DB index

인덱스(index) 란?
인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상 시키기 위한 자료구조이다.
SELECT *
FROM customer
WHERE first_name = 'JaeHee';CUSTOMER
first_name에 index가 없으면?
특정한 값을 찾기 위해 모든 데이터 페이지를 확인하는 Full Scan(= Table Scan)이 발생한다.
(시간 복잡도 O(N))
TABLE SCAN : 테이블에 읽는 모든 레코드를 순차적으로 읽는 것
Full Scan은 전체를 비교하여 탐색하기 때문에 처리 속도가 떨어진다.
first_name에 index가 있으면?
Full Scan 보다 더 빨리 찾을 수 있다.
시간 복잡도 O(logN) (B-tree based index)
인덱스(index)를 쓰는 이유?
- 조건을 만족하는 튜플(들)을 빠르게 조회하기 위해
- 빠르게 정렬(order by) 하거나 그룹핑 (group by)하기 위해
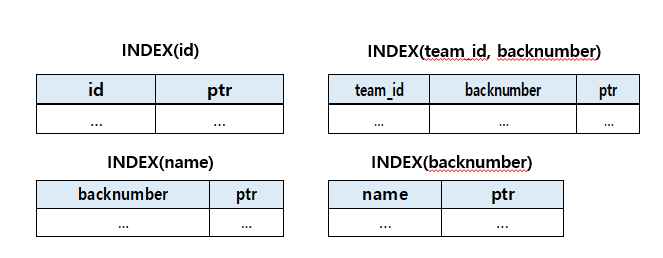
B-tree 기반 index가 동작하는 방식
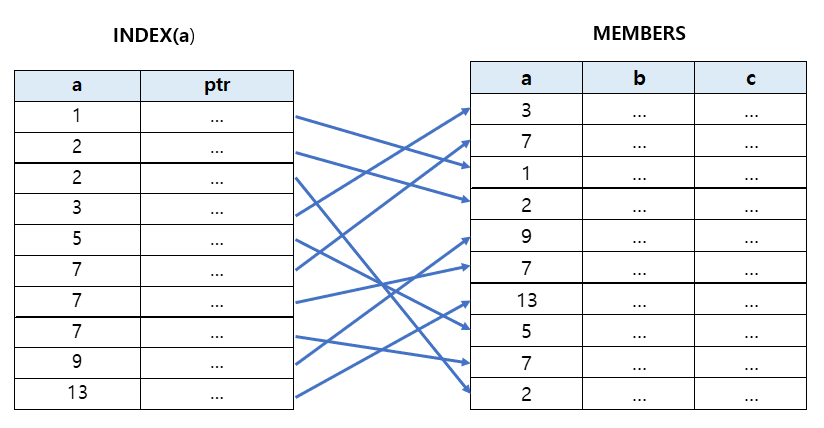
a에 대해 인덱스를 만들게 되면, 인덱스는 a에 대한 값들을 오름차순으로 정렬된 형태로 저장이된다.
ptr(포인터) 는 MEMBERS 테이블에 있는 튜블(연결고리)를 가지고 있는 데이터,
인덱스에 있는 각 데이터들이 실제 어떤 튜플과 연관 되어있는건지 정보를 가지고 있음.
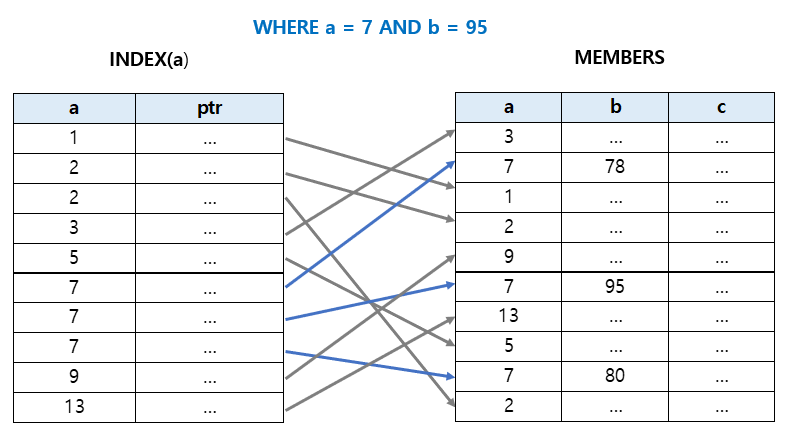
a는 7이고 b는 95인 데이터를 찾을 때 결국 a가 7인 데이터 안에서는 full scan 해야된다.
