Stack, Queue, Heap, Tree
1. 스택(Stack)
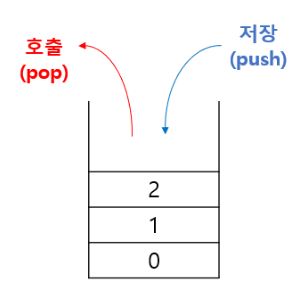
- 데이터를 일시적으로 저장하기 위해 사용되는 자료구조로, 데이터의 삽입과 삭제가 한쪽 끝에서만 일어나는 선형 자료구조 이다.
- 가장 마지막에 삽입된 데이터가 가장 먼저 삭제되는 후입선출(Last-In-First-Out, LIFO) 의 구조를 가지고 있다.
- 스택은 순차적으로 데이터를 추가하고 삭제하기 때문에 ArrayList와 같은 배열기반의 컬렉션 클래스가 적합하다.
1-2 스택 메서드
boolean empty()
: Stack이 비었는지 알려준다
Object peek()
: Stack은 맨 위에 저장된 객체를 반환. pop() 과 달리 Stack 에서 객체를 꺼내지는 않음 (비었을 때는 EmptyStackException 발생)
Object pop()
: Stack의 맨 위에 저장된 객체에를 꺼낸다 (비었을 때는 EmptyStackException 발생)
Object push(Object item)
: Stack에 객체(item)을 저장한다.
int search (Object o)
: Stack에서 주어진 객체(o)를 찾아서 그 위치를 반환, 못찾으면 -을 반환 (배열과 달리 위치는 0이 아닌 1부터 시작)
1-3 스택 활용 예시
- 함수 호출, 괄호 검사, 수식 계산 등에서 사용
- 웹브라우저에 뒤로 / 앞으로, 워드프로세서의 실행취소 (undo) / redo
ex) 괄호 검사
class Ex {
public static void main(String[] args {
Stack st = new Stack();
String expression = "((3+5*8))";
try {
for (int i = 0; i <expression.length(); i++) {
char ch = expression.charAt(i);
if (ch -- '(') {
st.push(ch + "");
} else if (ch == ')') {
st.pop();
}
}
if(st.isEmpty()) {
System.out.println("괄호가 일치합니다.");
} else {
System.out.println("괄호가 일치하지 않습니다.");
} catch (EmptyStackException e) {
System.out.println("괄호가 일치하지 않습니다.");
}
}
}
}2. 큐(Queue)

- 먼저 들어온게 먼저 나가는 선입선출(FIFO, First In FirstOut) 방식의 자료구조이다.
- 큐는 데이터를 꺼낼 때 항상 첫 번째에 저장된 데이터를 삭제하므로 ArrayList와 같은 배열기반 클래스를 사용하게 된다면,
데이터를 거낼 때마다 빈 공간을 채우기 위해 데이터의 복사가 발생해 비효율적이다.
그렇기 때문에 큐는 데이터의 추가/삭제가 쉬운 LinkedList로 구현하는 것이 더 적합하다.
2-1 큐의 메서드
- Queue는 Interface라서 객체 생성이 안된다.
그래서 Quere를 직접 구현하거나, Quere를 구현한 클래스를 사용하면 된다. - Java API에서 Queue Interface를 구현한 class의 목록을 찾아서 사용
해야 함.
boolen add(Object o)
: 지정된 객체를 Queue에 추가한다. 성공하면 true를 반환. (저장 공간이 부족하면 IllegalStateException 발생)
Object remove()
: Queue에서 객체를 꺼내 반환. (비어 있으면 NoSuchElementException 발생, 예외가 발생 하므로 try~catch로 처리 해야 한다.)
Object element()
: 삭제 없이 요소를 읽어온다. peek와 달리 Queue가 비었을 때 NoSuchElementException 발생.
boolean offer(Object o)
: Queue에 객체를 저장. 성공하면 true, 실패하면 false를 반환.
Object poll()
: Queue에서 객체를 꺼내서 반환. 비어있으면 null을 반환. if(obj == null)로 처리를 해야 한다.
Object peek() *
: 삭제 없이 요소를 읽어온다. Queue가 비어있으면 null을 반환.
2-2 PriorityQueue(우선순위 큐)
: Queue인터페이스의 구현체 중의 하나로, 저장한 순서에 관계없이 우선순위(priority)가 높은 것부터 꺼냅니다.
