Introduction
최근에 GAN으로 생성한 이미지의 품질과 해상도가 크게 향상되었다. 수 많은 연구가 있었지만 현실적인 이미지를 생성하는 것은 불완전해보였다. 논문의 저자는 아마도 이미지의 synthesis processs (original of stochastic features)를 아직까지 잘 이해하지 못했었기 때문이라고 주장한다. 왜냐하면 synthesis의 특성을 다른 모델과 정량적으로 비교할 수 없었기 때문이라고 한다.
이 논문은 style transfer literature에서 영감을 받아 새롭게 생성자의 구조를 설계했으며 image synthesis process를 통제할 수 있는 모델을 만들었다. 이 논문의 생성자는 이미지의 input과 각 convolution layer를 통과한 latent code 조절해서 직접적으로 다른 scales을 적용해 이미지의 스타일을 변경할 수 있다. 더 나아가 네트워크에 직접적으로 노이즈를 주입해서 high-level attributes을 조절해 사람의 포즈 또는 특성들을 바꿀 수 있다.
또한 이 논문은 Disentangle 데이터를 만들고 구별하기 위해 아래와 같은 측정법을 제시했다.
- Perceptual path length
- Linear separability
Style-based generator
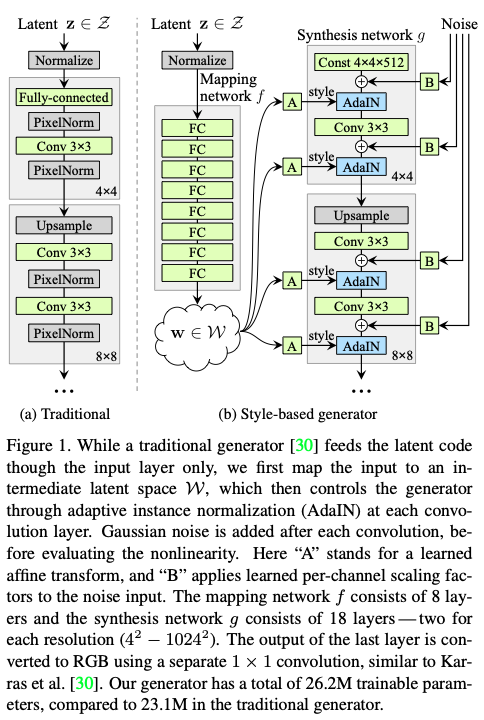
PG-GAN와 StyleGAN 모두 Progressive Growing 방식을 사용해 해상도를 점차적으로 늘린다. 하지만 PG-GAN은 stochastic latent variable 를 사용해 이미지를 생성하고 StyleGAN을 고정된 상수 값 4x4x512 텐서로 이미지를 만든다.
추가적으로, stochastic latent variables을 그대로 사용하지 않고 fully connected network 매핑 네트워크를 통해 비선형으로 변형시켜 스타일로 벡터로 만든다.
- Progressive Growing을 사용해 이미지의 해상도를 점차적으로 증가시킨다
- 이미지를 고정된 텐서 값으로 생성한다.
- 생성된 latent variables은 8번의 fully connected 매핑 레이어를 거쳐 비선형 벡터로 변형되고 변형된 벡터는 AdaIN normalizer을 거쳐 style vector로 사용된다.
Progressive Growing
Progressive Growing은 PG-GAN에서 제시한 고해상도 이미지를 만들기위한 방법이다. 모델을 간단하게 설명하자면, 저해상도 이미지부터 시작해 점차적으로 고해상도 이미지를 GAN(생성자와 식별자)으로 생성하는 방식이다.
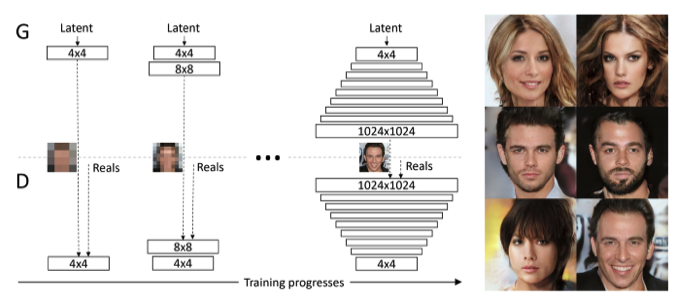
위의 이미지를 보면 알겠지만 시작하는 이미지의 해상도는 4x4이고 점차적으로 1024x1024 고해상도 이미지를 생성한다.
Style Modules(AdaIN)
![]()
AdaIN(Adaptive Instance Normalization)은 normalizer이지만 오직 style과 image statistics에만 적용이되고 learning parameter에는 적용이 되지 않는다. 그러므로 스타일을 변환하는데 유용하게 사용할 수 있다.
이 모듈은 매핑 네트워크에서 생성된 를 생성된 이미지로 전달한다. 이 모듈은 합성 네트워크의 각각의 단계에 더해지고 해당 단계에서의 시각적인 표현을 정의한다.

