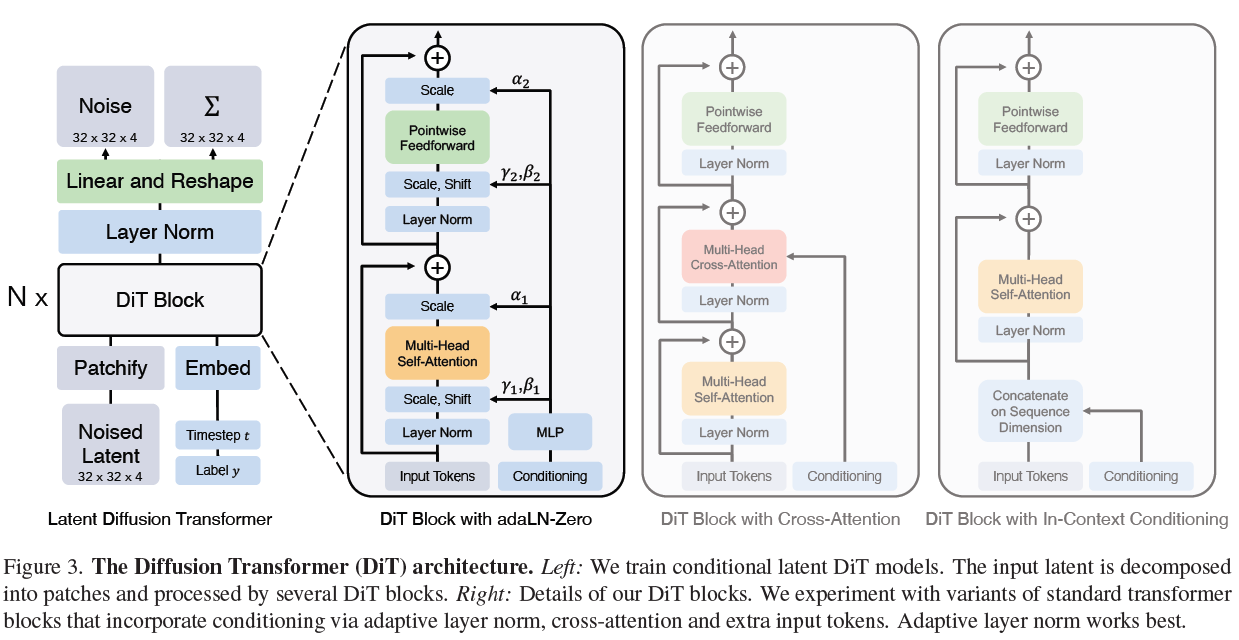
기존의 U-Net은 컨볼루션(Convolutional) 레이어들을 통해 이미지를 처리합니다. 반면 DiT는 그 구조적 철학을 Vision Transformer(ViT)에서 가져왔습니다. 이미지를 전통적인 픽셀의 격자로 보는 대신, 마치 문장 속 단어들의 연속(sequence)처럼 다루는 것이죠.
논문에 제시된 아키텍처 다이어그램을 바탕으로 DiT의 작동 방식을 단계별로 살펴보겠습니다.
- Patchify (패치화): 모델은 먼저 VAE(Variational Autoencoder)를 통해 압축된 이미지의 공간적 표현(잠재 표현, latent)을 입력으로 받아 "Patchify" 레이어를 통과시킵니다. 이 레이어는 입력을 평면 토큰(patch)들의 시퀀스로 잘게 쪼갭니다.
- Transformer Blocks (트랜스포머 블록): 쪼개진 토큰들은 일련의 표준 트랜스포머 블록들을 차례로 통과합니다.
- adaLN-Zero를 통한 조건부 제어 (Conditioning): 생성 모델은 단순히 노이즈를 지우는 것을 넘어 '무엇을' 만들지 알아야 하므로 클래스 레이블이나 노이즈 타임스텝 같은 조건부 입력(Conditional input)이 필요합니다. DiT는 이를 처리하기 위해 오른쪽 다이어그램에 묘사된 'adaLN-Zero(적응형 레이어 정규화)' 블록을 사용합니다. 이 블록은 잔차 연결(residual connections) 직전에 적용되는 스케일링 파라미터를 회귀(regress)합니다. 연구진은 이 블록들을 항등 함수(identity function)로 초기화하는 것이 컴퓨팅 효율성을 챙기면서도 최고의 성능을 낸다는 것을 발견했습니다.
- Decoding (디코딩): 마지막으로 선형 디코더(linear decoder)가 처리된 토큰들을 원래의 공간 레이아웃으로 되돌려 노이즈와 공분산을 예측해 냅니다.
DiT의 핵심 경쟁력: 강력한 확장성 (Scalability)
Diffusion Transformer의 가장 놀라운 발견은 바로 엄청난 '확장성'에 있습니다.
머신러닝에서는 모델의 순방향 패스(forward pass) 복잡도를 "Gflops"라는 단위로 측정합니다. 연구진은 DiT 모델의 Gflops와 이미지 생성 품질(FID 점수) 사이에 강력하고 일관된 상관관계가 있음을 밝혀냈습니다.
간단히 말해, "연산량이 많을수록 더 나은 이미지가 생성된다"는 뜻입니다. DiT 모델의 성능을 끌어올리려면 크게 두 가지 방법을 쓸 수 있습니다.
- 트랜스포머의 깊이나 너비를 늘리기 (모델 사이즈 키우기)
- 패치 크기(patch size)를 줄여 입력 토큰의 수를 늘리기
최고 수준의 결과 (State-of-the-Art Results)
연구진이 아키텍처의 스케일을 가장 큰 모델인 DiT-XL/2로 키웠을 때, 그 결과는 매우 인상적이었습니다.
- 클래스 조건부 ImageNet 벤치마크에서 FID 2.27이라는 당시 최고 수준(State-of-the-Art)의 기록을 달성했습니다.
- ADM이나 LDM과 같은 기존의 강력한 U-Net 기반 디퓨전 모델들을 모두 뛰어넘었으며, 심지어 연산 효율성 면에서도 우위를 점했습니다.
결론 (The Bottom Line)
Diffusion Transformer는 최고 수준의 이미지를 생성하는 데 있어 굳이 'U-Net의 귀납적 편향(inductive bias)'이 필수적이지 않다는 것을 증명했습니다. 표준화된 트랜스포머 아키텍처를 채택함으로써, 이제 디퓨전 모델도 자연어 처리(NLP) 분야의 눈부신 성장을 이끌었던 예측 가능한 '확장 법칙(Scaling laws)'의 혜택을 온전히 누릴 수 있게 되었습니다. 앞으로 DiT가 이끌어갈 생성형 AI의 다음 챕터가 더욱 기대되는 이유입니다.
