
[Abstract]
최근 연구들에 따르면 deep convolutional neural networks를 이용한 super-resolution의 성능이 향상했다. 이 논문은 dense skip connection이 사용된 SRDenseNet 모델을 소개한다. 제안된 이 모델은 각 층의 feature maps를 더해주는 방식이 아닌 concatenate로 연결해 효과적으로 low-level features와 high-level features 정보를 조합해 저해상도 이미지를 고해상도 이미지로 복원한다. 학습시 깊은 모델에서 주로 나타나는 vanising-gradient 문제를 dense skip connection을 추가해서 해결한다. Bottleneck layers를 사용해 파라미터의 수를 줄여주고 해상도의 크기를 늘려주는 Deconvolution layers을 통해 upsampling filters를 학습한다.
[Introduction]
저해상도 이미지와 고해상도 이미지를 매핑하여 고해상도 이미지로 생성하는 것은 매번 여러 가지의 다른 이미지가 생성될 수 있기 때문에 이것을 ill-posed한 문제라고 한다. 특히 upscaling factor가 클수록, 이미지가 가지고 있는 high-frequency 디테일을 복원하는 게 힘들다. 그러므로 저해상도 이미지가 가지고 있는 contextual information을 잘 추출하는 것이 매우 중요하다.
최근 연구에 따르면 모델이 깊으면 깊을수록 더 많은 contextual information을 저해상도 이미지로부터 추출해서 고해상도 이미지를 예측해서 생성할 수 있다. 그러나 이러한 깊은 모델을 vanishing-gradient를 피해 효과적으로 학습시키는 것은 매우 어렵다. 물론 skip connection을 이용해 top layers와 bottom layers를 연결하여 어느 정도 Vanishing-gradient를 피할 수 있다. 그리고 skip connection을 사용하면 전체 layers가 연결되기 때문에 top layers에 있는 high-level features들뿐만 아니라 low levels에 있는 low features 정보를 추가하여 더 디테일한 고해상도 이미지를 만들 수도 있다. 또한, feature map을 재사용해서 feature redundancy를 효과적으로 줄여 쓸모없는 feature에 대해 재학습을 피할 수도 있다. 추가로 마지막에 upsample을 추가하는 것보다 reconstruct layer 전에 bottleneck layers를 이용해서 features의 수를 줄이고 upscale filters까지 학습하는 것이 속도와 품질 측면에서 더 좋다고 한다.
[Structure]
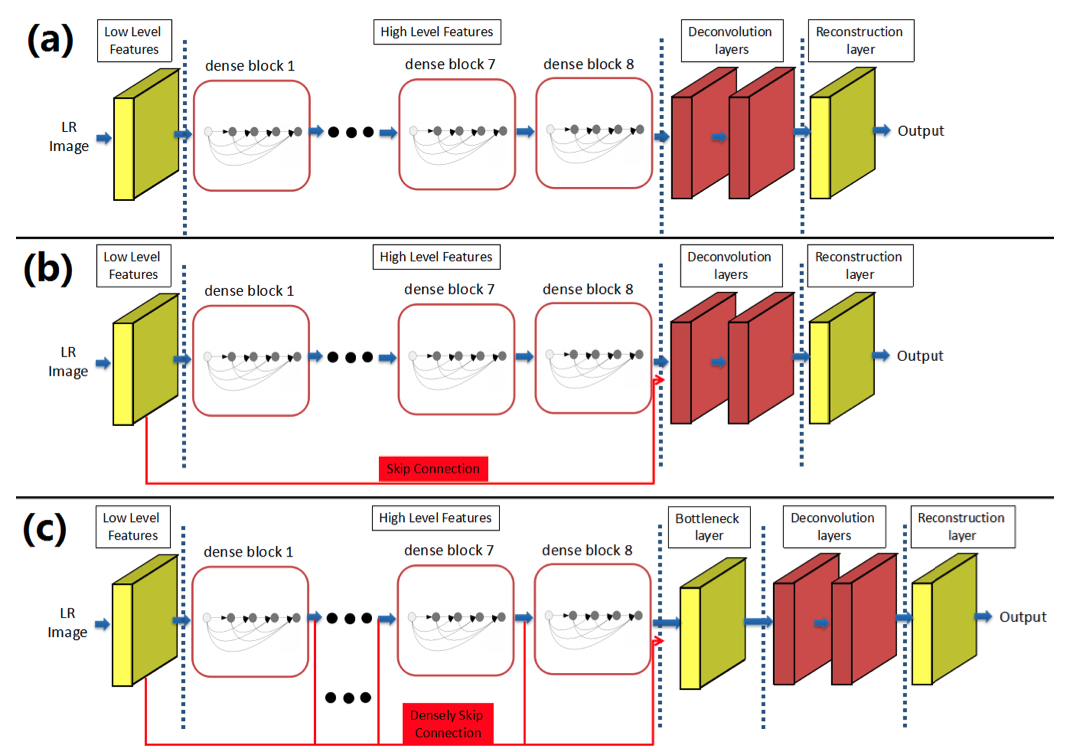
a) High-level feature maps만 사용된 모델
b) Low-level and high-level features를 조합한 모델
c) 모든 레이어가 skip-connections로 연결된 모델
SRDenseNet은 아래의 단계로 나누어질 수 있다.