PriorityQueue는 null은 저장할 수 없으며, null을 저장할 시 NullPointerException이 발생합니다.
PriorityQueue는 저장공간을 배열을 사용하며, 각 요소를 "힙(heap)"이라는 자료구조의 형태로 저장합니다.
힙(heap)은 가장 큰 값이나 가장 작은 값을 빠르게 찾을 수 있다는 특징을 가집니다.
class PriorityQueueEx {
public static void main(String[] args) {
Queue pq = new PriorityQueue();
pq.offer(3);
pq.offer(1);
pq.offer(5);
pq.offer(2);
pq.offer(4);
System.out.println(pq); // pq의 내부 배열을 출력
Object obj = null;
// PriorityQueue에 저장된 요소를 하나씩 꺼낸다.
while((obj = pq.poll())!=null)
System.out.println(obj);
}
}출력값
[1,2,5,3,4]
1
2
3
4
5
저장 순서가 3,1,5,2,4 인데도 출력결과가 1,2,3,4,5 인 것을 확인할 수 있다. poll로 값을 가져오면 위 처럼 숫자가 작은 것이 우선순위를 가져 1 2 3 4 5 순으로 출력된다.
숫자가 아닌 객체를 저장하려면 각 객체의 크키를 비교할 수 있는 방법을 제공해야한다. 배열에 저장된 순서와 실제 우선순위가 다른것은 각 요소가 힙이라는 자료구조의 형태로 저장한 것이라서 그렇다.
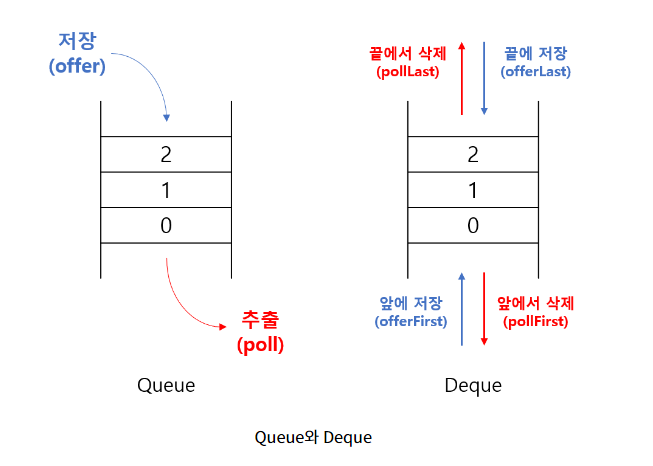
2-3 Deque(Double-Ended Queue)
: Queue의 변형으로 한쪽끝으로 추가/삭제만 할 수 있는 Queue과 달리, Deque는 양쪽 끝에 추가,삭제가 가능하다. ( 스택과 큐를 하나로 합쳐놓은 것과 같다. ) Deque의 조상은 Queue이고, 구현체로는 ArrayDeque, LinkedList 등이 있습니다.
2-4 큐 활용 예시
- 최근 사용문서
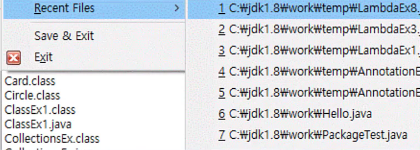
최대 7개의 최신 목록만 보여 준다 했을 때, 새로운게 들어오면 제일 오래된 것을 제거하고 최근 것을 추가 - 인쇄작업 대기목록, 버퍼(bufer)
- 너비 우선 탐색(BFS, Breadth-First Search) 구현
- 캐시(Cache) 구현
- 은행 업무
class StackQueueEx {
public static void main(String[] args) {
Stack st = new Stack();
