
[Abstract]
단일 데이터로 스타일을 입힌 모델은 스타일의 자세한 특징을 담기 어렵다는 것이 문제다. 예로 들어 눈의 모양, 얼굴형 등이 있다. 그래서 이 논문은 이것들을 보완하기 위해 pre-trained stylegan 으로 특정 이미지의 style w 와 GT 이미지와 비교해서 fine-tune 하는 방식을 채택했다.
[Methodology]


- GAN inversion 모델을 통해 나온 style 생성
- Style 와 연관이 있는 를 만들기 위해 random style mixing 을 사용해서 생성
- 와 를 데이터셋으로 구성으로 StyleGAN finetune 진행
[Style Mixing]
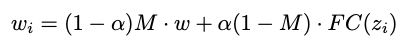
- 위의 이미지는 조정하는 랜덤 스타일 믹싱 equation 이다.
- 는 scalar value 이고 는 랜덤 노이즈다.
- 은 style mixing 할 레이어다.
- 데이터 경우 style mixing layers 7 to 18 번째를 조정해서 포즈, 머리 스타일, 눈의 모양의 정보를 보존했다.
- 데이터 경우 style mixing layers 7 to 9 번째를 조정해서 스타일의 색감 정보를 보존했다.

Color preserving C 데이터와 데이터 구성에 따라 다른 결과 값 생성
[Finetune]
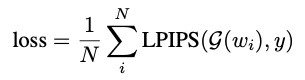
Finetune 은 위에서 생성한 데이터셋과 percetual loss "LPIPS" 손실함수를 사용해서 한다.
[Experiments]
- Pretrained model: StyleGAN
- Total itertations: 500
- Learning rates: 0.0002
- Datasets: GT & or
[Results]

.png)
Deep Learning Research Engineer