각 feature map 를 별도로 normalize해주고 style 의 scalar components를 통해 scaled와 biased로 변환해준다. 이후 scale과 bias는 각 채널의 컨볼루션 output을 shift 시켜 컨볼루션에서 각 필터의 중요성을 정의하고 로부터의 정보를 시각적으로 표현하고 이미지로 변환된다.
Quality of generated images

새로운 생성자의 특성을 알아보기 전에 저자는 이미지의 품질이 어떻게 개선되었는지 실험을 통해 증명하고자 한다.
테이블 1을 보면 GAN 성능 지표 중 하나인 FID(Frechet inception distances)의 스코어를 사용했고 CelebA-HQ & FFHQ 데이터셋을 사용했다.
- (A): Prgoressive GAN (PGGAN)
- (B): A모델 + bilinear up/downsampling operations
- (C): B모델 + AdaIN operations
- (D): C모델 + + 기존 input layer 삭제 및 고정 4x4x512 tensor 사용
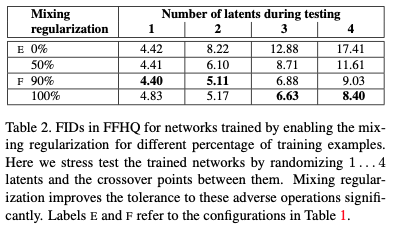
- (E): D모델 + noise input injection과 novel mixing regularization

Properties of the style-based generator
새로운 생성자 구조는 이미지의 synthesis를 scale을 수정해서 조절할 수 있다. mapping & affine transformations은 각 스타일 샘플을 그리기 위한 수단이다. 그리고 synthesis network는 스타일의 모음에 따라 이미지를 생성하는 역할을 한다. 각 스타일 효과는 각 네트워크내에 지역화된다. 이 말은 즉 특정 부분의 스타일을 수정하면 그 영역만 수정이 가능하다.
지역화를 살펴볼때는 AdaIN 연산자가 어떻게 사용되는지 보면 알 수 있는데, 각 채널들을 zero mean & unit variance로 normalize 해주고 scales와 biases를 스타일대로 적용시킨다. 새로운 per-channel은 스타일에 의존하고, 중요한 features는 convolution 연산자에 의해 결정된다.
Truncation trick in
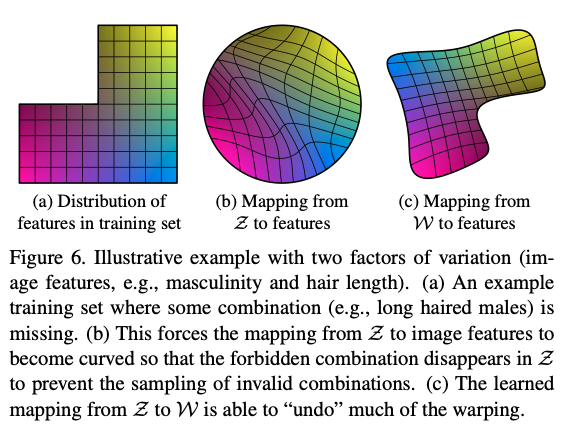
실제 학습 데이터의 분포를 고려하면, 밀도(density)가 낮은 부분의 경우 불안정한 학습이 된다. 이러한 부분을 방지하기 위해 쓰는 방법이 truncation trick이다.
이 방법은 학습 중에 조정하는 것이 아닌 학습이 완료된 네트워크의 input을 제어하는 방식이다. 보통 이전 GAN 모델에서는 직접적으로 를 truncation trick에 적용했지만 이 논문의 모델은 mapping network의 결과물인 의 space 에 적용해서 사용했다.
는 0~1 사이 값으로 설정하고 1이면 truncation trick 사용하지 않는 결과랑 동일하고 0이면 평균적인 결과물이 나온다.
Style mixing
StyleGAN은 Mixing Regularization를 사용한다. 이 정규화는 두 개의 latent variables을 섞어 학습 때 스타일 벡터에 사용된다. 예를 들어 와 매핑 네트워크에서 통과 된 는 4x4 이미지를 생성할 때 사용하고 은 8x8 이미지를 생성할 때 사용된다. 이 방법을 통해 인접 스타일이 상관관계가 되는 것을 방지한다.