- convolution layers로 low-level features 학습
- blocks of Dense Net으로 high-level features 학습
- deconvolution layers로 upscaling filters 학습
- reconstruction layers로 고해상도 이미지 생성
- 모든 layers는 ReLu 활성화 함수로 nonlinear 하게 매핑
[Skip connections]
CNNs 모델이 깊어짐에 따라 학습 시 vanishing gradient 또한 심해진다. 많은 최근 논문들이 이 문제점을 지적했다. 그로 인해 bypassing(우회) path를 이용하는 ResNet & Highway 모델들이 등장해서 어느 정도 이 문제점을 해결했었다. DenseNets은 모든 layers를 skip connection으로 연결해서 vanishing-gradient 문제를 보완하고 동시에 feature propagation을 강화한다.
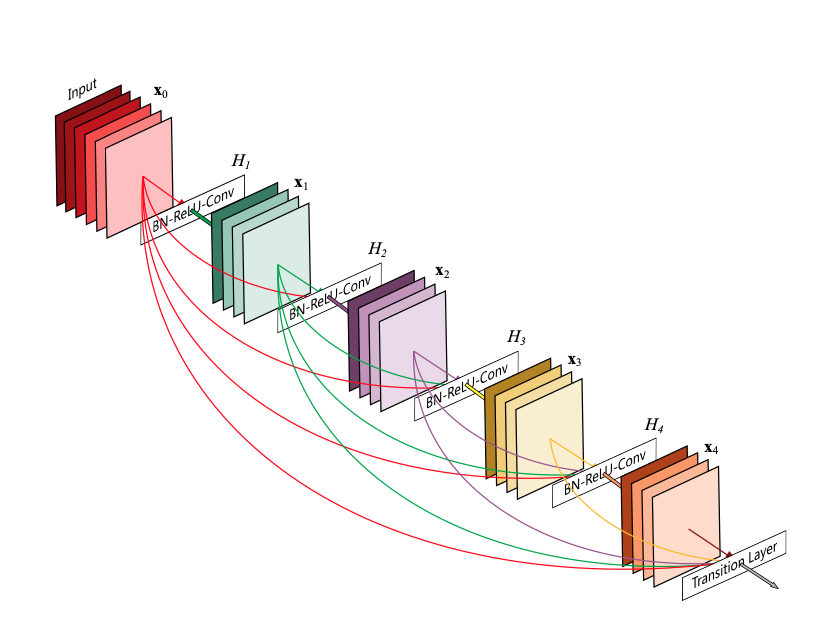
[DenseNet blocks]
DenseNet blocks은 high-level features를 학습하기 위해 사용된다. 단순히 ResNet처럼 feature maps들을 더하는 것이 아니라 concatenate로 겹겹이 쌓아 layers 사이에 작은 길목을 열어 flow of information을 강화하고 vanishing-gradient 문제까지 보완한다. 추가로 feature map을 재사용 함으로써 파라미터 수를 줄인다. 그 결과로 작아진 연산량과 메모리 사용량의 이점까지 얻는다.
