[Abstract]
보통 CNN 기반의 네트워크는 초기 층에서 high resolution 으로 시작해서 층이 깊어질 수록 low resolution으로 축소하여 convolution 을 진행했다. 하지만 이 논문의 네트워크는 초기 층부터 마지막 층까지 high resolution 을 유지해서 결과를 생성한다.
이 논문에서 주장하는 high resolution subnetwork 를 high to low로 구성되어 있는 층마다 하나씩 추가해 원본의 resolution 을 유지하고 동시에 multi-resolution subnetwork 와 multi-scale fusion 을 통해 병렬적 처리할 수 있도록 한다. 그 결과 더욱 정확한 keypoint heatmap 을 얻을 수 있었다.
[Introduction]
2D human pose estimation 은 컴퓨터 비전에서 근본적이고 핫한 문제이다. 이 분야의 목표는 사람 관절을 각 파트(팔, 다리, 손목, 등)로 구분할 수 있게 하는 것이다. 또한 human action, recognition, human-computer interaction, animation 등에서 많이 사용되었다. 이 논문은 single-person pose estimation, 즉 단 사람 타겟을 목적으로 body pose estimation 할 수 있는 모델을 소개한다.
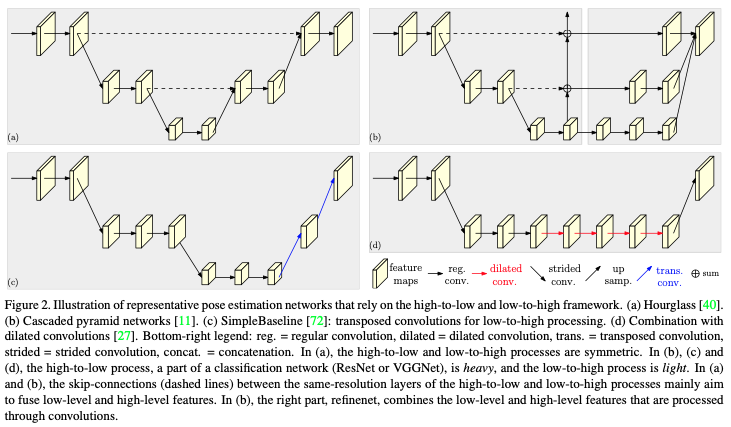
최근에 deep convolutional neural networks 를 통해 이 분야의 기능들이 비약적으로 향상되었다. 보통 CNN 기반의 네트워크는 input 의 해상도를 층마다 축소시키는 high to low resolution subnetworks 방식을 사용한다. 그리고 나중에 축소 된 해상도를 upsampling 방식으로 복원을 가장 많이 사용해왔다. 예로 symmetric low-to-high process + transposed convolution layers 또는 ResNet의 마지막 부분에 들어가는 Dilated convolution 방식이 있다.
이 논문은 고해상도를 처음부터 끝까지 유지하는 High-Resolution Net (HRNet) 을 선보인다. 이 모델의 경우 high-resolution subnetwork 를 첫 스테이지부터 추가하고 점진적으로 깊어지는 층마다 추가한다. 그리고 이 subnetwork를 병렬적으로 처리하기 위해 multi-resolution 을 사용한다. 그리고 multi-scale fusion 로 multi-subnetwork 들 간에 정보들을 병렬적으로 전달할 수 있게 도와준다. 그 결과 input 이 가지고 있는 해상도를 유지한 채 keypoints 를 찾아낸다.
이 논문은 다른 pose estimation 모델 대비 HRNet의 좋은점 2가지를 소개한다.
첫째, 다른 모델과 달리 순차적으로 처리하지 않고 병렬적으로 처리가 가능했기 때문에 처음부터 끝까지 동일한 고해상도를 유지할 수 있었다. 그 결과 output heatmap 이 조금 더 공간적으로 정확하다.
둘째, 기존에 있었던 fusion 방식과 다르게 반복적인 multi-scale fusion 방식을 사용했다. 그 결과 깊은 네트워크 층에서 저해상도가 가지고 있는 특징을 고해상도 이미지에서도 가질 수 있었기 때문에 더 풍부한 정보를 이용해서 높은 정확도를 확보할 수 있다.
