
Abstract
열화가 심한 이미지에서 사람의 얼굴을 복원(Blind Face Restoration) 하는 것은 대단히 어려운 일이다. 알 수 없고 복잡한 방법으로 열화가 생긴 이미지를 non-blind 방법으로 학습한 deep neural network (DNN) 모델로 결과를 보면 참담하다. 다행히도 Generative adversarial network (GAN) 기반 방법이 조금 더 나은 결과를 보여주지만 너무 그림같이 이미지를 생성하는 경향이있다. 그래서 이 논문은 처음으로 U-shaped DNN과 GAN을 이용한 사람 얼굴 복원 모델을 새로운 방법으로 제안한다. 이 모델은 global face structure, local face details 그리고 background를 조절해서 현실같은 얼굴을 생성한다.
Introduction
얼굴 이미지는 일상 생활에서 자주 접할수 있는 타입 중 한개이다. 얼굴 이미지는 일상 생활에서 자주 공유하고 보정을 통해 이미지에 열화가 생긴다. 컴퓨터 비전쪽에는 이러한 열화가 심한 이미지를 복원하기 위해 많은 관심을 쏟고있다. 전통적인 이미지 복원 방법은 수작업이나 열화가 생긴 원인을 찾아 거꾸로 문제를 풀어가는 방식을 많이 선택하였다. 하지만 복원하는 시간이 오래 걸렸었고 실용적이지 못했다. 최근에는 DNNs을 통해 얼굴을 복원하는 모델들이 수차례 나왔고 결과들도 나쁘지는 않았다.
하지만 현존하는 모델들은 알 수 없고 복잡한 열화가 있는 얼굴 이미지에서는 별 효과가 없었다. 그래서 많은 연구자들이 어려움을 느끼고 새로운 모델들을 개발을 하였지만 현실같은 얼굴로 복원을 하는데 한계가 있었다. 그나마 Pix2PixHD 모델은 현실적인 얼굴로 복원하는데 성공했지만 여전히 얼굴이 뭉게진것 처럼 보이는 artifacts가 남아있었다.
GAN의 대한 많은 관심과 연구로 GAN 기술력은 하루하루가 다르다. 최근에는 굉장히 해상도가 작은 얼굴 이미지를 GAN을 이용해서 복원하는 모델이 있었다. 이 모델의 연구자 Richardson은 encoder network를 통해 series of style vectors를 생성했고 이 vectors를 pre-trained generator에 input으로 넣었다. 굉장히 놀랄만한 성과였지만 여전히 blind image super-resolution 문제까지는 완벽하게 풀 수 없었다. 또한 뒤의 배경이 복잡한 형태로 이루어져 있으면 인위적으로 얼굴을 생성한 티가 많이 났었다.
이 논문은 DNNs 그리고 GAN 모델의 장점을 가져와 새로운 모델을 설계한다. 첫번째로, pre-train GAN for High Quality face image generation 모델을 DNN 디코더에 block 형식으로 집어넣는다. 그리고 이 모델을 fine-tunning을 하는데, 이때 저해상도-고해상도 이미지를 쌍으로 묶어 새로운 모델을 학습시킨다. DNN 모델은 열화가 심한 input을 깨끗하게 한 뒤 latent space에 매핑하는 방법을 배우고 GAN network가 목표한 고해상도 얼굴 이미지를 재생성할 수있게 도운다. 논문의 연구자들은 U-shaped DNN의 deep features 들이 latent code 통해 global face reproduction을 생성할 수 있게 GAN 블럭들을 디자인했다. 그리고 shallow features로 local face details을 살리고 뒷배경은 그대로 놔둘 수 있도록 했다. 결과적으로 이 연구를 통해 현실적인 디테일들을 담고 있는 고해상도 이미지를 생성할 수 있었다.

