
✔️ 공부하며 배운 것
- 고객 그룹 만들기
✔️ 앞으로 To do List
- 해보고 싶은 분석의 데이터 생각하기
✔️ 오늘 활용한 자료
- 자동차 판매량 데이터
섹션 8
스타트업 작은 회사에 다니고 있는 데이터 사이언티스트라고 가정해봅시다. 상대적으로 작은 회사라 주요 도시의 큰 회사와는 경쟁할 수는 없죠.
집으로 가서 세탁물을 직접 받아와서 그것을 가져가서 세탁하여 후에 가져다주는 서비스를 제공한다. 보통 2~3일이 소요되는 됩니다.
작은 도시에서 이 네트워크를 형성하기 위해 겨냥할 수 있는 전략을 생각해봅시다.
✔️ 공부하며 배운 것
- 열을 여러 열로 분할하기
- 데이터 해석하기
✔️ 앞으로 To do List
- 해보고 싶은 분석의 데이터 생각하기
✔️ 오늘 활용한 자료
- 회사 정보 ( 매출액, 위치) 데이터, 인구 조사 데이터
섹션 7
데이터 과학자의 최소 70%에 포함되는 일은 데이터 준비하고 정리하고 노이즈 제거, 사용하기 좋게 다듬는 작업에 해당합니다.
데이터셋
그룹을 통한 사용자 지정 영역
여러 다른 판매 지역들을 어떻게 시각화 할 수 있을까?
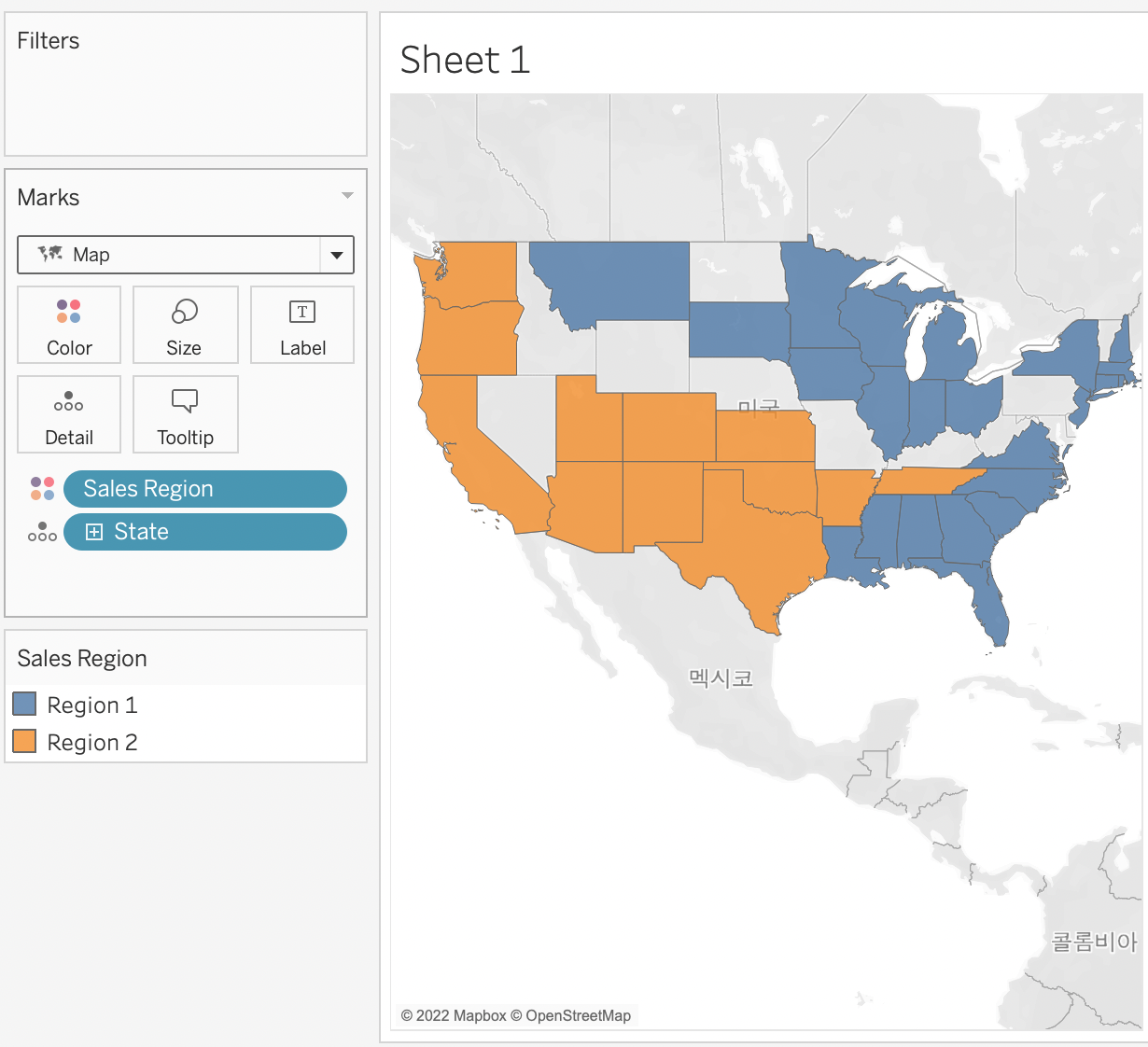
한 회사나 스타트업을 구축해서 이 것을 두 분야로 나누고 서로 비교하여 더 좋은 부분을 찾으며 성장하는 것도 좋은 방법이다.