위의 장점을 입증하기 위해 keypoint detection 에서 보편적으로 사용하는 벤치마크 데이터셋 "the COCO Keypoint detection data" 과 "the MPII Human Pose dataset" 으로 증명했다.
Related Work
Deep learning 기반의 Body pose estimation 방법은 두 갈래로 나눠진다.
첫째, Regressing the position of keypoints
둘째, Estimating keypoint heatmaps (가장 높은 정확도 값을 가진 히트맵 정보를 선택하는 방법)
대부분의 heatmap 을 사용하는 cnn 기반의 body pose estimation 경우 image classification 에서 많이 사용하고 있는 stem subnetwork 을 사용한다. Stem subnetwork 는 위에서 많이 언급되었던 high-to-low resolution & low-to-high resolution 방식이다. 예를 들어, Input 의 해상도를 점진적으로 줄이고 main body 에서 input 에서 동일한 해상도로 생성한다. 그 다음 regressor (회귀자)를 통해 keypoints 의 heatmaps 을 예측한다. 그리고 기존 이미지에 적용시킨다.
High-to-low and low-to-high
먼저 high-to-low process 는 저해상도와 high-level representations 을 생성하고 low-to-high process 는 고해상도와 high-level representations 을 생성하는 것이 목적이다. 여기서 high-level representations 이란 이미지가 가지고 있는 특징들을 최대한 보존하는 것을 뜻한다.
여러가지 대표적인 네트워크의 디자인인 경우 아래와 같은 특징들을 포함하고 있다.
첫째, Symmetric high-to-low and low-to-high process
둘째, ResNet low-to-high process 에서 사용하는 blinear-upsampling 또는 transpose convoluton layers
셋째, dilated convolution 을 ResNet 또는 VGGNet 의 마지막에서 2번째 층에 적용시켜 spatial resolution 손실을 제거한다. 그 결과 low-to-high resolution process 때 많이 소모되는 computation cost 를 줄인다.
Multi-scale fusion
Multi-resolution images 를 개별적으로 multiple networks 에 전달하고 output 의 response maps 을 취합한다. High-to-low process 에서 생성 된 low-level 의 features 와 low-to-high process 에서 생성 된 high-level 의 features 를 skip connection 을 통해 합친다.
다른 방법으로는 cascaded pyramid network 가 있다. globalnet 으로 high-to-low process 에 있는 low-to-high level features 를 점진적으로 low-to-high process 에 합친다. 그리고 refinenet 가 CNN 을 통과한 low-to-high level features 합치는 작업을 한다.
HRNet 은 multi-scale fusion 을 반복하는 모델이다.
Intermediate supervision
Intermediate & deep supervision 은 초창기 image classification 을 위해 개발되었다. 또한 deep networks 을 학습하고 heatmap 예측 정확도를 향상시키기 위해 사용했다.
HRNet approach
HRNet 은 high-to-low subnetworks 를 병렬적으로 연결한다. High-resolution representations 을 전체 층 동안 유지시켜 heatmap 의 공간적 정보를 보존한다. 또한 반복적인 fusing 통해 high-to-low subnetworks 단계에서 high resolution representations 생성한다. HRNet 은 다른 모델과 다르게 low-to-high process 에서 개별적인 upsample 방식이 필요하다. 예로 각 스테이지에서 multi-scale 로 downsampling 된 이미지를 upsampling 을 해서 GT heatmap 과 동일한 이미지로 맞춰야하기 때문이다.
Approach
Human pose estimation 은 keypoint detection 이라고도 많이 부르고 위치 K의 keypoints 를 이미지 의 에서 탐지하는 것이 목적이다. State-of-the-art 의 모델들은 이미지 를 heatmaps ()을 예측하는 방식으로 변환시켰다. 여기서 는 각 k 번째 위치의 confidence 를 의미한다.
HRNet 은 이미지의 해상도를 축소하기 위해 보편적으로 사용되는 two strided CNN 방식의 stem pipeline 을 적용시켰다. 그리고 main body 에서 input feature maps 과 동일한 output feature maps 을 만드는 방식을 따랐고 regressor 가 heatmaps 을 예측해 완전한 output 을 생성한다.