Related Work
Generative Adversarial Network (GAN) 모델이 성공적으로 연구가 된 이후 많은 컴퓨터 비전 테스크에서 사용된다. 이유는 GAN을 통해 현실적인 이미지를 생성할 수 있었기 때문이였다. 특히 여러분야에서 많이 쓰였는데 image inpainting, super-resolution, image colorization, texture synthesis, 등 많은 분야에서 사용했다. 특히 유저에게 다양한 컨디션을 적용할 수 있도록 제안한 (cGAN)을 통해 다양한 image-to-imge translation 문제들을 해결할 수 있었다. cGAN으로 부터 unsupervised learning, disentangled learning, few-shot learning, high resolution image synthesis, multi-domain translation, multi-modal translation 이 파생되었다. 하지만 안타깝게도 cGAN을 이용한 결과들은 over-smoothing 문제가 있었다.
Deep generative 모델들은 inverse problems을 푸는데 유용하다. 예를 들어 deblurring, image inpainting, phase retriebal, 등. Inverse problems을 연구하며 이미지를 pre-trained GAN 모델을 사용해 latent code 변경하는 방법 또는 추가적인 인코더를 통해 image space를 latent space로 변경하는 방법에 대해 개발했다. 하지만 연구 초반에는 추론시간이 느려 실용적이지 못했다. 이후 모델 최적화를 거듭해서 Pixel2Style2Pixel 모델이 세상에 공개되었고 광범위하게 image-to-image translation에 사용될 수 있었다. 하지만 여전히 image space를 latent space로 바꾸는 것은 어려웠고 또한 열화가 있는 얼굴 이미지에는 더욱 더 변경하기 어려웠다.
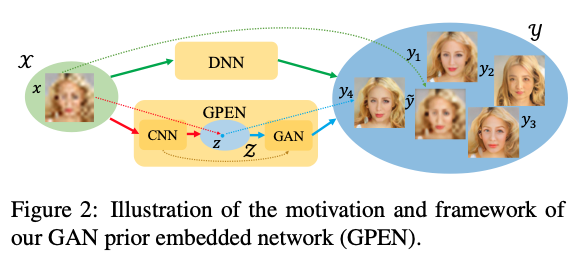
이 논문은 얼굴을 생성하는 GAN모델을 DNN에 모델에 내장시켜 얼굴 복원하는 모델을 만들었다. 이 후 GAN 모델을 DNN 모델안에서 fine-tune 하고 latent code와 noise input이 열화가 있는 이미지로부터 잘 복원할 수 있도록 학습을 했다.
Proposed Method
Motivaition and Framework
얼굴을 복원하는 일은 inverse problem 이다.
= space of degraded Low Quality faces images
= space of original HQ face images
일단 얼굴 복원 모델은 LQ 얼굴 이미지 를 통해 깨끗한 얼굴 이미지 의 데이터를 찾는다. 대부분의 DNN 기반 방법론이 그렇듯 를 와 매핑시켜 학습을 하는 것이 목표이다. 하지만 이러한 방법은 one-to-many inverse 문제를 야기시키고 를 통해 여러개의 다른 y 얼굴 이미지를 생성할 수 있는 단점이 있다. 현재 DNN 모델들을 보통 pixel-wise loss function을 이용해서 학습을 시킨다. 그 결과로 Figure 2의 결과처럼 over-smoothed 그리고 많은 이미지 정보 손실이 일어난다. cGAN을 통해 불확실한 매핑 확률을 줄여서 이러한 문제들을 조금이나마 해결할 수 있지만 복잡한 열화 포함한 이미지에는 효과가 떨어진다.
이 논문의 연구자들은 미리 학습시킨 GAN 모델을 DNN 디코더 네트워크에 내장시켜 고해상도 얼굴 이미지를 복원한다. 그리고 이것을 GAN prior embedded network (GPEN)이라고 칭했다. Figure 2에서 언급했듯이 GPEN의 첫번째 네트워크는 CNN encoder 이다. Encoder는 열화 input 와 GAN으로 생성된 latent space 안에 있는 latent code 와 매핑해서 학습을 한다. 사전에 학습 된 GAN이 고해상도 이미지를 생성한다 ( -> ). 생성자의 프로세스는 기본적으로 one-to-one mapping이고 one-to-many mapping에서 생긴 불확실한 것들을 완화시켜준다.
