[컴구웅 스터디 2회차] 명령어(Instruction), 컴파일과 인터프리트, CPU의 작동 원리 (feat. x86 아키텍처)
컴구웅(컴퓨터 구조 + 운영체제) 스터디
💬 Intro
이번 주차는 내가 좋아하는 키워드들(어셈블리어, 컴파일, 스택 프레임, 인터럽트)이 많이 나와서 학습하는 게 재밌었던 주간이었다. 특히나 Java 컴파일, JVM과도 지식이 연결되는 부분이 있어서 더 즐겁게 학습할 수 있었다.
이번에 학습하고 정리한 내용은 아래와 같다.
- 고급 언어로 작성된 소스 코드가 기계어로 컴파일 되는 과정
- 컴파일 방식과 인터프리트 방식의 차이, Java의 JIT 컴파일 방식
- CPU의 주요 레지스터 목록(intel x86 아키텍처 기반)
- JVM과 CPU 동작 방식의 유사성
- 스택과 스택 프레임
- 명령어 사이클(fetch, decode, execute)
- 소프트웨어 인터럽트와 하드웨어 인터럽트
- 하드웨어 인터럽트 처리 과정
❓고급 언어, 저급 언어, 어셈블리어, 기계어가 무엇인가요?
✅ 고급 언어(high-level programming language)
고급 언어는 C, Java, Kotlin, Python, Go, Rust와 같이 사람이 이해하고 작성하기 쉽게 만들어진 언어다. 컴퓨터는 고급 언어를 이해할 수 없다.
✅ 저급 언어(high-level programming language)
저급 언어는 컴퓨터가 이해하고 실행할 수 있는 언어다. 저급 언어에는 기계어(Machine Code)와 어셈블리어(Assembly Language)가 있다.
▶️ 기계어
기계어는 0과 1로만 이루어져 있어 사람이 이해할 수 없다.
// test.cpp
#include <stdio.h>
int main() {
printf("Hello Binary!");
}위의 C언어로 작성된 소스 코드(test.cpp)를 컴파일하여 기계어로 번역하면 아래와 같은 기계어로 번역된다.
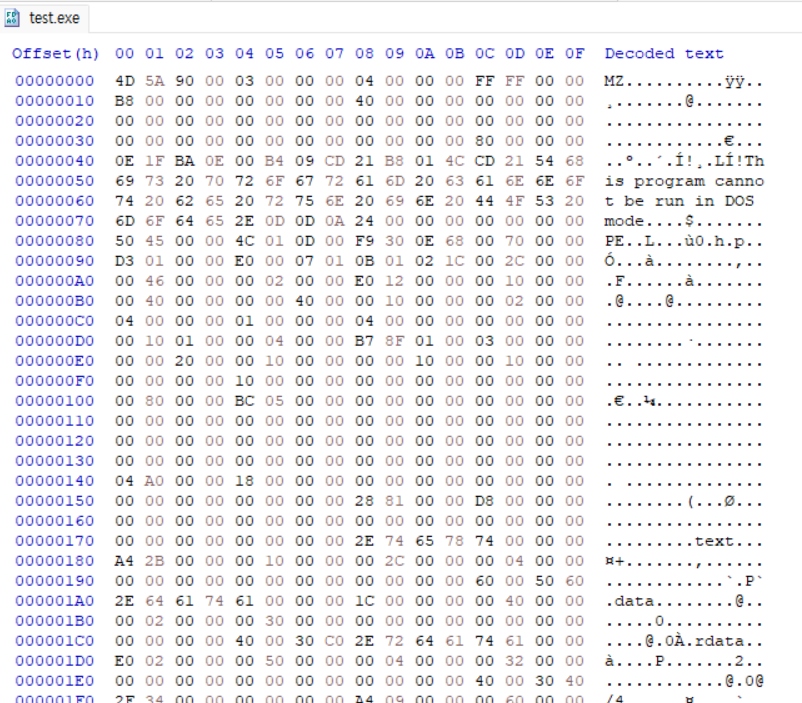
test.exe 파일의 크기는 총 40752byte고, 위 사진의 내용은 파일의 극히 일부 내용이다.
binary가 아닌 hex 값이긴 하지만 이 hex 값들을 보고 원본 소스 코드를 유추해낼 수 있는가?
기계어는 사람의 노력으로 이해할 수 있는 범주를 넘어섰다고 생각하면 된다.
TMI
소스 코드를 기계어로 번역하는 컴파일 과정 자체가 정보 손실을 일으키고, 최적화 과정에서 코드를 변형시키기 때문에 완벽한 디컴파일이 불가능하다. IDA 같은 Hex-Rays 도구를 이용하면 그럴듯하게 디컴파일 해주기는 한다.
▶️ 어셈블리어
어셈블리어는 기계어와 다른 언어가 아니다. 기계어를 노력하면 읽을만한 정도로 한 단계 추상화한 언어다.
| 어셈블리어 | hex | binary |
|---|---|---|
ADD eax, ebx | 01 D8 | 00000001 11011000 |
ADD [eax], ebx | 01 18 | 00000001 00011000 |
그래도 여전히 가독성이 매우 떨어진다.
