
[Abstract]
End-to-end 학습 기반 single image super-resolution (SISR) 방법이 기존에 모델 기반 방법론 보다 효과적이고 효율적이다. 하지만 모델 기반 SISR 방법론은 다른 scale factors, blur kernels 그리고 noise levels 문제들을 maximum a posteriori (MAP)를 통해 유연하게 풀어 나갈 수 있지만 학습 기반 방법론은 모델 기반처럼 유연하지 못한게 단점이다. 이러한 이슈들을 해결하기 위해 이 논문은 새로운 모델기반과 학습기반을 합친 end-to-end trainable unfolding network를 제안한다.
[Introduction]
Single image super-resolution (SISR)은 low-resoltuion (LR) 저해상도 이미지를 선명하고 자연스러운 디테일을 살려 high-resolution (HR)으로 복원하는 과정이다
SISR은 low-level computer vision에서 classical ill-posed inverse problems 이다. 게다가 SISR은 현실에서 여러분야에서도 적용할 수 있는 기술이다. 예로 저해상도 이미지의 품질을 high-definition display에서도 선명하게 보일 수 있도록 복원하고 high-level vision tasks의 성능향상에도 도움을 준다.
SISR의 연구는 수십년간 진행되어 왔지만 아직 학술 그리고 산업 목적으로 사용되기 위해서는 더 많은 연구가 진행이 되어야한다. 이유는 아직도 실생활에 있는 훼손된 이미지와 SISR에서 단순한 기법을 통해 의도적으로 훼손한 이미지의 특징은 다르기 때문이다.
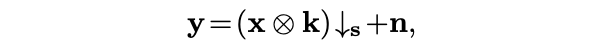
- Degradation Equation
는 scale-factor of degradation
는 고해상도 이미지
는 blur kernel
는 고해상도 이미지 에 blurred, decimated, 그리고 noisy version 추가 된 이미지
는 white Gaussian noise (AWGN)
는 noise level
위의 식은 HR 이미지를 훼손(degradation)해서 LR 이미지를 생성 할 수 있는 식이다. 또한 위의 식은 MAP 프레임워크에 따라 data term과 prior term 조합을 해결하는 모델 기반 방법에서 광범위하게 연구되어 왔다.
많은 연구자들은 편안함을 위해 blur kernel 그리고 noise level을 고려하지 않고 bicubic을 이용한 downsampled LR을 통해 HR 이미지를 계산했다. 물론 bicubic으로 LR과 HR 매핑 기반으로 학습한 convolutional neural network (CNN) 기반 모델에서는 PSRN과 perceptual 부분에서 굉장한 성과가 있었다. 하지만 단순히 bicubic으로 매핑한 CNN 기반 SR은 blurry하고 noisy 이미지에 대해서는 유연하게 대처할 수 없었다.
이 논문은 모델 기반과 학습 기반의 장점들을 모아 USRNet을 제안한다. 모델 기반과 비슷하게 USRNet은 한 개의 모델로 여러가지 다른 scale factors, blur kernels, noise levels 문제들을 효과적으로 해결 할 수 있다. 게다가 학습 기반 모델과 비슷하게 end-to-end 학습을 지향해서 효과성과 효율성을 보장한다.
Deep unfolding 방법론은 기존에 학습 방법론과 다르게 열화 제약조건을 학습 기반 모델에도 적용할 수 있다는 것이다. 하지만 이전의 deep unfolding 기반의 모델들은 단점을 가지고 있었다. 첫번째 이유는 모델이 CNN 기반이 아니여서 기대만큼 성능이 나오지 않았다. 두번째 이유는 data subproblem을 풀수가 없었다. 세번째 이유는 end-to-end manner가 아닌 stage-wise 또는 fine-tuning manner로 학습이 진행되어 왔었다. 이 논문은 새로운 모델을 위의 3가지 단점들을 보완해서 제안된다.
