
웹 스크래핑(web scraping)은 웹 페이지에서 우리가 원하는 부분의 데이터를 수집해오는 것을 뜻합니다.
- 한국에서는 같은 작업을 크롤링 crawling 이라는 용어로 혼용해서 쓰는 경우가 많습니다. 원래는 크롤링은 자동화하여 주기적으로 웹 상에서 페이지들을 돌아다니며 분류/색인하고 업데이트된 부분을 찾는 등의 일을 하는 것을 뜻해요.
- 구글 검색을 할 때는 web scraping 으로 검색해야 우리가 배우는 페이지 추출에 대한 결과가 나올 거예요!
네이버 영화 순위 페이지에서 영화 제목들을 스크래핑해보겠습니다.
링크: https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303
-
크롬 브라우저에 페이지를 띄우고 개발자도구를 열어 HTML 구조를 파악한다.
- 각 영화들이 old_content라는 id를 갖는 div 안에 table 안에 tbody 안에 tr 태그로 들어있네요.
- 일부 tr은 가로줄을 표시하기 위한 태그라서 영화 정보가 없습니다.
- 각 영화 정보에서 제목은 title이라는 클래스를 갖는 td 안에 div 안에 있는 a 태그의 텍스트로 들어가 있어요.
💡 개발자도구 Elements 탭에서 각 구역을 접어가며 점점 상위 요소를 파악해 id를 갖는 요소까지 올라가면 된다.
-
HTML 구조를 파악하는 데 도움을 주는
beautifulsoup4패키지를 설치한다.
(beautifulsoup은 옛날 버전의 패키지로 호환이 안되므로 꼭beautifoulsoup4를 받아야 합니다.)
그리고 코드 큰 구조를 작성했다.
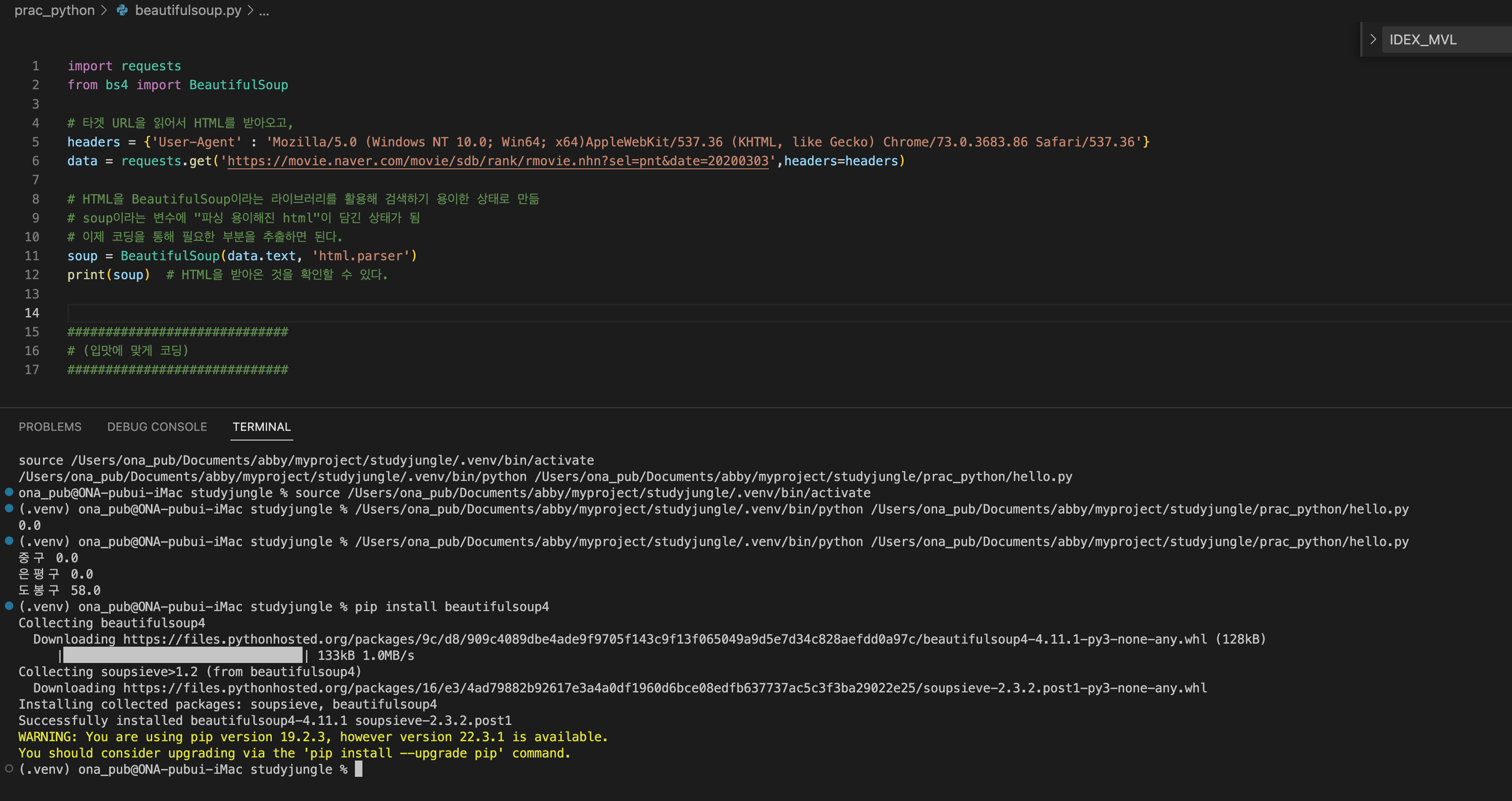
BeautifulSoup 메소드
select()는 조건을 만족하는 모든 요소를 리스트에 담아 반환하고,
select_one()은 그 중 가장 위에 나오는 요소를 반환합니다.