❓컴파일 언어와 인터프리터 언어의 차이는 무엇인가요? 장단점은 무엇인가요?
✅ 컴파일 방식과 인터프리트 방식의 차이
개발자들이 고급 언어로 작성한 소스 코드를 실행하기 위해서는 결국 실행 가능한 기계어 파일(ex. .exe 파일, .out 파일, ELF executable 포맷 파일)로 번역되어야 한다.
(이하 고급 언어로 작성한 소스 코드 = 소스 코드, 실행 가능한 기계어 = 기계어로 요약해서 표현한다.)
여기서 소스 코드를 기계어로 번역하여 실행하는 방식에는 컴파일(Compile) 방식과 인터프리트(Interpret) 방식이 있다.
헷갈리면 안되는 것이 두 방식 모두 소스 코드를 기계어로 번역한다는 점은 동일하다.
런타임 이전에 고급 언어의 소스 코드 전체를 통째로 전부 기계어로 번역하느냐, 실행에 필요한 일부 소스 코드만 그때그때 번역하느냐와 같이 기계어로 번역하는 시점의 차이만 존재한다.
✅ 컴파일 언어와 인터프리터 언어
작성한 소스 코드 전체를 실행 가능한 파일(Executable File)로 번역하는 과정을 컴파일이라고 부르고, 컴파일을 수행해 주는 도구를 컴파일러(Compiler)라고 부른다.
별도의 실행 파일 없이 인터프리터 프로그램을 이용해서 실행 중간중간 소스 코드를 기계어로 번역하는 방식을 인터프리트 방식이라 부른다. 인터프리터(Interpreter)는 소스 코드를 짧은 의미 있는 구문 단위(보통 한 줄)로 기계어로 번역하여 실행해주는 도구다.
컴파일 방식으로 프로그램을 실행하는 언어를 컴파일 언어, 인터프리트 방식으로 프로그램을 실행하는 언어를 인터프리터 언어라고 부른다.
컴파일 언어와 인터프리어 언어의 차이를 표로 요약하면 다음과 같다.
| 구분 | 컴파일 언어 | 인터프리터 언어 |
|---|---|---|
| 실행 방식 | 소스 코드를 한 번에 기계어로 번역한 뒤 실행한다. | 런타임에 소스 코드를 짧은 의미 있는 구문 단위로 해석해서 실행한다. |
| 기계어로 번역 시점 | 실행 전 (Compile Time) | 실행 중간 (Run Time) |
| 결과물 | 실행 가능한 파일을 생성한다. | 별도 실행 파일을 만들지 않는다. 인터프리터 프로그램(ex. python 인터프리터)을 이용해서 그때그때 기계어로 번역하고 바로 실행한다. |
| 개발, 테스트 속도 | 컴파일을 기다려야 해서 배포 속도, 테스트 속도가 느릴 수 있다. | 작성한 코드를 바로 실행할 수 있어 빠르다. |
| 실행 속도 | 미리 번역된 기계어를 실행하므로 빠르다. | 런타임에 번역하므로 느리다. |
| 오류 발견 시점 | 컴파일 시점에 발견하므로 빠르다. | 실행 도중 발견하므로 늦다. ex. python에서 x = "hello" + 5는 실행되기 전까지 오류가 발생하지 않는다. |
| 대표 언어 | C, C++, Go, Rust 등 | Python, JavaScript, Ruby 등 |
여기서 조금 더 디테일하게 들어가보자.
현대의 인터프리트 방식은 컴파일 방식과 혼용되어 사용되고 있다. 소스 코드를 실행 시기에 바로 기계어로 번역하는 방식은 실행 속도가 매우 느리므로, 바이트코드라는 중간 단계의 번역을 먼저 수행하는 방식을 사용한다.
📌 순수 인터프리트 방식
- 소스 코드 -> 기계어
- 런타임에 소스 코드를 기계어로 번역하는 방식
- ex. BASIC
📌 바이트코드 인터프리트 방식
- 소스 코드 -> 바이트코드 -> 기계어
- 실행 전 모든 소스 코드를 바이트코드(bytecode)라는 중간 단계 번역 파일로 변환해놓고, 런타임에 바이트코드만 인터프리터가 기계어로 번역해서 실행한다.
- ex. Python의 CPython, Ruby, Lua
📌 JIT(Just-In-Time) 컴파일 방식
- 인터프리트 방식과 컴파일 방식을 혼용한 방식이다.
- 실행 전 모든 소스 코드를 바이트코드로 변환한다.
- 런타임에 인터프리트 방식으로 실행하다가, 자주 실행되는 바이트코드만 기계어로 컴파일 해놓고 캐싱해서 재사용한다.
- 그래서 시간이 지날수록 실행 속도가 점점 빨라진다.
- ex. Java의 HotSpot JVM , JavaScript V8, Python의 PyPy
✅ 소스 코드가 기계어로 컴파일 되는 과정
컴파일러의 기본 기능은 소스 코드 전체를 훑어보며 문법적인 오류가 없는지 확인하고 문제가 없다면 기계어로 번역하는 일을 한다.
