
Volatile 키워드란?
Volatile 키워드는 Java 변수를 “주 메모리에 저장됨”으로 표시하는 데 사용됩니다. 보다 정확하게는 휘발성 변수에 대한 모든 읽기는 CPU 레지스터가 아닌 컴퓨터의 주 메모리에서 읽혀지며, 휘발성 변수에 대한 모든 쓰기는 CPU 레지스터뿐만 아니라 주 메모리에 기록된다는 의미입니다.
위에서 말했던것 처럼 Volatile 키워드는 스레드 전체의 변수 변경 사항에 대한 가시성을 보장합니다. 다소 추상적으로 들릴 수도 있으므로 자세히 설명하자면
스레드가 비휘발성 변수에 대해 작동하는 다중 스레드 애플리케이션에서 각 스레드는 성능상의 이유로 작업하는 동안 주 메모리의 변수를 CPU의 레지스터로 복사할 수 있습니다. 컴퓨터에 두 개 이상의 CPU가 있는 경우 각 스레드는 서로 다른 CPU에서 실행될 수 있습니다. 즉 각 스레드는 변수를 다른 CPU의 CPU 레지스터에 복사할 수 있습니다.
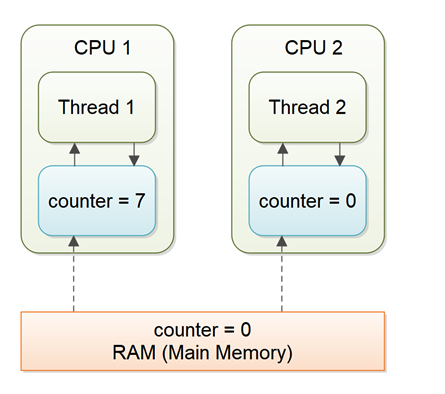
변수가 아직 다른 스레드에 의해 주 메모리에 다시 기록되지 않았기 때문에 변수의 최신 값을 보지 못하는 스레드의 문제를 “가시성” 문제라고 합니다. 한 스레드의 업데이트는 다른 스레드에 표시되지 않습니다.
Java 휘발성 가시성 보장
Java Volatile 키워드는 변수 가시성 문제를 해결하기 위한 것입니다. Counter 변수를 선언하면 변수 volatitle에 대한 모든 쓰기가 counter 즉시 주 메모리에 다시 기록됩니다. 또한 모든 변수 읽기는 counter 주 메모리에서 직접 읽혀집니다.
Volatile 변수 선언은 다음과 같습니다.
public class SharedObject {
public volatitle int counter = 0;
}Volatile를 변수에 선언하면 해당 변수에 대한 다른 스레드에 대한 사시성이 보장됩니다.
완전한 휘발성 가시성 보장
- 쓰기 후 읽기 (Write-Read 가시성 보장)
만약 스레드 A가 volatile 변수에 값을 쓰게 된다면 그 전에 스레드 A가 보았던 모든 변수들의 상태가 메인 메모리에 강제로 기록됩니다. 그런 다음 스레드 B가 그 volatile 변수를 읽을 때, 스레드 B는 그 전에 스레드 A가 본 모든 변수들의 최신 값을 메인 메모리에서 읽게 됩니다. 이렇게 함으로써 스레드 간의 메모리 가시성이 보장됩니다.
- 읽기 후 다시 읽기 (Read-After-Read 가시성 보장)
스레드 A가 volatile 변수를 읽을 때 모든 변수들을 메인 메모리에서 다시 읽는 효과를 가집니다. 이는 volatile 변수가 읽히는 시점에, 스레드 A가 메인 메모리의 최신 값을 보게 만든다는 것을 의미합니다. 즉, 그 이전에 스레드 A가 가지고 있었던 모든 변수들의 캐시된 값이 아닌, 메인 메모리에 있는 최신 값을 다시 가져오게 됩니다.
이러한 메커니즘을 통해 volatile 키워드는 다중 스레드 환경에서 메모리의 일관성을 유지하는데 도움을 줍니다.
명령어 재정렬 문제
명령어 재정렬이란?
