트리의 부모 찾기 - 11725번
문제
루트 없는 트리가 주어진다. 이때, 트리의 루트를 1이라고 정했을 때, 각 노드의 부모를 구하는 프로그램을 작성하시오.
입력
첫째 줄에 노드의 개수 N (2 ≤ N ≤ 100,000)이 주어진다. 둘째 줄부터 N-1개의 줄에 트리 상에서 연결된 두 정점이 주어진다.
출력
첫째 줄부터 N-1개의 줄에 각 노드의 부모 노드 번호를 2번 노드부터 순서대로 출력한다.
풀이
dfs와 bfs 메소드 둘 다 가능하다. 문제에서 트리의 루트를 1이라고 정하기 때문이다.
DFS 방식
트리의 루트를 1이라고 정했기 때문에 1부터 깊이 우선 탐색(DFS)을 시작하고, 1과 연결되어 있는 Node들 중에 아직 방문하지 않은 노드를 방문한다. 이때 변수 graph와 변수 parent의 각 원소의 인덱스는 곧 트리 안의 노드 번호이고 각 원소의 값은 그 노드 번호에 인접해있는 원소들의 목록이다.
변수 graph에는 원소들이 인접해있는 정보들을 담는다. 가령 예제 입력 2를 입력 후 실행하였을 때 graph는 이렇게 된다. 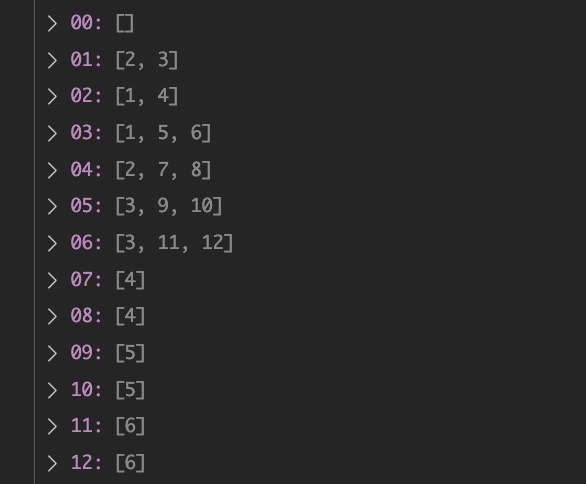
다음의 코드는 정답이다.
import sys
sys.setrecursionlimit(10**6)
input = sys.stdin.readline
N = int(input())
graph = [[] for _ in range(N+1)]
for _ in range(N-1):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
parent = [int(0) for _ in range(N+1)]
def dfs(curr):
for curr_adjacent in graph[curr]:
if parent[curr_adjacent]==int(0):
parent[curr_adjacent] = curr
dfs(curr_adjacent)
dfs(1)
for x in range(2, N+1): print(parent[x])변수 parent에 탐색을 시작한 노드(즉, 해당 원소의 부모 노드)를 저장한다. 그리고나서 그 부모 원소를 재귀적으로 호출하여 새로이 탐색하기 시작한다.
parent에 아직 방문하지 않은, 그러니까 값이 0인 원소가 더이상 남아있지 않을 시점에서 함수 dfs는 종료된다.
끝에서 각 노드의 부모 노드 번호를 2번 노드부터만 프린트하는 것이므로 for x in range(2, N+1): print(parent[x]) 가 된다. 이를 다르게 표현해본다면 for x in parent[2:]: print(x) 와 같다.
BFS 방식
BFS를 이용한 방식도 DFS와 유사한 것을 알 수 있다. 우린 1부터 너비 우선 탐색(BFS)을 시작하기 때문에 먼저 1을 큐 변수 q에 넣고 while문을 돌린다.
다음의 코드는 정답이다.
import sys
from collections import deque
input = sys.stdin.readline
N = int(input())
graph = [[] for _ in range(N+1)]
for _ in range(N-1):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
parent = [int(0) for _ in range(N+1)]
q = deque([1])
def bfs():
while q:
curr = q.popleft()
for curr_adjacent in graph[curr]:
if parent[curr_adjacent]==0:
parent[curr_adjacent] = curr
q.append(curr_adjacent)
bfs()
for x in parent[2:]: print(x)현재 탐색하고 있는 노드를 변수 curr에 할당한다. graph[curr]는 노드 curr에 인접해있는 노드에 대한 리스트일 것이다.
이 리스트의 원소들을 for문 돌리기 위해 각 curr_adjacent이라는 변수로 부르자. 우리가 아직 curr_adjacent에 대한 탐색 이전이라면, 다시 말해 parent[curr_adjacent]가 0 이라면 parent[curr_adjacent] = curr 로 할당해준다.
그런 뒤 우린 q에 curr_adjacent를 넣어 다음 탐색 대상으로서 원소 curr_adjacent을 설정해준다. 그렇게 whlie문 한 회차가 끝난다. 그런 식으로 다음 탐색 대상이 더 없을 때까지 while문을 계속 돌게 된다.
끝에서 각 노드의 부모 노드 번호를 2번 노드부터만 프린트하는 것이므로 for x in range(2, N+1): print(parent[x]) 가 된다. 이를 다르게 표현해본다면 for x in parent[2:]: print(x) 와 같다.
변수의 이름이 코드의 진행에 영향을 주는 것은 아니지만 난 개인적으로 변수 parent의 이름이 의미상 parent가 아니라 adjacent여야 하는 것 아닌지에 대한 의구가 생겼었다. 변수 parent가 인덱스:노드번호 에 값:노드에대한인접노드번호 의 의미를 가지는 점에서 말이다...
그런데 생각해보니 graph와 달리 parent는 무조건 모든 원소가 한 원소(graph의 인덱스) 당 하나의 값만 가지게 된다(graph와 parent의 맨 처음 인덱스 0째 원소는 안 사용하는 원소니까 빼고 말했다.). 고로 결과적으로 봤을 때 이는 해당 원소의 부모 원소에 대한 정보가 되는 것이다.
