단변량 분석 실습
문제 출처: https://github.com/DA4BAM/dataset
-
고객사는 카시트를 판매하는 회사임.
-
최근 매출 하락에 대해 각 부서가 파악한 원인 다음과 같음.
- 최근에 경쟁사와의 가격 경쟁력이 하락하고 있고, 광고비용이 적절하게 집행되지 않음.
- 너무 국내 시장에 집중됨.
- 지역마다의 구매력을 제대로 파악하지 못하고 있음.
-
그러나 각 부서가 파악한 원인이 데이터에 근거하고 있는지 확인해 볼 필요가 있음.
단변량 분석 할 때 확인해야 할 점들
-
개별 변수의 분포로 부터…
- 값의 범위 확인
- 데이터가 모여 있는 구간(혹은 범주)와 희박한 구간(혹은 범주) 확인
- 이상치 확인 및 조치 방안
- 결측치 확인 및 조치 방안
- 가변수화, 스케일링 대상 선별
-
비즈니스의 일반 사항과 특이사항을 도출
- 추가 분석 대상 도출.
# 필요한 모듈 가져오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings(action='ignore')카시트 판매량 데이터

| 변수명 | 설명 | 구분 |
|---|---|---|
| Sales | 각 지역 판매액(단위 : 1000달러) | Target |
| CompPrice | 경쟁사 가격(단위 : 달러) | feature |
| Income | 지역 평균 소득(단위 : 1000달러) | feature |
| Advertising | 각 지역, 회사의 광고 예산(단위 : 1000달러) | feature |
| Population | 지역 인구수(단위 : 1000명) | feature |
| Price | 자사 지역별 판매가격 | feature |
| ShelveLoc | 진열상태 | feature |
| Age | 지역 인구의 평균 연령 | feature |
| Urban | 도심 지역 여부(0,1) | feature |
| US | 매장이 미국에 있는지 여부(0,1) | feature |
path = 'https://raw.githubusercontent.com/JunhoYu/Data-Analysis/main/Carseats.csv'
data = pd.read_csv(path)
# 설명이 되어 있지 않은 컬럼에 대해서는 삭제 조치
data.drop('Education', axis = 1, inplace = True)
data.head()| Sales | CompPrice | Income | Advertising | Population | Price | ShelveLoc | Age | Urban | US | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 9.50 | 138 | 73 | 11 | 276 | 120 | Bad | 42 | Yes | Yes |
| 1 | 11.22 | 111 | 48 | 16 | 260 | 83 | Good | 65 | Yes | Yes |
| 2 | 10.06 | 113 | 35 | 10 | 269 | 80 | Medium | 59 | Yes | Yes |
| 3 | 7.40 | 117 | 100 | 4 | 466 | 97 | Medium | 55 | Yes | Yes |
| 4 | 4.15 | 141 | 64 | 3 | 340 | 128 | Bad | 38 | Yes | No |
① Sales (Target)
var = 'Sales'1) 변수의 비즈니스 의미
- 각 지역 판매액(단위 : 1000달러)
- Target
2) 숫자, 범주?
- 숫자형 데이터(float)
3) NaN 존재 유무 및 조치방안
data[var].isna().sum()0- NaN 없음
4) 가변수화 필요 여부
- 숫자형 데이터로 가변수화 필요 없음.
5) 기초통계량(수치화)
data[var].describe()count 400.000000
mean 7.496325
std 2.824115
min 0.000000
25% 5.390000
50% 7.490000
75% 9.320000
max 16.270000
Name: Sales, dtype: float646) 분포 확인(시각화)
plt.figure(figsize = (6,8))
plt.subplot(3,1,1)
sns.histplot(x = var, data = data, bins = 20)
plt.subplot(3,1,2)
sns.kdeplot(x = var, data = data)
plt.subplot(3,1,3)
sns.boxplot(x = var, data = data,)
plt.tight_layout()
plt.show()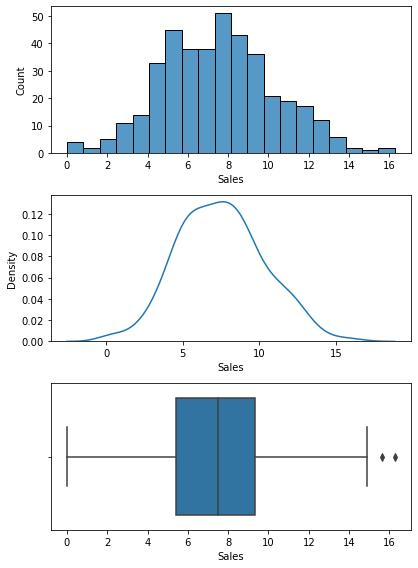
7) 기초통계량과 분포를 통해서 파악한 내용.
