
💬 Intro
안녕하세요, 헤일러입니다.
4월 중순에 시작했던 컴구웅 스터디가 어느덧 마무리 되었네요!
스터디 팀원들과 함께 계획했던 기간 안에 책 한 권을 완주했다는 점이 정말 뿌듯하네요! 😊
아래는 학습한 내용 목차입니다.
- 페이지 교체 알고리즘
- 프레임 할당 방식
- 파일, 디렉터리
- 디스크, 파티션, 볼륨, 블록, 섹터 등 용어 정리
- 파일 시스템
- FAT, UFS
- BIOS, UEFI / MBR, GPT
❓ 요구 페이징(Demand Paging)이 무엇인가요?
실행에 필요한 페이지만 메모리에 로드하는 기법을 요구 페이징이라고 합니다.
요구 페이징은 기본적으로 아래와 같은 절차로 수행됩니다.
1. CPU가 특정 페이지에 접근하는 명령어를 실행
2. 해당 페이지가 현재 메모리에 있을 경우(유효 비트가 1일 경우) CPU는 페이지가 로드된 프레임에 접근
3. 해당 페이지가 현재 메모리에 없을 경우(유효 비트가 0일 경우) 페이지 폴트 발생
4. 페이지 폴트 처리 루틴을 통해 해당 페이지를 메모리로 로드하고 유효 비트를 1로 설정
5. 다시 1번 수행
이 요구 페이징 시스템이 안정적으로 작동하기 위해서는 페이지 교체, 프레임 할당 두 가지 문제를 해결해야 합니다.
❓ 페이지 교체 알고리즘이 무엇인가요?
페이지들을 로드하다 보면 언젠가 메모리가 가득 차게 되고, 로드된 페이지 일부를 보조기억장치로 내보내야 합니다. 이 때 어떤 페이지를 내보낼지 결정하는 방법이 페이지 교체 알고리즘입니다.
✅ 좋은 페이지 교체 알고리즘?
일반적으로 페이지 폴트를 적게 발생시키는 알고리즘을 좋은 페이지 교체 알고리즘이라고 말합니다. 페이지 폴트가 자주 발생했다는 것은 페이지 교체 알고리즘이 메모리에서 내보내면 안 되는 페이지를 보조기억장치로 자주 내보냈다는 의미고, 이는 성능 저하로 이어지기 때문입니다.
그렇다면 페이지 교체 알고리즘이 좋은지 나쁜지 평가하기 위해 페이지 폴트 발생 횟수를 계산할 수 있어야 겠죠? 이 페이지 폴트 발생 횟수는 보통 페이지 참조열을 기반으로 시뮬레이션하여 계산합니다.
✅ 페이지 참조열(Page Reference String)
페이지 참조열은 CPU가 참조하는 페이지들 중 연속된 페이지를 생략한 페이지열을 말합니다.
예를 들어 CPU가 아래와 같은 순서로 페이지에 접근했다고 가정해보겠습니다.
1 2 2 5 6 7 7 7 7 2 2연속으로 중복된 페이지를 생략하면 아래의 페이지 참조열이 됩니다.
1 2 5 6 7 2❓ FIFO 페이지 교체 알고리즘은 무엇인가요?
메모리에 오래 머무른 페이지부터 내보내!
FIFO 페이지 교체 알고리즘은 이름 그대로 메모리에 가장 먼저 올라온 페이지부터 내보내는 방식입니다. 아이디어와 구현이 간단하지만, 그다지 실용적이지는 않습니다. 메모리에 오래 머문 페이지가 자주 사용되지 않을 페이지라는 것의 상관 관계가 모호하기 때문입니다.
📌 2차 기회 페이지 교체 알고리즘(Second Chance Page Replacement Algorithm)
2차 기회 페이지 교체 알고리즘은 FIFO 페이지 교체 알고리즘과 동일하게 메모리에 가장 오래 머물렀던 페이지를 내보낼 페이지로 선택합니다. FIFO 페이지 교체 알고리즘과 다른 점은 페이지의 참조 비트가 1일 경우 바로 내보내지 않고 참조 비트를 0으로 만든 뒤, 가장 최근 적재한 것으로 취급합니다. 참조 비트가 1일 경우 메모리에 머물 기회를 한 번 더 주는 방식입니다.
❓ 최적 페이지 교체 알고리즘은 무엇인가요?
가장 먼 미래에 참조될 페이지부터 메모리에서 내보내!