Queue q = new LinkedList(); // Queue인터페이스의 구현체인 LinkedList를 사용
// Stack에 값 넣기
st.push("0");
st.push("1");
st.push("2");
// Queue에 값 넣기
q.offer("0");
q.offer("1");
q.offer("2");
System.out.println("= Stack =");
while(!st.empty()) {
System.out.println(st.pop());
}
System.out.println("= Queue =");
while(!q.isEmpty()) {
System.out.println(q.poll());
}
}
}
출력값
= Stack =
2
1
0
= Queue =
0
1
2
3. 트리(Tree)
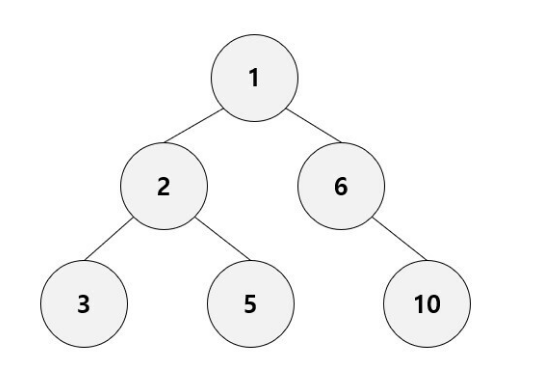
- 노드들이 나무 가지처럼 연결된 비선형 계층적 자료구조
- 하나의 루트 노드와 0개 이상의 하위 트리로 구성
- 데이터를 순차적으로 저장하지 않기 때문에 비선형 자료구조
- 트리 내에 또 다른 트리가 있는 재귀적 자료구조
- Loop를 갖지 않고 연결된 무방향 그래프 구조
- 계층형 자료구조 : 모든 노드는 단 하나의 부모 노드만을 가짐 (루트노드 제외)
- 노드가 n개인 트리는 항상 n-1개의 간선(edge)를 보유
3-1 트리와 관련된 용어
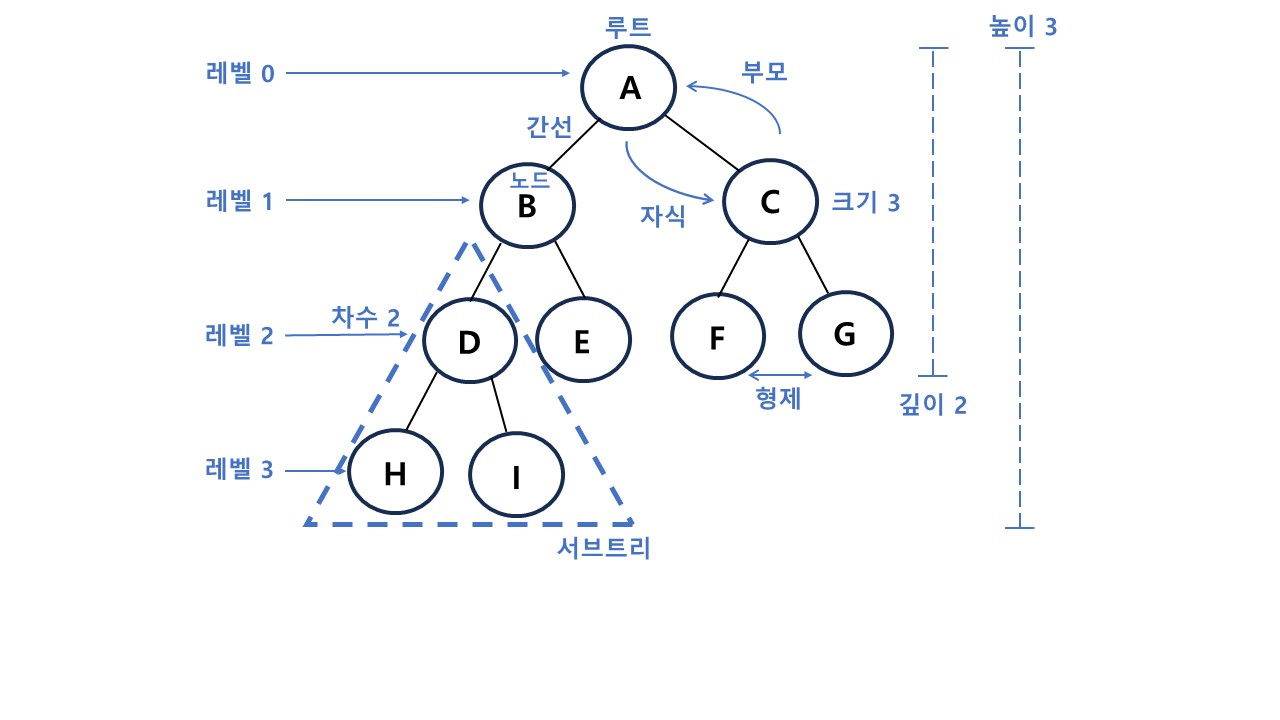
- Node(노드): 트리를 구성하는 각각의 요소
- Edge(간선): 트리를 구성하기 위해 노드와 노드를 연결하는 선
- Root Node(루트노드): 트리 구조에서 최상위에 있는 노드
- Parent Node(부모노드): 자식 노드를 가진 노드
- Chlid Node(자식노드): 부모 노드를 가진 노드
- Sibling Node(형제노드): 같은 부모를 가지는 노드
- Terminal Node(단말노드): 자식 노드가 없는 노드 (=Leaf Node, External Node, Outer Node)
- Internal Node(비단말노드): 자식 노드가 있는 노드 (=Branch Node, Internal Node, Inner Node)
Tree의 특징/속성 지칭 용어
- Depth(깊이): 어떤 노드에서 루트 노드까지 가장 긴 경로의 간선(Edge)의 수
- Height(높이): 어떤 노드에서 단말 노드까지 가장 긴 경로의 간선(Edge) 수
- Level: 루트 노드로부터 임의의 노드까지의 깊이 (루트 노드의 레벨=1)