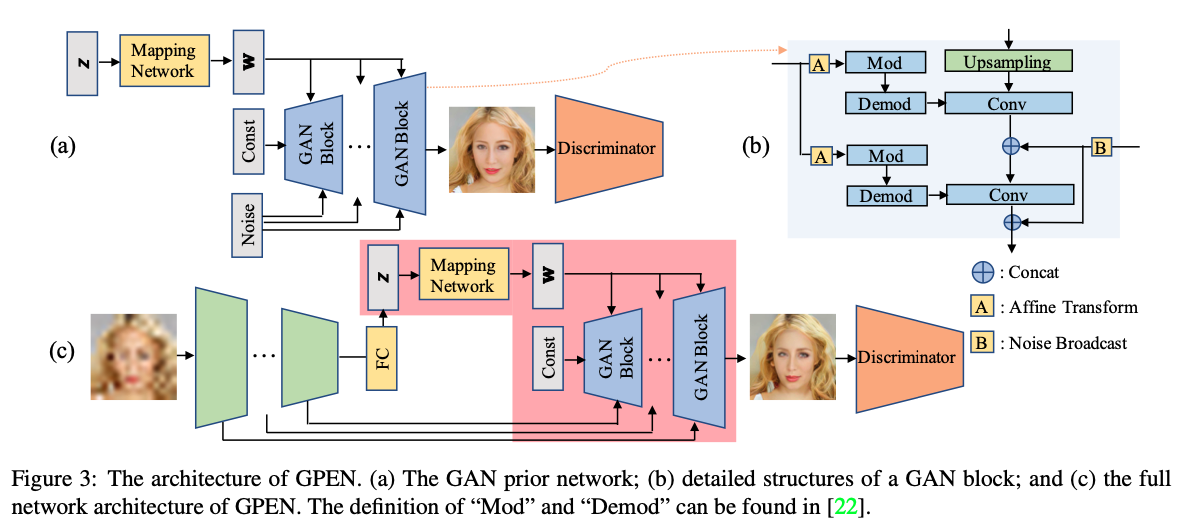
GAN inversion 방법론들이 GPEN과 비슷한 성격을 가진 아이디어이지만, GAN inversion 방법론들은 pre-trained GANs을 그대로 사용해서 얼굴을 복원한다. 반면에 GPEN은 pre-trained GAN 블럭들을 만들고 이것을 fine-tune 해서 효과를 증대시킨다. Figure 3은 GPEN과 GAN 블럭들의 구조를 설명하고 있다.
Network Architecture
U-Net은 이미지 복원에서 광범위하게 사용되고 이미지 디테일을 보존하는 능력이 탁월하다. 그래서 GPEN에서 U-shape의 encoder-decoder 구조를 사용했다. GAN 모델을 디자인 할 때 2가지 부분을 신경썼었다.
- 고해상도 이미지를 생성할 수 있어야 한다.
- GAN 모델이 쉽게 U-shaped GPEN의 디코더 블록으로 내장될 수 있어야 한다.
StyleGAN의 모델에서 많은 영감을 받아, 매핑 네트워크를 사용했고 latent code 를 less entangled space 로 변경할 수 있도록 했다 (Figure 3(a)). 이렇게 변경된 code 를 GAN 블럭에 통과시킨다. GAN 모델을 fine-tune할 것이기 때문에 U-shaped DNN 인코더에서 추출한 skipped features maps을 위한 공간을 만들어야한다. 또한 추가적인 noise inputs도 각 GAN 블럭들에게 전달한다.
