
2021년 9월 3일에 작성된 문서 10번 입니다.
MongoDB 배운 내용을 정리했습니다.
Aggregation Framework
MongoDB에서 데이터를 파이프라인에 따라 처리할 수 있는 강력한 프레임워크
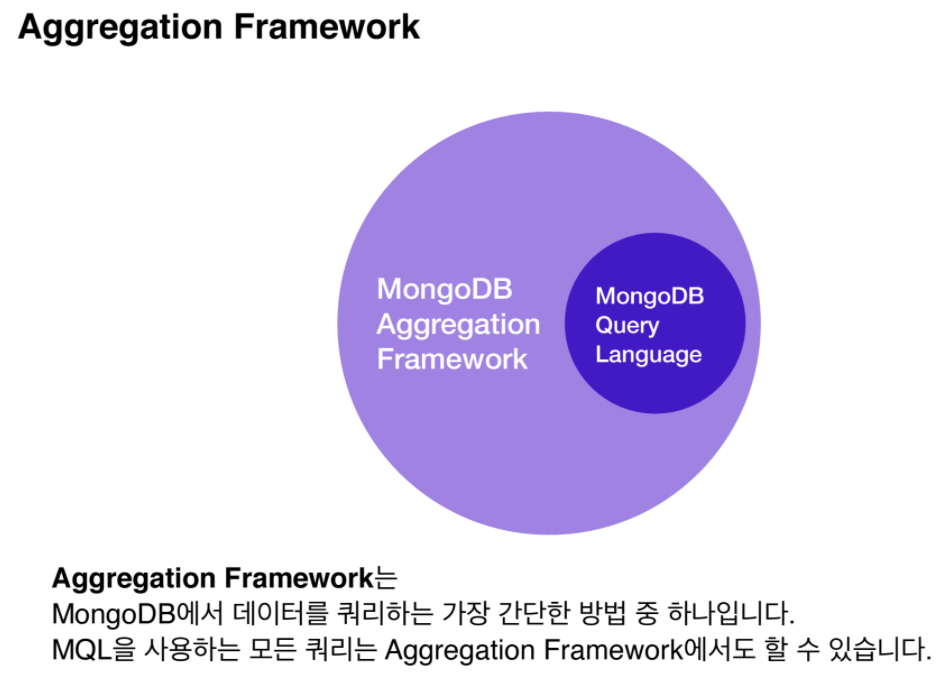
- Aggregation Framework는 MongoDB에서 데이터를 쿼리하는 가장 간단한 방법 중 하나
- MongoDB 쿼리 언어를 사용하는 모든 작업은 Aggregation Framework를 사용하여 수행 할 수도 있다.
amenities 중 하나로 Wi-Fi가 포함 된 모든 도큐먼트를 찾고 결과에 가격과 주소만 포함하려 합니다.

- Aggregation Framework에서는 find가 아닌 aggregate 명령을 사용.
- aggregate :
- 도큐먼트를 필터링 하지않고 그룹으로 데이터를 집계하거나 데이터를 수정할 수 있다.
- 데이터 찾기 및 프로젝션없이 작업을 수행하거나 계산할 수 있다.
- 대괄호를 이용해 배열을 인자로 사용.
- 파이프라인처럼 배열 요소의 순서대로 작업을 하기 때문.
그래서 해당 쿼리에선 파이프라인 작업 순서대로 amenities 배열에 Wifi가 포함되는 도큐먼트를 찾기 위해 $match 연산자를 사용하고 그렇게 찾은 도큐먼트들을 $project 연산자를 사용하여 price와 address 필드만 Projection합니다.