- Degree(차수): 노드의 자식 수 (= 서브트리의 수)
- Path: 한 노드에서 다른 한 노드에 이르는 길 사이에 놓여있는 노드들의 순서
- Path Length: 해당 경로에 잇는 총 노드의 수
- Size(크기): 자신을 포함한 자손의 노드 수
- Width: 해당 레벨에 있는 노드 수
- Breadth: 리프 노드의 수
- Distance: 두 노드 사이의 최단 경로에 있는 간선(Edge)의 수
- Order: 부모 노드가 가질 수 있는 최대 자식 수 (이진 트리는 order = 2)
3-2 이진 탐색 트리 (Binary Search Tree)
: 이진 탐색이 동작할 수 있도록 고안된 효율적인 탐색이 가능한 자료구조의 일종.
- 각 노드가 최대 2개의 child를 갖는다.
- 왼쪽 자식 노드 < 부모 노드 < 오른쪽 자신 노드
-부모 노트보다 왼쪽 자식 노드가 작다.
-부모 노트보다 오른쪽 자식 노드가 크다. - 부모 노드를 중심으로 작은 값은 왼쪽 자식 노드에 큰 값은 오른쪽 자식 노드에 존재해야 하므로, 이직 탐색 트리는 모든 데이터 값은 중복 되는 값이 존재하면 안된다.
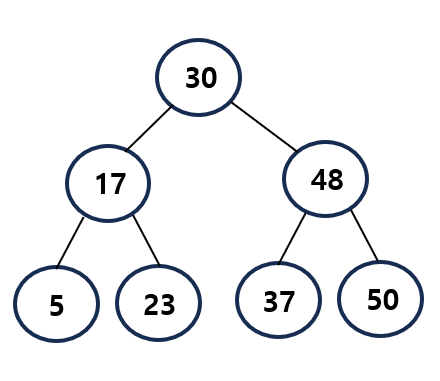
데이터 조회 과정
찾고자 하는 원소 : 37
1) 루트 노드부터 방문하여 탐색 진행
2) 현재 노드와 값을 비교 (찾는 원소가 더 크므로 오른쪽 방문)
3) 현재 노드와 값을 비교 (찾는 원소가 더 작으므로 오른쪽 방문)
4) 원소를 찾았으므로 탐색 종료
3-3 트리의 순회
: 트리 자료구조에 포함된 노드를 특정한 방법으로 한 번씩 방문하는 방법
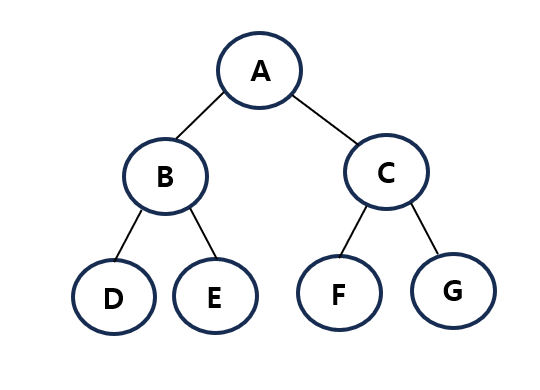
- 전위 순회(preorder traverse): 루트를 먼저 방문 (A -> B -> D -> E -> C -> F -> G) * 루트 - 왼쪽 자식 - 오른쪽 자식
- 중위 순회(inorder traverse): 왼쪽 자식을 방문한 뒤에 루트를 방문 (D -> B -> E -> A -> F -> C -> G) * 왼쪽 자식 - 루트 - 오른쪽 자식
- 후위 순회(postorder traverse): 오른쪽 자식을 방문한 뒤에 루트를 방문 (D -> E -> B -> F -> G -> C -> A) * 왼쪽 자식 - 오른쪽 자식 - 루트
3-4 트리의 사용 예시
계층 구조적인 관계를 나타낼때 ex) 파일 및 폴더는 계층적 트리 형태로 저장됨
회사의 조직도
정렬된 데이터를 관리할 때
빠르게 방문을 할 때
우선 순위 큐
4. 힙(Heap)
4-1 힙(Heap)이란?