상관 관계 방지를 통해 지역화를 향상시켜 FIDs 스코어 점수가 나아진 것을 확인할 수 있었다. 은 2개의 latent codes를 여러 scales을 통해 나온 결과물이다. 위의 이미지는 latent variables가 Source A와 Source B를 생성하기 위해 사용했다. 이 결과로 특정 구간에서 이미지의 특성을 바꾸는 것을 확인할 수 있었다.
예로 latent variable of B는 저해상도 구간에서 사람의 얼굴, 피부, 성별, 나이 등을 source B와 비슷하게 생성하고 고해상도에서는 뒷배경이나 머리카락의 색을 조절할 수 있었다.
Stochastic variation
사람의 초상화는 사람의 머리카락, 반점, 모공등을 많은 특징들을 포함하고 있는데 올바른 정규 분포를 사용한다면 자연스럽게 바꿀 수 있다.
기존의 모델은 어떤식으로 stochastic variation을 적용시켰는지 살펴보자. 기존 모델은 input을 input layer에 통과시키기만 했다. 네트워크가 이미지를 생성하기 위해서는 임의 공간 난수를 생성해야하는데 생성하는 것이 쉽지 않았고 생성하더라도 모든 이미지에서 성공적이지 않았다. 하지만 새로운 모델은 per-pixel noise를 각 convolution에 주입시켜 문제를 해결했다.

는 같은 이미지에 다른 noise realization을 추가해서 다른 결과값을 보여준다. 하지만 stochastic aspects에만 영향을 주었을뿐 나머지 영역에 영향은 주지않은 것을 확인할 수 있다.

