
[Abstract]
최근 초해상화 관련 논문은 deep convolutional neural networks (DCNN)을 이용한 모델들이 많았다. 특히, residual learning 기술들이 초해상화 성능 향상에 크게 기여했다. 이 논문이 발표하는 enhanced deep super-resolution network (EDSR)는 논문을 발표한 시점의 다른 state-of-the-art 초해상화 기법보다 월등히 높은 성능을 낸다. 다른 모델보다 EDSR이 더 좋은 성능을 낼 수 있었던 중요한 원인은 ResNet에 필요 없는 모듈을 삭제하고 깊은 모델을 안정적으로 학습할 수 있었기 때문이었다. 이 논문에서 제안한 EDSR 모델은 이 당시 최고의 SR 모델들보다 뛰어난 benchmark 성능을 보여줬고 NTIRE2017Super-Resolution Challenge에서 우승도 했다.
[Structure]
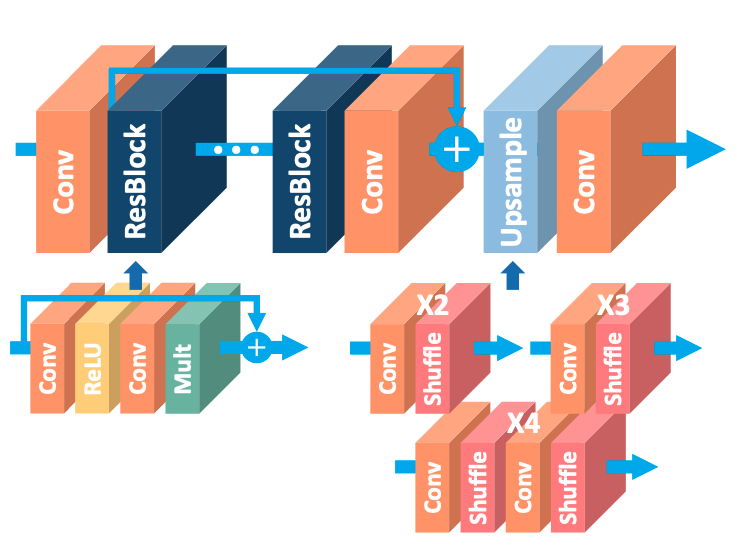
EDSR은 SRResNet의 architecture와 크게 다르지 않은 모델이다. SRResNet에서 사용된 ResNet은 Higher-level 비전, image classification과 detection 사용되었고 low-level 비전, SR에도 효율적으로 적용할 수 있을 것 같아서 EDSR에 적용했다. 간략하게 ResNet을 설명하자면, ResNet은 더 깊게 모델을 만들 수 있게 공헌한 기법이다. 특히 skip-connection과 재귀 convolution을 이용하여 SR에 불필요한 identity information을 줄여 모델이 빠르고 안정적으로 수렴할 수 있도록 도왔다.
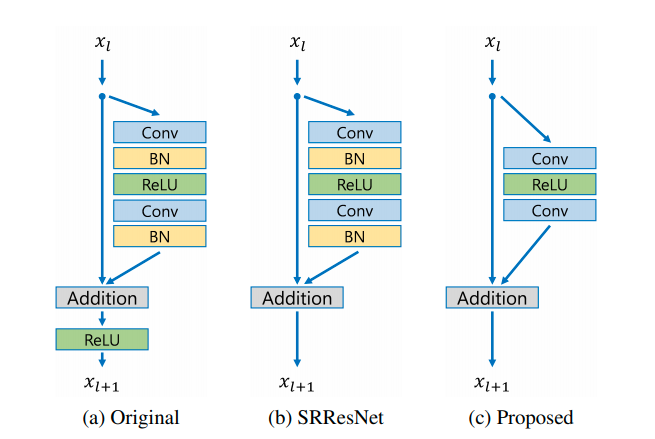
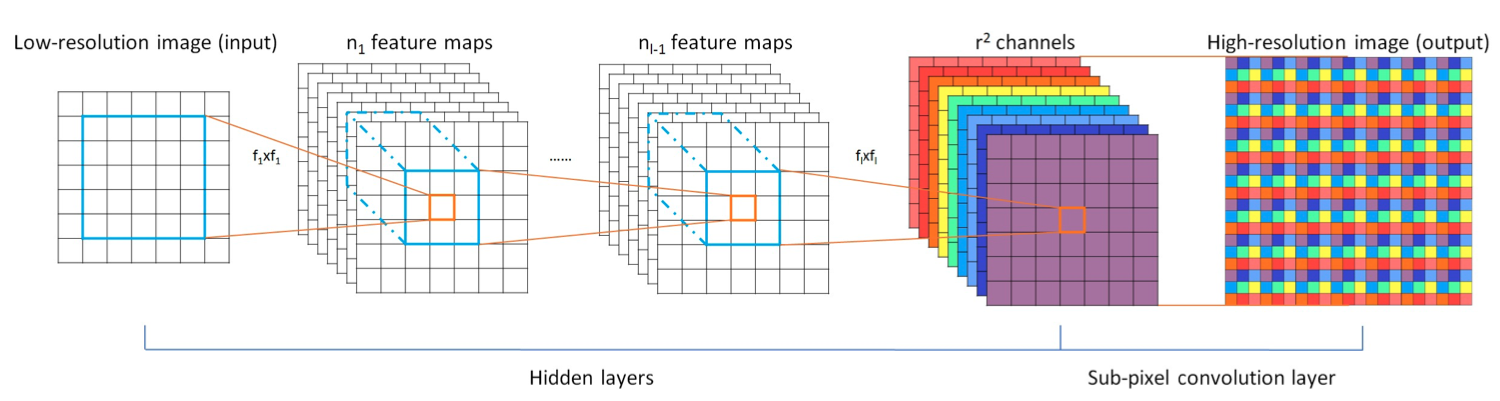