- 판매액이 주로 5000 ~ 9000달러 사이에 분포해 있는 것을 알 수 있음.
- 판매액이 10 ~ 16천달러로 높은 지역과 상대적으로 낮은 판매액(5천달러 미만)을 기록한 지역들간의 차이를 확인해볼 필요가 있음(진열 상태, 도심지 위치, 경쟁사 가격 등)
8) 추가 분석해 볼 사항이 있나요?
- 경쟁사의 카시트 평균 판매 가격과 매출의 관계
- 광고비용과 매출의 관계
- 지역에 따른 매출의 관계
② CompPrice
var = 'CompPrice'1) 변수의 비즈니스 의미
- 경쟁사 가격(단위 : 달러)
2) 숫자, 범주?
- 숫자형 데이터(float)
3) NaN 존재 유무 및 조치방안
data[var].isna().sum()0- NaN 없음
4) 가변수화 필요 여부
- 숫자형 데이터로 가변수화 필요 없음.
5) 기초통계량(수치화)
data[var].describe()count 400.000000
mean 124.975000
std 15.334512
min 77.000000
25% 115.000000
50% 125.000000
75% 135.000000
max 175.000000
Name: CompPrice, dtype: float646) 분포 확인(시각화)
plt.figure(figsize = (6,8))
plt.subplot(3,1,1)
sns.histplot(x = var, data = data, bins = 20)
plt.subplot(3,1,2)
sns.kdeplot(x = var, data = data)
plt.subplot(3,1,3)
sns.boxplot(x = var, data = data,)
plt.tight_layout()
plt.show()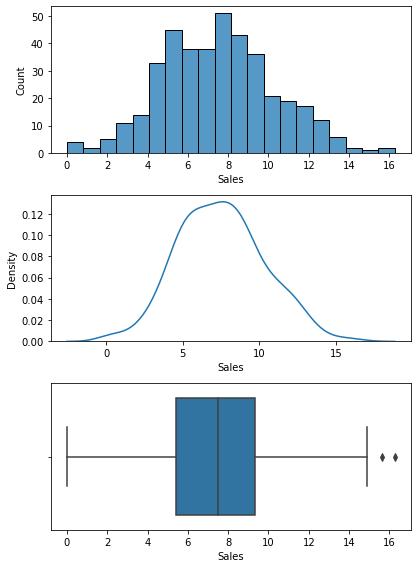
7) 기초통계량과 분포를 통해서 파악한 내용.
- 경쟁사 카시트 가격의 최저가와 최고가의 가격 차이는 약 100달러로 금액차이가 크지 않음.
- 경쟁사의 상품가격은 주로 115~135달러 사이로 저가 제품이 주를 이루고 있음을 알 수 있음.(2016년 한국 카시트 평균가격 약 46만원, 출처: https://www.seoul.co.kr/news/newsView.php?id=20160823010019)
- 따라서 경쟁사의 저가 상품 위주가 판매 전략임을 알 수 있음.
8) 추가 분석해 볼 사항이 있나요?
- 자사 제품과의 가격차이
③ Income
var = 'Income'1) 변수의 비즈니스 의미
- 지역별 평균소득(단위: 1000달러)
2) 숫자, 범주?
