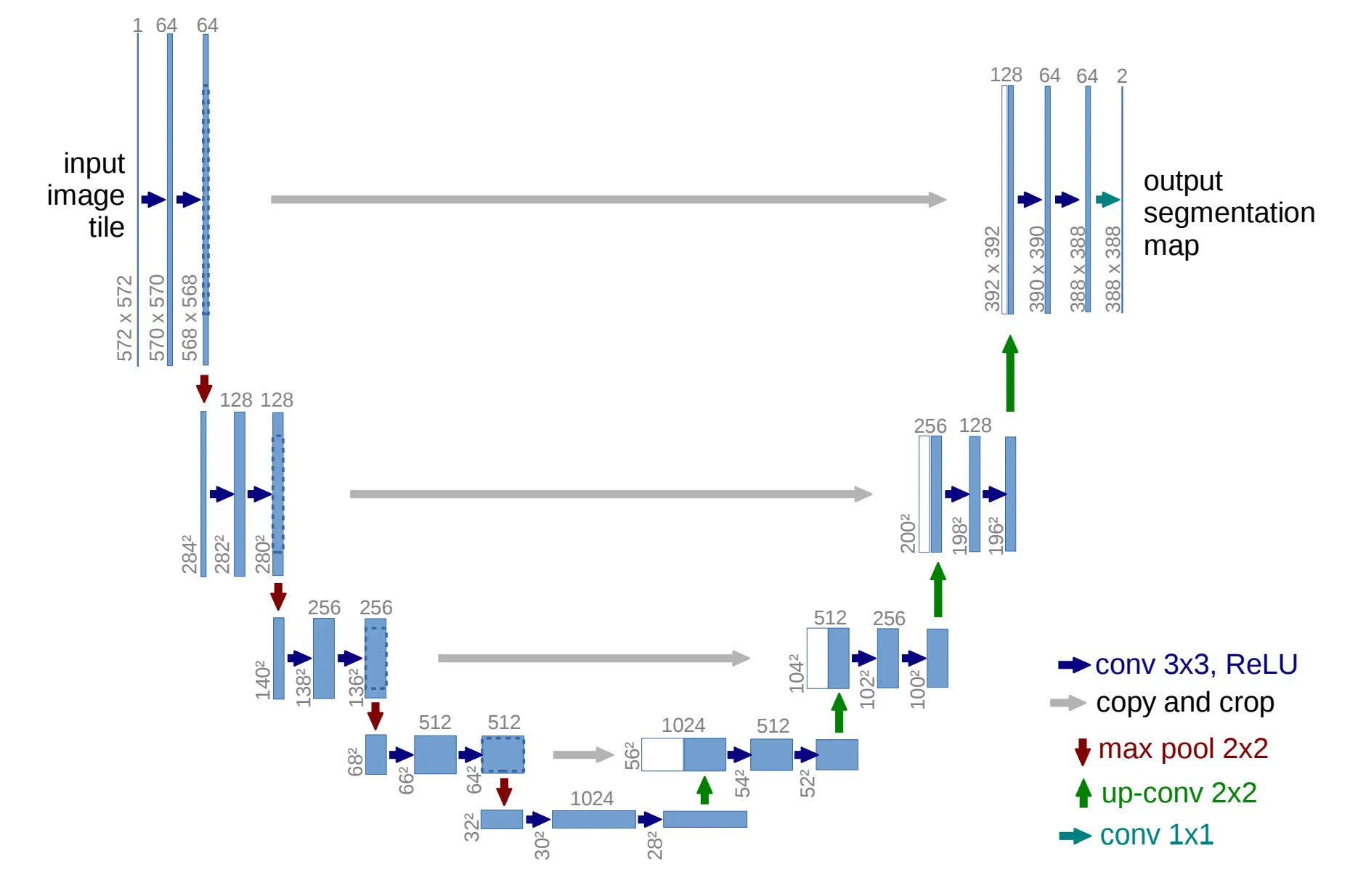
최신 이미지 생성 모델, 특히 Cascade Diffusion Model들이 공통적으로 채택하는 네트워크 구조가 있습니다. 바로 U-Net입니다.