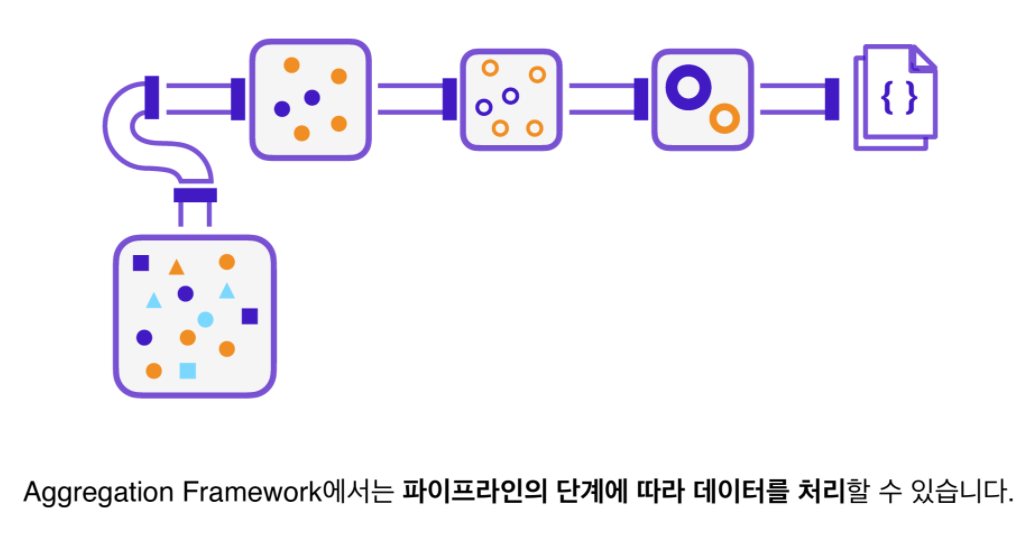
- Aggregation Framework에서 데이터를 파이프라인에 따라 처리할 수 있다.
- 각각의 처리 작업은 나열한 배열의 순서에 의해 결정
- 마지막으로 변환된 데이터가 파이프 라인의 끝에 나타남.
앞서 작성한 쿼리를 파이프라인으로 표현해보겠습니다.
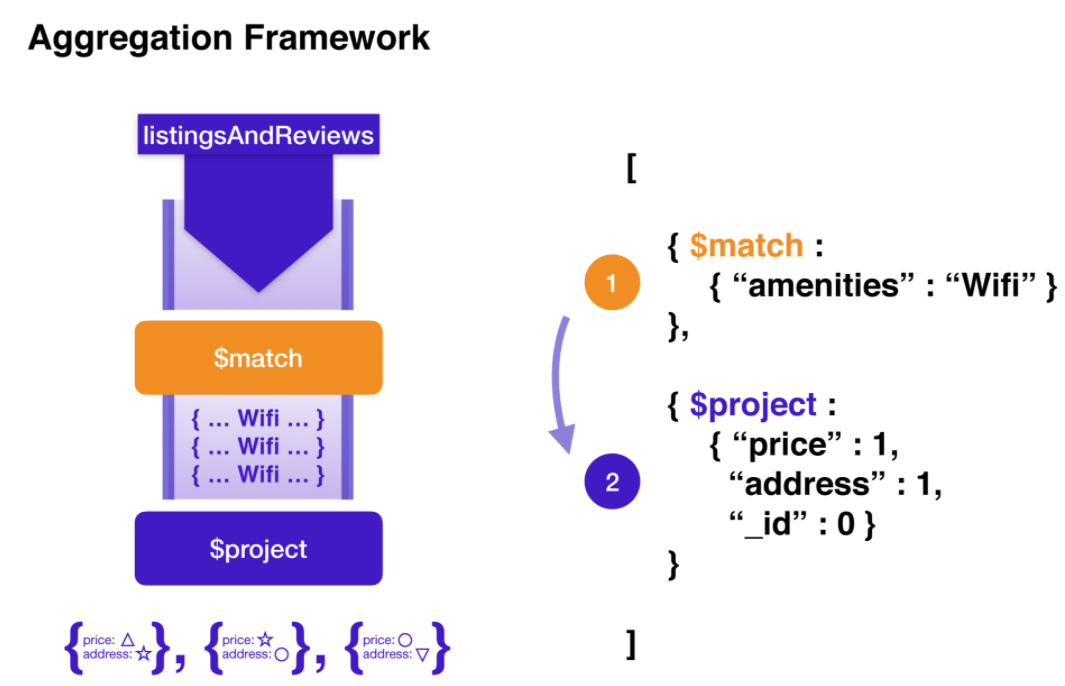
- 두개의 필터가 존재.