- 숫자형 데이터(int)
3) NaN 존재 유무 및 조치방안
data[var].isna().sum()0NaN 없음
4) 가변수화 필요 여부
- 숫자형 데이터로 가변수화 필요 없음.
5) 기초통계량(수치화)
data[var].describe()count 400.000000
mean 68.657500
std 27.986037
min 21.000000
25% 42.750000
50% 69.000000
75% 91.000000
max 120.000000
Name: Income, dtype: float646) 분포 확인(시각화)
plt.figure(figsize = (6,8))
plt.subplot(3,1,1)
sns.histplot(x = var, data = data, bins = 20)
plt.subplot(3,1,2)
sns.kdeplot(x = var, data = data)
plt.subplot(3,1,3)
sns.boxplot(x = var, data = data,)
plt.tight_layout()
plt.show()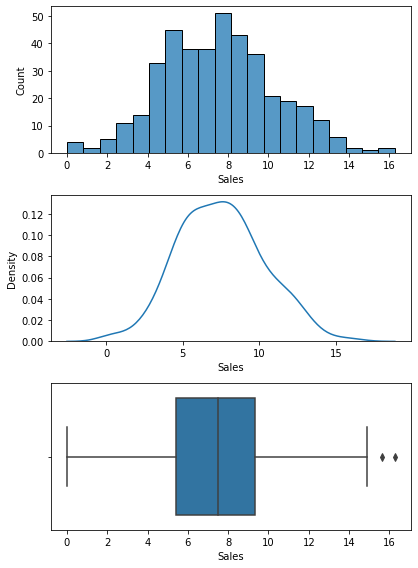
7) 기초통계량과 분포를 통해서 파악한 내용.
- 최소 21만달러 ~ 최대 12만 달러 이므로 연간 소득일 것으로 예상
- 주로 소득이 42만 ~ 91만 달러 사이에 위치
8) 추가 분석해 볼 사항이 있나요?
- 평균 소득과 카시트 판매량과의 관계
- 평균 소득과 카시트 가격과의 관계
- 평균 소득과 지역 인구수간의 관계(빈민가 vs 부촌)
④ Advertising
var = 'Advertising'1) 변수의 비즈니스 의미
- 각 지역, 회사의 광고 예산(단위 : 1000달러)
2) 숫자, 범주?
- 숫자형 데이터
3) NaN 존재 유무 및 조치방안
data[var].isna().sum()04) 가변수화 필요 여부
- 숫자형 데이터로 가변수화 필요 없음.
5) 기초통계량(수치화)
data[var].describe()count 400.000000
mean 6.635000
std 6.650364
min 0.000000
25% 0.000000
50% 5.000000
75% 12.000000
max 29.000000
Name: Advertising, dtype: float646) 분포 확인(시각화)
plt.figure(figsize = (6,8))
plt.subplot(3,1,1)
sns.histplot(x = var, data = data, bins = 20)
plt.subplot(3,1,2)
sns.kdeplot(x = var, data = data)
plt.subplot(3,1,3)
sns.boxplot(x = var, data = data,)
plt.tight_layout()
plt.show()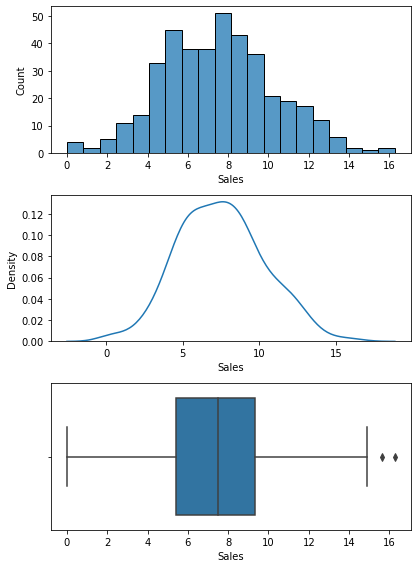
7) 기초통계량과 분포를 통해서 파악한 내용.
# 광고비 예산이 0 인 지역이 많아 보임.
# 광고비 예산이 0 인 지역의 비율.
data.loc[data['Advertising']==0].shape[0] / data.shape[0]0.36- 광고비 예산이 0 인 지역이 전체에 36%나 됨.