-
도시별 평균 수익
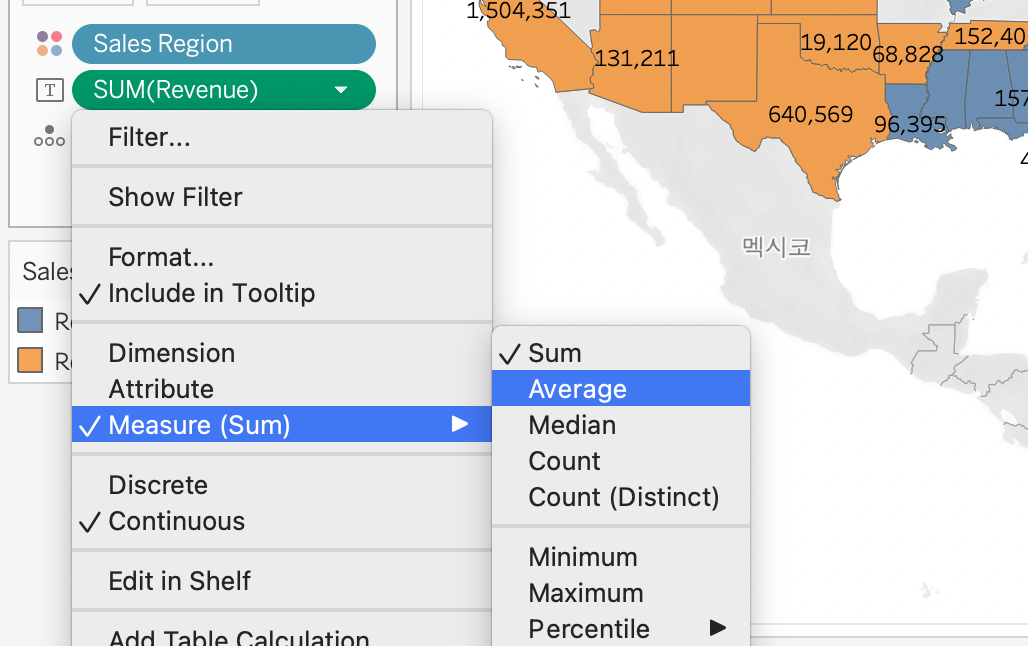
-
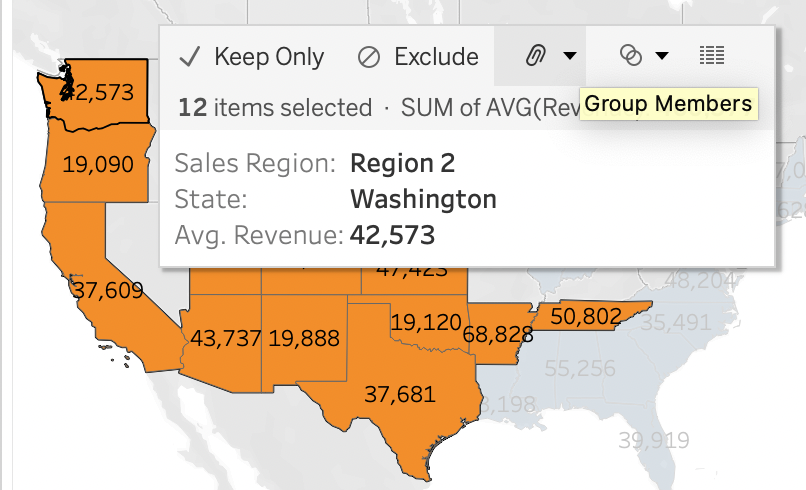
도시 그룹핑하기
주들을 ctrl 하여 드래그하고, 우클릭 > group 하여 묶어준다.