GAN 블럭 구조에는 여러가지지 pre-trained 모델들이 내장될 수 있다. 이 연구는 StyleGANV2를 적용해서 고해상도 얼굴 이미지를 만들기로 했다. 하지만 StyleGAN v1, PGGAN 그리고 BigGAN 또한 GPEN에 쉽게 내장 될 수 있다. GAN의 블럭 수는 DNN 인코더에서 추출한 skipped feature maps의 수와 동일해ㄴ야한다. 이것은 이미지의 input 해상도와도 연관이 있다. StyleGAN은 다른 두가지의 noise inputs을 각 GAN 블럭에 요구하고 noise inputs을 재사용 할 수 있게 해야한다. 또한 noise를 add 대신 concatenate을 통해 convolutions을 합쳐서 더 많은 디테일을 살릴 수 있도록 한다.
Figure 3(c)를 보면 알 수 있듯, GAN 모델을 U-shaped DNN의 디코더로 내장했다. Latent code 와 noise inputs은 fully-connected(deep) 그리고 shallower layer로 교체가 됬다. 이것으로 global face structure, local face details 그리고 이미지의 뒷배경도 조정할 수 있게된다. 제안한 모델이 완벽히 convolutional 하지않기 때문에 LQ 얼굴 이미지는 로 사이즈 변경한 뒤 GPEN 모델의 input으로 사용될 수 있다. 그 다음 GPEN은 인코더와 디코더가 상호 학습을 통해 미세조정이 된다.
Training Strategy
- 사전에 GAN 모델을 고해상도 얼굴 이미지로 학습 (StyleGAN 학습 방법 동일)
- 위의 GAN 모델을 제안된 GPEN 모델에 디코더로 내장
- LQ-HQ 쌍으로 묶어 지도학습을 통해 전체 네트워크를 학습
GPEN 모델을 fine-tune하기 위해 여러가지의 loss functions을 사용
Loss functions
- adversarial loss
- content loss
- feature matching loss

기존 GAN 모델을 학습할 때 사용했던 loss function
= ground-truth HQ
~ = LQ
= Generator
= discriminator
L1-norm distance between the final results of the generator and the cor- responding ground-truth images.
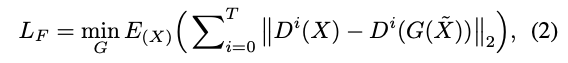
- perceptual loss와 비슷하지만 단순히 VGG를 discriminator로 사용
- 는 intermediate layers가 feature extraction에 사용 된 총 수
- 는 extracted feature가 된 discriminator layer의 인덱스
Final loss
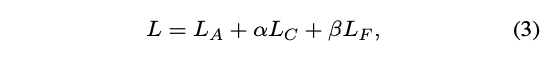
- (1)와 (0.02) 는 파라미터의 벨렁싱을 잡아주는 역할
- content loss 는 원본의 색 정보를 보존
- feature matching loss 는 discriminator
- adversarial loss 는 현실적인 디테일이 포함한 얼굴 이미지로 복원
Experiments
Datasets and Evaluation Metric
- 70,000 FFHQ datasets을 GAN 모델을 학습하는데 사용
- 그 다음 열화가 있는 LR과 HR을 쌍으로 묵어 GEPN 전체 네트워크를 fine-tune
Main Contributions
- DNN에 pre-trained GAN network를 추가하고 DNN에 내장 된 GAN을 fine-tune 한다. 이전의 연구들은 오직 fine-tune이 안된 pre-trained GAN을 DNN에 추가했다.
- GAN 블럭들을 디자인해서 쉽게 U-shaped DNN에 내장해서 fine-tuning을 할 수 있게 했다. GAN의 latent code와 noise input이 deep 그리고 shallow features을 통해 global structure, local face details 그리고 뒷 배경을 생성할 수 있게 했다.
- 현실세계에서 열화가 심한 이미지에도 이 논문의 저자가 만든 모델을 사용해서 완벽하게 복원할 수 있다.
.png)
안녕하세요. [Blind Face Restoration]을 GitHut에 소개를 하던데 어떻게 다운로드 받을 수 있을까요? GitHut 그런 곳에 가보면 항상 파일들을 하나씩 나열을 해놓았더군요. 하나씩 일일이 다운로드 받아야 하는 게 불편한 일인데 왜 그렇게 해 놓을까요? 그 파일들은 다운로드 받으라고 올려놓은 게 아닌 건가요?