
개요
Kotlin는 읽고 쓸 수 있는 프로퍼티(var)와 읽기 전용 프로퍼티(val)로 구분됩니다. 마찬가지로 코틀린은 읽고 쓸 수 있는 컬렉션과 읽기 전용 컬렉션으로 구분됩니다.
이는 컬렉션 계층이 설계된 방식 때문이라고 할 수 있습니다.
컬렉션 계층
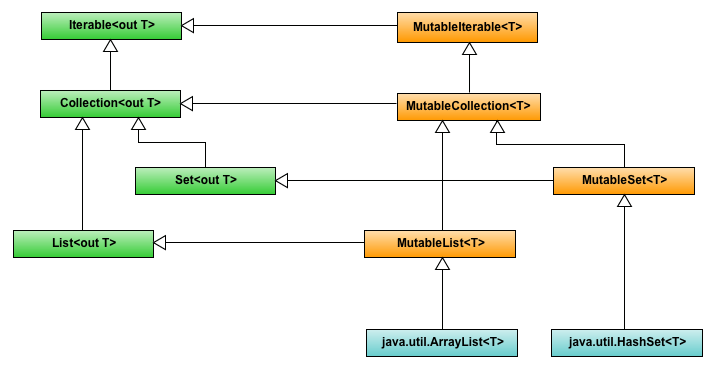
다음 이미지는 코틀린의 컬렉션 계층을 나타낸 것 입니다. 왼쪽에 있는 Iterable, Collection, Set, List 인터페이스는 읽기 전용이며 변경을 위한 메서드를 따로 가지고 있지 않습니다. 반면 오른쪽에 있는 MutableIterable, MutableCollection, MutableSet, MutableList 인터페이스는 읽고 쓸 수 있는 컬렉션입니다. 특징을 보면 앞에 Mutable이 붙어 있는 것을 볼 수 있습니다.
이처럼 mutable이 붙은 인터페이스는 대응되는 읽기 전용 인터페이스를 상속 받아서, 변경을 위한 메서드를 추가한 것입니다. 이는 마치 읽기 전용 프로퍼티는 getter()만 갖고 읽고 쓰기 전용 프로퍼티는 getter()와 setter()를 가지고 있는 것 처럼 말입니다.
그렇다고 읽기 전용 컬렉션이 내부의 값을 변경할 수 없다는 것은 아닙니다. 대부분 변경이 가능하지만 읽기 전용 인터페이스가 지원을 하지않아 변경이 안되는 것입니다. 이 차이를 이해해야 합니다.
코틀린이 내부적으로 immutable 하지 않은 컬렉션을 외부적으로 immutable하게 보이게 만든 이유는 안정성 때문입니다. 하지만 앞에서 말한 것 처럼 어떠한 개발자들은 시스템 해킹을 시도해 다운캐스팅을 하게되고 그때 문제가 발생하게 됩니다.
컬렉션 부분에서 이러한 다운캐스팅을 하는 것은 kotlin의 rule 위반이며 추상화를 무시하는 행위 입니다. 또한 읽기 전용 컬렉션을 강제로 쓸 수 있게 해버리면 예측할 수 없는 결과가 발생할 수 있습니다.
val list = listOf(1,2,3)
if(list is MutableList){
list.add(4)
}위의 코드 동작의 결과는 플랫폼에 따라 차이가 있는데 JVM에서 listOf는 자바의 List 인터페이스를 구현한 Array.ArrayList 인스턴스를 리턴합니다. 즉 자바에서는 add와 set 같은 메서드를 제공하기 때문에 kotlin의 MutableList로 변경이 됩니다. 하지만 Arrays.ArrayList는 이러한 연산을 구현하지 않기 때문에 다음과 같은 error가 발생하게 됩니다.