는 stochastic variation을 다른 subset of layer에 적용한 것 이다. 이 논문의 저자는 네트워크가 stochastic variation을 만드는 가장 쉬운 방법은 노이즈를 추가하는 것이라고 가설을 세웠다.
Separation of global effects from stochasticity
에서 설명하는 지표는 만약 latent space가 disentanglement 하다면 의 값이 변동이 있더라도 큰 차이가 없어야한다고 말하고 있다. 만약 Entanglement 하다면 다양한 features들이 서로 얽혀있기 때문에 모든 영역에 영향이 있다고 말한다.
Disentanglement studies
일반적으로 Disentaglement 의미는 얽힌 것을 푸는 것이지만 여기서 말하는 의미는 latent space가 선형적인 구조를 이용해 한개의 variation으로 조절하는 것이 목표이다. 예를 들어 variation으로 이미지의 특정 부분 (머리카락 위치나 길이, 포즈 등)만 영향을 주게 되면 그것을 disentanglement라고 한다.
Perceptual path length
Perceptual Path Length (PPL)은 이미지의 변화가 지각적으로 부드럽게 변했는지 측정한다. 조금 더 자세히 말하자면, 가짜 이미지가 latent space에서 가장 짧은 지각적 경로에서 변경되어 생성되는지 확인하는 것이다.
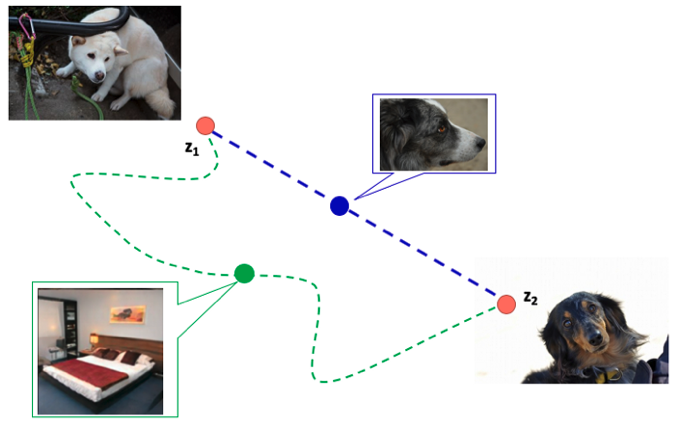
가정을 통해 조금 더 쉽게 이해해보자. 만약 latent variable 이 하얀색 강아지를 생성하고 latent variable 가 검은색 강아지를 생성한다고 하자. 이 둘 이미지 요소의 다른점은 강아지의 색 빼고는 없기 때문에 latent variable의 변화가 하얀색과 검은색 사이에서만 움직인다. 그러므로 중간 latent variable을 통해 회색 강아지 이미지가 생성이 된다. 다른 말로, 파란색 경로는 오직 색만 변경하기 때문에 짧은 지각적 거리를 가지고 있다고 말할수있다. 반면에 초록색 경로는 물체의 모양도 변경해야하기 때문에 상대적으로 긴 지각적 거리를 가지고 있다고 말할수있다.
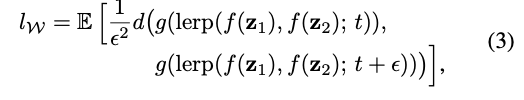
위의 공식은 PPL을 정량적으로 계산하기 위한 식이다. 이 식으로 ratio 와 ratio 에서 latent varialbes & 으로 생성된 2개의 이미지의 거리를 잴 수 있다.
예상하겠지만 파란색 경로의 강아지 이미지 와 의 지각적 거리는 가깝고 거리의 값은 작다. 반면에 침대와 강아지의 거리는 상대적으로 길고 값은 크다. 결과적으론 거리가 짧고 값이 작을 경우 사람이 생성된 이미지를 부자연스럽게 인지하는 상황이 드물게 생기는 것을 확인할 수 있었다.
Linear seperability
Latent space가 disentangle 하다면 특성을 나누는 벡터의 방향을 정확하게 찾아낼 수 있다는 개념에서 출발한 지표이다. 선형적인 초평면(linear hyperplane)을 가지고 이를 나눌 수 있다면 이는 latent space가 얽혀 있지 않다고 할 수 있다.
이 논문은 40개의 변수를 이진 분류할 수 있는 40개의 auxiliary classfication network를 학습을 하고 생성기로 생성한 20만장의 이미지를 auxiliary network에 집어넣고 신뢰도가 높은 상위 50%의 이미지만 보관한다. 이후 input 변수는 생성된 이미지의 와 값을 linear SVM을 사용해서 분류하고 분류가 잘되면 linear hyperplane만으로도 특성을 잘 잡는 결과를 보여준다.
Analysis of StyleGAN
StyleGAN은 고해상도의 이미지를 현실적으로 생성한다. 하지만 특정 부분에서 노이즈를 생성하고 또 부자연스러운 부분을 생성하기도 한다.

빨간 동그라미로 표시된 노이즈는 항상 발생되는 것은 아니지만 특정 해상도 64x64에 모든 feature maps에서 발생된다. 논문의 저자는 normalization layer (AdaIN) 때문에 생성되는 것이라고 생각하고 있다. 스파이크 유형 분포가 작은 feature map에 들어오면 원래 값이 작더라도 AdaIN에 의해 값이 증가하여 큰 영향을 준다.
다음은 부자연스러운 부분에 대한 지적이다. 때때로 생성된 이미지의 작은 특성들이 얼굴의 각도가 달라졌음에도 불구하고 고정된 방향성을 가지고 있어서 부자연스럽게 보인다. 이 논문의 저자는 아마 이러한 부자연스러움이 progressive growing에서 비롯된 것이라고 한다. Progressive growing에서 각 해상도에서 이미지를 독립적으로 생성한 것이 문제였던 것이다.
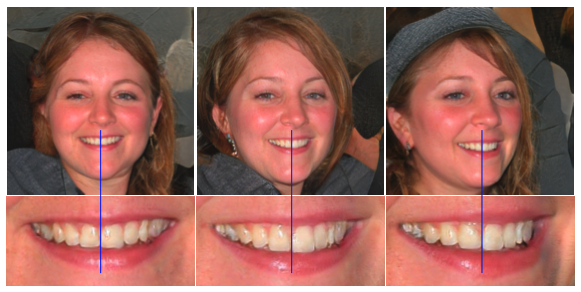
StyleGAN2는 이러한 문제점을 해결하기 위해 PPL과 향상된 droplet noise & non-follwing modes로 극복하고자 한다.
.png)