아래의 7단계로 나누어진 컴파일 단계는 Compilers: Principles, Techniques, and Tools (일명 드래곤북)에서 제시하는 일반적인 이론이다. 현대의 대부분 언어의 컴파일러에 적용되는 내용이니 알아두면 좋다.
| 단계 | 설명 | 예시 |
|---|---|---|
| 1. 전처리 (Preprocessing) | 소스 코드에서 #include, #define 같은 전처리 지시문을 처리한다. | #include <stdio.h>를 실제 소스 코드 파일로 대체한다. |
| 2. 어휘 분석 (Lexical Analysis) | 소스 코드를 토큰 단위로 분리한다. | int a = 3; → int, a, =, 3, ; |
| 3. 구문 분석 (Syntax Analysis) | 문법 규칙(Grammer)에 맞는지 확인하고 구문 트리(Parse Tree)를 생성한다. | int a = 3;이 문법적으로 올바른지 확인한다. int b = "hello"도 문법적으로는 올바르므로 구분 분석 단계를 통과한다. |
| 4. 의미 분석 (Semantic Analysis) | 변수 선언, 타입 일치, 스코프 등 의미적 오류를 확인한다. | int a = "hello"; -> 타입 오류 처리 |
| 5. 중간 코드 생성 (IR Generation) | 소스코드를 기계어와 유사한 중간 표현(IR: Intermediate Representation)으로 변환한다. | int a = b + c * d; -> t1 = c * d; t2 = b + t1; a = t2 |
| 6. 중간 코드 최적화(IR Optimization) | 중간 표현을 기반으로 성능 최적화할 수 있는 부분들을 최적화한다. | - Dead Code Elimination: 사용되지 않는 코드 제거 - Contant Folding: int x = 3 + 5 -> int x = 8- Strength Reduction: x*2 -> x<<1- Common Subexpression Elimination: 중복된 계산 제거 - Loop Invariant Code Motion: 반복문 외부로 불변 코드 이동 |
| 7. 코드 생성 (Code Generation) | 타겟 머신 아키텍처에 맞는 기계어(binary)를 생성한다. | .exe, .out 같은 실행 가능한 파일을 만든다. |
컴파일러에 따라 사용하는 라이브러리에 보안 문제가 없는지 검사하는 등의 추가적 기능을 제공해주기도 한다.
❓연산 코드가 무엇인가요? 어떤 종류가 있나요?
명령어(Instruction)는 연산 코드(Operation Code, Opcode)와 오퍼랜드(Operand)로 구성되어 있다.
연산 코드는 "어떤 연산을 수행할 것인지"를 결정하고 오퍼랜드는 "연산에 사용될 값 또는 메모리 주소"를 결정한다.
✅ 연산 코드와 오퍼랜드의 사용 예시
x86-64를 기준으로 사용되는 연산 코드와 오퍼랜드 사용 예시를 알아보자.
▶️ 데이터 전송
| 연산 코드 | 설명 | 예시 | 의미 해석 |
|---|---|---|---|
mov | 데이터를 복사한다. | mov rax, rbx | rbx 값을 rax로 복사한다. |
push | 값을 스택에 저장한다. | push rax | rsp의 값을 8바이트 감소시키고, rax 값을 스택에 저장한다. 스택 프레임 영역이 확장된다. |
pop | 스택에서 값을 꺼낸다. | pop rbx | rsp가 가리키고 있는 주소에 저장된 값을 rbx에 저장하고, rsp의 값을 8바이트 증가시킨다. 스택 프레임 영역이 축소된다. |
lea | 주소를 계산하여 레지스터에 저장한다. | lea rax, [rbx+8] | rbx + 8의 주소를 rax에 저장한다. |
xchg | 두 오퍼랜드의 값을 교환한다. | xchg rax, rbx | rax와 rbx 값을 교환한다. |
▶️ 산술/논리 연산
| 연산 코드 | 설명 | 예시 | 의미 해석 |
|---|---|---|---|
add | 덧셈 | add rax, rbx | rax = rax + rbx |
sub | 뺄셈 | sub rax, rbx | rax = rax - rbx |
mul | 부호 없는 곱셈 (rax 기반) | mul rbx | rax = rax * rbx. rax와 rbx를 양수로 취급하여 곱셈한다. |
imul | 부호 있는 곱셈 | imul rax, rbx, 5 | rax = rbx * 5. 2의 보수 표현을 고려해서 부호를 고려한 곱셈 결과를 저장한다. |
div | 부호 없는 나눗셈 (rax ÷ 오퍼랜드) | div rbx | 몫은 rax, 나머지는 rdx에 저장한다. |
and | 비트 AND 연산 | and rax, rbx | rax = rax & rbx |
or | 비트 OR 연산 | or rax, rbx | rax = rax | rbx |
xor | 비트 XOR 연산 | xor rax, rbx | rax = rax ^ rbx |
not | 전체 비트 반전 | not rax | rax = ~rax |
shl | 왼쪽으로 Logical Shift | shl rax, 1 | rax를 왼쪽으로 1비트 이동 |
sal | 왼쪽으로 Arithmetic Shift | sal rax, 1 | rax를 부호를 유지한 채로 왼쪽으로 1비트 이동 |
shr | 오른쪽으로 Logical Shift | shr rax, 1 | rax를 오른쪽으로 1비트 이동 |
sar | 오른쪽으로 Arithmetic Shift | sar rax, 1 | rax를 부호를 유지한 채로 오른쪽으로 1비트 이동 |
▶️ 제어 흐름 변경
| 연산 코드 | 설명 | 예시 | 의미 해석 |
|---|---|---|---|
jmp | 지정한 주소부터 명령어를 실행하도록 한다. | jmp label | PC(program counter)를 label의 주소로 갱신한다. |
call | 서브루틴(함수) 호출 | call function | function이라는 이름의 함수 실행을 마친 후 복귀할 주소를 스택에 저장한다. 그리고 PC를 function 함수의 시작 주소로 갱신한다. |
ret | 서브루틴(함수) 복귀 | ret | 스택에 저장된 복귀 주소(call 호출 시 저장했던 주소)로 돌아간다. |
cmp | 두 값을 비교하고 플래그 설정 | cmp rax, rbx | rax - rbx 결과를 플래그에 반영한다. |
▶️ 입출력 제어
x86-64에서는 하드웨어 I/O를 직접 다루기 위해 in, out 명령어를 사용한다.