- 광고비가 불균형하게 쓰이고 있음을 확인.
- 초기 매출 하락 원인으로 언급된 광고비의 적절한 집행이 되고 있지 않다는 것을 보여줌.
8) 추가 분석해 볼 사항이 있나요?
- 광고비 예산 0인 지역의 판매량 확인 필요.
- 광고비 예산 0을 제외하고 분포 확인 필요.
⑤ Population
var = 'Population'1) 변수의 비즈니스 의미
- 지역 인구수(단위 : 1000명)
2) 숫자, 범주?
- 숫자형 데이터
3) NaN 존재 유무 및 조치방안
data[var].isna().sum()0- NAN 없음
4) 가변수화 필요 여부
- 숫자형이므로 필요 없음
5) 기초통계량(수치화)
data[var].describe()count 400.000000
mean 264.840000
std 147.376436
min 10.000000
25% 139.000000
50% 272.000000
75% 398.500000
max 509.000000
Name: Population, dtype: float646) 분포 확인(시각화)
plt.figure(figsize = (6,8))
plt.subplot(3,1,1)
sns.histplot(data[var], bins = 20)
plt.subplot(3,1,2)
sns.kdeplot(data[var])
plt.subplot(3,1,3)
sns.boxplot(data[var])
plt.tight_layout()
plt.show()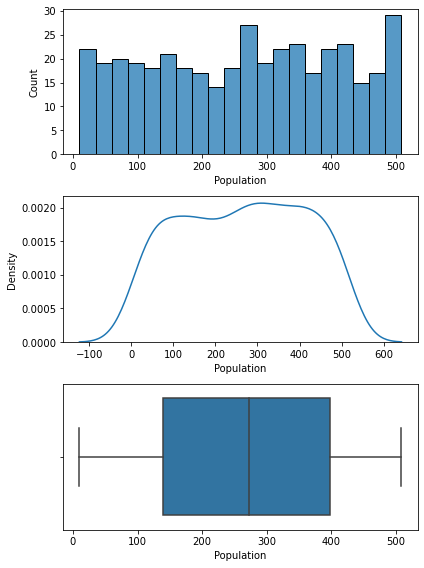
7) 기초통계량과 분포를 통해서 파악한 내용.
- 인구수가 거의 균등분포를 이룸.
- 인구수가 적을수록 부유한 지역일 확률이 높음. 보통 거주단지는 부유한 지역보다 집값이 싸기 때문에 출근은 도시로, 거주는 도시 외곽에서 하는 경우가 많음. 따라서 지역 인구수가 높은 곳일수록 잠재적 고객수가 많음을 의미.
8) 추가 분석해 볼 사항이 있나요?
- 인구수에 따른 판매량 관계
- 인구수와 평균연령의 관계
⑥ Price
var = 'Price'1) 변수의 비즈니스 의미
- 자사 지역별 판매가격
2) 숫자, 범주?
- 숫자형 데이터
3) NaN 존재 유무 및 조치방안
data[var].isna().sum()0- NAN 없음
4) 가변수화 필요 여부
- 숫자형이므로 필요 없음
5) 기초통계량(수치화)
data[var].describe()count 400.000000
mean 115.795000
std 23.676664
min 24.000000
25% 100.000000
50% 117.000000
75% 131.000000
max 191.000000
Name: Price, dtype: float646) 분포 확인(시각화)
plt.figure(figsize = (6,8))
plt.subplot(3,1,1)
sns.histplot(data[var], bins = 20)
plt.subplot(3,1,2)
sns.kdeplot(data[var])
plt.subplot(3,1,3)
sns.boxplot(data[var])
plt.tight_layout()
plt.show()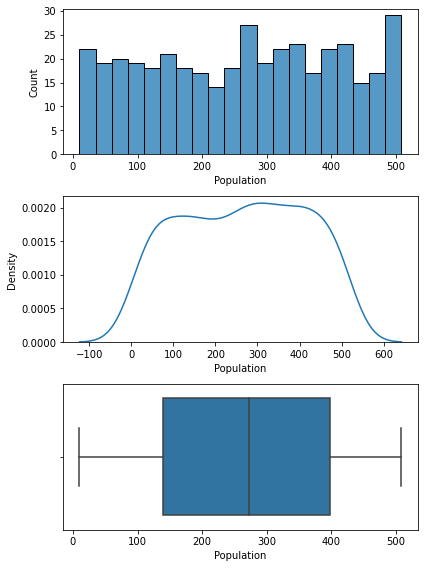
7) 기초통계량과 분포를 통해서 파악한 내용.