오늘은 해당 논문의 'Architectures' 섹션을 바탕으로, 왜 U-Net이 확산 모델의 표준이 되었는지, 그리고 확산 과정의 핵심 파라미터인 , , 등이 내부에서 어떻게 처리되는지 수식적 관점에서 정리해 보겠습니다.
1. U-Net: 역방향 프로세스(Reverse Process)를 위한 최적의 선택
확산 모델(Diffusion Model)의 핵심은 노이즈가 섞인 상태에서 원본을 복원해 나가는 역방향 프로세스(Reverse Process)를 학습하는 것입니다.
입력과 출력의 관계
이 과정에서 네트워크는 손상된 데이터(corrupted data), 즉 를 입력받습니다. 그리고 이 의 노이즈 분포를 역추적하기 위한 파라미터를 출력해야 합니다. 논문에서는 이를 다음과 같이 정의합니다.
- Input: (시점 에서의 노이즈 이미지)
- Output: (역방향 프로세스의 평균과 분산 파라미터)
왜 U-Net인가?
여기서 중요한 제약 조건이 있습니다. 출력되는 파라미터 는 입력된 이미지 와 동일한 공간적 차원(Spatial Dimensions)을 가져야 한다는 점입니다.
U-Net(Ronneberger et al., 2015)은 이미지를 압축(Downsampling)했다가 다시 복원(Upsampling)하면서도, Skip Connection을 통해 공간 정보를 유지하는 특성이 있습니다. 따라서 라는 이미지 형태의 입력을 받아, 픽셀별로 대응되는 맵을 출력하기에 가장 '자연스러운 선택(Natural Choice)'이 됩니다.
2. 스칼라 조건 (Scalar Conditioning): 와 클래스 정보
이미지 생성 시에는 '어떤 그림을 그릴지(Class Label)'와 '현재 노이즈 제거 단계가 어디인지(Timestep )'에 대한 정보가 필요합니다. 이는 이미지 형태가 아닌 스칼라 값입니다.
- Diffustion Timestep:
- Class Label: (또는 관련 임베딩)
이 스칼라 값들은 네트워크 내에서 임베딩(Embedding) 벡터로 변환된 후, U-Net의 중간 레이어(Intermediate layers)들에 더해지는(Add) 방식으로 주입됩니다. (Ho et al., 2020)
3. 저해상도 이미지 조건 (Low-Resolution Image Conditioning)
Cascade 모델의 핵심은 저해상도 이미지를 힌트로 삼아 고해상도 이미지를 생성하는 것입니다. 즉, 저해상도 이미지가 조건(Condition)으로 들어갑니다.
이 논문에서는 SR3나 Improved DDPM 방식을 차용하여 다음과 같이 처리합니다.
- Upsampling: 저해상도 이미지를 목표 해상도(Desired Resolution)에 맞춰 Bilinear 혹은 Bicubic 방식으로 키웁니다.
- Concatenation: 업샘플링된 이미지를 현재 단계의 입력 와 채널 방향으로 결합(Channelwise Concatenation)합니다.
수식적 흐름 요약
결국 네트워크 는 다음과 같은 형태의 입력을 받게 됩니다.
이렇게 결합된 텐서가 U-Net에 들어가고, 앞서 설명한 임베딩이 중간에 개입하여 최종적으로 를 예측하게 되는 것입니다.
요약 Note
- Architecture: 와 동일한 차원의 를 출력하기 위해 U-Net을 사용.
- Scalar Info: 와 같은 스칼라 값은 임베딩하여 Intermediate Layers에 주입.
- Low-Res Info: 저해상도 이미지는 업샘플링 후 와 Concatenation하여 입력.
References: Ronneberger et al. (2015), Salimans et al. (2017), Ho et al. (2020), Saharia et al. (2021), Nichol and Dhariwal (2021)