정말 읽기 전용에서 mutable로 변경해야 한다면 kotlin의 copy()를 통해 새로운 mutable 컬렉션을 만드는 list.toMutableList를 활용해야 합니다.
val list = listOf(1,2,3)
val mutableList = list.toMutableList()
mutableList.add(4)다음과 같이 코드를 작성하게 되면 kotlin의 rule도 어기지 않을 수 있고 기존의 객체는 여전히 읽기 전용으로 남아있기 때문에 즉 getter()만 가능하기에 안정성 또한 가질 수 있습니다
데이터 클래스의 copy
String 이나 Int처럼 내부적인 상태를 변경하지 않는 immutalbe 객체를 많이 사용하는 데는 다음과 같은 이유가 있기 때문입니다.
-
한 번 정의된 상태가 유지되므로 코드의 이해가 쉬워진다.
-
immutable 객체는 공유했을 때 충돌이 발생하지 않으므로 안전한 병렬처리가 가능하다.
-
immutable 객체에 대한 참조는 변경되지 않으므로 쉽게 캐시를 할 수 있습니다.
-
immutable 객체는 방어적 복사(defensive copy)를 만들 필요가 없습니다.
방어적 복사란??? : 생성자의 인자로 받은 객체의 복사본을 만들어 내부 필드를 초기화하거나, getter 메서드에서 내부의 객체를 반환할 때 객체의 복사본을 만들어 반환하는 것을 말합니다.
추가 설명 -> 방어적 복사를 많이 사용되는 부분은 유효성을 검사할 때 입니다.
일반적으로 값을 검증하고 객체 내부변수에 할당해주는게 맞는 절차라고 생각할 수 있지만 Date와 이벤트 발생 시점과 연관된 동작의 경우(LatLng) 값이 변경될 수 있기 때문에 생성자에서 매개변수의 유효성을 검사하기 전 방어적 복사본을 만들고 이를 이용해 검증하는 것 입니다.
5.immutable 객체는 다른 객체를 만들때 활용하기 좋습니다. 또한 immutable 객체는 코드 run 상태에서의 실행을 쉽게 예측할 수 있습니다.
6.immutable 객체는 set 또는 map의 키로도 사용할 수 있습니다. 그러한 이유는 set와 map은 내부적으로 해시테이블을 사용하고 해시 테이블은 처음 요소를 넣을 때 요소의 값을 기반으로 버킷을 결정하기 때문입니다. 따라서 요소에 수정이 일어나면 해시 테이블 내부에 저장한 요소를 찾을 수 없게 되어버립니다.
6-1 6번의 내용을 코드로 보여드리겠습니다.
val countrys: SortedSet<Country>= TreeSet()
val korea = Country("Korea","Seoul")
countrys.add(korea)
countrys.add(Country("Japan","Tokyo")
countrys.add(Country("China","Beijing")
print(countrys)
// 출력결과는 다음과 같습니다.
// Korea Seoul, Japan Tokyo, China Beijing
//그리고 아래와 같이 코드를 입력하면
print(korea in Countrys)
// 결과 -> true
korea.name = "South Korea"
print(countrys)
// 출력결과는 다음과 같습니다.
// South Korea Seoul, Japan Tokyo, China Beijing
print(korea in Countrys)
// 결과 -> false마지막 출력을 보면, 세트 내부에 해당 객체가 있음에도 false를 리턴하는 것을 알 수 있습니다. 객체를 값을 변경했기 때문에 찾을 수 없는 것 입니다.
위의 코드에서 본 것처럼 mutable 객체는 예측하기 어려우며 위험하다는 단점이 있습니다. 반면 immutable 객체는 변경할 수 없다는 단점이 있습니다. 따라서 immutable 객체는 일부를 수정해야 한다면 새로운 객체를 만들어내는 방식으로 해결해 나가야합니다.
마치며
이번 글에서 보면 Kotlin에서 mutable과 immutable을 분리를 시켜 얻는 여러가지의 장점 중 가장 중요한 것은 안정성(safety)라는 것을 알 수 있습니다. 또한 멀티스레딩 환경에서는 값의 안정성이 지켜지지 않는다면 어떠한 결과를 불러올지 모르니 다운캐스팅을 하는 행위는 없어야 할 거라는 생각이 들게 되네요 이번 글도 읽어주셔서 감사합니다!!