- 가격대가 24 ~ 191 달러로 경쟁사보다 범위가 넓음.
- 50%는 100 ~ 130 사이.
8) 추가 분석해 볼 사항이 있나요?
- 가격에 따라 판매량은 달라지는지
- 자사 가격과 경쟁사 가격과의 비교
# 추가 분석
plt.figure(figsize = (10,6))
sns.kdeplot(data['Price'], label = 'Price')
sns.kdeplot(data['CompPrice'], label = 'CompPrice')
price_mean = round(np.mean(data['Price']),1)
com_mean = round(np.mean(data['CompPrice']),1)
plt.axvline(price_mean, color = 'C0', linewidth = .5)
plt.axvline(com_mean, color = 'C1', linewidth = .5)
plt.text(price_mean-16, 0.001, price_mean, color = 'C0')
plt.text(com_mean+5, 0.001, com_mean, color = 'C1')
plt.legend()
plt.show()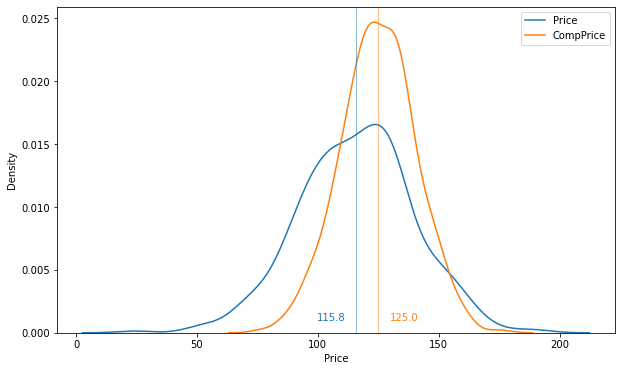
plt.figure(figsize = (10,6))
sns.boxplot(data=data[['Price','CompPrice']], orient="h")
plt.show()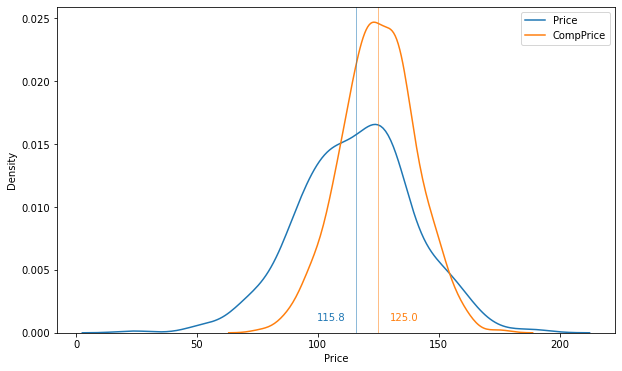
- 이를 통해 초기 판매 부진의 원인 중 하나라 했던 가격 경쟁력 하락은 근거가 약해보임
- 일부 제품을 제외하고는 대부분의 자사 제품 가격이 경쟁사 제품의 가격보다 대부분 낮음.
- 경쟁사가 다양한 프로모션(할인 쿠폰, 이벤트 등)을 진행하고 있는지 확인할 필요가 있음
⑦ ShelveLoc
var = 'ShelveLoc'1) 변수의 비즈니스 의미
- 매장 진열상태
2) 숫자, 범주?
