Abstract
전체 슬라이드 이미지(WSI) 분류의 어려운 문제를 해결합니다. WSI는 해상도가 매우 높으며 일반적으로 지역화된 주석이 부족합니다. WSI 분류는 슬라이드 수준 레이블만 사용할 수 있는 경우 MIL(다중 인스턴스 학습) 문제로 간주될 수 있습니다. 우리는 지역화된 주석을 필요로 하지 않는
WSI 분류 및 종양 검출을 위한 MIL 기반 방법을 제안합니다. 우리의 방법에는 세 가지 주요 구성 요소가 있습니다.
먼저, 훈련 가능한 거리 측정 기능이 있는 이중 스트림 아키텍처에서 인스턴스의 관계를 모델링하는 새로운 MIL 집계기를 소개합니다.
둘째, WSI는 MIL 모델의 학습을 방해하는 크거나 불균형한 백을 생성할 수 있으므로 자기 감독 대조 학습을 사용하여 MIL에 대한 좋은 표현을 추출하고 큰 백에 대한 메모리 비용 문제를 완화할 것을 제안합니다.
세번째로, 우리는 멀티스케일 WSI 기능을 위해 피라미드형 융합 메커니즘을 채택하고 분류 및 지역화의 정확도를 더욱 향상시킵니다.
우리 모델은 두 가지 대표적인 WSI 데이터 세트에서 평가됩니다. 우리 모델의 분류 정확도는 데이터 세트 전체에서 2% 미만의 정확도 차이로 완전히 감독된 방법에 비해 유리합니다. 우리의 결과는 또한 이전의 모든 MIL 기반 방법을 능가합니다. 표준 MIL 데이터 세트에 대한 추가 벤치마크 결과는 일반 MIL 문제에 대한 MIL 집계기의 우수한 성능을 추가로 보여줍니다.
GitHub 저장소:https://github.com/binli123/dsmil-wsi
1. Introduvtion
전체 슬라이드 스캐닝은 질병 진단, 의학 교육 및 병리학 연구에서 세포 조직 섹션을 시각화하는 강력하고 널리 사용되는 도구입니다.[10, 38]
스캐닝은 평가, 공유 및 분석을 위해 유리 슬라이드의 조직을 디지털 전체 슬라이드 이미지(WSI)로 변환합니다. WSI의 자동화된 질병 탐지는 컴퓨터 지원 진단 시스템의 오랜 과제였습니다. 우리는 딥 러닝의 발전에 힘입어 컴퓨터 비전 및 의료 이미지 분석 커뮤니티[6, 44, 3, 24, 27, 29]에서 최근 몇 가지 성공을 보기 시작했습니다.
WSI는 해상도가 매우 높습니다. 일반적인 병리학 이미지의 크기는 40,000 × 40,000입니다. 따라서 WSI 분류에 가장 널리 사용되는 패러다임은 패치 기반 처리입니다. WSI는 수천 개의 작은 패치로 분할되어 추가로 검사됩니다. 예를 들어 CNN(Convolutional Neural Network) [21, 53, 35, 11, 33]과 같은 분류기에 의해.약하게 감독된 WSI 분류에 대한 이전 접근 방식[21, 53, 35, 11, 18, 8]의 대부분은 다중 인스턴스 학습(MIL) 문제 공식[14, 34]을 따릅니다. 여기서 각 WSI는 많은 것을 포함하는 백으로 간주됩니다. 패치 인스턴스. WSI(bag)는 해당 패치(인스턴스) 중 하나라도 질병 양성(예: 병변 포함)인 경우 질병 양성으로 표시됩니다. 패치 수준 기능 또는 점수는 슬라이드 수준 레이블을 예측하는 분류기에 의해 추출, 집계 및 검사됩니다. 최근의 MIL 기반 접근 방식은 특징 추출 및 특징 집계를 위해 심층 신경망을 사용하여 큰 이점을 얻었습니다[22, 50, 37].
클리닉에서 질병 양성 조직 절편은 전체 조직의 작은 부분(예: 20% 미만)만 차지하여 많은 수의 질병 음성 패치로 이어질 수 있습니다. 불행하게도 기가픽셀 해상도를 사용하면 전문 병리학자가 패치 수준 라벨을 지정하는 데 시간이 많이 걸리고 확장이 어렵습니다. 이 문제를 해결하기 위해 여러 최근 연구[21, 3, 18]에서 패치 기반 분류기를 교육하는 데 슬라이드 수준 레이블만 사용되는 약한 감독 WSI 분류의 가능성을 보여주었습니다.
약하게 감독된 WSI 분류에 대한 이전 접근 방식의 대부분은 MIL(다중 인스턴스 학습) 문제 공식을 따르며, 여기서 각 WSI는 패치의 많은 인스턴스를 포함하는 백으로 간주됩니다.
WSI(bag)는 해당 패치(인스턴스) 중 하나라도 질병 양성(예: 병변 포함)인 경우 질병 양성으로 표시됩니다. 패치 level feature 또는 점수는 슬라이드 수준 레이블을 예측하는 분류기에 의해 추출, 집계 및 검사됩니다. 최근의 MIL 기반 접근 방식은 특징 추출 및 특징 집계를 위해 심층 신경망을 사용하여 큰 이점을 얻었습니다[22, 50, 37].
약하게 감독되는 WSI 분류를 위한 심층 MIL 모델을 개발하는 데 두 가지 주요 과제가 있습니다.
첫째, 포지티브 이미지(백)의 패치(인스턴스)가 매우 불균형한 경우(즉, 패치의 작은 부분만 양성이고) 모델은 널리 채택된 최대 풀링과 같은 간단한 집계 작업을 사용할 때 이러한 포지티브 인스턴스를 잘못 분류할 가능성이 있습니다.[22] 이는 MIL의 가정 하에서 최대 풀링이 완전 감독 교육과 비교하여 결정 경계의 이동으로 이어질 수 있기 때문입니다(그림 1). 게다가 모델은 과적합으로 쉽게 어려움을 겪을 수 있고 약한 감독 신호로 인해 풍부한 기능 표현을 학습할 수 없습니다.[12, 32, 1]
둘째, 현재 모델은 CNN에서 추출한 고정 패치 기능을 사용하거나 소수의 고득점 패치를 사용하여 기능 추출기만 업데이트합니다.[12, 3, 32] 기능 추출기 및 집계기의 종단간 교육은 대형 백에 대해 엄청나게 비용이 많이 들기 때문입니다. 이러한 단순화된 학습 체계는 WSI 분류를 위한 차선 패치 기능으로 이어질 수 있습니다.