방법1
방법2
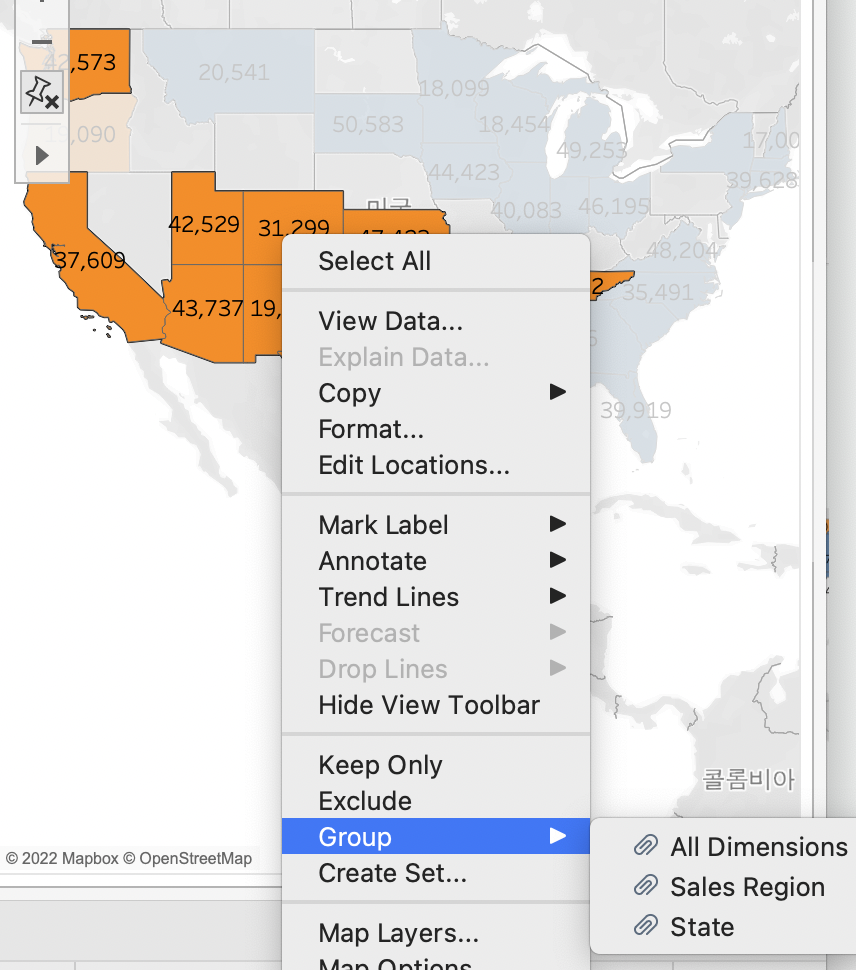
차원을 선택하여줌. All DImensions 으로,
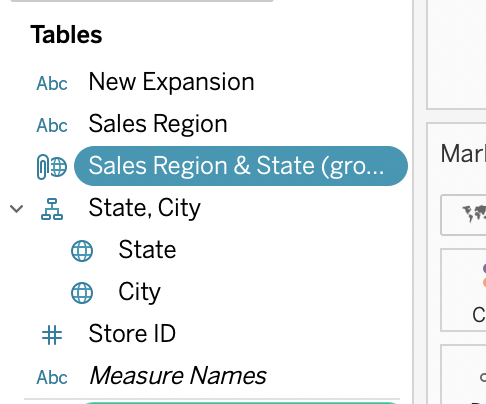
그룹 생성된 것을 확인가능함.
