https://velog.io/@choijaehyeokk/DBMS%EC%99%80-RDBMS
DB
: DataBase - set of data stored in computer.
즉, 컴퓨터에 저장되는 데이터 집합입니다. 이런 데이터들은 쉽게 접근, 사용하기 위해서 구조화된 형태로 존재합니다. (Table, key-value 형태 등등)
DBMS
: DataBase Management System. 말 그대로 해석하면 DB를 관리하는 시스템.
종류
document DB
collection > document > json의 형태로 정보를 저장한다.

정규화 없이 쓰는 게 일반적, 데이터 입출력이 상대적으로 간단하다.
DB를 분산해놓는다.
입출력이 잦으면 사용한다.
MongoDB가 대표적.
MongoDB는 다양한 플랫폼에서 사용할 수 있는 NoSQL 타입의 데이터베이스 프로그램으로, JSON과 비슷한 형태로 자료를 정리합니다.
MongoDB의 자료는 각각의 딕셔너리인 도큐먼트가 모여 컬렉션, 컬렉션이 모여 DB가 되는 형태입니다.
일전에 크롤링한 영화 정보를 예로 들면, 제목/순위/별점이 있는 각 영화 정보가 도큐먼트이고, 이것들을 모인 컬렉션을 크롤링 용 DB에 저장할 수 있겠죠. 만약 네이버 기사 제목을 크롤링했다면 그 결과는 같은 DB에 다른 컬렉션으로 저장할 수 있을 것입니다.
key-value DB
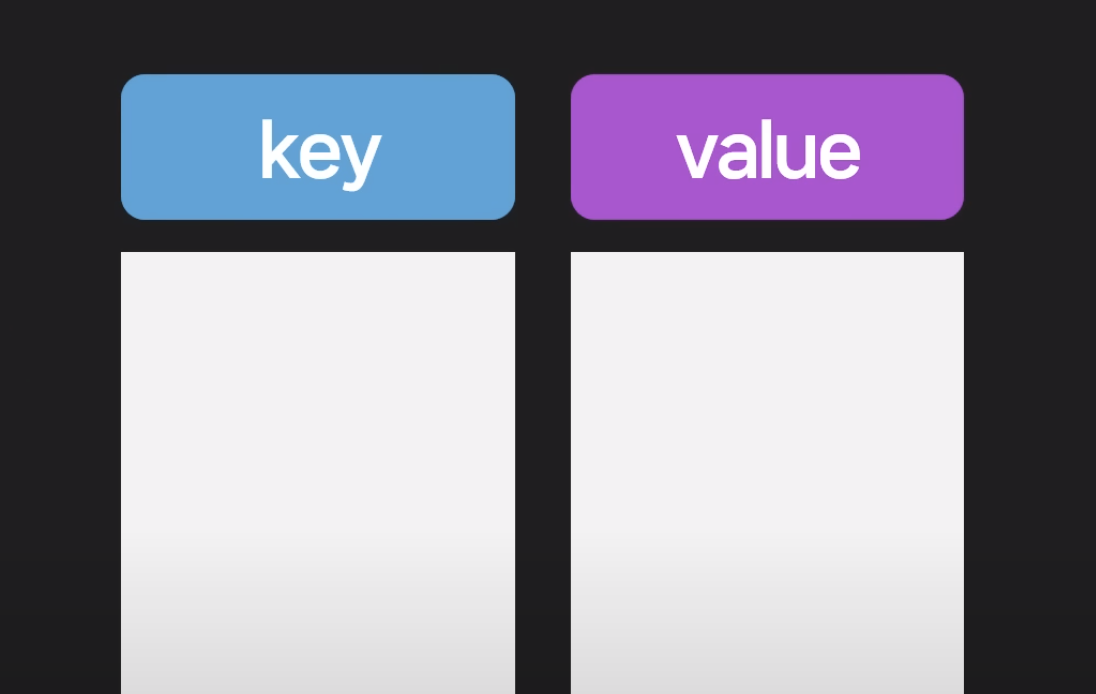
key-value 구조, 예를 들어 이름:홍길동.. 나이:20.. 뭐 이런 식인 데이터를 저장한다.