힙 자료구조는 가장 높은(혹은 가장 낮은) 우선순위(최댓값, 최솟값)를 가지는 노드를 빠르게 찾아내기 위해 고안된 완전 이진트리(Complete Binary Tree) 기반의 자료구조이다. 따라서 가장 높은(또는 가장 낮은) 우선순위를 가지는 노드가 항상 루트 노드(root node)에 오는 게 특징이다.
완전 이진 트리(Complete Binary Tree) 자료구조란?
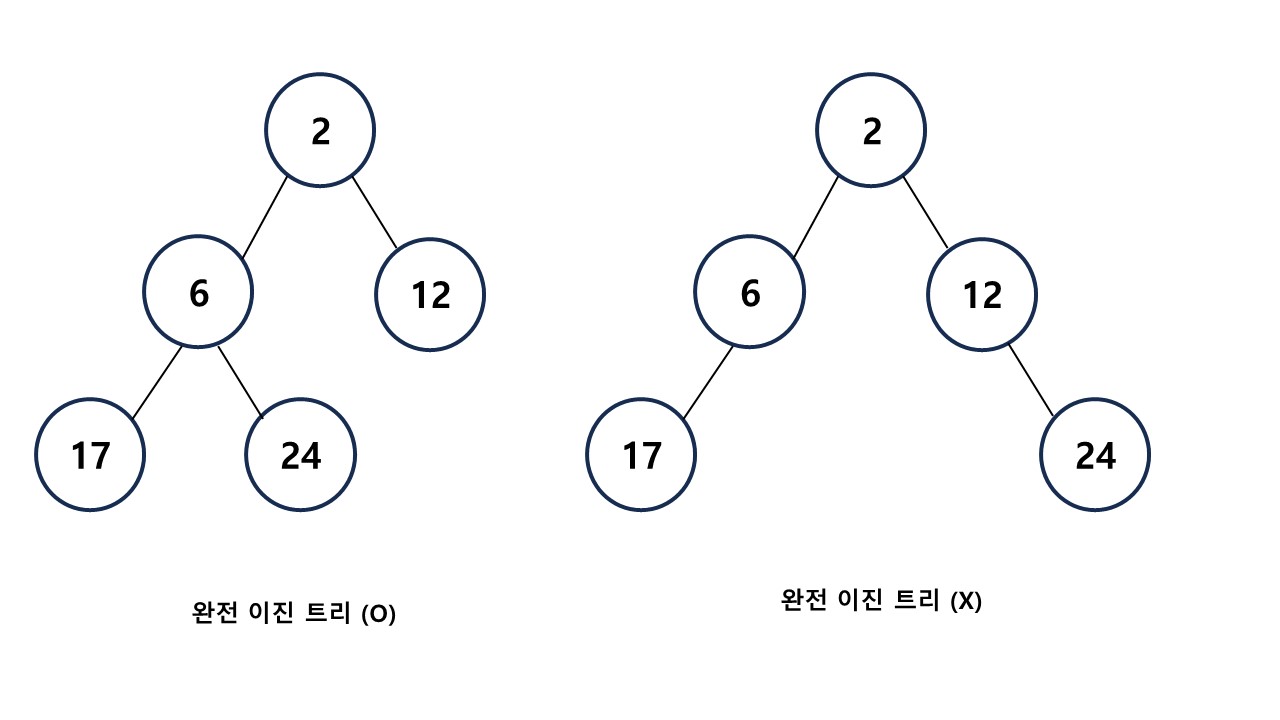
완전 이진 트리란 각 노드가 최대 2개의 자식 노드를 갖는 트리 형태의 자료구조로서 마지막 레벨을 제외한 모든 노드는 완전히 채워져 있어야 한다. 또한, 최하단 레벨의 노드는 좌측만 노드가 채워져 있거나 좌측과 우측 모두 채워져 있어야 하며, 노드를 삽입할 때는 최하단 좌측 노드부터 차례대로 삽입해야 한다. 우측 트리는 노드 12의 자식 노드가 우측에만 삽입되어 있기 때문에 완전 이진트리라고 할 수 없습니다.