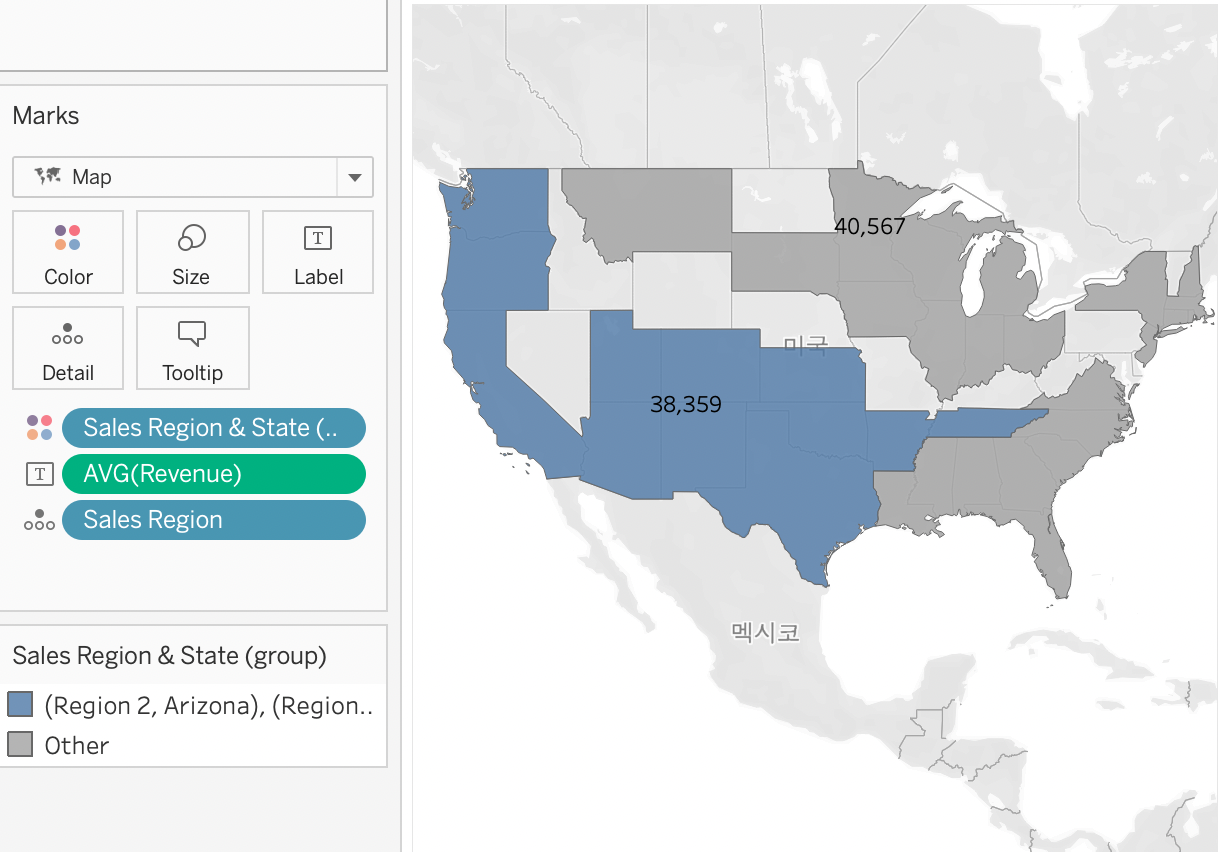
마지막으로 state 필터를 제거해주면 그룹으로만 묶인 것을 볼 수 있다.
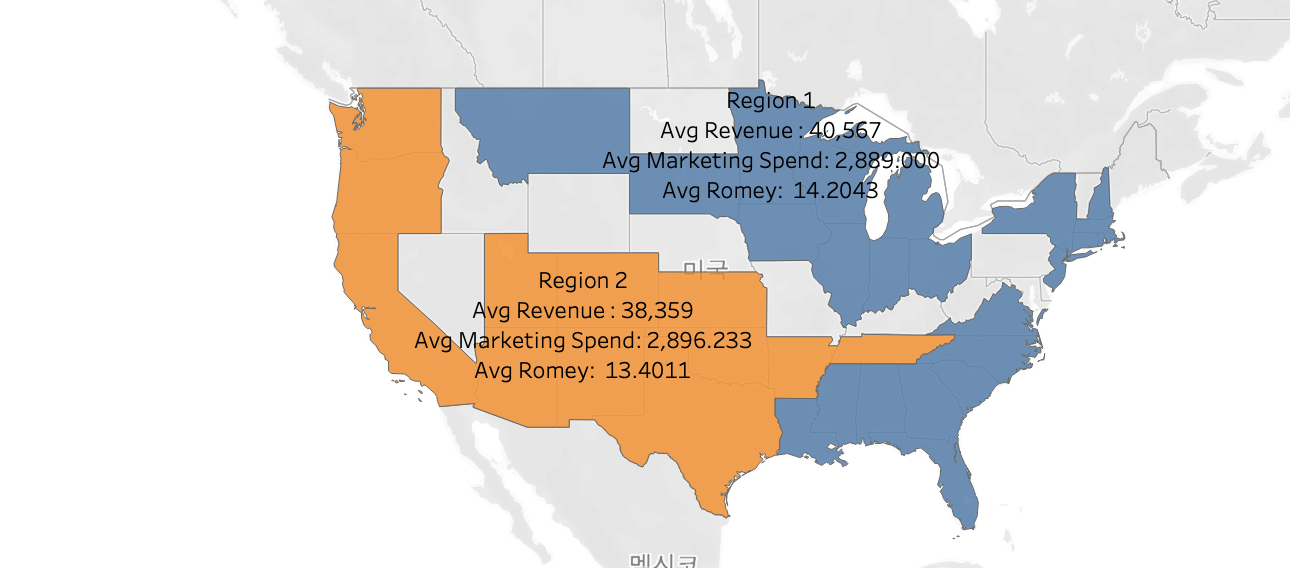
지역1은 마케팅 지출 측면에서 앞서 있다. 지역 1보다 지역 2 평균인수가 낮기 때문에 더 우수하다고 볼 수 있다.