1.$match단계- amenities에 Wi-Fi가 없는 모든 숙소가 파이프 라인의 다음 단계를 통과하지 못하도록 필터 역할.
$project단계
- 각 도큐먼트에서 address나 price가 아닌 모든 필드를 필터링
- 첫 번째 필터보다 더 자세한 필터여야 한다.
$group 단계
- 들어온 데이터를 가지고 여러 개의 개별 저장소로 빨아들여 그룹화하는 연산자.
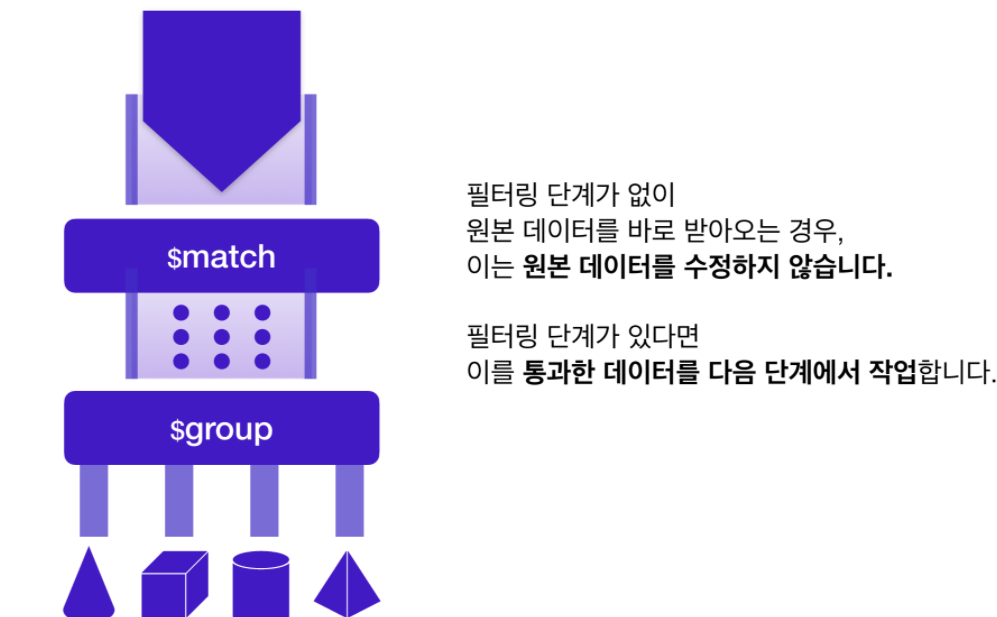
Aggregation Framework에 $match 등과 같은 필터링 단계가 없으면 데이터 요약, 계산 및 그룹화를 수행 할 때 원본 데이터를 수정하지 않는다는 점을 유의해야합니다
- 필터링 단계가 있을때에는 원본 데이터 대신 파이프 라인의 이전 단계에서 가져온 데이터로 작업.
- Aggregation Framework는 데이터를 계산, 재구성 및 재정립하는 기능을 통해 MQL의 필터링 기능을 능가하는 강력한 도구
- Aggregation 파이프 라인 데이터는 파이프 라인 내에 있어 원본 데이터를 수정하거나 변경하지 않는다.
- Aggregation Framework 문법은 나열된 순서대로 단계가 실행되는 파이프 라인의 형태. 각 단계의 이름 앞에는
- $가 있고 뒤에는 $match 또는 $sum과 같은, 해당 단계에서 실행할 여러 유형의 작업에 대한 설명.
Written with StackEdit.