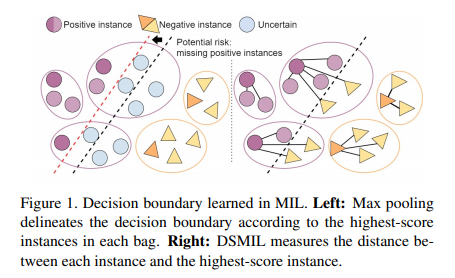
그림1
이러한 문제를 해결하기 위해 DSMIL(dual-stream multiple instance learning network)이라고 하는 새로운 심층 MIL 모델을 제안합니다. 구체적으로 DSMIL은 두 개의 스트림 아키텍처를 사용하여 패치(인스턴스)와 이미지(백) 분류기를 공동으로 학습합니다.
첫 번째 스트림은 표준 최대(max) 풀링을 배포하여 가장 높은 점수를 받은 인스턴스(중요 인스턴스라고 함)를 식별하고 두 번째 스트림은 중요 인스턴스까지의 거리를 측정하여 각 인스턴스에 대한 attention 점수를 계산합니다. DSMIL은 그림 1과 같이 포지티브 백의 인스턴스를 더 잘 설명하는 결정 경계로 이어지는 주의 점수를 사용하여 인스턴스의 soft 선택을 추가로 적용합니다.
중요한 점은 DSMIL이 WSI용 feature 추출기를 훈련하기 위해 자체 지도 대조 학습을 사용하여 강력한 패치 표현을 생성한다는 것입니다. 또한 DSMIL은 밀리미터 규모(예: 혈관 및 땀샘)에서 세포 규모(조직 미세 환경)에 이르는 조직 features을 활용할 수 있는 멀티스케일 feature 융합 메커니즘을 통합합니다.
우리는 Camelyon16 및 TCGA 폐암을 포함한 두 개의 공개 WSI 데이터 세트에서 약하게 감독된 WSI 분류에 대해 DSMIL을 평가합니다. 결과는 DSMIL이 분류 정확도에서 다른 최신 MIL 모델보다 최소 2.3% 더 우수함을 보여줍니다. 더 중요한 것은, 우리의 분류 정확도는 2% 미만의 정확도 차이로 완전히 감독된 방법에 비해 유리하다는 것입니다. 또한 DSMIL은 현지화 정확도가 뛰어나 이전 MIL 모델보다 훨씬 뛰어납니다. 마지막으로 약하게 감독된 WSI 분류를 넘어 일반적인 MIL 문제에 대한 DSMIL의 최신 성능을 시연합니다.
2. Related Work
우리 작업은 심층 모델을 사용하여 WSI 분석을 위한 MIL을 개발합니다. MIL 자체는 잘 정립된 주제입니다. 설문 조사를 위해 독자들에게 [4]를 참조하십시오. 이 섹션에서는 심층 MIL 모델에 대한 최근 노력과 WSI 분석을 위한 MIL 모델 관련 작업을 간략하게 검토합니다.
Deep MIL Models
일반적으로 MIL 모델은 평균 풀링 및 최대 풀링과 같은 수작업 집계를 고려합니다[16, 39].
최근에는 신경망으로 집계 연산자를 매개변수화하는 것이 여전히 유익할 수 있음이 밝혀졌습니다[16, 52, 37].
[22]는 가방 임베딩에 대한 각 인스턴스의 기여도를 포함하는 신경망에 의해 매개변수화된 attention 기반 집계 연산자를 제안했습니다.
그래프 신경망 기반 접근법과 캡슐 네트워크 기반 접근법과 같은 인스턴스 간의 종속성을 모델링하기 위해 상황 정보를 고려한 방법이 제안된다[47, 55, 8].
instance-to-instance 및 instance-to-bag 관계를 모델링하기 위해 로컬이 아닌 작업을 배포합니다[51]. ABMIL(attention-based MIL)[22]의 어텐션 메커니즘과 달리, 우리 모델의 어텐션은 훈련 가능한 거리 측정을 기반으로 명시적으로 계산됩니다. 우리의 방법은 또한 노드 사이의 가중치가 학습된 매개변수가 아니라 두 노드의 함수라는 점에서 그래프 모델 및 캡슐 네트워크와 다릅니다[43, 42]. 측정 메커니즘은 self-attention[48, 51]과 유사하지만 하나의 노드(임계 인스턴스)와 다른 노드 사이에서만 측정이 수행된다는 점에서 다릅니다. 이중 스트림 비로컬 작업은 임베딩이 아닌 별도의 브랜치에서 학습된 신뢰도 점수에 따라 임베딩이 필터링된다는 점에서 비대칭 비로컬 작업과도 다릅니다[56]. 또한, 약하게 감독된 객체 위치 파악[9] 및 감지[45, 49]를 포함하여 약하게 감독된 다른 비전 작업을 위해 심층 MIL 모델이 고려되었습니다. 이 논문에서는 WSI의 약하게 감독된 분류에 초점을 맞춥니다.
MIL Models for WSI Analysis
MIL은 세포 분할 및 종양 검출과 같은 작업을 위한 WSI 분석에 성공적으로 적용되었습니다[54, 21, 40, 23, 3, 8]. Campanellaet al의[3]은 약하게 레이블이 지정된 큰 WSI 데이터 세트에서 훈련된 MIL 분류기가 픽셀 수준 주석이 있는 소규모 랩 데이터 세트에서 훈련된 완전 지도 분류기보다 더 잘 일반화됨을 보여줍니다. 전자는 일상적인 클리닉에서 대규모로 쉽게 얻을 수 있는 반면 후자는 연구실에서 노동 집약적인 주석이 필요합니다.