너무 간단해서 실용성이 떨어져 서브용DB로 많이 쓰인다.
redis라는 서비스가 가장 대표적이다.

redis는 하드디스크가 아닌 REM에 저장해준다. (비교할 수 없이 빠름.)
메인DB와 redis에 중복으로 저장되며, 필요할 때 redis에서 꺼내서 보여주면 빠르다.
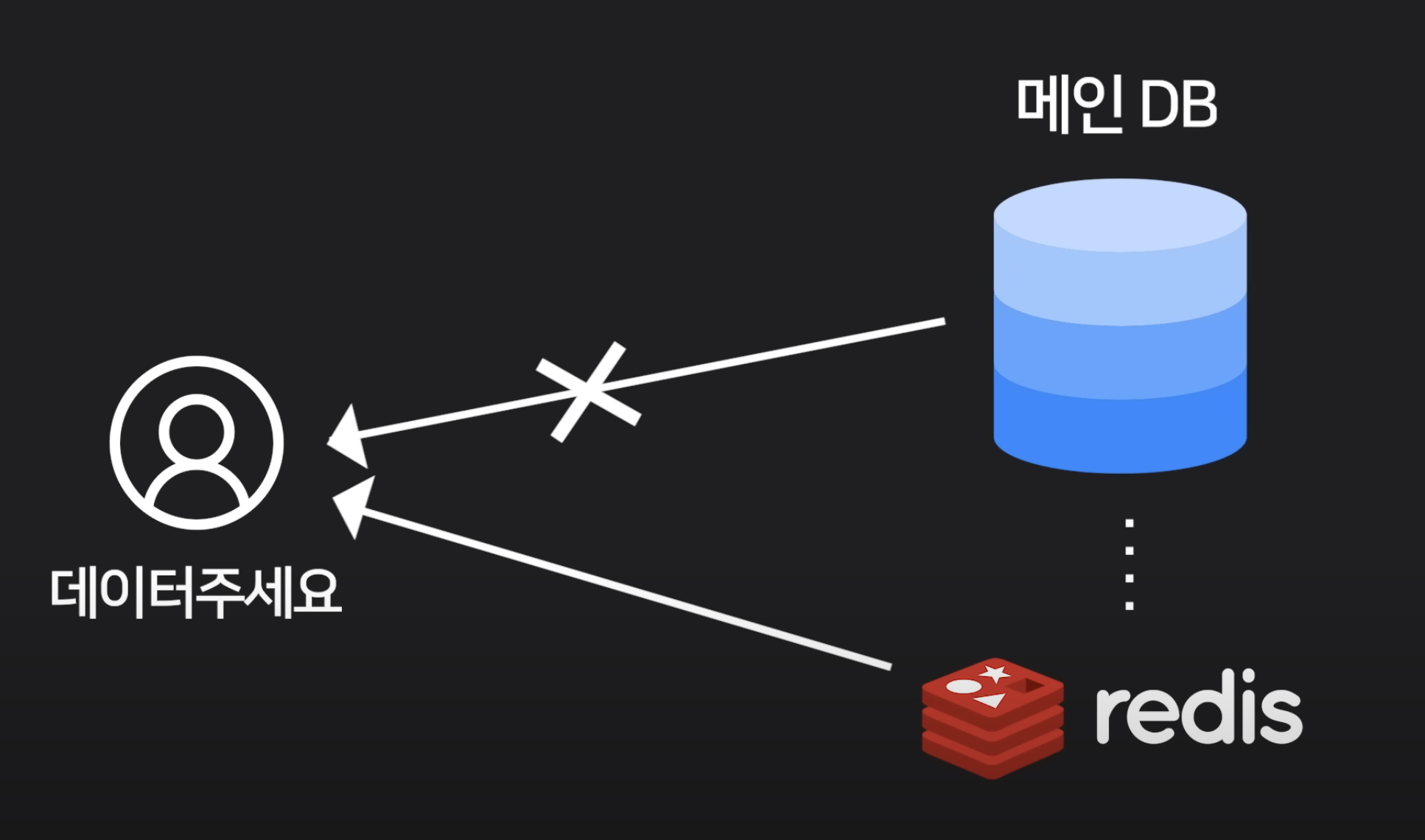
데이터 캐싱, 채팅, 영상 스트리민, 로그인 기록 저장 등에 쓰인다.