Sequential multi-resolution subnetworks
기존에 있었던 pose estimation 모델들은 순차적으로 CNN 을 처리하는 high-to-low resolution subnetwork 을 사용했다. 또한 해상도의 크기를 반으로 줄이는 subnetworks 을 사용했다.
Parallel multi-resolution subnetworks
논문의 저자는 점진적으로 high-to-low resolution 을 위한 subnetwork 을 층마다 추가 했고 multi-resolution subnetworks 을 병렬적으로 연결했다. 그 결과, later stage의 parallel subnetworks 에 대한 해상도는 전에 있던 stage의 해상도와 더 낮은 해상도로 구성하고 있다.
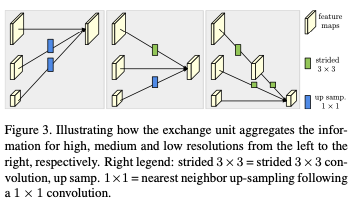
Repeated multi-scale fusion
Repeated multi-scale fusion 은 소개단에서 설명한 반복적이고 parallel subnetworks 끼리 정보를 전달하는 units 이다. 아래의 그림과 같이 정보들이 병렬적으로 전달되는 것을 확인할 수 있다.
은 s 번째의 스테이지, b 번째 블럭, r 번째에 해상도의 convolution unit
논문의 저자는 kernel 그리고 stride 2를 가진 convolution 을 해상도를 2배 줄일 때 적용했고 4배를 줄일 때는 위의 CNN 을 2개로 붙여 사용했다.
Heatmap estimation
마지막 exchange unit 에서 Heatmap 을 회귀한다. 그리고 mean squared error 손실함수를 통해 GT 와 output heatmap 을 pixel-wise 로 비교하게 된다.
Network instantiation
HRNet 은 ResNet 의 각 스테이지에 depth 와 각 해상도에 채널의 값을 분산시키는 디자인을 예시로 들었다.
HRNet 의 경우 병렬적으로 해상도를 2배로 줄이고 키울 수 있는 subnetworks 와 4개의 스테이지로 구성하고 있다. 첫번째의 스테이지 경우 ResNet-50 과 동일한 4개의 residual units 을 가지고 있다. 두번째, 세번째의 스테이지 경우 1,4, 3의 exchange blocks 을 가지고 있다. 한 개의 exchange block 은 3x3 CNN 이 2개가 포함한 4 개의 residual units 으로 각 해상도에 접근할 수 있다. 결과적으로 한 개의 block 당 총 8개의 exchange units (8 multi-scale fusion) 을 포함하고 있다.
Experiments
COCO Keypoint Detection
Dataset
COCO 데이터셋의 경우 약 200,000 이미지와 250,000 17개의 사람 관절을 포함하고 있는 라벨링을 포함하고 있다. 논문의 저자는 COCO train2017 데이터셋을 사용했다. 그리고 evaluation 같은 경우 val2017 과 test-dev2017 셋으로 진행했다.
Evaluation metric
Body pose estimation 에서 가장 기본적으로 사용되는 평가지표는 Object Keypoint Similarity (OKS) 이다.
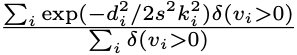
는 Euclidean distance 로 detected keypoint 와 corresponding GT 의 거리
는 물체가 보이는지 아닌지를 표현하는 flag
는 물체의 크기
는 관절 점의 종류 마다 설정되는 상수
Average Precision
AP 는 여러 인물 자세 추정의 평가에 이용되는 지표이다. 이는 추정 자세와 정답 사세의 유사성을 나타내는 척도이다. AP 의 경우 OKS 에 따라 계산된다.

Training
- 사람을 검출하는 바운딩 박스의 크기를 고정된 4:3 비율로 지정 후 자름
- 자른 이미지를 256x192 또는 384x288 크기로 고정
- Data augmentation
- random rotation -45 ~ 45
- random scale 0.65 ~ 1.35
- Adam optimizer
- Starts with
- at 170th
- at 200th
Terminate trainging at 210 epochs

.png)