- Romey = 수익/ 마케팅 지출 => 투자회수금
하이라이터 추가하기
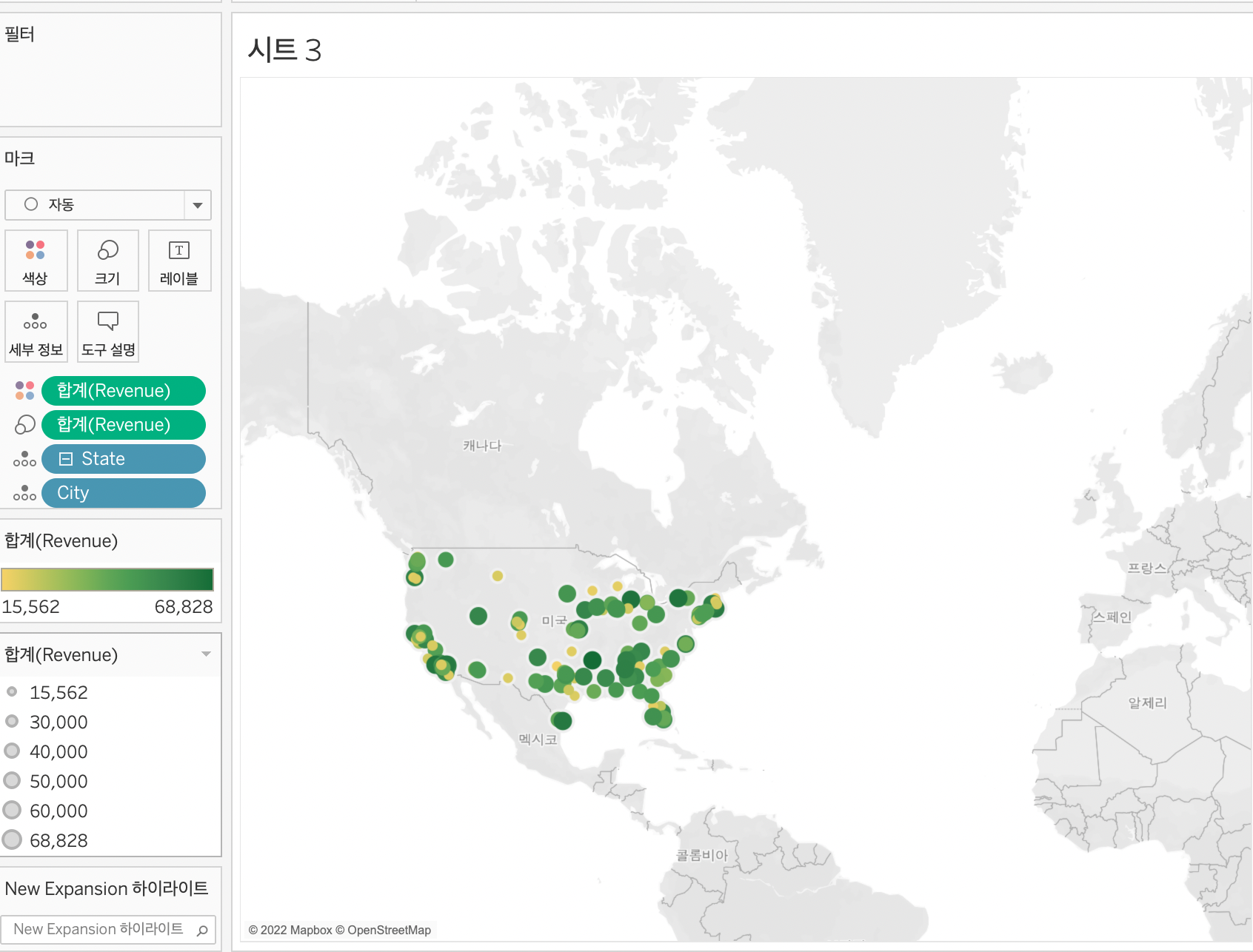
아래의 하이라이트 필터에서 변경해줄 수 있다.
