
[Abstract]
모델 기반 최적화 방법론과 차별화 학습 방법론이 low-level vision의 문제를 푸는데 대부분 사용된다. 특히 2가지의 방법론은 장점과 단점이 분명하게 존재하는데, 모델 기반 최적화 방법론은 학습 기반 방법과 달리 훈련에 필요한 데이터셋이 필요하지 않고, 여러 종류의 이미지 디블러링에 유연하게 쓰일 수 있다는 장점이 있다. 하지만 학습 기반 방법에 비해 결과 이미지를 얻기 위한 처리 속도가 느리고, 좋은 성능을 내기 위해 다양하고 복잡한 이미지를 사용해야 한다는 단점이 존재한다. 반면에 학습 기반 방법은 복잡한 이미지를 필요로 하지 않고, 결과 이미지를 빠르게 취득할 수 있는 대신 대량의 학습 데이터를 필요로 한다는 단점이 있다. 이 논문은 두 가지의 방법론을 통합한 모델을 만들고자 이 연구를 시작했다.
[Introduction]
이미지 복원은 오래전부터 low-level vision에서 많이 다뤄왔던 문제다. 일반적으로 이미지 복원은 손상된 이미지를 깨끗한 이미지로 복원하는 작업이다. 손상된 이미지 같은 경우 대부분 노이지와 흐릿함이 포함 된 이미지로 설명이 된다. 손상된 이미지를 복원하기 위해 model optimized 방법론과 discriminative learning 방법론을 사용 할 수 있다. Model optimized 방법론은 시간은 좀 걸리지만 반복적인 추론을 통해 최적의 알고리즘을 찾아 문제를 푼다. 게다가 Model optimized는 넓은 범위의 이미지 복원 문제를 해결할 수 있다. 반대로 discriminative learning 방법론은 지도학습을 통해 파라미터를 학습 시키고 추론을 하여 문제를 빠르게 해결하지만 특정 이미지 복원 문제 밖에 해결하지 못한다. 예를 들어 denoise, deblur, super-resolution 폭 넓은 문제를 다루는 Model optimized 방법론의 모델은 NCSR이 있다. 그리고 이 3가지 문제를 각 해결하는 discriminative learning 방법론 모델의 MLP, DCNN, SRCNN 모델들이 있다. 이미지 복원 모델을 2가지의 방법론을 하나로 통합해 만드는 것이 이 논문의 핵심이다. Half quadratic splitting (HQS) 방법론을 통해 fidelity term과 regularization term을 분리한다. HQS를 통해 Regularization term을 오직 denoising만 다룰 수 있게 분리할 수 있어 여럿 discriminative desnoiser들을 model-based optimization 방법론에 통합할 수 있게 되었다.
[IRCNN]
IRCNN은 HQS를 사용하여 분리하고, 복잡한 다른 이미지 prior 대신 깊은 합성곱 신경망 잡음 제거기 (Denoiser)에 기반한 데이터로부터 학습된 이미지 prior를 사용해서 효과적으로 이미지를 복원하는 모델이다.
[Model optimized structure]
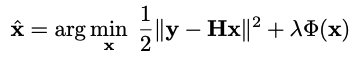
[Discriminative learning Structure]
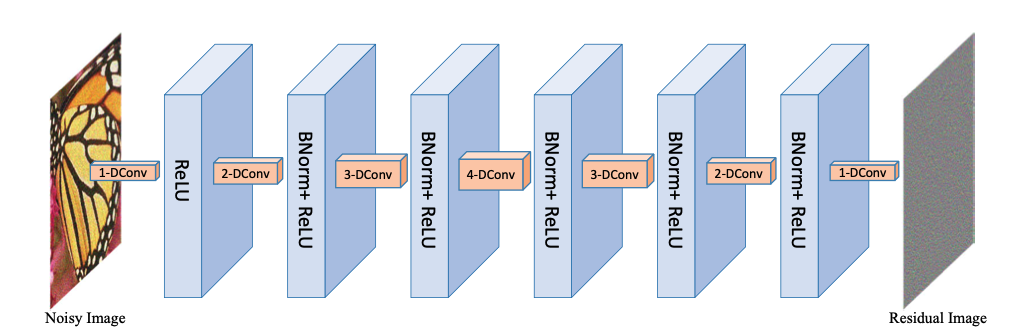
위의 모델 구조는 CNN Denoiser에 사용 된 구조다. 이 모델은 총 7개의 레이어와 3개의 다른 블럭들로 구성되어 있다.
Type of Blocks
- 첫 번째 계층의 "Dilated Convolution + ReLU" 블록
- 중간 계층에 있는 5개의 "Dilated Convolution + Batch Normalization + ReLU" 블록
- 마지막 레이어의 "Dilated Convolution" 블록
Dilated Convolution
Context information을 추출하는 것이 이미지 복원에 가장 근복적인 일이다. 일반적으로 CNN을 이용해서 많은 Context information을 원할 때 CNN의 필터 사이즈를 올린다. 물론 필터 사이즈의 증가로 많은 context information을 추출할 수 있지만 동시에 컴퓨터 연산량도 같이 증가시킨다. 연샨량을 줄이면서 깊은 모델과 비슷한 결과를 만들기 위해 Dilated convolution을 사용하게 된다. 그 결과로 dilated convolution을 사용한 위의 모델은 3x3 convolution filter를 사용한 7개의 CNN 레이어보다 PSNR이 높고 16개의 CNN 레이어를 포함하는 모델의 성능과 비슷하다.
Batch Normalization + Residual Learning
Batch Normalization과 residual learning을 함께 쓰이는 조합은 안정적이고 빠른 학습을 돕는 것을 동시에 denoising 성능을 올려준다.
Small size training samples
Denoise를 위해 사용된 CNN 레이어에서 boundary artifacts가 많이 생기는데 small size training samples을 사용해 방지 할 수 있다.
Denoiser model with small interval noise levels
노이즈 레벨의 범위를 0부터 50까지 설정하고 denoise 모델을 학습을 한다. Epoch마다 노이즈 레벨을 0에서 2씩 증가시켜 총 25개의 다른 노이즈 레벨을 모델에 학습한다. 그 결과로 denoise 모델이 대부분의 노이즈 레벨 영역을 학습하고 처리할 수 있다.
[Model optimized + Discriminative learning]
제안 된 모델은 CNN 모델과 함께 HQS 방법을 사용하여 반복 최적화를 수행한다.
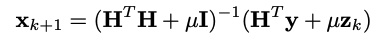
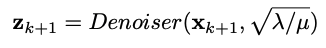
수식 설명
- H는 degradation 행렬이고 블러 링 연산자
- z는 보조 변수
- x는 노이즈가 제거 된 이미지
- 는 잡음 수준 (를 상수로 설정 하면 를 찾을 수 있다.)
- Denoiser는 잡음 제거 CNN 모델
반복적으로 다른 수준의 노이즈 레벨( )의 input을 denoiser에 통과 시켜 새로운 z를 생성하여 x의 새로운 값을 얻는다.
[Results]


.png)