- 범주 값의 종류 : 'Bad', 'Good', 'Medium'
3) NaN 존재 유무 및 조치방안
data[var].isna().sum()0- NAN 없음
4) 가변수화 필요 여부
- 범주형이고, 1,0 값이 아니므로 가변수화 필요.
5) 기초통계량(수치화)
# 범주별 빈도수
data[var].value_counts()Medium 219
Bad 96
Good 85
Name: ShelveLoc, dtype: int64# 범주별 비율
data[var].value_counts() / data[var].shape[0]Medium 0.5475
Bad 0.2400
Good 0.2125
Name: ShelveLoc, dtype: float646) 분포 확인(시각화)
sns.countplot(data[var], order = ['Good','Medium','Bad'])
plt.show()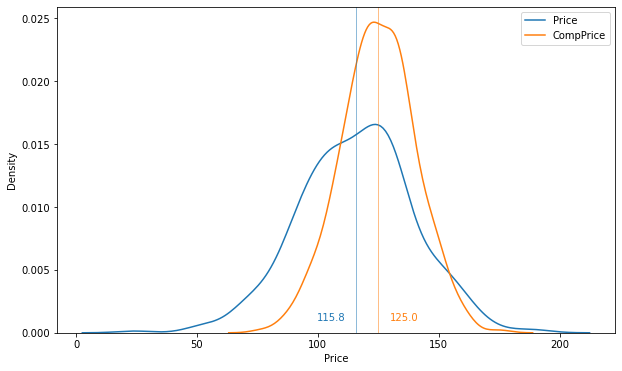
7) 기초통계량과 분포를 통해서 파악한 내용.
- 매장 진열 상태가 중간인 정도가 약 55%, 나쁨이 약 24%로 총 79%의 매장 진열도가 good에 미치지 못함.
- 매장 진열 상태는 고객이 매장을 방문했을 때, 그 매장의 첫인상을 좌우하는 중요한 부분임.
- 따라서 전 매장의 진열 상태를 good으로 만들기 위해 매장 진열 메뉴얼을 갱신하고 관리자들이 확인을 할 필요가 있어보임.
8) 추가 분석해 볼 사항이 있나요?
- 진열상태에 따른 판매량 차이
- 지역, 인구수와 진열 상태 관계 비교, 인구수가 높을수록 진열 상태가 나쁘다면 방문하는 손님에 비해 매장 관리 인력이 부족한 것일 수 있음. 이 경우 인력을 추가배치할 필요가 있음.
⑧ Age
var = 'Age'1) 변수의 비즈니스 의미
- 지역 인구의 평균 연령
2) 숫자, 범주?
- 숫자형 데이터
3) NaN 존재 유무 및 조치방안
data[var].isna().sum()0- NAN 없음
4) 가변수화 필요 여부
- 숫자형이므로 필요 없음
5) 기초통계량(수치화)
data[var].describe()count 400.000000
mean 53.322500
std 16.200297
min 25.000000
25% 39.750000
50% 54.500000
75% 66.000000
max 80.000000
Name: Age, dtype: float646) 분포 확인(시각화)
plt.figure(figsize = (6,8))
plt.subplot(3,1,1)
sns.histplot(data[var], bins = 20)
plt.subplot(3,1,2)
sns.kdeplot(data[var])
plt.subplot(3,1,3)
sns.boxplot(data[var])
plt.tight_layout()
plt.show()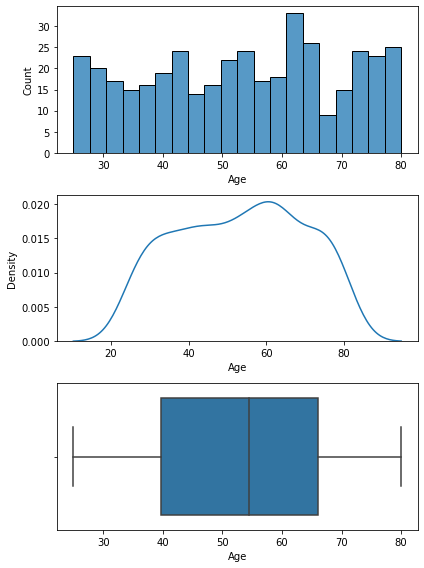
7) 기초통계량과 분포를 통해서 파악한 내용.