클러스터링
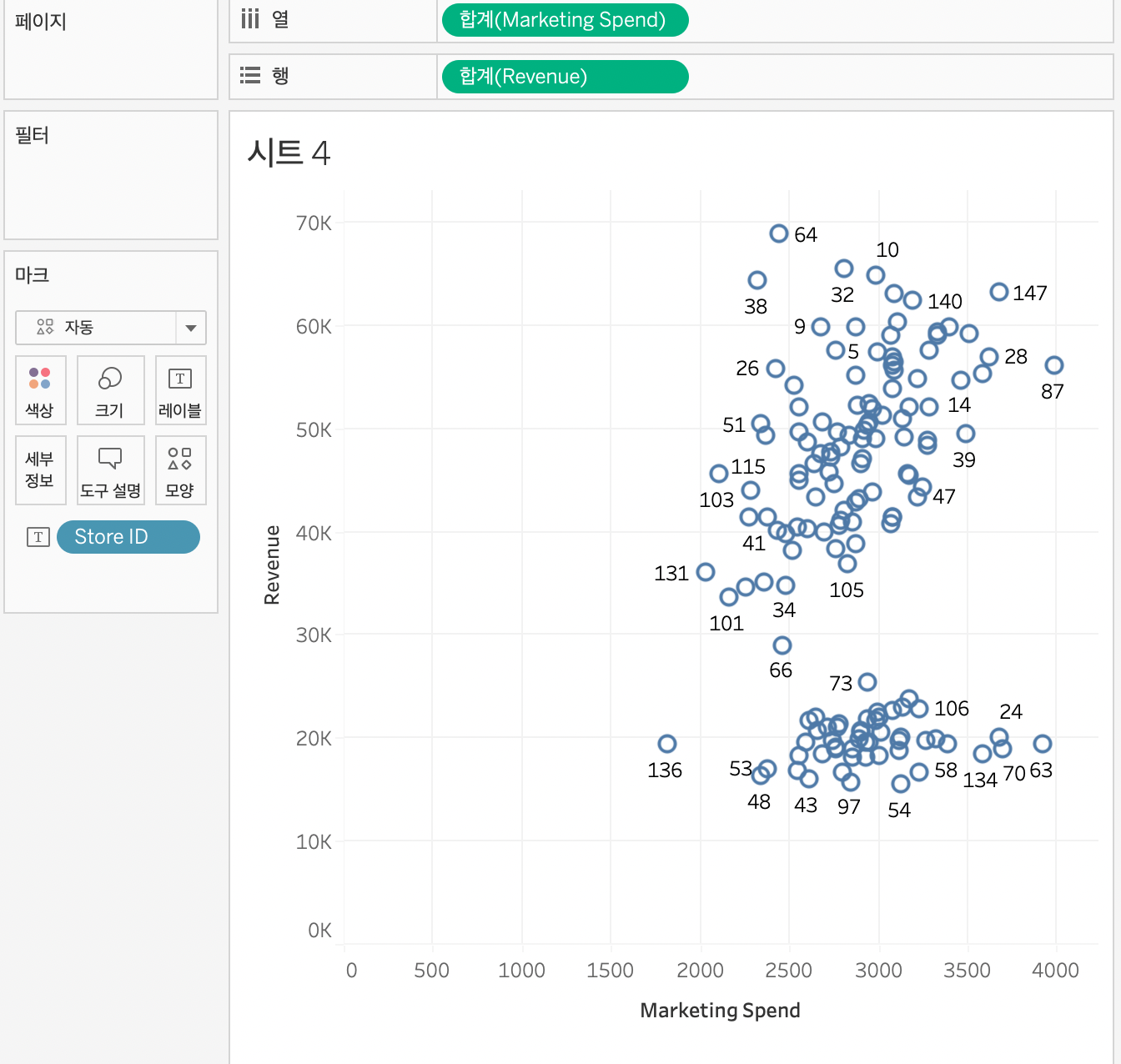
수익을 y축에 넣고 x축에 마케팅 비용을 넣고 시각화를 보니 수익이 좋은 그룹과 그렇지 못한 그룹으로 나뉘어 있는 것을 알 수 있다.