| 연산 코드 (Opcode) | 설명 | 간단한 예시 | 예시에 대한 자세한 설명 |
|---|---|---|---|
in | 포트에서 데이터를 읽기(read) | in al, 0x60 | 0x60 포트를 통해 al 레지스터로 값을 읽어 들인다. |
out | 포트로 데이터를 출력(write) | out 0x60, al | al 레지스터 값을 0x60 포트로 출력한다. |
int | 소프트웨어 인터럽트를 발생시킨다. | int 0x80 | 0x80은 시스템 콜 요청을 의미한다. 시스템 콜을 요청하기 위한 인터럽트를 발생시킨 것이다. 어떤 시스템 콜을 호출할지에 대한 정보는 범용 레지스터에 저장해놓고 호출한다. |
syscall | 시스템 콜 호출 | syscall | |
hlt | CPU를 정지(halt) 상태로 만든다. | hlt | CPU를 멈춘다. 인터럽트가 발생하면 깨어난다. cli, sti를 통해 인터럽트 금지/허용을 설정할 수 있다. |
📌 int 0x80과 syscall
int 0x80과syscall모두 시스템 콜 요청을 보내는 방식은 동일하다. 하지만 지금은 리눅스에서int 0x80대신syscall을 사용한다.int 0x80은 소프트웨어 인터럽트를 발생시키는 방식이다 보니 복잡한 인터럽트 핸들링 절차를 수행해야 한다.- 유저 모드 -> 커널 모드 변환
- Interrupt Descriptor Table 접근
- Privilege Level 변경 등등
syscall은 x86-64에서 CPU가 시스템 콜을 빠르게 처리할 수 있게 하기 위해 만들어진 전용 명령어다.- 상태 저장을 최소화하고,
- 시스템 콜 핸들러로 빠르게 진입하게 설계되어 있다.
- 따라서
int 0x80보다 훨씬 더 가볍고 빠르게 수행된다.
✅ 오퍼랜드의 주소 지정 방식
| 주소 지정 방식(Addressing Mode) | 설명 | 예시 | 의미 해석 |
|---|---|---|---|
| 즉시(Immediate) | 명령어 안에 사용할 데이터 값을 명시한다. | mov rax, 5 | rax = 5. 5라는 값을 바로 rax에 복사한다. |
| 직접(Direct) | 명령어 안에 사용할 주소를 명시한다. | mov rax, [0x1000] | rax = RAM[0x1000]. 0x1000 주소에 저장된 값을 rax에 복사한다. |
| 레지스터(Register) | 레지스터에 저장된 값을 그대로 사용한다. | mov rax, rbx | rax = rbx. rbx에 저장된 값을 rax에 복사한다. |
| 간접(Indirect) | 명령어에서 사용할 데이터는 주소의 주소에 포함된다. | mov rax, [[0x200]], move rax, [rbx] | rax = RAM[RAM[0x200]]. 0x200 주소에 어떤 유효 주소 (ex. 0x300)가 저장되어 있다. 그 유효 주소에 저장된 값을 rax에 복사한다. |
| 레지스터 간접(Register Indirect) | 간접 주소 지정 방식의 일종이다. 레지스터 안에 들어있는 값을 주소로 해석해서 그 주소를 통해 데이터를 읽거나 쓴다. | mov rax, [rbx] | rax = RAM[rbx]. rbx에는 유효 주소가 저장되어있다. 그 주소에 저장된 데이터 값을 rax에 복사한다. |
| 기준 주소 + 오프셋(Base + Offset) | 레지스터 + 상수 오프셋 조합을 사용하여 주소를 지정한다. | mov rax, [rbx+8] | rax = RAM[rbx+8]. rbx + 8 주소에 저장된 값을 rax에 복사한다. |
❓레지스터의 종류와 각 역할을 설명해 주세요.
