
[Abstract]
이 논문은 최초로 딥 러닝을 이용한 새로운 super-resolution(초해상화) 기술을 제안한다. SR은 저해상도 이미지에서 고해상도 이미지를 복원하는 기술이다. 이 대단한 기술에도 고질적인 문제가 있는데, 하나의 입력에 대해 복수의 결과물이 나올 수 있는 해결하기 어려운 문제가 있다.
SRCNN은 Deep convolutional neural network (CNN)으로 구성되어 있으며, 저해상도 이미지와 고해상도 이미지가 한 쌍으로 이루어져 지도학습을 하는 딥러닝기반 인공지능이다. 기존에 있던 방법과는 다르게 각 CNN층을 별도로 관리하고 최적화한다.
SRCNN은 가벼운 구조를 가지고 있었지만 논문발표 당시 품질과 성능은 최고였다.
[Structure]
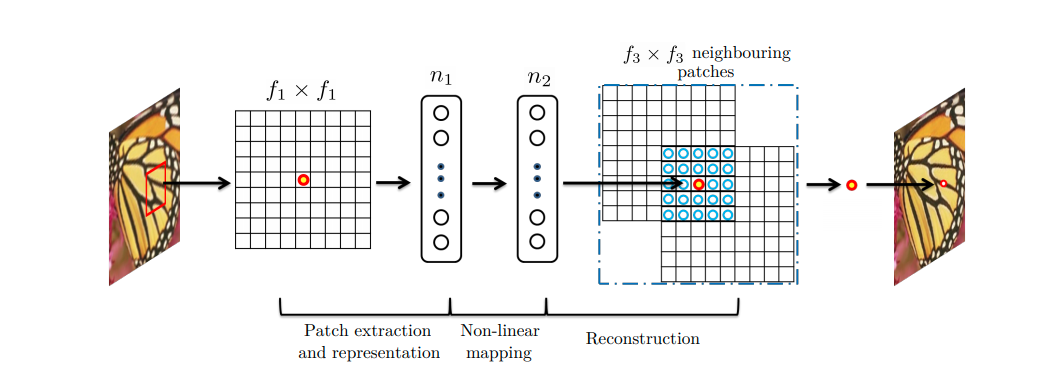
위의 그림은 SRCNN의 전체적인 구조이다. Sparse-coding-based 방식과 다르게, SRCNN은 non-linear operation을 이용하여 patch extration과 representation 과정을 학습하여 최적화가 된다. External example based 방식에 비해 더 많은 정보가 reconstruct되어 더 좋은 퀄리티의 고해상도 이미지로 복원할 수 있다.
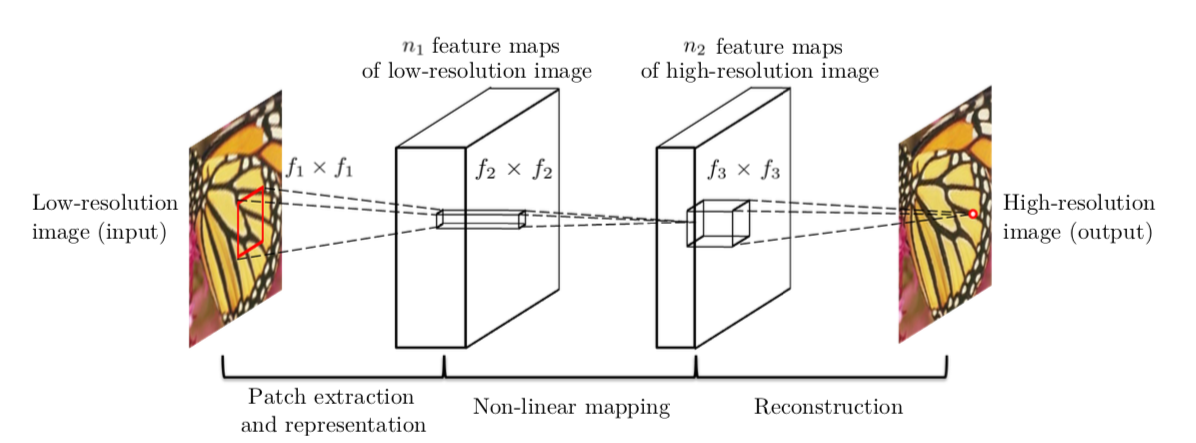
SRCNN의 자세한 구조는 아래와 같다.
- 이미지의 특징을 CNN을 통해 patch들로 추출한다.
- 추출된 다 차원의 patch들을 non-linear하게 1x1 filter 사이즈를 가지고 있는 CNN층에 다른 다차원의 patch들로 매핑한다.
- 다차원의 patch들을 이용하여 고해상도 이미지로 복원시킨다.
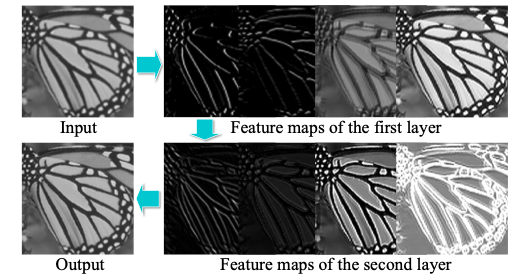
[Filter number]
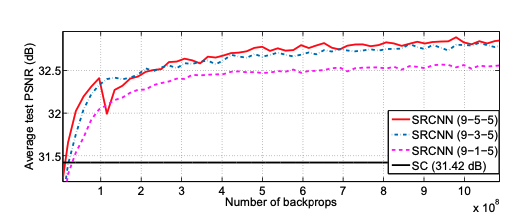
이 논문은 필터의 수가 많아지면 많아질 수록 추출하는 이미지의 특징이 많아지기 때문에 PSNR이 높아진다고 말하지만 그만큼 추론 시간도 증가한다고 주장한다.

[Filter size]
필터의 수가 output 이미지의 영향을 주듯이 필터 사이즈도 영향을 인공지능 모델에 아주 민감한 영향을 준다고 한다. 여기서 필터의 사이즈는 즉 convolution층에서 사용하는 kernel의 사이즈를 말한다.
큰 Filter size는 조금 더 풍부한 이미지의 structural information을 추출할 수 있고 더 나아가 좋은 결과값을 만든다고 한다. 하지만 역시 필터의 사이즈가 커지면 속도 또한 저하가 된다.
[Number of layers]
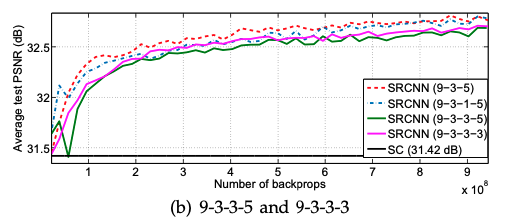
CNN층의 수 역시 super-resolution과 깊은 연관이 있다. Layer의 층을 깊게 쌓게 되면 역시나 더 좋은 output 이미지 결과가 나온다. 하지만 무조건 깊게 쌓는다고 더 좋은 결과값이 꼭 나오는것은 아니라고 이 논문은 주장한다.
[Conclusion]
이 논문은 인공지능을 학습시키고 추론까지 하는 최초의 딥러닝 기반 super-resolution이다. Sparse-coding-based SR 방법이 딥러닝 인공지능으로 변환이 가능하다는 걸 보여줬다. 여러가지의 연구를 통해 filter의 수, filter의 사이즈 그리고 layer의 수를 조정하며 SR에 적합한 인공지능 구조를 선보였다.
[Results]
| Original | BICUBIC x3 | SRCNN x3 |

|

|

|
[Github]
.png)