마케팅 비용이 높을 수로 수익이 높은 것은 확인 할 수 있다.
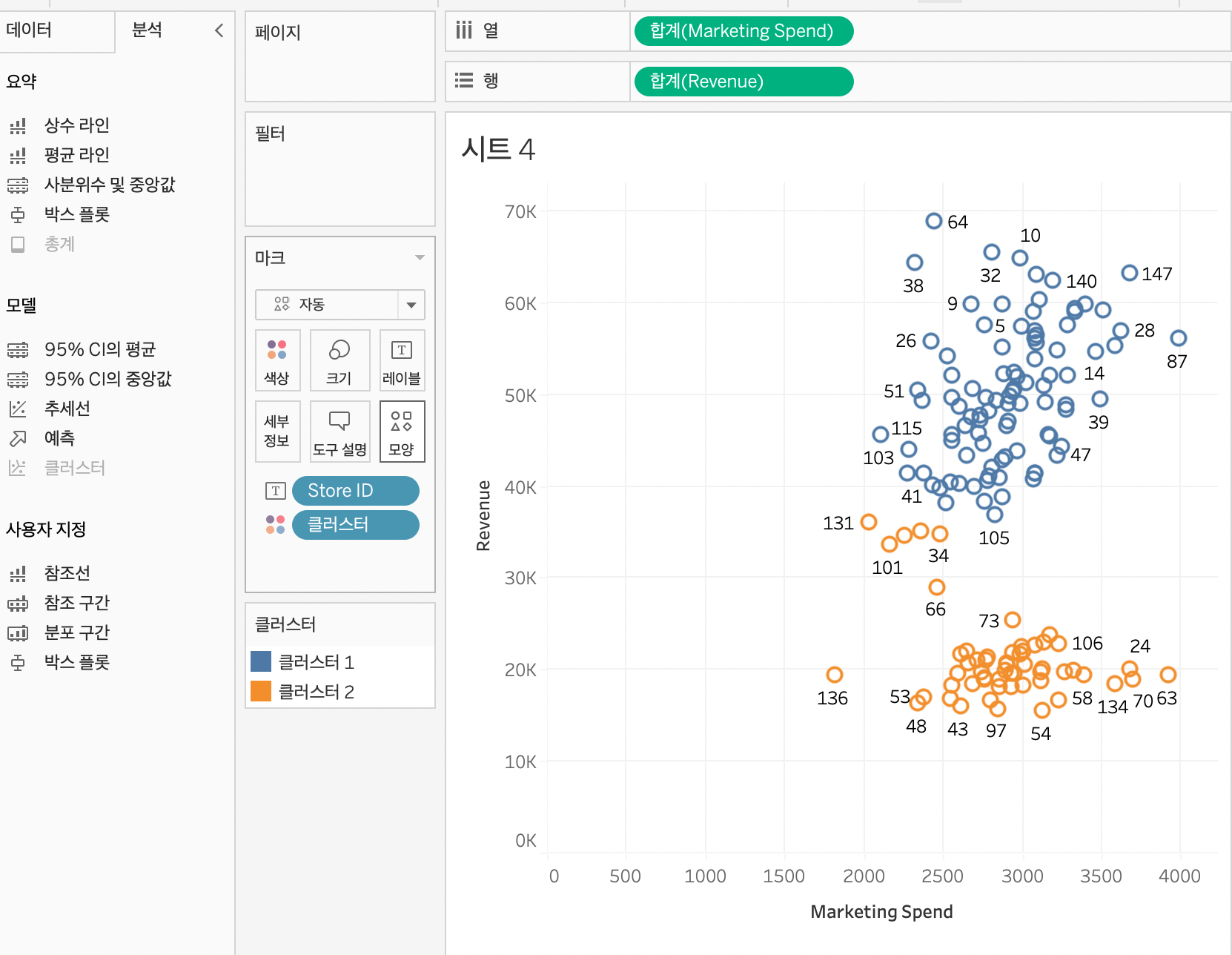
분석을 눌러 클러스터링 작업을 해주면 묶어준다.
분석 > 추세선을 추가해준다.
