
2021년 9월 3일에 작성된 문서 9번 입니다.
MongoDB 배운 내용을 정리했습니다.
배열과 서브 도큐먼트 쿼리하기
MongoDB에선 유연한 데이터 모델링을 통해 개발자가 데이터를 저장할 방법을 결정할 수 있습니다. 따라서 MongoDB에선 일반적으로 서브 도큐먼트 또는 배열로 저장합니다.

MongoDB 샘플 데이터베이스의 trips 컬렉션에서 시작하겠습니다.
- 컬렉션 도큐먼트에는
start station location과end station location필드가 있다.
* 각 필드에는 서브 도큐먼트(중첩된 도큐먼트)가 있습니다.
서브 도큐먼트를 쿼리
점 표기법(Dot notation)을 사용
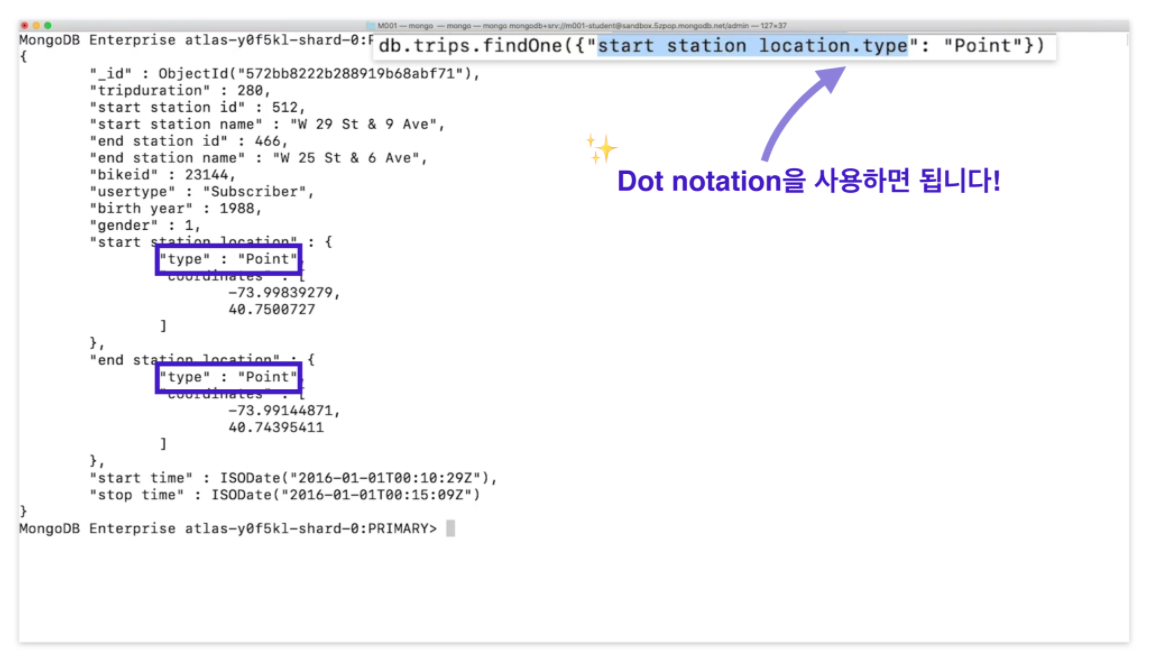
start station location.type:start station location도큐먼트 type 필드에 접근.- type이 Point인 도큐먼트가 결과로 반환

- 모든 도큐먼트는
start station location필드의type필드 값으로 point를 가지고 있다. - findOne을 사용했으므로 하나의 도큐먼트만 가져왔다.
start station location도큐먼트 최상위 필드에는 서브 도큐먼트인 객체가 있다.- 서브 도큐먼트에는
type과coordinates필드가 있다. - 두 필드의 값을 얻으려면 점 표기법을 사용.
서브 도큐먼트의 필드 이름은 최상위 필드 뒤 점으로 구분되며 전체 내용이 따옴표로 묶여 있습니다. 이 표기법은 도큐먼트에서 필요한 만큼 깊이 들어가는 데 사용할 수 있습니다.
- 서브 도큐먼트에는
- db.collection도 점을 이용하여 두 객체를 구분해 데이터베이스에서 컬렉션으로 이동.
값으로 도큐먼트가 있는 필드가 있고 해당 필드의 값으로 또 도큐먼트가 있는 경우에도 점 표기법을 사용하여 해당 계층에서 도큐먼트 자체가 아닌 필드의 값을 가져올 수 있습니다.

relationships배열 첫 번째 요소에 마크 주커버그가 있을 것이라고 가정- 배열의 첫번째 요소에서만 서브 도큐먼트를 찾는다.
- 배열의 위치를 찾고 있지만 여기에선 Bracket notation이 아닌 Dot notation을 사용하여 relationships 배열의 첫 번째를 확인합니다.
- 다음은 person 필드의 값.
- 여기서도 역시 점 표기법을 사용.
- "Zuckerberg"라는 사람을 찾고 싶으므로 그의 last name을 검색.
- 도큐먼트가 너무 크기때문에 회사의 name 필드 값만 가져오기 위해 name에 대한 프로젝션을 추가
이제 Shell에서 각 도큐먼트에 있는 relationships 배열의 첫 번째 요소에서 last name이 Zuckerberg인 사람을 검색해보겠습니다. 하나의 결과를 얻었으며 결과는 역시 Facebook입니다.