최적 페이지 교체 알고리즘은 미래의 페이지 참조열을 참고해, 가장 나중에 참조될 페이지를 선택해 메모리에서 내보내는 그리디 방식의 알고리즘입니다. (미래의 페이지 참조열의 순서가 정확하다는 가정 하에) 페이지 폴트가 최소로 발생하는 방법이기 때문에 가장 낮은 페이지 폴트율을 보장합니다.
하지만 프로세스가 미래에 어떤 페이지를 어떤 순서로 사용하게 될 지, 얼마만큼의 미래까지 예측해야 할 지 완벽하게 파악하는 것은 현실적으로 불가능에 가깝기 때문에 실제로 사용할 수 없는 알고리즘입니다.
최적 페이지 교체 알고리즘은 다른 페이지 교체 알고리즘의 성능을 평가할 때 용이합니다. 이미 실행이 지나간 페이지 참조열에 대해, "최적 페이지 교체 알고리즘으로 수행했다면 n번의 페이지 폴트가 발생했을 것이다"를 하한선으로 두고 그 차이를 성능의 지표로 사용할 수 있습니다.
❓ LRU(Least Recently Used) 페이지 교체 알고리즘은 무엇인가요?
최근에 사용되지 않은 페이지는 앞으로도 덜 사용될거야!
LRU 페이지 교체 알고리즘은 가장 오랫동안 사용되지 않은 페이지를 교체하는 알고리즘입니다. 오래 사용되지 않은 페이지는 앞으로도 사용되지 않을 가능성이 높다는 지역성(Locality) 원리를 활용하는 방법입니다.
하지만 가장 오래 사용되지 않은 페이지를 알기 위해서는 모든 페이지의 참조 이력을 기록하고 추적해야 하기 때문에 정확한 LRU 방식을 사용하기는 현실적으로 어렵습니다.
따라서 운영체제에서는 Clock 알고리즘, Aging 알고리즘과 같은 LRU 근사 알고리즘을 사용합니다.
📌 Clock 알고리즘
Clock 알고리즘은 순환 큐 형태로 페이지를 관리하고, 시계 바늘로 순환 큐를 순회하며, 참조 비트의 상태에 따라 교체할 페이지를 결정하는 방식의 알고리즘입니다.
-
페이지에 참조가 발생하면 참조 비트(
R bit)를 1로 설정 -
페이지 교체가 필요할 때 시계 바늘이 가리키는 페이지를 평가
R bit == 0: 해당 페이지를 교체R bit == 1:R bit = 0으로 리셋하고, 시계 바늘 1칸 회전
- 교체할 수 있는 페이지(
R bit == 0인 페이지)가 나올 때까지 시계 바늘 회전
📌 Aging 알고리즘
Aging 알고리즘은 각 페이지마다 참조 비트와 n bit 크기의 카운터를 두어, 시간 흐름에 따라 카운터에 참조 기록을 반영하는 방식의 알고리즘입니다.
정해진 주기마다 아래의 동작을 수행합니다.
-
모든 페이지에 대해
카운터 = 카운터 >> 1 -
모든 페이지를 순회하며
R bit == 1이면
- 가장 높은 비트를 1로 세팅. (n=8이라 가정하면
카운터 |= 10000000) - 참조 비트 리셋 (
R bit = 0)
그리고 페이지 교체가 필요할 때, 가장 작은 카운터값을 가진 페이지를 제거합니다.
❓ 스래싱(Thrashing)은 무엇일까요?
페이지 폴트가 자주 발생하는 이유가 나쁜 페이지 교체 알고리즘 때문만은 아닙니다. 각 프로세스가 사용할 수 있는 프레임 수가 너무 적어도 페이지 폴트가 자주 발생합니다.
나쁜 페이지 교체 알고리즘, 적절하지 않은 프레임 할당 방식으로 인해 페이지 교체가 자주 발생하게 되면, CPU가 계속 페이지 폴트를 처리하느라 프로세스의 작업을 제대로 처리하지 못하고 디스크 I/O만 계속 발생시키게 됩니다. 이로 인해 전체 시스템 성능이 저해되는 현상을 스래싱이라고 합니다.
-
일반적으로 스래싱이 발생하는 상황
- 과하게 많은 프로세스를 동시에 실행한 경우
- 프로세스 하나가 실행에 필요한 프레임 수보다 적게 할당 받은 경우
-
스래싱 해결 방법
- 실행 프로세스 수 조절
- 프레임을 동적으로 재할당
- 페이지 교체 정책 최적화
- 물리 메모리 증설
❓ 프레임을 할당하는 방식에는 무엇이 있을까요?