MIL에서 좋은 feature 표현을 위해 CNN을 훈련하는 것은 금지된 메모리 요구 사항과 잡음이 많은 감독 신호[32, 12]로 인해 WSI 분석에서 사소한 일이 아닙니다. 최근에 준지도 학습은 제한된 패치 레벨 레이블로 WSI 분류를 위한 분류기 훈련을 가능하게 하는 데 사용되었습니다[26]. 대조적으로, 우리의 작업은 MIL에서 특징 추출을 위해 자기 감독 대조 학습[7]을 사용합니다. 자기 감독 대조 학습은 시각적 표현 [36, 7, 19] 학습에서 성공을 입증했지만 WSI 분석에서는 아직 탐구되지 않았습니다.
병리학자에 의한 WSI의 평가는 다중 척도(multiscale)[2, 17, 46]로 수행되며 WSI 분석에서 다중 척도 특징을 고려하는 것이 일반적입니다. MIL에서 WSI의 다양한 배율의 특징을 단순히 포함하는 백을 사용하는 것이 유익한 것으로 나타났습니다[18]. 또 다른 가능성[33]은 저배율에서 영역을 선택하고 고배율 패치를 위해 이러한 영역을 추가로 확대하는 것입니다. 우리의 멀티스케일 피처 분석 전략은 딥 모델[41, 28]을 사용하는 멀티스케일 피쳐 표현에 대한 이전 작업에서 영감을 얻었지만 동시에 패치 주의를 로컬로 제한하는 기능에 대해 DSMIL 모델에 이점이 있습니다.
3. Method
우리는 이제 약하게 감독된 WSI 분류를 위한 우리의 방법을 제시합니다. 이 섹션에서는 MIL 공식을 소개하고 모델인 DSMIL을 제시합니다.
3.1. Background: MIL Formulation
MIL에서 훈련 샘플 그룹은 여러 인스턴스를 포함하는 백으로 간주됩니다. 각 백에는 백에 하나 이상의 긍정적인 인스턴스가 포함된 경우 양성인 백 레이블이 있고 이러한 긍정적인 인스턴스가 포함되지 않은 경우 부정적인 레이블이 있습니다. 인스턴스 수준 레이블을 알 수 없습니다.
이진 분류의 경우, B = {(x1, y1), ...,(xn, yn)}을 가방이라고 합니다. 여기서 xi ∈ χ는 레이블 yi ∈ {0, 1}인 인스턴스입니다,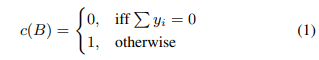 B의 라벨은 c(B)로 지정된다.
B의 라벨은 c(B)로 지정된다.
MIL은 c(B) = g(f(x0), ..., f(xn))에 의해 주어진 B의 레이블을 예측하기 위해 적합한 변환 f 및 순열 불변 변환 g[22, 5]를 더 사용합니다.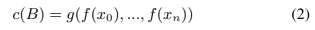
다중 인스턴스 학습은 f와 g의 선택에 따라 두 가지 방식으로 모델링될 수 있습니다.
1) 인스턴스 기반 접근법.
f는 각 인스턴스에 점수를 매기는 인스턴스 분류자이고, g는 인스턴스 점수를 집계하여 백 점수를 생성하는 풀링 연산자입니다.
2) 임베딩 기반 접근법.
f는 각 인스턴스를 임베딩에 매핑하는 인스턴스 수준 feature 추출기이고, g는 인스턴스 임베딩에서 백 임베딩을 생성하고 백 임베딩을 기반으로 백 점수를 출력하는 집계 연산자입니다. 임베딩 기반 방법은 가방 라벨이 직접 감독하는 가방 임베딩을 기반으로 가방 점수를 생성하며 일반적으로 인스턴스 기반 방법에 비해 정확도가 높지만[53] 일반적으로 분류기를 트리거하는 주요 인스턴스를 결정하기가 더 어렵습니다[30].
약하게 감독된 WSI 분류 설정에서 각 WSI는 백으로 간주되고 여기에서 추출된 패치는 이 백의 인스턴스로 간주됩니다. 그런 다음 인스턴스 수준 분류기와 임베딩 애그리게이터(aggregator)를 공동으로 학습하는 모델을 설명하고 이러한 하이브리드 아키텍처가 인스턴스 기반 및 임베딩 기반 방법 모두의 이점을 제공할 수 있는 방법을 설명합니다.
3.2. DSMIL for WSI Classification
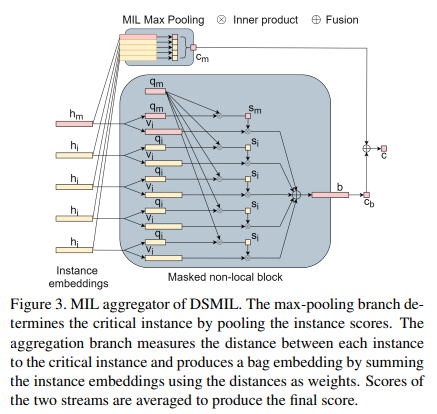
우리의 주요 혁신은 새로운 집계 함수 g의 설계와 기능 추출기 f의 학습입니다. 구체적으로 우리는 self-supervised contrastive learning에 의해 학습된 입력 인스턴스 임베딩과 함께 마스킹된 비로컬 블록과 기능 집계를 위한 최대(max) 풀링 블록으로 구성된 DSMIL을 제안합니다. 또한 DSMIL은 피라미드형 전략을 사용하여 멀티스케일 임베딩을 결합하므로 WSI의 패치에 대한 관심의 로컬 제약 조건을 보장합니다. 그림 2는 DSMIL의 개요를 보여줍니다. 이제 DSMIL의 각 구성 요소에 대해 설명합니다.
MIL Aggregator with Masked Non-Local Operation.