- 상세 설명 명령어 재정렬(instruction reordering)은 jvm 이나 cpu가 프로그램의 성능을 최적화하기 위해 명령어의 실행순서를 변경하는 것입니다. 이는 프로그램의 최종 결과에 영향을 주지 않는 범위 내에서 수행됩니다. 하지만 멀티 스레드 환경에서는 명령어 재정렬로 인해 변수 값의 가시성(visibility)이 보장되지 않을 수 있습니다.
Java VM과 CPU는 명령의 의미론적 의미가 동일하게 유지되는 한 성능상의 이유로 프로그램에서 명령의 순서를 변경할 수 있습니다. 예를 들어 보면
int a = 1;
int b = 2;
a++;
b++;이러한 명령어는 프로그램의 의미론적 의미를 잃지 않고 다음 순서로 재정렬될 수 있습니다.
int a = 1;
a++;
int b = 2;
b++;그러나 명령어 재정렬은 volatile 변수가 있을 때 문제를 제기합니다.
public class MyClass {
private int years;
private int months;
private volatile int days;
public void update(int years, int months, int days){
this.years = years;
this.months = months;
this.days = days;
}
}update() 메서드가 days에 값을 쓰면 새로 작성된 years 와 months의 값도 메인 메모리에 기록됩니다. 그러나, 만약 Java VM이 명령어를 다음과 같이 재정렬하면 어떻게 될까요?
public void update(int years, int months, int days){
this.days = days;
this.months = months;
this.years = years;
}days 변수가 수정될 때 months와 years의 값은 여전히 메인 메모리에 기록되지만, 이번에는 새 값이 months와 years에 기록되기 전에 발생합니다. 따라서 새로운 값이 다른 스레드에 제대로 보이지 않습니다. 재정렬된 명령어의 의미가 변경되었습니다.
문제점은 위의 예제에서 update() 메서드는 years, months, days 변수의 값을 설정할 때 days 변수는 volatile로 선언되어있습니다. 일반적으로 volatile 변수에 값을 쓸 때, 그 전에 수정된 다른 변수들도 메인 메모리에 기록됩니다.
그러나 JVM이 명령어를 재정렬하여 days를 먼저 업데이트하고, 그 다음에 months와 years를 업데이트 하면 다른 스레드에서 days 값을 읽을 때 months와 years의 최신 값이 보이지 않을 수 있습니다. 이렇게 되면 변수들의 가시성 보장이 깨져서 다른 스레드에서 잘못된 값을 읽을 가능성이 있습니다.
Java에서의 해결책
Java는 이러한 문제를 해결하기 위해 메모리 배리어 (memory barrier)와 같은 메커니즘을 제공합니다. volatile 변수에 대한 접근은 메모리 배리어를 통해 명령어의 재정렬을 방지하고, 변수의 가시성을 보장합니다. volatile 변수에 대한 쓰기 작업이 발생하면, 그 이전의 모든 쓰기 작업이 메인 메모리에 커밋되고, 읽기 작업이 발생하면 이후의 모든 읽기 작업이 메인 메모리에서 다시 읽히도록 보장합니다.
추가적으로 설명하겠습니다.
명령어 재정렬 문제를 해결하기 위해, Java의 volatile 키워드는 가시성 보장 외에도 명령어 재정렬을 제어하여 스레드간의 일관성을 보장합니다. 이는 happens-before 원칙에 의해 이루어집니다.
- 쓰기가 먼저 발생한 경우 (Write - Read)
volatile변수에 쓰기 작업이 발생하기 전에 다른 변수들에 대한 모든 읽기/쓰기 작업이 완료되어야 합니다.- 만약 어떤 변수에 대한 쓰기 작업이
volatile변수에 대한 쓰기 작업 이전에 발생했다면, 그 쓰기 작업은 절대volatile변수 쓰기 이후로 재정렬되지 않습니다.
- 읽기가 먼저 발생한 경우 (Read - After - Read)
volatile변수에 대한 읽기 작업이 발생한 후에 다른 변수들에 대한 모든 읽기/쓰기 작업이 발생해야 합니다.- 만약 어떤 변수에 대한 읽기 작업이
volatile변수에 대한 읽기 작업 이후에 발생했다면, 그 읽기 작업은 절대volatile변수 읽기 이전으로 재정렬되지 않습니다.