힙은 다음과 같은 속성이 있다.
• A가 B의 부모 노드(parent node)일 때 A 노드의 키(key) 값과 B 노드의 키 값에는 대소 관계가 성립한다.
• 키 값의 대소 관계는 반드시 부모-자식 노드 간에 성립하며, 형제 노드 간에는 성립하지 않는다.
4-2 힙의 종류?
최대 힙(Max Heap): (완전 이진 트리) + (부모 노드 > 자식 노드)
최소 힙(Min Heap): (완전 이진 트리) + (부모 노드 < 자식 노드)

4-3 힙의 활용?
N개의 데이터가 저장된 리스트에서 최댓값 또는 최솟값을 탐색하려면 O(N) 만큼의 시간이 필요하다. 반면 힙 자료구조는 O(logN) 만큼의 시간이 필요하다.
* 힙에서 데이터의 삽입과 삭제 과정에서는 이진트리에 데이터가 N개가 있을때 1/2씩 인덱스를 줄여나가면서 자신의 위치를 찾기 때문에 시간복잡도는 logN
따라서 최댓값이나 최솟값을 빠르게 탐색해야 하는 우선순위 큐, 최단 경로 알고리즘 등을 구현할 때 유용하다.
4-4 데이터 삽입
- 가장 끝의 자리에 노드를 삽입한다.
- 그 노드와 부모 노드를 서로 비교한다.
- 규칙에 맞으면 그대로 두고, 그렇지 않으면 부모와 교환한다. (부모노드는 삽입된 위치의 인덱스 번호에서 /2를 하면 쉽게 구할 수 있다.)
- 규칙에 맞을 때까지 3번 과정을 반복한다.
4-5 데이터 삭제
최댓값 혹은 최솟값이 저장된 루트 노드만 제거할 수 있다.
1. 루트 노드를 제거한다.
2. 루트 자리에 가장 마지막 노드를 삽입한다.
3. 올라간 노드와 그의 자식 노드(들)와 비교한다.
4. 조건에 만족하면 그대로 두고, 그렇지 않으면 자식과 교환한다.
최대 힙
부모보다 더 큰 자식이 없으면 교환하지 않고 끝낸다.
부모보다 더 큰 자식이 하나만 있으면 그 자식하고 교환하면 된다.
부모보다 더 큰 자식이 둘 있으면 자식들 중 큰 값과 교환한다.
최소 힙
부모보다 더 작은 자식이 없으면 교환하지 않고 끝낸다.
부모보다 더 작은 자식이 하나만 있으면 그 자식하고 교환하면 된다.
부모보다 더 작은 자식이 둘 있으면 자식들 중 작은 값과 교환한다.
- 조건을 만족할 때까지 4의 과정을 반복한다.
4-6 표현
이진 힙은 완전 이진 트리(Complete Binary Tree)로서, 배열로 표현하기 매우 좋은 구조다. 높이 순서대로 순회하면 모든 노드를 배열에 낭비 없이 배치할 수 있기 때문이다. 그림처럼 완전 이진 트리는 배열에 빈틈없이 배치가 가능하며, 대개 트리의 배열 표현의 경우 계산을 편하게 하기 위해 인덱스는 1부터 사용한다.
(부모 노드의 인덱스) = (자식 노드 인덱스) // 2
(왼쪽 자식 노드의 인덱스) = (부모 노드의 인덱스) 2
(오른쪽 자식 노드의 인덱스) = (부모 노드의 인덱스) 2 + 1
해당 노드의 인덱스를 알면 깊이가 얼마인지, 부모와 자식 노드가 배열 어디에 위치하는지 바로 알아낼 수 있다.