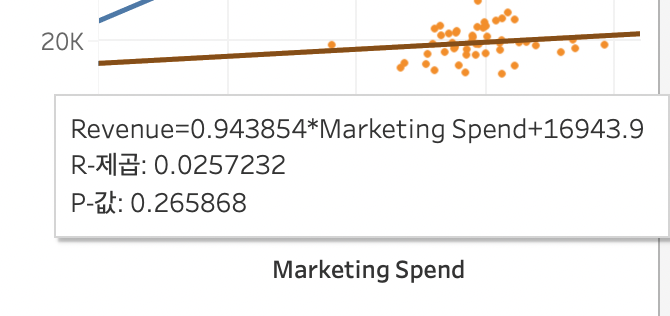
주황색을 보면, 마케팅 비용 1달러당 수익 0.94달러가 증가한다. 적자인 것을 알 수 있다.
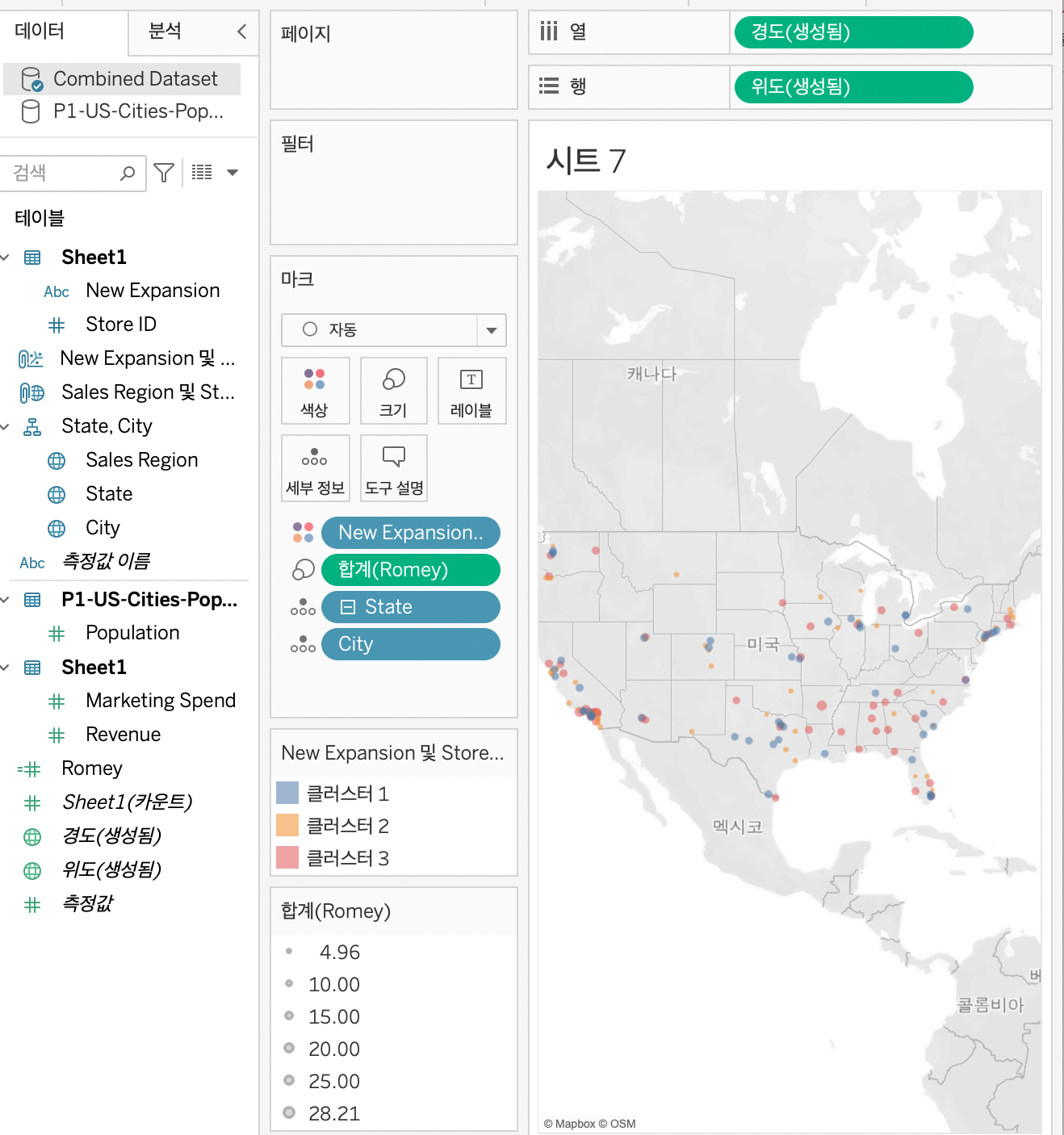
만들었던 클러스터를 왼쪽으로 드래그하면 새로 생성된다. 그것을 가지고 다른 시트에서 사용할 수 있다.