Amazon DynamoDB도 있다.

서버리스, 분산된 key-value DB로서 매우 빠르게 많은 것을 쓰고 읽어야 하는 경우 적합하게 사용된다.
key-value DB는 document DB에 비해 어떤 종류의 DB를 얻을 수 있는지가 보다 제한적일 수 밖에 없다. 저장하기 전에 어떠한 정보를 얻을 것인지, 정보에 어떻게 접근할 것인지에 대해 미리 고민이 필요. (NoSQL이기 때문) (정형화된 table 형태인 SQL타입들은 역시 이러한 고민이 적겠지?)
관계형 DB (RDB)

table 위에 이름 지정 후 각각에 맞는 정보 기입 가능. 엑셀도 관계형 data. 정보의 구조가 행과 열로써 존재.
(RDB === SQL DB, 그외 === NoSQL 이라고 말하는 사람도 있었다. 정확히 맞는 말인지는 아직 모르겠다..)
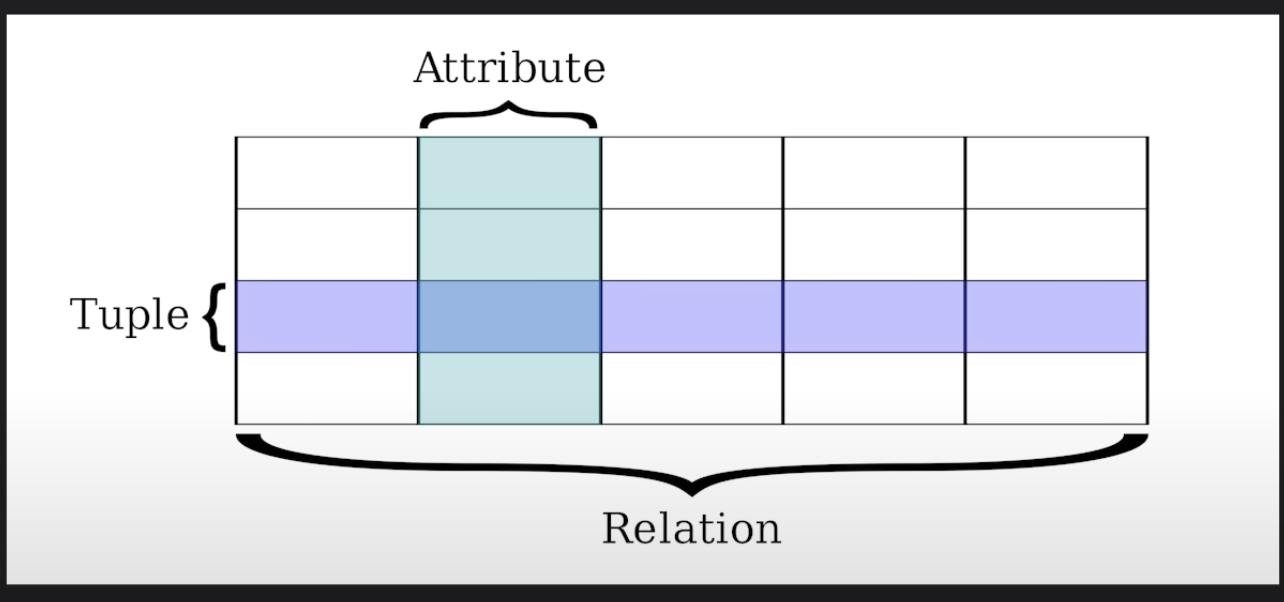
관계(Relation)이라는 용어 자체가 직역으로, 상관관계라는 뜻보단 그냥 표(table)의 개념.
oracle, MySQL, PostgreSQL, MS-SQL 등이 대표적으로 있다.