인스턴스 분류자 또는 백 분류자를 학습하는 대부분의 이전 방법과 달리 DSMIL은 인스턴스 분류자와 백 분류자 및 이중 스트림 아키텍처에 포함된 백을 공동으로 학습합니다.
B = {x1, ..., xn}은 WSI의 패치 백을 나타냅니다. 특징 추출기 f가 주어지면 각 인스턴스 xi는 임베딩 h_i = f(xi) ∈ R^(Lx1)로 투영될 수 있습니다. 첫 번째 스트림은 각 인스턴스 임베딩에 인스턴스 분류자를 사용하고 점수에 대한 최대 풀링이 이어집니다.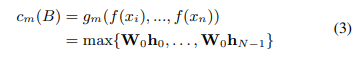 : 여기서 W0는 가중치 벡터입니다. 최대 풀링 스트림은 점수가 가장 높은 인스턴스(중요 인스턴스)를 결정합니다. 최대 풀링은 순열 불변 연산이므로 이 스트림은 방정식 2를 만족합니다.
: 여기서 W0는 가중치 벡터입니다. 최대 풀링 스트림은 점수가 가장 높은 인스턴스(중요 인스턴스)를 결정합니다. 최대 풀링은 순열 불변 연산이므로 이 스트림은 방정식 2를 만족합니다.
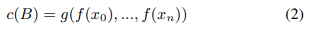
두 번째 스트림은 위의 인스턴스 임베딩을 백 임베딩으로 집계하여 백 분류기에 의해 추가로 점수가 매겨집니다. 임계 인스턴스의 임베딩 h_m을 획득하고, h_i(h_m 포함)를 임베딩하는 각 인스턴스를 쿼리 q_i ∈ R^L×1 및 정보 v_i ∈ R^L×1의 두 벡터로 변환합니다.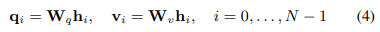
여기서 W_q 및 W_v는 각각 가중치 행렬입니다. 그런 다음 임의의 인스턴스에서 임계 인스턴스까지의 거리 측정 U를 다음과 같이 정의합니다 : 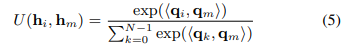
"<·,·>"는 두 벡터의 내적을 나타낸다. 백 임베딩 b는 임계 인스턴스까지의 거리를 가중치로 사용하여 모든 인스턴스의 정보 벡터 v_i의 가중 요소별 합계입니다. 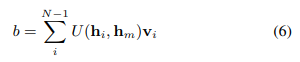
백 스코어 c_b는 다음과 같이 주어진다: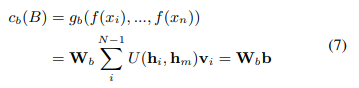
여기서 W_b는 이진 분류를 위한 가중치 벡터입니다. 이 동작은 self-attention[48]과 유사합니다. 그러나 쿼리 키 매칭은 임계 노드와 다른 노드(주요 노드 자체 포함) 간에만 수행된다는 점에서 다릅니다. 또한 각 쿼리를 self-attention과 같은 추가 키 벡터와 일치시키는 대신 쿼리를 다른 쿼리와 일치시키고 키 벡터를 학습하지 않습니다.
내적은 두 쿼리 간의 유사성을 측정하여 더 유사한 인스턴스에 대해 더 큰 값을 생성합니다. 따라서 중요한 인스턴스와 더 유사한 인스턴스는 더 큰 주의 가중치를 갖습니다. 정보 벡터 v_i에 대한 추가 계층을 사용하면 각 인스턴스 내에서 기여 정보를 추출할 수 있습니다. 방정식 5의 softmax 연산은 백 크기에 관계없이 어텐션 가중치가 1로 합산되도록 합니다.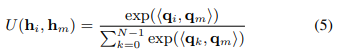
중요한 인스턴스는 인스턴스의 순서에 의존하지 않고 측정 U는 대칭이므로 b를 포함하는 백이 인스턴스의 순서에 의존하지 않도록 이 합계 항은 두 번째 스트림이 순열 불변이며 다음을 충족합니다. 방정식 2. 최종 백 점수는 두 스트림 점수의 평균입니다.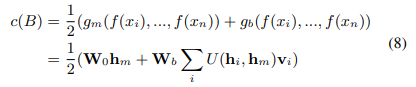
DSMIL은 인스턴스 점수를 최대 풀링하고 각 클래스에 대한 주의 가중치를 개별적으로 계산하여 다중 클래스 MIL 문제의 경우를 처리할 수 있습니다. 결과 백 임베딩은 행렬 b ∈ R^L×C이며 여기서 C는 클래스 수이며 각 항목은 인스턴스 정보 벡터 v_i의 가중 합입니다. 그러면 마지막 완전 연결 계층의 출력 채널 수는 C입니다.
정보 벡터 vi는 인스턴스 내 feature 선택을 허용하는 반면 거리 측정은 임계 인스턴스와의 유사성에 따라 인스턴스 간 선택을 적용합니다. 결과로 생성된 백 임베딩은 백 크기에 관계없이 일정한 모양을 가지며 추론 시 출력 백 점수 c_b를 계산하는 데 사용됩니다. 수집기의 아키텍처는 그림 3에 설명되어 있습니다.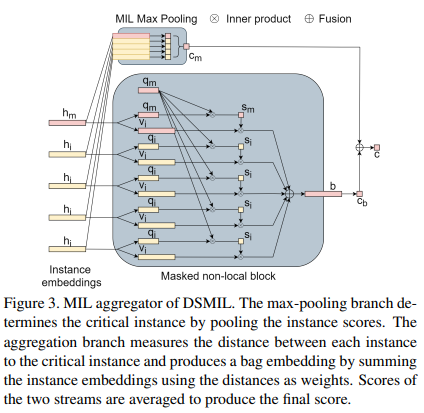
Self-Supervised Contrastive Learning of WSI Features
집계(aggregation) 작업을 넘어 기능 추출기 f를 학습하기 위해 자기 감독 대조 학습을 사용할 것을 제안합니다. 특히, 수동 레이블 없이 강력한 표현을 학습할 수 있는 최첨단 자가 감독 학습 프레임워크인 [7]의 SimCLR을 고려합니다. SimCLR은 CNN이 하위 이미지 배치에서 동일한 이미지의 하위 이미지를 연결하도록 훈련시키는 대조 학습 전략을 배포합니다. 하위 이미지는 이미지 배치에서 무작위로 선택되어 두 개의 무작위 이미지 확대 분기에 공급됩니다. 이 모델은 대조 손실을 사용하여 동일한 이미지의 하위 이미지 간의 일치를 최대화하도록 훈련됩니다. 교육이 수렴된 후 기능 추출기가 유지되고 다운스트림 작업에 대한 교육 샘플의 표현을 계산하는 데 사용됩니다. SimCLR에 사용되는 데이터 세트는 WSI에서 추출한 패치로 구성됩니다. 패치는 겹치지 않고 조밀하게 잘리고 SimCLR 교육을 위한 개별 이미지로 처리됩니다.