위의 그림 (C) Proposed를 보면 SRResNet에서 불필요한 Batch Normalize (BN) 을 제거하여 EDSR에 적용했다. BN을 제거한 이유는 BN이 소모하는 GPU 메모리 사용량이 보통 한 개의 CNN layer와 비슷하기 때문이다. 이후 BN을 제거하고 남은 GPU 메모리에 더 많은 CNN을 쌓아 더 깊은 모델을 만들었다. 그 후 ESPCN에서 사용한 pixel-shuffle으로 LR 이미지의 해상도 크기를 늘려 HR 이미지를 생성한다.
일반적으로 모델의 parameter의 수를 증가시키는 것이 모델의 성능을 올리는 가장 좋은 방법의 하나다. 예를 들어 CNN layer의 수를 증가시키거나 filter의 수를 증가시키는 것이 보편적이다. 하지만 무작정 증가 시켜 학습을 하면 모델의 학습은 매우 불안정해진다. 그래서 이 논문은 깊은 모델에 residual-scale을 적용하여 불안정한 학습을 안정화해준다.
[Training Details]
EDSR은 DIV2K 800개의 트레이닝 데이터셋과 100개의 테스트셋을 사용하여 학습했다. 학습 LR 이미지는 48*48 RGB 패치로 다양한 Augmentation(random horizontal flips과 90 rotations)을 추가하여 학습을 진행했다. Optimizer로 ADAM을 사용하였고 정해진 순서에 따라 learning rate를 변경하여 학습했다. 또한 MSE 또는 L2Loss 손실함수를 대신 L1Loss를 사용하여 모델이 잘 수렴할 수 있게 도왔다.
[Conclusion]
이 논문은 enahnced-super-reolution 알고리즘을 제안한다. SRResNet에서 필요 없는 모듈들을 삭제함으로써, 향상된 결과를 모델 경량화와 함께 얻을 수 있었다. 또한 residual scale을 적용하여 깊은 모델에 안정된 학습을 제공했다.

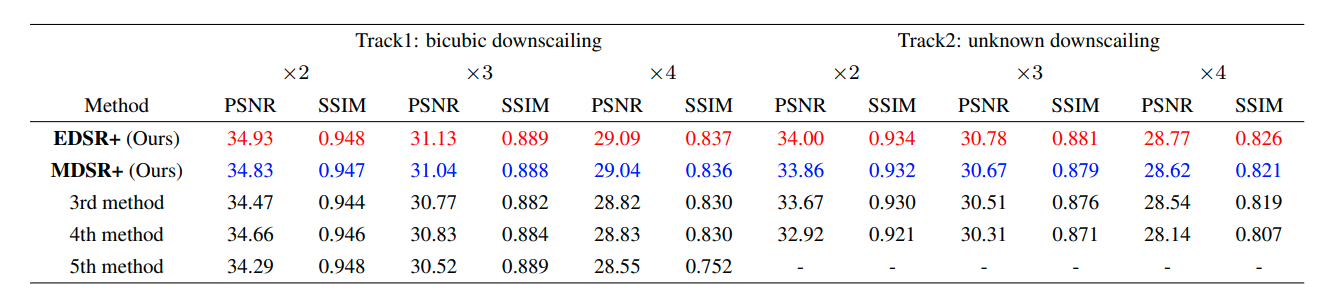
[Github]
.png)