- 지역별 평균나이는 거의 균등분포로 보임.
8) 추가 분석해 볼 사항이 있나요?
- 지역 인구 전체에 대한 평균
- 카시트가 필요한 사람은, 약 10세 이하 자녀를 둔 부모
- 10세 이하 자녀들과 20대후반 ~ 40세의 부모가 주축인 지역이 어딘지 파악할 필요가 있음.
⑨ Urban
var = 'Urban'1) 변수의 비즈니스 의미
- 도심 지역 여부
2) 숫자, 범주?
- 범주형 데이터
data[var].unique()array(['Yes', 'No'], dtype=object)가변수화 필요
3) NaN 존재 유무 및 조치방안
data[var].isna().sum()0- NA 없음
4) 가변수화 필요 여부
- 범주형이고, 1,0 값이 아니므로 가변수화 필요.
5) 기초통계량(수치화)
# 범주별 빈도수
data[var].value_counts()Yes 282
No 118
Name: Urban, dtype: int64# 범주별 비율
data[var].value_counts() / data[var].shape[0]Yes 0.705
No 0.295
Name: Urban, dtype: float646) 분포 확인(시각화)
sns.countplot(data[var], order = ['Yes','No'])
plt.show()
7) 기초통계량과 분포를 통해서 파악한 내용.
- 약 70% 매장이 도시에 있음.
- 도심지역일수록 대중교통이 발달되어 있어 자가용을 사용할 확률이 적음. 따라서 도심 지역이 아닐 수록 자가용을 사용할 일이 많기 때문에 카시트를 구매할 확률이 높음.
- 반대로 도심지역 역시 대중교통이 발달되어 있다면 카시트를 어느정도 사용할 수 있기 때문에 해당 부분을 파악할 필요가 있음.
8) 추가 분석해 볼 사항이 있나요?
- 도시 외곽의 인구수
- 도심 지역의 대중교통 발달 수준
⑩ US
var = 'US'1) 변수의 비즈니스 의미
- 매장이 미국에 있는지 여부
2) 숫자, 범주?
- 범주형 데이터
data[var].unique()array(['Yes', 'No'], dtype=object)3) NaN 존재 유무 및 조치방안
data[var].isna().sum()04) 가변수화 필요 여부
- 범주형이고, 1,0 값이 아니므로 가변수화 필요.
5) 기초통계량(수치화)
# 범주별 빈도수
data[var].value_counts()Yes 258
No 142
Name: US, dtype: int64# 범주별 비율
data[var].value_counts() / data[var].shape[0]Yes 0.645
No 0.355
Name: US, dtype: float646) 분포 확인(시각화)
sns.countplot(data[var], order = ['Yes', 'No'])
plt.show()
7) 기초통계량과 분포를 통해서 파악한 내용.
- 약 65%가 국내(미국) 매장에 위칳마
- 초기 매출 하락에 대해 국내 시장에 집중된 문제를 언급. 그러나 해외 매장이 전체의 35%로 절대 적은 규모는 아님.
8) 추가 분석해 볼 사항이 있나요?
- 국외 광고비, 제품 판매가, 국외 경쟁사가격, 매출액 등
정리
최근 매출하락에 대한 원인들에 대해 단변량 분석 결과를 정리해봄.
- 최근 경쟁사와의 가격 경쟁력이 하락하고 있음 -> 이전 자사와 경쟁사의 제품 가격이 어느정도인지 알 수 없지만 현재 자사 제품의 가격 경쟁력은 약하지 않음.
- 너무 국내 시장에 집중됨 -> 약 30%의 매장이 국외 시장에 진출해 있기 때문에 결코 국내 시장에만 집중되어 있다고 볼 수 없음
- 지역마다 구매력을 제대로 파악하지 못하고 있음 -> 단변량 분석을 통해 각 지역의 구매력을 확인할 수 없음. 따라서 추가적인 데이터 분석이 필요함.