Locally-Constrained Multiscale Attention.
마지막으로 피라미드 연결 전략을 사용하여 다양한 배율의 WSI 기능을 통합합니다. 먼저, 각 저배율 패치에 대해 이 패치의 특징 벡터와 이 패치 내에서 더 높은 배율의 하위 이미지의 특징 벡터를 얻습니다. 예를 들어, 10배 배율에서 224×224 크기의 패치는 20배 배율에서 224×224 크기의 하위 이미지 4개를 포함합니다. 10× 패치마다 10× 특징 벡터를 각각의 20× 특징과 연결하고 4개의 특징 벡터를 얻습니다. 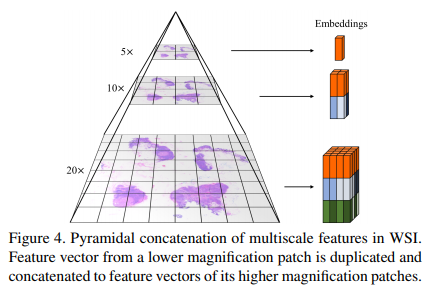
그림 4는 3배율(20×-10×-5×)의 경우를 보여줍니다. 우리는 실험에서 두 가지 배율(20배 및 5배)의 특징을 사용하여 이 방법의 효율성을 입증하지만 아이디어는 일반적이며 더 많은 배율로 확장될 수 있습니다.
이 연결 방법에는 두 가지 주요 이점이 있습니다. 1) 결과 특징 벡터의 첫 번째 부분은 동일한 5× 패치에 속하는 20× 패치에 대해 동일합니다. 결과적으로 DSMIL에서 이러한 벡터에 대한 거리 측정 결과 s_i = <q_i, q_m>는 유사한 경향이 있으며 인스턴스에 유사한 attention 가중치가 할당됩니다. feature 벡터의 두 번째 부분은 각 20x 패치에 고유하여 주의 가중치가 이러한 패치 간에 다를 수 있습니다. 2) 서로 다른 척도의 정보가 feature 벡터에 보존되어 네트워크가 서로 다른 척도에서 적절한 정보 v_i를 선택할 수 있습니다.
4. Experiments and Results
이제 우리는 실험과 결과를 제시합니다. 먼저 불균형/균형 가방 및 단일/다중 클래스 MIL 문제를 다루는 두 가지 임상 WSI 데이터 세트인 Camelyon16 및 TCGA 폐암에 대한 결과를 보고합니다. 또한, 우리는 MIL 애그리게이터(aggregator), 대조 기능 학습 및 멀티스케일 주의 메커니즘의 효율성을 보여주는 제거 연구를 제시합니다.
Experiment Setup and Evaluation Metrics.
우리는 두 데이터 세트에서 WSI 분류 작업에 대한 DSMIL의 정확도 및 곡선 아래 영역(AUC) 점수를 보고합니다. Camelyon16에서는 자유 반응 작동 특성 곡선(FROC)[15]을 보고하여 현지화 성능도 평가합니다. WSI 데이터 세트를 사전 처리하기 위해 모든 WSI는 20× 및 5× 배율에서 백을 형성하기 위해 겹치지 않고 224×224 패치로 잘립니다. 배경 패치(엔트로피 < 5)는 폐기됩니다. 두 데이터 세트 모두에 대해 20x 이미지에서 지속적으로 더 나은 결과를 얻었으며 단일 스케일의 WSI를 사용한 실험에 대해 보고되었습니다.
Implementation Details.
훈련 중 모델 가중치를 업데이트하기 위해 학습률이 0.0001인 Adam [25] 옵티마이저를 사용합니다. MIL 모델 훈련을 위한 미니 배치 크기는 1(가방)입니다. WSI 데이터 세트의 교육 세트에서 추출한 패치는 SimCLR을 사용하여 feature 추출기를 교육하는 데 사용됩니다. SimCLR의 경우 초기 학습률이 0.0001인 Adam 옵티마이저, 학습률 스케줄링을 위한 코사인 annealing-어닐링(warm 재시작 없음) 방식[31], 최소 배치 크기 512를 사용합니다. MIL 모델 및 SimCLR에 사용되는 CNN 백본 ResNet18입니다[20].
4.1. Results on Camelyon16
먼저 Camelyon16에서 결과를 발표합니다. 데이터 세트와 기준선을 소개하고 분류 및 지역화에 대한 결과를 논의합니다.
Dataset
Camelyon16은 유방암의 전이 탐지를 위해 제안된 공개 데이터 세트입니다[15]. 이 데이터 세트는 271개의 훈련 이미지와 129개의 테스트 이미지로 구성되어 있으며, 20배 배율에서 약 320만 개의 패치와 5배 배율에서 약 25만 개의 패치를 생성하며 백당 평균 약 8,000개 및 625개의 패치를 생성합니다. 종양 영역은 각 슬라이드의 픽셀 수준 주석으로 완전히 레이블이 지정됩니다. 훈련에서 픽셀 수준 주석을 무시하고 슬라이드 수준 레이블만 고려합니다(즉, 주석이 달린 종양 영역이 포함된 슬라이드는 양성으로 간주됨). 생성된 백에는 양성 백에 대한 종양 및 건강한 패치와 음성 백에 대한 모든 건강한 패치의 혼합물이 포함됩니다.