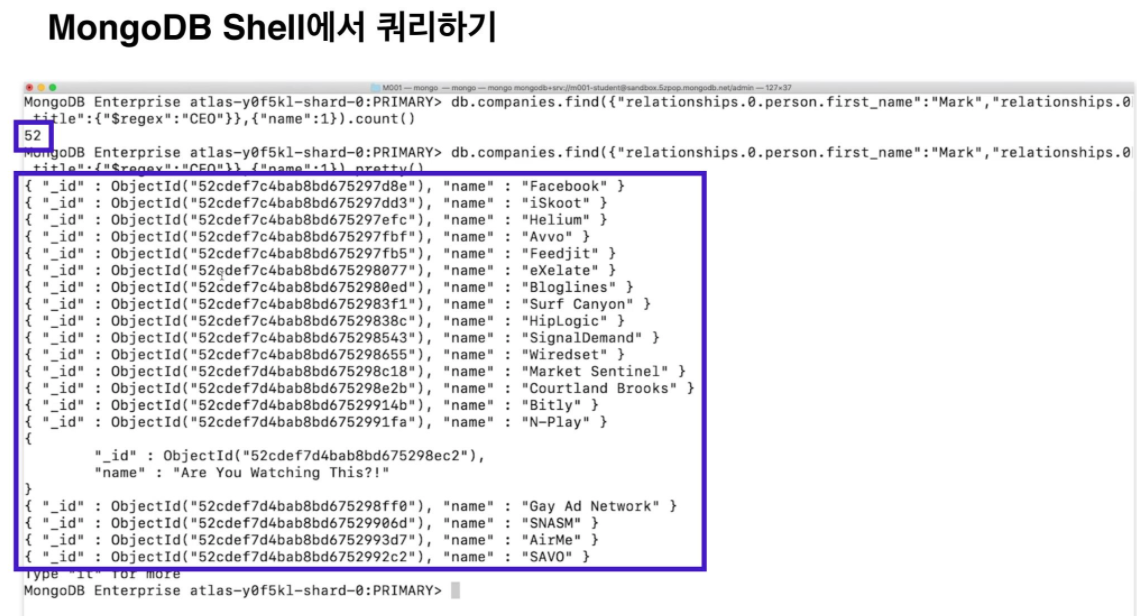
relationships 배열에서 이름이 Mark인 CEO가 몇 명인지 보겠습니다.
이를 위해 쿼리를 약간 수정해야합니다.
- last name을 first name으로 변경
- Zuckerberg를 Mark로 변경.
- 이 요소의 title에 CEO 문자열이 포함되는 조건을 추가
- 정규식 연산자인
$regex를 사용하여 일치시키려는 문자열을 지정
- 정규식 연산자인
Shell에서 쿼리를 실행해봅시다. 배열 필드의 첫번째 요소의 직함이 CEO이며 이름이 Mark인 52명을 찾았습니다.

이제 relationships 배열에 있는 Mark 중 현재 회사를 떠난 사람을 찾아봅시다.
- 모든 도큐먼트에서 배열의 첫번째 요소만이 아닌 배열 요소 전체를 검색
- 이 사람이 아직 회사에 있는지 여부를 알 수 있는 is past라는 필드가 있다.
- 회사를 떠났다면 그 값은 true.
- 배열 요소의 person 필드 아래에 있는 first name 필드 값은 Mark
elemMatch연산자를 사용해 모든 배열 요소를 살펴보고 조건과 일치하는 지 알 수 있다.- 이 경우 find 명령은 이전 두 개의 쿼리보다 훨씬 짧아진다.
Shell에서 쿼리를 실행해봅시다. is past 필드가 true이고 person.first_name 필드가 Mark 인 relationships 배열의 요소를 가진 회사 256개를 찾았습니다.

- 특정 요소 위치로 배열 필드를 쿼리하거나 서브 도큐먼트의 요소를 쿼리하기 위해 점 표기법을 사용하여 도큐먼트에서 주소를 지정
- 점 표기법을 사용하여 원하는 만큼 중첩된 도큐먼트로 이동할 수 있다.
- 배열에 점 표기법을 사용하려면 배열에서 요소의 위치를 지정해야 한다.

Written with StackEdit.