괄호()안 선택자는 css와 동일.
movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
# (조건을 만족하는 첫 번째 요소, 없으면 None을 반환한다.)
a_tag = movie.select_one('td.title > div > a')
print(a_tag)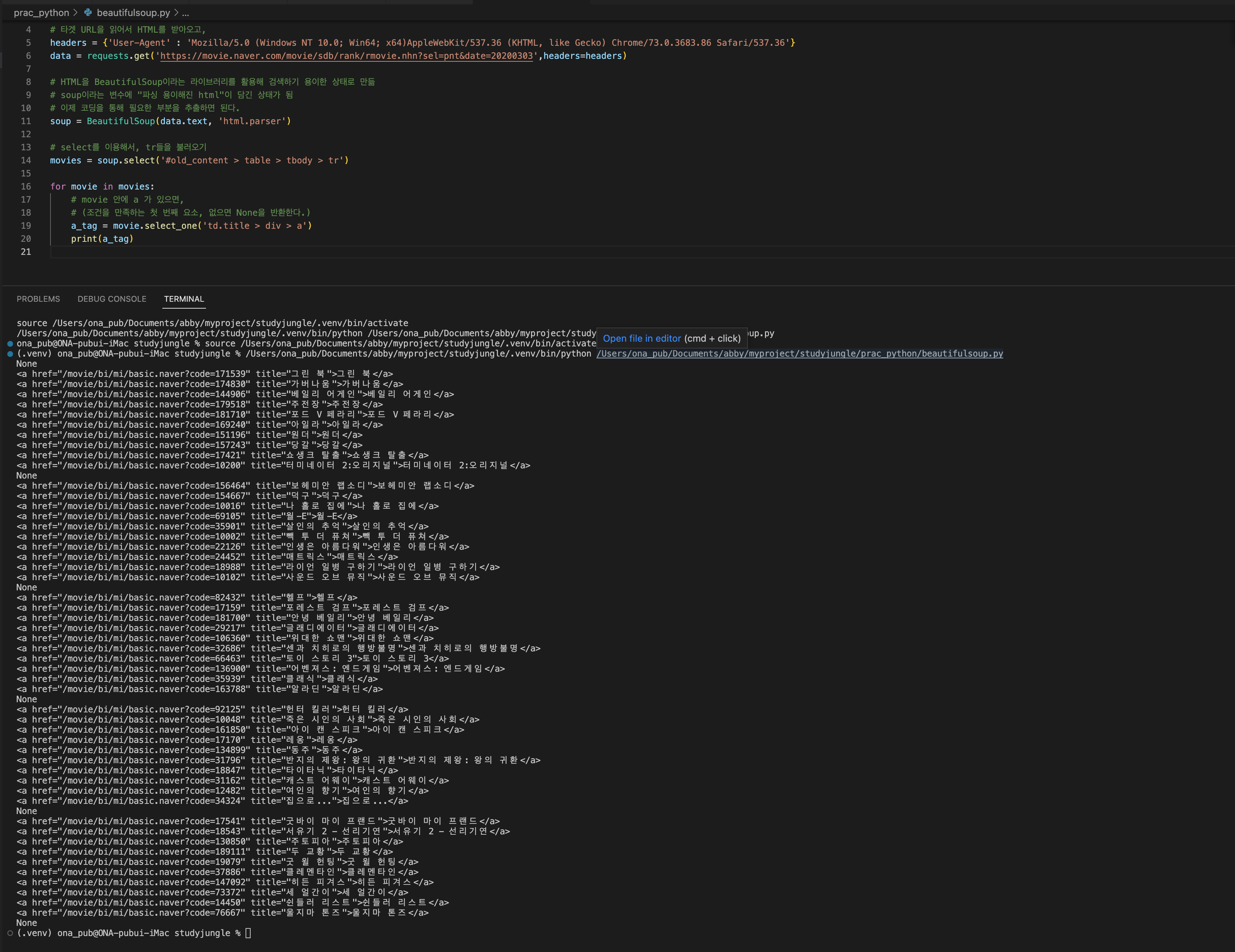
movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
# a의 text를 찍어본다.
print (a_tag.text)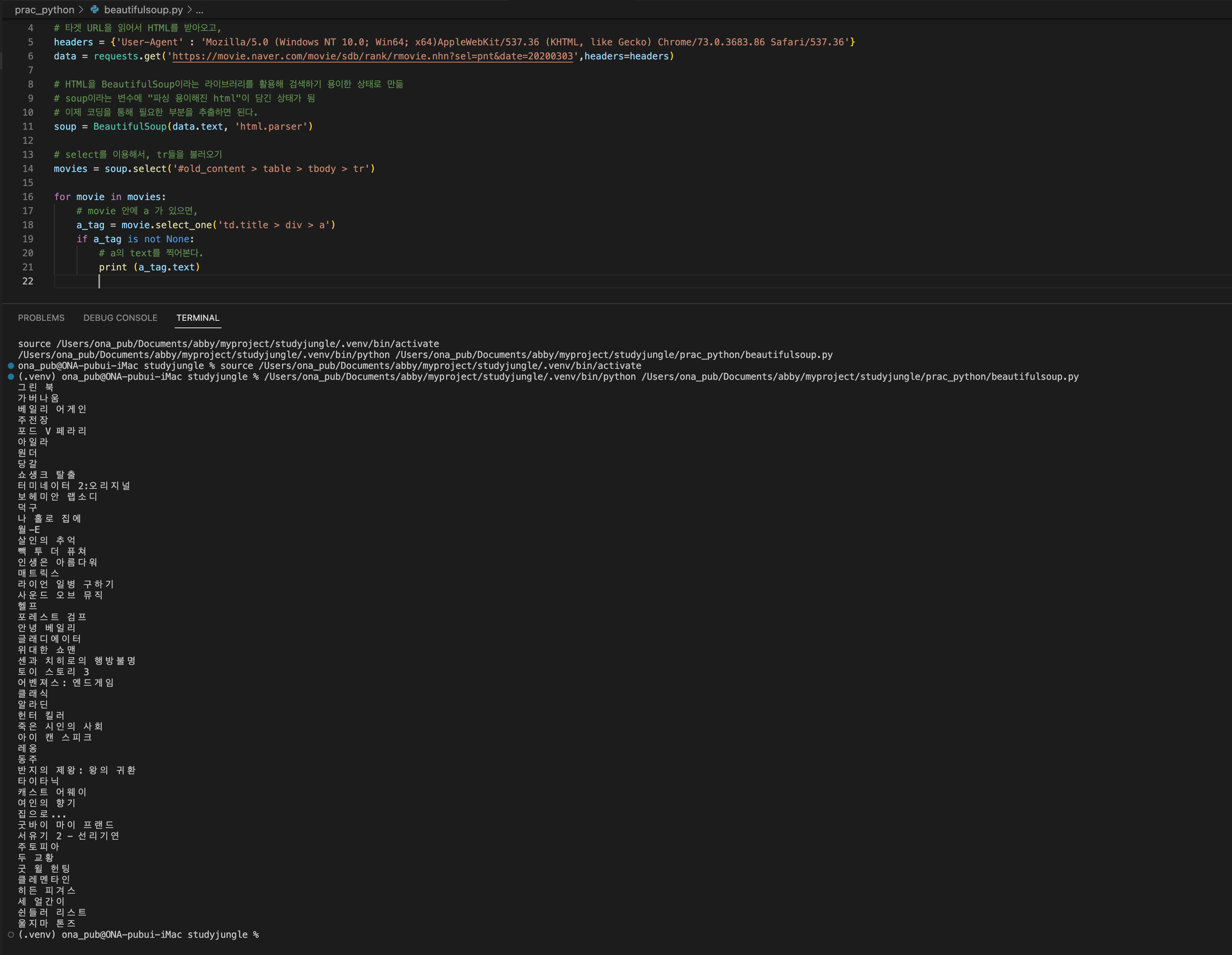
반복문이 돌아갈 때 조건에 맞지 않는 건 None으로 반환되는 점이 자바스크립트와 다르다.
if문이 if a_tag is not None: 과 같은 영어 문장의 꼴인 점도 재밌다.

JS, CSS, HTML, React etc