이 데이터 세트의 포지티브 백은 매우 불균형합니다. 양성 슬라이드의 일부 영역에만 종양(슬라이드당 총 조직 면적의 약 < 10%)이 포함되어 있어 양성 백에서 음성 패치의 많은 부분을 초래합니다. 이로 인해 대부분의 MIL 모델에서 좋은 표현을 직접 학습하기가 어렵습니다[32, 12]. 우리는 슬라이드 레벨 레이블에만 의존하는 우리의 방법이 이러한 어려움을 극복하고 픽셀 레벨 레이블을 사용하는 완전히 감독된 방법에 필적하는 성능을 달성할 수 있음을 보여줍니다.
Baselines.
우리는 WSI 분류 및 종양 국소화 작업에 대해 (1) 최대 풀링 및 평균 풀링과 같은 기존 MIL 풀링 연산자를 사용하는 심층 모델 및 (2) 최근 심층 MIL 모델을 포함하여 강력한 기준 세트와 DSMIL을 평가하고 비교합니다. [18, 3, 22]
또한 픽셀 수준의 주석을 사용하여 상한 완전 감독 모델을 얻습니다. 여기서 패치가 종양 영역 내에 있으면 양성으로 표시되고 WSI 점수는 모든 테스트 중인 패치 점수를 평균하여 얻습니다.
분류 작업에 대한 결과는 우수한 백 임베딩 생성 측면에서 우리 모델의 효능을 입증할 수 있는 반면, 지역화 작업에 대한 결과는 양성 백에서 양성 인스턴스를 묘사하는 DSMIL의 기능을 입증할 수 있습니다.
Classification Results.
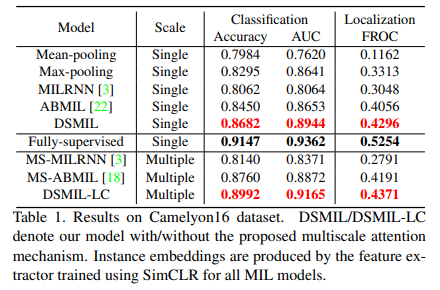
분류 결과는 표 1에 요약되어 있습니다. 기능은 동일한 설정에서 20x 패치에 대한 자기 감독 대조 학습을 사용하여 학습됩니다. 자기 감독 대조 학습 사용의 기여는 절제 연구에서 제시될 것입니다.
결과는 둘 다 전통적인 풀링 연산자보다 우수하지만 학습된 관심에 대한 추가 정규화를 구현하지 않는 ABMIL보다 단일 척도 설정에서 분류가 약 2.6% 향상되어 더 나은 집계를 달성함을 시사합니다. 순열-불변 특성을 고려하지 않은 순환 신경망 기반 모델은 기존 풀링 연산자보다 성능이 우수하지 않습니다. 통합된 멀티스케일 어텐션 메커니즘을 통해 DSMIL은 2% 미만의 분류 정확도 차이로 완전 감독 방식의 성능과 일치하는 향상된 결과를 달성합니다.
Localization Results.
Camelyon16에서 픽셀 수준의 주석을 사용할 수 있으므로 방법의 현지화 기능을 테스트할 수 있습니다. 현지화 성능은 MIL 모델이 긍정적인 인스턴스를 묘사하는 기능을 나타냅니다. 보고된 FROC 점수는 WSI당 1/4, 1/2, 1, 2, 4 및 8 FPs per의 미리 정의된 6가지 거짓 양성 비율에서의 평균 감도로 정의됩니다. 결과는 훈련 가능한 거리 측정을 사용하여 주의 점수가 명시적으로 계산되는 DSMIL이 탐지 위치 파악에서 ABMIL에 비해 상대적으로 최소 6% 개선된 양성 패치를 더 잘 묘사함을 보여줍니다. 테스트 세트의 대표 샘플 감지 맵은 그림 5에 나와 있습니다.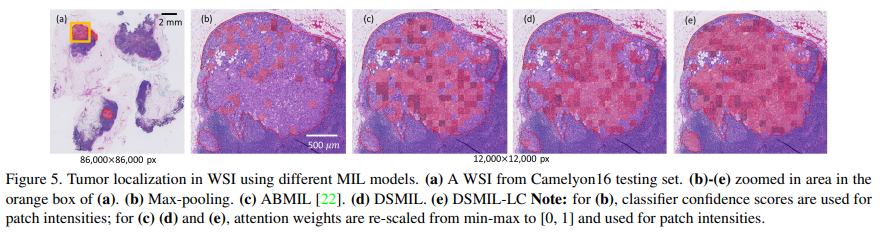
4.2. Results on TCGA Lung Cancer dataset
또한 The Cancer Genome Atlas(TCGA) 폐암 데이터 세트에 대한 결과를 제시합니다. 데이터 세트를 다시 소개하고 결과에 대해 논의합니다.
Dataset.
WSI에는 폐암의 두 가지 하위 유형인 폐 선암종과 폐 편평 세포 암종이 포함되며 총 1054개의 진단용 디지털 슬라이드가 국립 암 연구소 데이터 포털에서 다운로드할 수 있습니다. 우리는 WSI를 840개의 교육 슬라이드와 210개의 테스트 슬라이드로 무작위로 분할했습니다(4개의 낮은 품질의 손상된 슬라이드는 폐기됨). 이 데이터 세트는 백당 평균 약 5000 및 350개의 패치로 20배 배율에서 520만 개의 패치와 5배 배율에서 0.36만 개의 패치를 생성합니다. 이 데이터 세트에는 슬라이드 수준 레이블만 사용할 수 있습니다.