✅ 레지스터 종류
x86-64를 기준으로 실제 사용되는 레지스터의 이름과 역할을 알아보자.
▶️ 프로그램 카운터
프로그램 카운터(PC: Program Counter)는 현재 실행할 명령어의 주소(메모리 주소)를 저장한다. 프로그램 카운터를 명령어 포인터(IP: Instruction Pointer)라고 부르는 CPU도 있다.
| CPU 아키텍처 | 프로그램 카운터 이름 |
|---|---|
| ARM, RISC-V, MIPS | PC (Program Counter) |
| x86 (32비트) | EIP (Extended Instruction Pointer) |
| x86-64 (64비트) | RIP (Register Instruction Pointer) |
📌 JVM PC Register와 CPU PC Register의 차이
출처: https://www.geeksforgeeks.org/how-many-types-of-memory-areas-are-allocated-by-jvm/
출처: https://www.learncomputerscienceonline.com/what-are-cpu-registers/
CPU는 메모리에 올라온 기계어를 실행하는 역할을 한다.
JVM은 메모리에 올라온 바이트코드를 실행하는 역할을 한다.
CPU는 코어가 실행할 (기계어) 명령어의 주소를 PC 레지스터(CPU 내 하드웨어 레지스터)에 기록하고, JVM은 쓰레드가 실행할 (바이트코드) 명령어의 주소를 JVM 내 쓰레드 별 PC 레지스터 공간에 기록한다. JVM 내 PC 레지스터는 하드웨어 레지스터가 아니라 메모리 내의 일부 공간을 사용하는 것이다. 그냥 CPU의 PC 레지스터에서 이름을 차용해온 것이다.
"Write Once, Run Anywhere" (WORA)
WORA는 한 번 작성한 코드를 어떤 운영체제, 어떤 하드웨어에서도 실행할 수 있게 하겠다는 Java의 핵심 철학이다.
이런 철학을 달성하기 위해 각 CPU 아키텍처마다 다른 명령어 집합을 추상화하고, 어떤 하드웨어 환경에서도 바이트코드를 실행할 수 있는 가상의 실행 방법이 필요했을 것이다. 그 과정에서 CPU 동작 방식을 소프트웨어로 흉내내는 것은 어쩔 수 없는 선택이었을 것 같다.
그래서 어떻게 보면 JVM은 소프트웨어로 구현된 CPU 역할을 한다고 볼 수 있다.
📌JVM vs CPU
JVM의 구성 요소가 CPU의 어떤 구성 요소에 대응되는지 표로 정리해보았다.
| 역할 | JVM 구성 요소 | CPU 구성 요소 |
|---|---|---|
| 명령어 집합 | 바이트코드(Bytecode) | 기계어(Machine Code) |
| 명령어가 로드되는 공간 | 바이트코드(.class 파일)가 Method Area에 로드됨 | 기계어가 Text 영역에 로드됨 |
| PC | 쓰레드 별 PC 레지스터 | 코어 별 PC 레지스터 |
| PC에 저장되는 값 | 쓰레드가 실행할 바이트코드 명령어의 주소 | 코어가 실행할 기계어 명령어의 주소 |
| 메모리 구조 | JVM Heap, Method Area, Stack | RAM에서의 전통적인 Heap, Text, Stack 등 논리 영역 |
| 호출 스택 관리 | Java Stack Frame | 스택 포인터 기반 Call Stack |
▶️ 명령어 레지스터
명령어 레지스터(IR: Instruction Register)는 현재 실행할 명령어의 요약 정보를 저장하는 레지스터다.
📌 CISC에는 IR이 없다
RISC(Reduced Instruction Set Computer) 유형의 아키텍처(ex. MIPS, RISC-V)에서는 명령어와 IR이 둘 다 고정된 크기(4 byte)로 존재한다. 그래서 IR 하나에 전체 명령어를 통째로 저장하고 decode하는 방식이 가능하다.
하지만 CISC(Complex Instruction Set Computer) 유형의 아키텍처에서는 조금 다르다. x86-64 아키텍처의 경우 명령어가 1~15byte 가변길이면서 용량이 크기 때문에 32bit IR만으로는 명령어를 저장할 수 없다. 그래서 IR이 따로 존재하지 않고, IR를 대체하는 여러 레지스터와 버퍼가 명령어의 정보를 나누어 관리한다.
▶️ 메모리 주소 레지스터(MAR)와 메모리 데이터 레지스터(MDR)
메모리 주소 레지스터(MAR: Memory Address Register)는 메모리의 주소를 저장하는 레지스터다. CPU가 메모리에서 읽거나 쓸 데이터가 있는 메모리 주소를 잠시 저장하기 위해 사용된다.
메모리 데이터 레지스터(MDR: Memory Data Register)는 MAR 주소에 있는 그 읽거나 써야하는 데이터를 잠시 저장하기 위해 사용되는 레지스터다.