Volatile의 한계
volatile 키워드는 변수의 가시성을 보장하지만, 모든 경우에 충분하지는 않습니다. 특히 여러 스레드가 동일한 변수를 읽고 그 값을 기반으로 새로운 값을 생성하는 경우에는 volatile만으로는 동기화문제를 해결할 수 없습니다.
경합 조건(Race Condition)
여러 스레드가 동시에 volatile 변수를 읽고, 그 값을 기반으로 새 값을 생성한 후 메인 메모리에 쓰려고 하면, 서로의 작업을 덮어쓰는 경합 조건이 발생할 수 있습니다. 이로 인해 최종 값이 잘못될 수 있습니다.
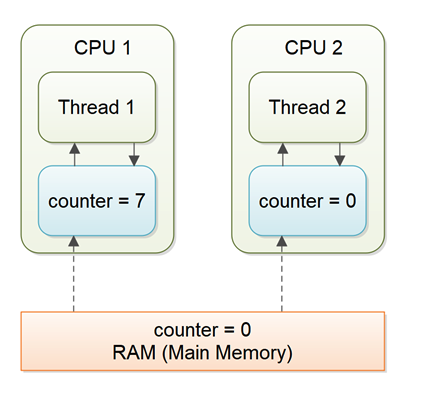
예제를 들어보면 : 두 스레드가 동시에 카운터 변수를 읽고 각각 1로 증가시킨 후 메인 메모리에 쓰지 않는 경우를 상항해보면, 두 스레드는 각각 1이라는 값을 가지고 있지만, 실제 메인 메모리에는 여전히 0이 기록되어있습니다. 이는 명백한 동기화 문제입니다.
해결책 : 이러한 문제를 해결하려면 volatile 키워드 외에도 synchronized 블록이나 java.util.concurrent.atomic 패키지의 원자 클래스 (AtomicInteger)를 사용하여 동기화를 보장해야합니다. 이를 통해 여러 스레드가 동일한 변수를 안전하게 읽고 쓰는 것을 보장할 수 있습니다.
Volatile만으로 충분한 경우는 언제인가?
- 단일 쓰기, 다중 읽기 상황:
- 한 스레드가 volatile 변수의 값을 쓰고, 다른 스레드들이 그 변수를 읽기만 하는 경우에는 volatile 키워드를 사용하는 것으로 충분합니다.
- 이 경우 volatile 키워드는 읽기 스레드가 항상 최신 값을 읽을 수 있도록 보장합니다.
- 다중 쓰기, 다중 읽기 상황:
- 여러 스레드가 동시에 변수의 값을 읽고 쓰는 경우, volatile 키워드 만으로는 충분하지 않습니다. 이 경우 원자성을 보장해야 하므로 synchronized 블록을 사용하여 읽기와 쓰기를 동기화해야합니다.
- 예를 들어 두 스레드가 같은 카운터 변수를 증가시키는 상황에서는 synchronized를 사용하여 각 스레드가 읽기 - 쓰기 연산을 완료하기 전까지 다른 스레드가 간섭하지 않도록 해야 합니다.
대안 방법
- Atomic 클래스 사용:
- java.util.concurrent.atomic 패키지에서 제공하는 원자적 데이터 타입들을 사용하여 동기화 문제를 해결할 수 있습니다. 예를 들어 AtomicLong, AtomicInteger, AtomicRefrerence 등이 있습니다.
- 이러한 클래스들은 내부적으로 CAS(compare - and - swap) 연산을 사용하여 동시성 문제를 해결합니다. 이를 통해 동기화 없이도 원자성을 보장할 수 있습니다.
- 추가적인 보장
- 비트 수와의 관계
- volatile 키워드는 32비트와 64비트 변수에서 작동이 보장됩니다. 이는 volatile 변수가 메모리에서일관된 상태를 유지하도록 합니다.
- 비트 수와의 관계
volatile 키워드는 메모리 가시성을 보장하지만, 성능 저하를 일으킬 수 있습니다. 이는 메인 메모리 접근 비용이 높고, 명령어 재정렬을 방지하기 때문입니다. 따라서 volatile 변수를 사용해야 하는 상황을 잘 이해하고, 필요한 경우에만 사용해야 합니다. 또한 성능 최적화를 위해 캐시 계층 구조와 동기화 메커니즘을 잘 이해하는 것이 중요합니다.