생성된 백에는 양성 백에 대한 종양 및 건강한 패치 유형과 음성 백에 대한 모든 건강한 패치의 혼합물이 포함됩니다. 이 데이터 세트의 종양 슬라이드에는 종양 영역의 많은 부분(슬라이드당 >80%)이 포함되어 있어 양성 백에 있는 양성 패치의 많은 부분으로 이어집니다. 따라서 MIL을 고려하지 않고 패치 기반 방법을 사용하여 분류기를 교육하는 것은 이미 합리적인 결과를 가지고 있습니다(즉, WSI의 패치가 모두 교육에서 전체 WSI와 동일한 레이블을 가진 것처럼 처리하고 테스트 중인 WSI). MIL을 고려하면 상당히 개선된 결과를 얻을 수 있음을 보여줍니다.
Classification Results.
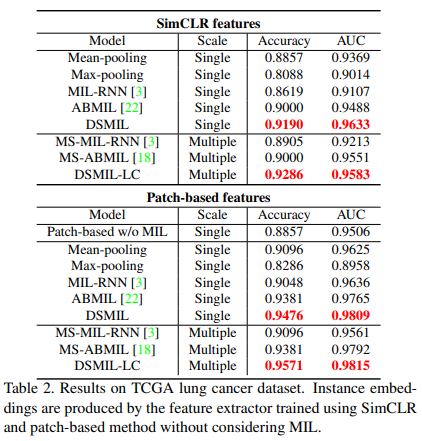
이 데이터 세트에 대한 MIL을 고려하지 않고 SimCLR과 패치 기반 방법으로 학습한 기능을 모두 비교합니다. 대조적으로 패치 기반 방법은 양수 백에 많은 수의 음수 패치로 인해 Camelyon16에 대해 수렴하지 않으므로 패치 기반 기능 결과는 Camelyon16에 포함되지 않습니다. 결과는 Camelyon16 데이터 세트와 유사한 결론을 제시하는 표 2에 요약되어 있습니다.
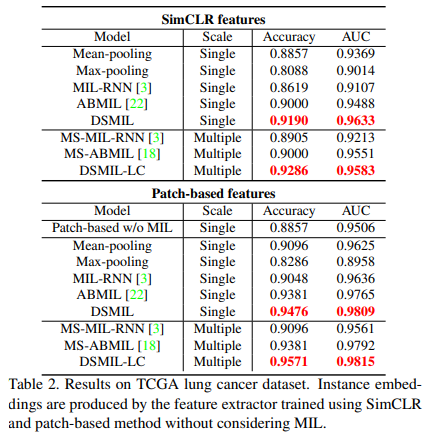
4.3. Ablation Study
이제 모델의 세 가지 주요 구성 요소인 DSMIL 애그리게이터(aggregator), 인스턴스 기능에 대한 자체 감독 대조 학습 및 멀티스케일 어텐션 메커니즘에 대한 제거 연구를 통해 모델의 기여도를 설명합니다. 우리는 DSMIL 애그리게이터를 유지하고 WSI에 대한 다양한 멀티스케일 기능 융합 방법뿐만 아니라 다양한 방법으로 학습한 기능을 비교합니다. DSMIL 집계기의 성능은 이전 섹션의 두 WSI 데이터 세트에서 시연되었지만 절제 연구에서 여러 고전적인 MIL 데이터 세트에서 MIL 집계기에 대한 광범위한 벤치마크 실험을 추가로 수행합니다.
Effects of Contrastive Learning.
자기 지도 대조 학습으로 학습한 기능을 여러 기준과 비교합니다. 1) maxpooling 연산자 [3]에서 학습한 특징 추출기를 사용합니다. maxpooling을 사용한 end-to-end 교육은 최대 점수 인스턴스를 동적으로 찾고 대용량 메모리 없이 모델 가중치를 업데이트하는 데 사용되는 for-loop에서 수행할 수 있습니다. 2) MIL을 고려하지 않고 패치 기반 방법으로 훈련된 특징 추출기를 사용(훈련 시 WSI의 패치를 모두 WSI와 동일한 레이블을 가진 것처럼 처리하고 테스트 시 WSI의 패치 점수를 평균화함). 3) ImageNet 데이터셋[13]에서 미리 훈련된 특징 추출기를 사용합니다.
결과는 표 3에 나와 있습니다. 균형이 맞지 않는 백(예: Camelyon16 데이터 세트)의 경우 자체 감독 대조 학습을 통해 종단 간 max 풀링 training에서 얻은 기능과 비교하여 분류 정확도가 최소 16% 이상 높아져 훨씬 더 나은 성능을 얻을 수 있습니다. 균형 잡힌 백(예: TCGA 폐암 데이터 세트)의 경우 자기 감독 대조 학습으로 학습한 기능은 패치 기반 방법의 기능과 비슷하지만 엔드 투 엔드 최대 풀링 교육보다 여전히 훨씬 더 우수합니다(> 14% 더 높은 정확도). 균형이 맞지 않는 백의 경우 패치 기반 방법은 포지티브 백에 많은 양의 네거티브 샘플로 인해 좋은 기능으로 이어지지 않습니다. 또한 대조적인 학습 기능에 최대 풀링을 사용하는 것이 최대 풀링의 종단 간 훈련보다 약 10% 더 우수하다는 것을 관찰합니다. 결과는 self-supervised contrastive learning이 bag에 있는 negative 및 positive instance의 분포에 관계없이 MIL에 대한 좋은 표현을 얻을 수 있는 실행 가능한 방법이며 또한 큰 bag 크기로 인해 발생하는 메모리 요구 사항 문제를 완화함을 시사합니다.
Effects of Multiscale Attention.
우리는 멀티스케일 어텐션 메커니즘을 멀티스케일 WSI 기능을 고려하는 몇 가지 다른 방법과 비교합니다. 1) 완전 연결 레이어 전에 각 배율에서 훈련된 MIL 모델의 백 임베딩을 연결합니다. 2) 각 배율에서 학습된 MIL 모델의 예측에 대해 최대 풀링을 사용합니다[3]. 3) 다양한 스케일의 인스턴스를 백에 혼합하고 백을 MIL 모델에 공급합니다[18].