실제로는 예시보다 더 많은 중복값이 발생할 것이기 때문에 성능적으로 비효율적이다.
CREATE INDEX (a, b)
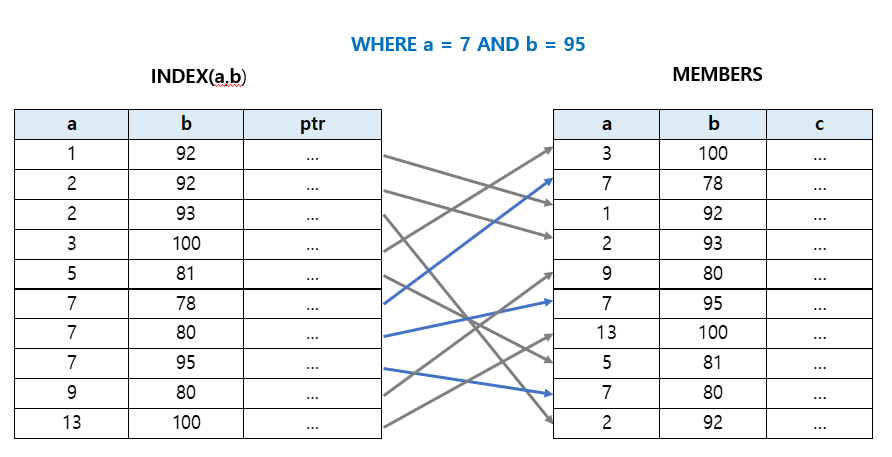
a와 b를 묶어서 인덱스를 생성하게 되면, 왼쪽을 기준으로 우선순위 형성된다.
a를 먼저 기준으로 정렬하고, a의 값이 같다면 b를 기준으로 정렬된다.
그렇기 때문에 멀티 컬럼 인덱스로 만들게 되면 인덱스의 순서가 중요하다!
ex) WHERE B = 95 로 조회할 경우 b가 순서대로 정렬되지 않았기 때문에 Full Scan하는거랑 차이가 없다. 그렇기 때문에 b의 인덱스를 만드는게 낫다.
예제
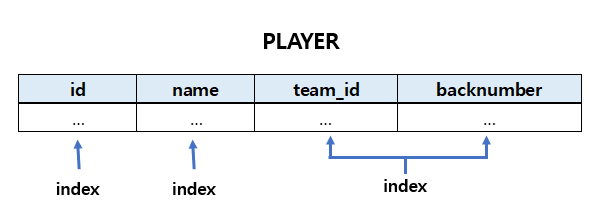
SELECT * FROM player WHERE team_id = 110;
SELECT * FROM player WHERE team_id = 110 AND backnumber = 7;
// 비효율적인 예시
SELECT * FROM player WHRER backnumber = 7;
SELECT * FROM player WHERE team_id = 110 OR backnumber = 7;- backnumnber 인덱스가 없기 때문에 Full Scan 해야함
- OR 조건으로 team_id는 기준대로 정렬후 backnumber가 정렬 되기 때문에 team_id = 110은 빠르게 검색이 되나 backnumber에 대한 조건은 Full Scan 된다.
💡결론
: 사용되는 query에 맞춰서 적절하게 index를 걸어줘야 query가 빠르게 처리 될 수 있다
🔎 그렇다면, 어떤 인덱스를 쓸지 명시하지 않았는데 어떻게 쓰이는걸까?
