
[Abstract]
딥러닝 기반 SRCNN 모델이 super-resolution 분야에서 눈에 띄는 속도와 품질 결과를 보여줬었다. 그러나 real-time(24fps)으로 구현하기에는 높은 비용의 연산량 때문에 턱없이 부족했다. 이 논문이 제안하는 FSRCNN모델은 모래시계 모양을 가지고 있으며, SRCNN모델 기반으로 가공하여 real-time에 가까운 성능을 내기 위해 어떤 노력을 했는지 말해준다.
- Deconvolution layer를 모델의 마지막 부분에 넣어줌으로써 따로 interpolation 없이 저해상도 이미지를 고해상도 이미지로 매핑하여 학습이 가능하다.
- SRCNN의 중간 CNN 층인 mapping layers에 통과되기 전에 첫 번째 CNN의 input feature 차원의 수를 줄이고 중간 레이어를 통해 매핑 후 다시 첫번째 CNN의 input feature 차원의 수와 동일하게 늘리는 새로운 방법으로 구현되었다.
- Filter sizes들을 줄여 CPU에서도 빠르고 좋은 성능을 내는 모델을 만들었다.
[Structure]
FSRCNN은 SRCNN을 기반으로 만들어진 모델이다 보니, SRCNN과 비교하며 모델의 전체적인 구조를 보여준다.
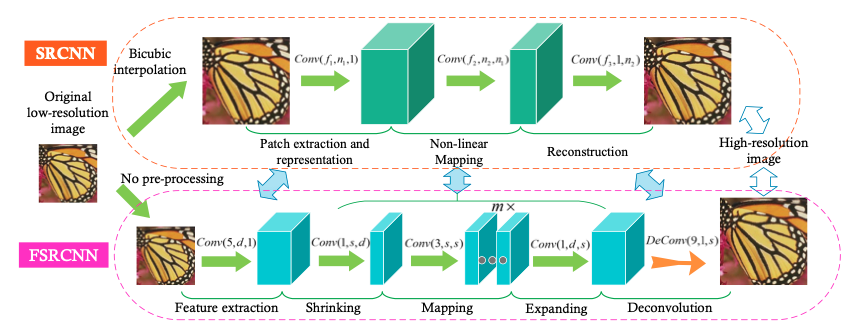
위에 그림을 보면 잘 알겠지만 FSRCNN은 총 다섯가지 부분으로 나누어져있다.
- Feature extraction - 이미지의 특징 추출
- Shrinking - input feature 차원의 수 축소
- Non-linear Mapping - 매핑
- Expanding - input feautre 차원의 수 증가
- Deconvolution - Deconvolution을 이용한 해상도 크기 증가
Feature extraction은 SRCNN과 비슷하지만 FSRCNN의 input은 interpolation을 하지 않고 바로 첫 번째 CNN에 통과된다. 그리고 SRCNN의 첫 번째 CNN의 kernel 사이즈는 9x9였지만 FSRCNN은 5x5로 대체하여 모든 이미지의 특징을 담았다. 그러므로 5x5로 추출된 이미지의 특징이 미세하게 손실되었다.
Shrinking은 매핑 스텝으로 통과되기 전에 lr feature의 차원을 줄여 연산 복잡도를 줄여준다. 주로 feature의 차원을 증가시키거나 축소 시킬때 CNN의 kernel 사이즈를 1x1로 고정하여 연산 복잡도를 줄인다. 이 결과로 많은 파라미터의 수를 줄여 학습 및 추론 시간을 상당히 많이 줄였다.
Non-linear mapping은 SR output 결과에 가장 중요한 부분이다. 특히 CNN층에 필터 수(width)와 CNN층의 수(depth)가 SR 성능에 가장 영향을 미치는 부분이라 할 수 있다. SRCNN은 매핑 층에서 5x5를 사용하여 매핑을 진행했었는데, 모델을 깊게 쌓지 못하는 문제점이 있었다. 하지만 FSRCNN은 kernel의 크기를 3x3으로 축소하고 여러 개의 층으로 겹겹이 쌓음으로써 SRCNN보다 좋은 성능을 보여줬다.
Deconvolution은 FSRCNN의 마지막 부분이고, 실질적으로 이미지 해상도를 키워 HR을 생성하는 부분이다. Deconvolution는 convolution의 반대라고 생각하면 된다. Stride 부분을 조정하여 정수 단위로 해상도의 크기를 조절할 수 있다.
마지막으로는 PReLU activition function을 소개한다. PReLU는 ReLU 비슷한 성격을 가지고 있지만, 실수의 값도 가질 수 있어, zero gradients 때문에 생기는 dead features를 조금 방지할 수 있게 도와준다.
[From SRCNN to FSRCNN]
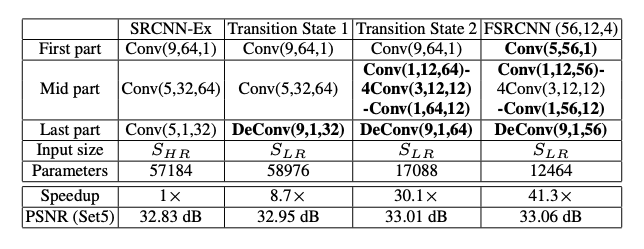
첫 번째로 SRCNN의 마지막 부분을 deconvolution layer로 교체하여 8.7x 추론 시간을 감소시켰다. 그리고 단일 bicubic kernel보다 psnr 0.12dB 값을 증가시켰다.
두번째는 mapping layer가 shrinking layer, 4 mapping layers, expanding layer로 교체되었다. 전체적으로는 5개의 layers가 더 추가되었지만, 오히려 파라미터의 개수는 59,976에서 17,088로 줄어 약 30배 정도 빨라졌다. 여기서 키 포인트는 narrow한 layer가 wide한 layer보다 더 성능이 좋다는걸 증명하고 있다.
마지막으로는 적은 필터 사이즈와 적은 필터 수를 적용하여 불필요한 파라미터를 줄여 약 41.3배 정도 빨라졌고 PSNR은 약 0.05db 향상되었다.
[Conclusion]
이 논문은 빠르고 더 정확하게 복원하는 딥러닝 기반 super-resolution을 위해 연구를 진행하였다. SRCNN의 구조를 전반적으로 재구성하였고 이름은 FSRCNN으로 변경했다. 그 결과로 무려 약 40배 정도 더 빠른 결과를 만들어 real-time super-resolution에 한 걸음 더 가까워졌다.
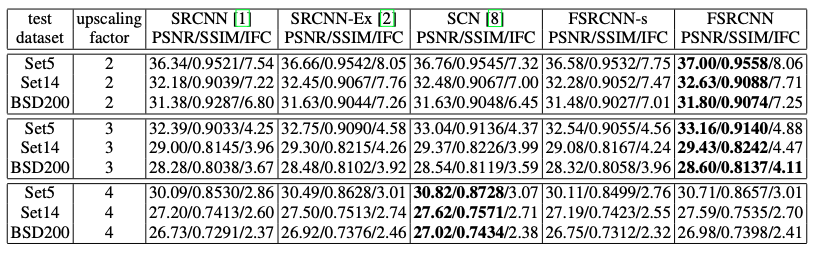
[Results]

[Github]
.png)