📌 메모리 읽기 과정
1. CPU가 mov rax, [0x1000] 명령어를 실행하려 한다.
2. 메모리 주소 0x1000을 MAR에 저장한다.
3. 주소 버스를 통해 RAM에 0X1000을 전달한다.
4. Control Unit이 제어 버스를 통해 READ 신호를 RAM에 전달한다.
5. RAM은 주소 버스로 전달 받은 0x1000 주소에 저장된 값을 읽어, 데이터 버스로 전달한다.
6. 데이터 버스를 통해 전달된 값이 MDR에 저장된다.
7. MDR에 저장된 값을 rax에 복사한다.
▶️ 범용 레지스터
| 레지스터 | 비트수 | 알파벳 의미 | 설명 |
|---|---|---|---|
rax / eax / ax / ah al | 64bit / 32bit / 16bit / 8bit | a = accumulator | 주로 ALU의 산술 연산 결과를 저장한다. |
rbx / ebx / bx / bh bl | 64bit / 32bit / 16bit / 8bit | b = base address | 주로 주소 계산에 사용한다. |
rcx / ecx / cx / ch cl | 64bit / 32bit / 16bit / 8bit | c = counter | 주로 반복문에서 반복 횟수를 저장할 때 사용한다. |
rdx / edx / dx / dh dl | 64bit / 32bit / 16bit / 8bit | d = data | 주로 산술 연산에 사용되는 데이터를 저장한다. |
범용 레지스터의 실제 사용을 예시로 들어보겠다.
a = b + c; 소스 코드를 기계어로 번역할 때 컴파일러는 보통 b와 c의 값은 ecx, edx에 저장하고, 둘을 더한 결과는 eax에 저장하도록 번역한다. 보통의 상황에 그렇다는 것이고, 레지스터의 사용은 최적화 방식에 따라 조금씩 달라질 수 있다.
범용 레지스터들은 자주 사용되는 기본 용도는 있지만, 자유롭게 어떤 용도로든 사용할 수 있다.
▶️ 플래그 레지스터
플래그 레지스터는 CPU 명령어 실행 결과나 상태를 나타내는 여러 비트를 저장하는 레지스터다. x86에서는 플래그 레지스터를 EFLAGS라 부른다.
| 플래그 이름 | 약어 | 비트 위치 (EFLAGS 기준) | 의미 / 설명 |
|---|---|---|---|
| Carry Flag | CF | 0번 비트 | 덧셈/뺄셈 명령어 수행 후 자리올림 또는 자리내림이 발생하면 1로 설정한다. |
| Parity Flag | PF | 2번 비트 | 연산 결과의 하위 8비트에서 1의 개수가 짝수면 1로 설정한다. |
| Zero Flag | ZF | 6번 비트 | 연산 결과가 0이면 1로 설정한다. |
| Sign Flag | SF | 7번 비트 | 연산 결과가 음수면 1로 설정한다. |
| Overflow Flag | OF | 11번 비트 | 부호 있는(signed) 연산에서 오버플로우가 발생하면 1로 설정한다. |
▶️ 포인터 레지스터
| 레지스터 | 비트수 | 알파벳 의미 | 설명 |
|---|---|---|---|
rbp | 64bit | b = base pointer | 현재 스택 프레임의 기준 주소(메모리 상 가장 높은 주소)를 저장한다. |
rsp | 64bit | s = stack pointer | 현재 스택 프레임의 꼭대기(메모리 상 가장 낮은 주소)를 저장한다. |
💡 Deep Dive
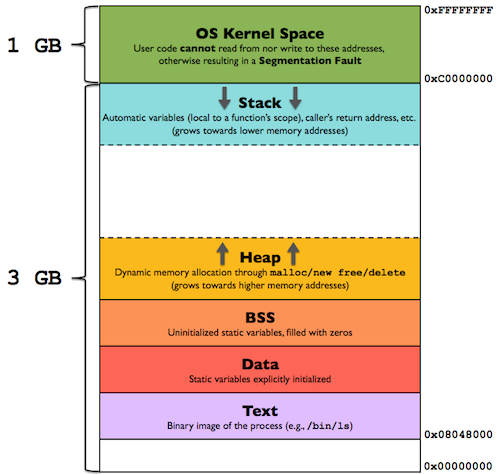
📌 스택과 메모리 주소
- 스택은 거꾸로 자란다.
- 스택은 메모리 주소가 높은 곳에서 시작해서, 낮은 방향으로 데이터가 쌓인다.
- 즉, 스택의 시작 지점(스택의 기준 주소, base address)은 메모리 주소 높은 곳에 있고, 스택의 꼭대기(top)은 메모리 주소가 낮은 곳에 있다.
출처: https://gabrieletolomei.wordpress.com/miscellanea/operating-systems/in-memory-layout/
📌 스택 프레임이란?
- 스택 영역에 할당된 지금 실행 중인 함수만을 위한 일시적인 메모리 공간이다. 1개의 함수당 1개의 스택 프레임이 생성된다.