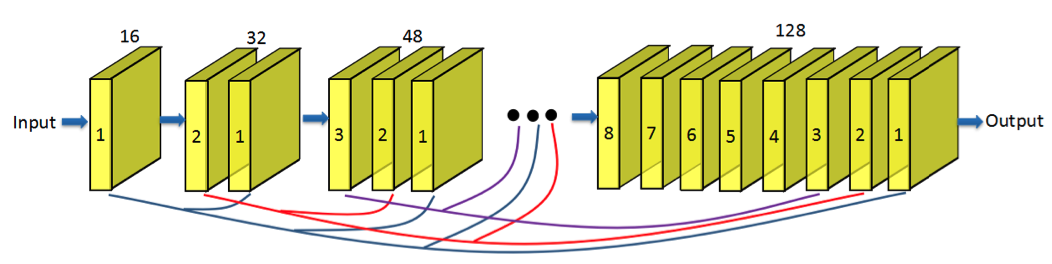
위의 그림은 DenseNet block의 내부 구조를 표현한다. 기본적으로 한 블록 안에 8개의 convolution layers가 들어가 있다. 각 convolution layer가 k개의 feature map을 생성한다고 가정을 하면 전체적으로는 k*8개의 feature map이 한 개의 블록 내에 생성된다. 여기서 k는 growth rate라고 불리고 새로운 정보가 고해상도 이미지를 만들 때 각 layer에 얼마나 영향을 미치는지 조절하는 역할이다.
[Deconvolution layers]
초창기 SR 모델인 SRCNN 그리고 VDSR은 bicubic 보간기법으로 먼저 upscale을 사용해 저해상도 이미지를 고해상도로 만들었었다. HR space에서 모든 convolution layer가 연산이 되기 때문에 연산량이 증가해서 추론속도를 저하했었다. 그러므로 최근 연구에서는 최대한 많은 연산을 LR space에서 진행을 하고 deconvolution layers을 이용해서 고해상도 이미지를 만든다. 또 upscaling filters까지 학습해서 이미지의 특징을 더 정확히 구현했다. 정확하게는 upscaling의 kernels을 학습을 시켜 고해상도의 이미지를 예측해서 생성할 수 있게 했다.
Upscaling 할 때 Deconlution layer를 사용해서 생기는 장점 두 가지가 있다.
- 거의 모든 연산 처리는 LR space에서 진행되기 때문에 SR reconstruct process를 가속화 한다.
- 저해상도 이미지가 가지고 있는 대량의 contextual information을 사용해서 high frequency detail을 추론 할 수 있다.
[Bottleneck and Reconstruction layers]
SRDenseNet은 concatenate를 이용해서 수많은 feature maps를 연결한다. 그 결과로, feature maps의 수는 많이 증가한다. 이렇게 증가된 feature maps를 deconvolution layers 통과시키게되면 연산 비용과 모델 사이즈가 증가한다. 그러므로 feature maps의 수를 줄여주는 것이 매우 중요하다. 전에 많은 연구에서 증명되었듯이 1*1 convolution layer가 input의 feature maps 수를 줄이기 위해 사용되는 것을 알 수 있었다. 그리고 이것을 bottleneck layer라고 부른다. 이 논문은 모델을 가볍고 효과적으로 연산을 하기 위해 bottleneck layer를 deconvolution layer에 전에 추가하여 feature maps의 수를 줄이고 고해상도 이미지를 생성했다.
[Training Details]
- 50,000 datasets
- 100*100 cropped image from HR image and downsample the cropped image using bicubic
- Scale factor: 4
- Only Y channel is used from YCBCR
- 8 DenseNet blocks were used
- 16 growth rate was set
- Kernel(filter) 3*3 size was used in all layers
- Relu activation function was used
- Adam optimizer was used
- Learning rate: 0.00001 and decreased by a factor of 10 after 30 epoches
- Mini batch size: 32
- MSE loss function was used
[Results]


[Conclusion]
이 논문은 concatenate를 사용해 모든 layers에 skip connections를 적용한 새로운 SRDenseNet 모델을 제안했다. 효과적으로 high & low level feature를 학습하기 위해 layers마다 skip connections를 연결했고 보다 정확한 HR space를 만들기 위해 deconvolution layers도 학습을 시켜 고해상도 이미지를 생성했다.
[Github]
.png)