[Structure]
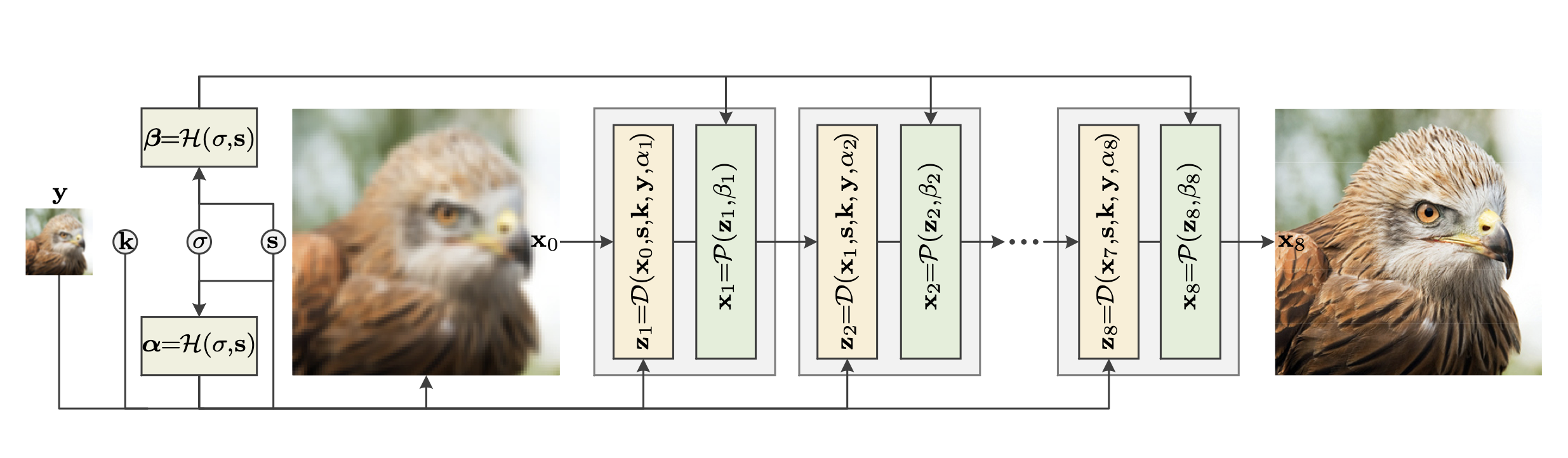
Data module
=
- 데이터 모듈은 모델기반 최적화 방법론으로 다양한 blur kernel, scale factor 통해 깨끗한 이미지를 생성한다. 위의 방정식은 PyTorch에 FFT와 inverse FFT 연산자를 사용해서 모델에 추가했다.
Prior module
- prior 모듈은 학습기반 방법론으로 깨끗한 이미지 는 는 노이즈 레벨 과 denoiser에 통과시켜 얻을 수 있다. 이 논문에서 제안한 denoiser는 Residual blocks을 U-Net에 적용한 ResUNet이다. ResUNet은 와 노이즈 레벨 맵을 하나로 뭉쳐 input으로 사용된다. 그리고 output은 denoise가 적용된 이미지 이다. 그렇기 때문에 ResUNet은 한 가지 모델을 통해 여러 노이즈 레벨을 처리할 수 있고 결과로 작아진 hyper-parameter 수를 가지게 된다.
Hyper-parameter module
- 하이퍼 파라미터 모듈은 'slide bar' 처럼 data module & prior module의 outputs 데이터를 조절할 수 있다. 예를 들어 는 통해 결정되고 통해 결정된다. 그러므로 하이퍼 파라미터를 조절해 다른 output을 얻을 수 있다.
[Contributions]
- USRNet은 처음으로 end-to-end 학습 모델로 classical degradtion 문제들을 해결
- USRNet은 모델 기반의 유연함과 학습 기반의 장점들을 섞은 모델
- USRNet은 LR 이미지가 가지는 여러가지(scale-factors, blur kernels, noise levels) 열화에 대해서도 좋은 성능을 나타낸다.
.png)