- 지역 변수, 함수 인자, 함수 실행이 종료되면 PC가 복귀할 주소(return address), 이전 함수가 사용하던 스택 프레임의 기준 주소(SFP: Saved Frame Pointer) 등이 저장된다. 스택 프레임은 함수 실행이 종료되면 스택에서 회수된다.
📌 스택 프레임 예시
long myfunc(long a, long b, long c, long d,
long e, long f, long g, long h)
{
long xx = a * b * c * d * e * f * g * h;
long yy = a + b + c + d + e + f + g + h;
long zz = utilfunc(xx, yy, xx % yy);
return zz + 20;
}위의 소스 코드를 컴파일해서 실행했을 때 아래 그림과 같은 스택 프레임이 생성된다.
출처: https://eli.thegreenplace.net/2011/09/06/stack-frame-layout-on-x86-64
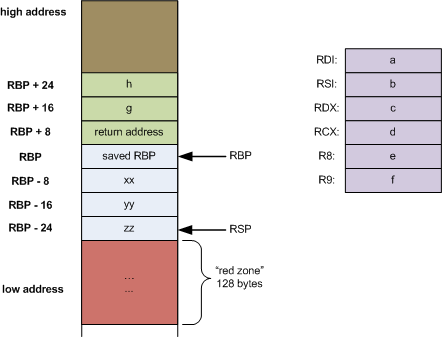
SFP(위의 그림에서 saved RBP 값)는 myfunc()이 호출되기 이전에 실행 중이던 함수가 사용하던 스택 프레임의 rbp를 저장하고, return address(PC가 돌아갈 주소)는 myfunc() 실행이 끝난 후 실행해야 할 명령어가 저장된 메모리 주소를 저장한다.
TMI
x86에서는 모든 함수 인자를 스택 프레임에 저장하지만, x86-64에서는 성능 최적화를 위해 일부 함수 인자를 스택 프레임이 아닌 레지스터에 저장한다.
ABI(Application Binary Interface) 규칙에 의해 함수의 첫 6개의 인자(argument)는 레지스터에 순서대로 저장하고, 나머지는 인자의 값들은 스택에 저장한다.
❓명령어 사이클(instruction cycle)이 무엇인가요?
CPU가 하나의 명령어를 처리하는 과정에는 정해진 흐름이 있다. 그 정형화된 흐름을 instruction cycle이라 한다. instruction cycle은 fetch, decode, execute 3개의 단계로 나뉜다.
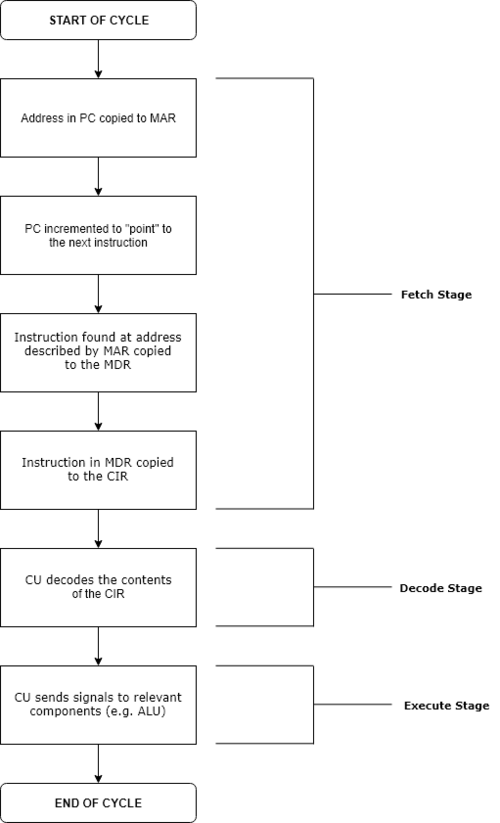
- fetch 단계
- 메모리로부터 다음 실행할 명령어 정보를 CPU의 레지스터로 가져오는 단계다.
- PC가 가리키는 메모리 주소로부터 명령어를 읽어와서 인코딩한 뒤 IR에 저장한다.
- decode 단계
- CU(Control Unit)가 IR에 저장된 명령어를 해석해서 해당 명령어를 실행하기 위해 필요한 CPU 내부 환경을 세팅하는 단계다.
- 이 때 명령어를 opcode(연산 코드)와 operand(오퍼랜드)로 나누어 해석한다.
- opcode를 해석해 "무슨 동작"을 할지 정하고, operand를 해석해 "어디에 작용"할지 정한다.
- ex. 메모리에 접근할 준비, 필요한 레지스터 값 세팅, 제어 신호 보낼 준비
- execute 단계
- decode 단계에서 미리 세팅해 둔 환경을 기반으로 CPU가 명령어를 실제로 수행하는 단계다.
- 제어 신호를 보내, CPU 내부의 각 부품(레지스터, ALU, 버스 등)을 물리적으로 동작하게 만든다.
- ex. ALU에게 연산을 시켜서 결과 값을 rax 레지스터에 저장시킨다, 데이터 버스를 동작시켜서 메모리로부터 데이터 값을 읽어온다, PC를 새로운 주소로 수정한다 등
예를 들어 mov eax, [1000] 명령어를 수행한다고 해보자.