조금만 서치해도 아주 많은 양의 관련 글이 나온다.
https://velog.io/@jisoo1170/Oracle-MySQL-PostgreSQL-%EC%B0%A8%EC%9D%B4%EC%A0%90%EC%9D%80
- 2차원 구조 모델(열 : 속성, 행 : 튜플, 데이터)을 기반으로한 수평적 구조를 사용, 테이블 형식으로 데이터를 저장합니다. 각 테이블들은 많은 행과 열로 구성되며, 테이블은 구조화된 데이터를 저장하기 위한 엄격한 구조를 제공합니다.
- ACID(원자성, 일관성, 독립성, 지속성) 트랜잭션을 보장하는 기능을 가지는데, 이 기능들은 모든 트랜잭션이 완전하고 정의된 모든 규칙에 따라서 일관성을 가지게 함으로써 오류, 시스템 충돌과 같은 문제가 없는지 확인할 수 있도록 합니다. 이로써 데이터 무결성, 완전성, 정확성을 보장합니다.
ACID
Atomicity : 원자성은 트랜잭셔과 관련된 작업들이 부분적으로 실행되다가 중지되는 것이 아니라 하나의 원자 단위로 수행되는 것을 보장하는 특징입니다. 즉, 중간 단계까지 실행되는 것이 아니라 처음부터 끝까지 완전하게 실행되며 중간에서 실패하는 일이 없도록 합니다.
Consistency : 일관성은 트랜잭션이 완료되면 언제나 일관된 DB 상태를 유지하는 것을 의미합니다.
Isolation : 독립성은 트랜잭션을 수행 할 시, 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것을 의미하는데, 다시말해 다른 트랜잭션의 연산이 중간 단계의 데이터를 볼 수 없음을 의미합니다.
Durability : 지속성은 성공적인 트랜잭션은 영원히 반영되어야 함을 의미합니다. 시스템 에러, DB 일관성 체크 등을 하더라도 유지되어야함을 의미합니다. 트랜잭션은 로그에 모든 것이 저장된 후에만 Commit 상태로 간주될 수 있습니다.
다양한 곳에서 일반적으로 많이 사용된다.
SQL이라는 문법을 사용한다. CRUD 조작을 허용.
중복되는 데이터가 있을 경우 자동으로 정규화 한다.