: optimizer가 알아서 적절하게 index를 선택한다 (explain을 통해 확인 가능하며 직접 인덱스를 지정하여 사용할 수 있다)
```````````옵티마이저 : 가장 효율적인 방법으로 SQL을 수행할 최적의 처리 경로를 생성해주는 DBMS의 핵심 엔진이다.
인덱스는 막 만들어도 괜찮을까?
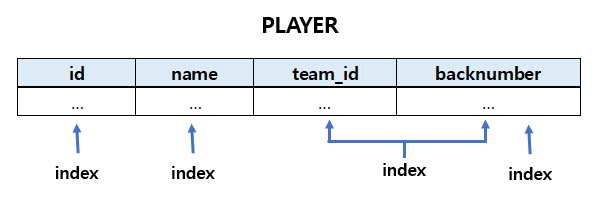
이 데이터의 인덱스를 생성해줄 때 마다 부가적인 데이터도 생성된다.
- table에 write(insert, update, delete) index 변경도 발생 (트리 구조가 변경, 인덱스 테이블, 원본 테이블 이렇게 두 군데의 데이터 수정 작업 등 오버헤드가 발생 될 수 있다)
- 추가적인 저장 공간 차지
인덱스(index)를 사용하면 좋은 경우
- 규모가 작지 않은 테이블
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
**인덱스(Index)의 자료구조**
해시 인덱스 (Hash index)
- hash table을 사용하여 index 구현
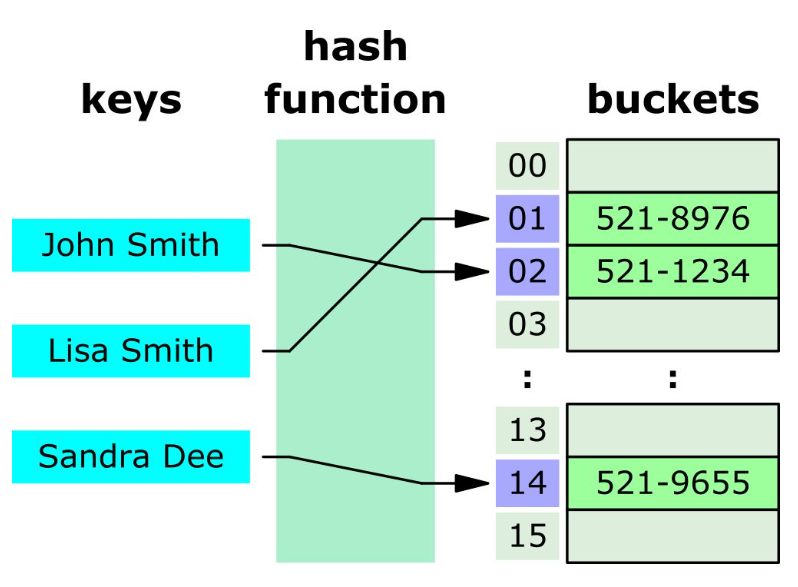
해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠른 데이터 검색이 필요할 때 유용하다. 해시 테이블은 Key값을 이용해 고유한 index를 생성하여 그 index에 저장된 값을 꺼내오는 구조이다.
- 해시 테이블의 시간복잡도는 O(1)이며 매우 빠른 검색을 지원한다.
- 데이터 사이즈가 커지면 사이즈를 늘려줘야하는 rehashing에 대한 부담
- equality 비교만 가능 (==, ≠), range 비교 불가능
- multicolum index의 경우 전체 attributes에 대한 조회만 가능
Full Scan이 더 좋은 경우
- table에 데이터가 조금 있을 때
- 조회하려는 데이터가 테이블의 상당 부분을 차지할 때
참고 자료 : https://www.youtube.com/watch?v=IMDH4iAQ6zM&t=1s&ab_channel=%EC%89%AC%EC%9A%B4%EC%BD%94%EB%93%9C