- fetch 단계에서 PC가 실행할 명령어가 위치한 메모리 주소를 알고 있다. 해당 메모리 주소에 있는 명령어 정보를 IR로 읽어온다.
- decode 단계에서 MAR에 1000을 저장하고, 제어 신호를 보낼 준비를 한다.
- execute 단계에서 메모리 1000번지에 들어있는 유효 주소를 읽고, 그 유효 주소에 다시 접근해서 데이터를 읽어온다. 읽은 데이터는 MDR을 거쳐
eax레지스터에 저장된다.
일반적으로 fetch - decode - excecute 사이클을 반복하며 프로그램이 실행된다.
❓소프트웨어 인터럽트와 하드웨어 인터럽트가 무엇인가요? 어떻게 다른가요?
CPU의 instruction cycle 중간에 다른 작업에 대한 요청을 불쑥 들이밀 수 있는 방법이 하나 있다. CPU의 작업 흐름에 합법적(?)으로 새치기를 할 수 있는 방법이 바로 인터럽트(interrupt)다.
인터럽트를 발생시키는 주체에 따라 소프트웨어 인터럽트와 하드웨어 인터럽트로 분류할 수 있다. 각각의 정의와 예시들을 살펴보자.
✅ 소프트웨어 인터럽트
CPU가 현재 실행 중인 소프트웨어에 의해 발생하는 인터럽트다. 소프트웨어 인터럽트는 예외(Exception)와 인터럽트를 발생시키는 명령어(ex. int, syscall)에 의해 발생한다. 대표적인 예로 arithmetic overflow, divide by zero, page fault 등이 있다.
✅ 하드웨어 인터럽트
I/O device 컨트롤러나 타이머에 의해 발생하는 인터럽트를 말한다. 대표적인 예로 키보드 입력, 마우스 클릭, 네트워크 패킷 수신 등이 있다.
❓하드웨어 인터럽트 처리 순서는 어떻게 되나요?
- I/O device가 CPU에 인터럽트 요청(IRQ: Interrupt Request) 신호를 보낸다.
- CPU는 execute 단계가 끝나고 다음 실행할 명령어를 fetch하기 전 인터럽트 발생 여부를 확인한다.
- CPU는 IRQ를 확인하고 인터럽트 플래그를 통해 현재 인터럽트를 받아들일 수 있는 지 여부를 확인한다.
- 인터럽트를 받아들일 수 있다면 CPU는 실행하던 명령어 작업을 백업한다.
- CPU는 인터럽트 벡터(Interrupt Vector)를 참조하여 인터럽트 서비스 루틴(ISR: Interrupt Service Routine)을 실행한다.
- ISR 실행이 끝나면 4번 과정에서 백업해 둔 작업을 복구하여 실행을 재개한다.
💡 Deep Dive
📌 IRQ가 ISR에 닿는 과정
- IRQ는 하드웨어가 CPU에 보내는 하드웨어 수준의 전기 신호다. (진짜 1bit짜리 신호)
- 보통 I/O device 하나당 하나의 IRQ 선을 할당 받는다.
- 각 IRQ 선에는 고유 번호가 부여되어있다. (ex. IRQ 1 = 키보드 키입력 인터럽트, IRQ 7 = 프린터 인쇄 작업 완료 인터럽트)
- 각 IRQ 선에는 그에 대응되는 인터럽트 벡터 번호(ex.
0x21)가 존재한다. - CPU는 IDTR(Interrupt Descriptor Table Register)을 통해 IDT(Interrupt Descriptor Table) 주소를 항상 알고 있다.
- IDT의 각 인덱스에는 ISR이 저장되어 있는 주소가 저장되어 있다. (ex.
IDT[0x21]에는 키보드 인터럽트를 처리하기 위한 ISR의 주소가 저장되어 있음) - 인터럽트 벡터 번호는 IDT의 인덱스를 의미한다. IDT의 몇 번째 인덱스에 저장된 ISR 주소를 불러올 것 인지를 결정한다.
- ISR은 메모리의 kernel 영역에 상주하고 있는 프로그램이다. 인터럽트 핸들러(Interrupt Handler)라고도 부른다. 인터럽트 별로 어떤 처리를 해야 하는지 이미 프로그램이 작성되어 있다.
📌 키보드 키입력을 했을 때 어떤 일이 내부적으로 일어나는가?
- 사용자가 키보드에서 키를 입력하면
- 키보드는 IRQ 1 신호를 CPU로 보낸다.
- CPU는 IRQ 1에 해당하는 인터럽트 벡터 번호
0x21를 인식한다. - CPU는
IDT[0x21]에 저장된 ISR 주소를 불러온다. - CPU는 ISR을 실행한다.
- ISR 실행이 끝난 후, 인터럽트를 처리하기 이전에 실행하던 명령어로 돌아간다.
Reference
- 혼자 공부하는 컴퓨터 구조+운영체제, 강민철
- interrupts