Graph DB
neo4j가 대표적.
노드 생성 후 안에 정보 기입, 그리고 그 노드들 간의 관계를 기록할 수 있는 형태이다.
Graph Query Language라는 문법을 사용한다.
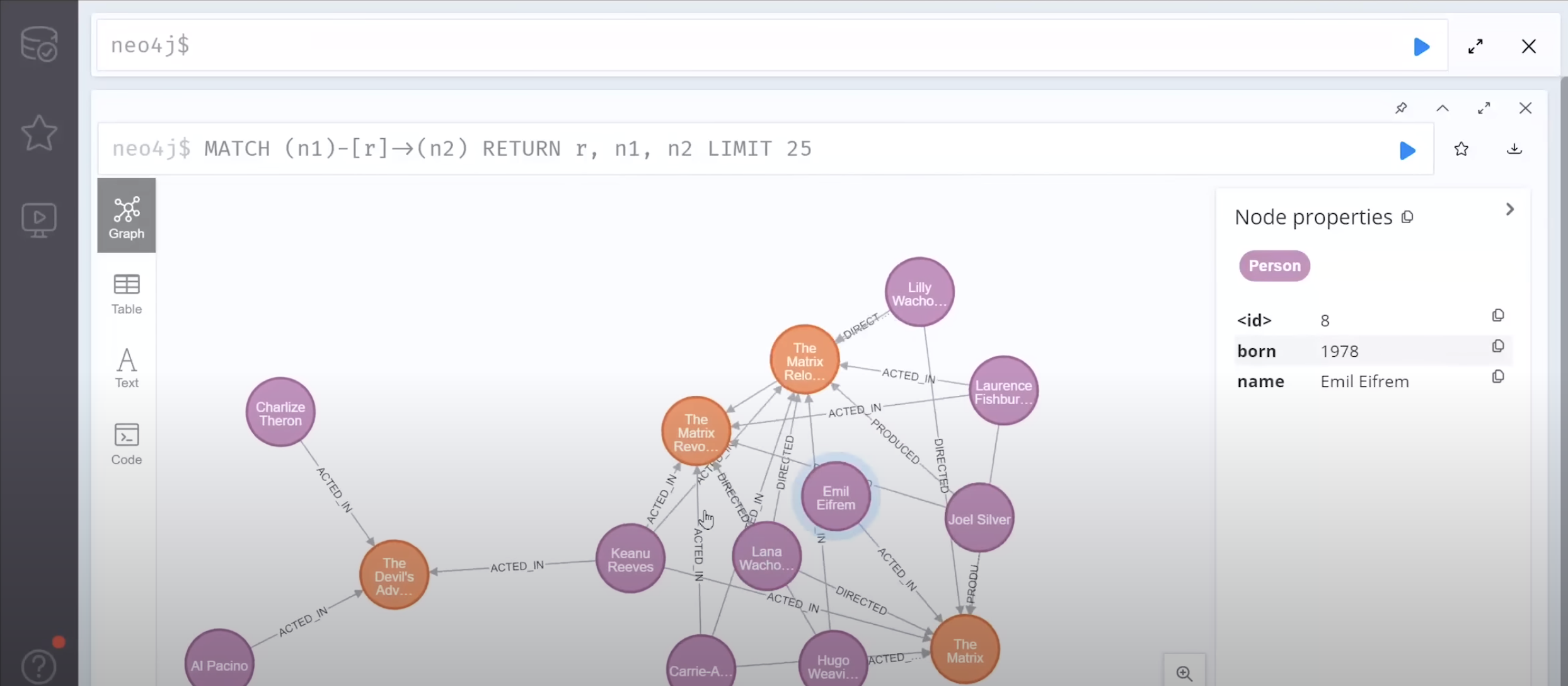
코로나 전염 맵, SNS 친구 관계, 비행기 노선, 추천 서비스 등의 데이터들을 저장, 관리하기에 적합하다.
페이스북은 Tao DB 라는 자체 Graph DB가 있다.
column-family DB
Cassandra, Apache Hbabe, Google Could Bigtable가 대표적.

Cassandra의 경우 key-value DB로 구분하는 사람도 있는 듯 하다. 읽고 쓰기가 매우 빠르다. 애플, 넷플릭스 등이 사용.
많은 양의 데이터를 재빨리 읽어야 하는 경우 적합하다.
정규화 없이 쓰는 게 일반적, 데이터 입출력이 상대적으로 간단하다.

DB를 분산해놓는다.
입출력이 잦으면 사용한다.
시간 기록.
search engine
구글.
index 보관에 특화. ---> 데이터 검색을 위한 목차 형태의 정보 보관.
실시간 검색어, 추천 검색어, 입력 오타 교정 등에 쓰인다.
용어 한 번 더 짚고 가면,
DBMS
: DataBase Management System. 말 그대로 해석하면 DB를 관리하는 시스템.
RDBMS
: Relational DataBase Management System. 관계형 DB 관리 시스템.
그
래
서
.
.
.
SQL DB vs NoSQL DB ?
SQL DB은 정보의 구조가 행과 열로써 존재해 매우 정확, 정돈된 엄격한 형태. 유연하지 않다.
SQL DB이라는 건 MySQL, PostgreSQL, SQLite 등이 해당되고 그 외 광범위하게 NoSQL.
NoSQL DB의 대표 주자인 MongoDB는 json형태로 자료를 저장하여 원하는 무슨 형태든 저장이 가능하고, 데이터가 모두 같은 모양일 필요도 없다.

첨부된 도식 그림이 이해에 도움이 된다.