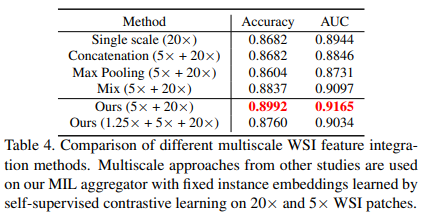
표 4는 Camelyon16 데이터 세트에 대한 결과를 나타냅니다. 우리의 멀티스케일 어텐션은 단일 스케일 접근 방식보다 3%, 기타 멀티스케일 접근 방식을 최소 1.5% 능가하므로 멀티스케일 기능을 고려하면 WSI에 대한 탐지 정확도가 향상되고 구조화된 멀티스케일 기능이 결과를 더욱 향상시킬 수 있음을 시사합니다. 그러나 두 가지 수준(5×+20×)을 사용하면 세 가지 수준(1.25×+5×+20×)을 모두 사용하는 것보다 +1.6%의 정확도와 +1.3%의 AUC로 더 나은 결과를 얻을 수 있습니다. 우리는 때때로 더 거친 척도(예: 1.25×)의 정보가 더 미세한 척도(예: 20×)만큼 효과적이지 않을 수 있으며 결과 벡터가 덜 식별될 수 있다고 추측합니다. 따라서 융합 전에 다른 척도의 기능을 재가중하기 위해 배율 수준에 따른 주의 메커니즘이 필요할 수 있습니다.
DSMIL Aggregator on Other MIL Tasks.
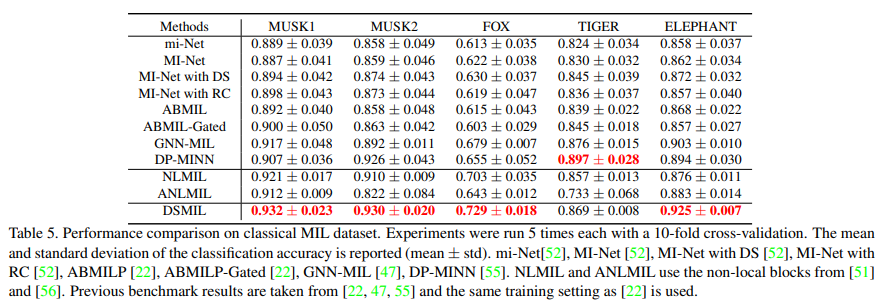
마지막으로, 기존 MIL 벤치마크 데이터 세트에서 듀얼 스트림 MIL 집계기를 벤치마킹합니다. 이러한 데이터 세트는 인스턴스의 추출된 특징 벡터로 구성되며 특징 추출기를 학습할 필요가 없습니다. 처음 두 데이터 세트(MUSK1, MUSK2)는 분자 형태를 기반으로 약물 효과를 예측하는 데 사용됩니다. 분자는 서로 다른 형태를 가질 수 있으며 그 중 일부만이 효과적인 형태일 수 있습니다[14]. 각 백에는 동일한 분자의 여러 형태가 포함되어 있으며 적어도 하나의 형태가 효과적이면 백에 양성으로 표시되고 그렇지 않으면 음성으로 표시됩니다. 다른 3개의 데이터 세트인 ELEPHANT, FOX 및 TIGER는 이미지에서 추출한 특징 벡터로 구성됩니다. 각 백에는 이미지의 세그먼트 그룹이 포함되며 하나 이상의 세그먼트에 관심 있는 동물이 포함되어 있으면 백에 양수 레이블이 지정되고 해당 동물이 표시되지 않으면 음수 레이블이 지정됩니다.
특징 벡터(인스턴스 임베딩)가 이미 제공되었으므로 실험에는 특징 벡터를 DSMIL 집계기에 직접 공급하는 작업이 포함됩니다. MIL 문제에 대한 다른 최근의 비로컬 아키텍처에 대해 MIL 애그리게이터를 테스트하기 위해 제안된 DSMIL 애그리게이터를 NL51 및 ANL56의 비로컬 블록으로 대체하고 5개의 MIL 데이터 세트 5. 실험은 10배 교차 검증으로 각각 5번 실행됩니다. 벤치마크 결과는 당사의 듀얼스트림 MIL 통합기가 일반적인 MIL 문제에서 NL 및 ANL과 같은 기타 비로컬 작업뿐만 아니라 이전 최고의 MIL 모델보다 평균 3% 더 우수한 성능을 보인다는 것을 보여줍니다.
5. Conclusion and Future Work
본 논문에서는 Weakly Supervised WSI 분류를 위한 새로운 MIL 기반 접근법을 제시한다. 우리의 방법은 대표적인 WSI 데이터 세트에 대한 이전 방법에 비해 상당한 개선을 보여주었습니다. 우리의 핵심 기술 혁신은 MIL 벤치마크 데이터 세트와 대표적인 WSI 데이터 세트 모두에서 최신 MIL 모델을 능가하는 새로운 MIL 집계기입니다. 또한 MIL 모델에서 자기 감독 대조 학습을 활용하고 다중 스케일 기능을 통합할 것을 제안합니다. 우리의 방법은 WSI 분류를 위한 MIL 모델에 제안된 애그리게이터, 대조 학습 및 멀티스케일 기능을 추가로 통합합니다. MIL 문제로 WSI에서 종양 탐지를 캐스팅함으로써 우리의 솔루션은 주석이 없는 슬라이드를 대량으로 사용할 수 있는 실제 임상 응용 프로그램에 대한 잠재력을 가지고 있습니다. 우리는 우리의 작업이 MIL과 전산 조직병리학 모두를 위한 확실한 진전을 제공한다고 믿습니다.
향후 연구에는 조직병리학적 데이터의 특성에 적응하는 자기 감독 학습 전략 설계가 포함됩니다. 또한 공간 관계를 모델링하는 메커니즘을 통합하여 공간적으로 구조화되고 잠재적으로 추가 개선으로 이어질 수 있는 WSI의 거시적 기능을 캡처할 수 있습니다.