✅ 정적 할당 방식
단순히 실행 전 프로세스의 크기만을 고려한 방식입니다. 프로세스마다 프레임 수를 고정적으로 할당합니다. (ex. A 프로세스에 10개, B 프로세스에 20개 고정 할당)
프로세스의 프레임 수가 너무 부족하면 스래싱이 자주 발생하고, 프레임 수가 과하면 자원 낭비가 일어납니다. 따라서 프레임 수를 상황에 따라 유연하게 조정할 수 없는 정적 할당 방식은 다음과 같이 제한적인 경우에만 사용하는 것이 좋습니다.
- 프로세스 수가 고정되고 예측 가능한 환경
- 프로세스 별 작업 집합(Working Set) 크기가 비슷한 경우
- 시스템 자원이 아주 제한적인 경우
- ex. 실시간 임베디드 시스템
이러한 정적 할당 방식에는 균등 할당 방식, 비례 할당 방식이 있습니다.
▶️ 균등 할당(Equal Allocation)
모든 프로세스에 동일한 수의 프레임을 할당하는 방식입니다.
📌 수식
- 전체 프레임 수:
- 프로세스 수:
- 각 프로세스 에게 할당할 프레임 수: =
▶️ 비례 할당(Proportional Allocation)
프로세스의 전체 페이지 수에 비례하여 프레임을 할당하는 방식입니다.
📌 수식
- 전체 프레임 수:
- 프로세스 수:
- 각 프로세스 의 페이지 수:
- 전체 페이지 수:
- 에 할당할 프레임 수:
▶️ 정리
균등 할당 방식은 구현이 단순한 대신, 프레임 부족/낭비 문제가 발생할 가능성이 높습니다.
비례 할당 방식은 조금 더 그럴듯한 접근이지만, 프로세스의 전체 용량의 크기와 실행에 필요한 페이지 수는 다를 수 있습니다. 크기가 크더라도 막상 실행해보면 필요한 프레임 수가 많지 않거나, 반대로 프로세스 크기는 작지만 실행해보니 많은 프레임을 필요로 할 수 있습니다.
✅ 동적 할당 방식
동적 프레임 할당은 프로세스 실행 중 프로세스의 메모리 사용량 변화에 따라 프레임 수를 조절하는 방식입니다.
동적 할당 방식은 프로세스 실행 중에 할당할 프레임 수를 가변적으로 조정할 수 있기 때문에 스래싱을 방지하고 자원을 효율적으로 사용하는데 유리하지만, 구현이 복잡하고 프레임 수를 계산하는 과정에서 오버헤드가 조금 있다는 것이 단점입니다. 하지만 단점보다 이점이 훨씬 크기 때문에 현대 운영체제는 대부분 동적 프레임 할당 방식을 사용하고 있습니다.
-
동적 프레임 할당 방식이 유리한 경우
- 프로세스의 작업 집합이 시간에 따라 변하는 경우
- 스래싱 방지가 중요한 환경
- 고부하 멀티태스킹 환경 (자원 활용률 최적화 가능)
-
동적 프레임 할당 방식이 불리한 경우
- 작업 집합 추적 비용이 큰 경우 (참조 비트, 타임스탬프 기록에 대한 비용이 큰 경우)
- 시스템이 매우 소규모/단순한 경우
이러한 동적 할당 방식에는 작업 집합 모델 기반 프레임 할당 방식, 페이지 폴트 빈도 기반 할당 방식이 있습니다.
▶️ 작업 집합 모델(Working Set Model) 기반 프레임 할당
작업 집합 모델 기반 프레임 할당은 프로세스가 일정 기간 동안 참조한 페이지 집합(작업 집합)을 기준으로 필요한 만큼의 프레임을 동적으로 할당하는 방식입니다.
-
장점
- 필요한 만큼만 프레임을 할당하므로 스래싱을 방지할 수 있고, 자원 낭비가 줄어듭니다.
-
단점
- 구현이 복잡합니다.
- 페이지 참조열을 추적하는데 오버헤드가 발생합니다.
- 작업 집합 윈도우 크기 를 적절하게 선택해야 하는 문제가 있습니다.

📌 수식
- 작업 집합 윈도우(Working Set Window) 크기:
- 에서 까지 참조된 페이지들의 작업 집합:
- 작업 집합의 크기 를 측정하여 최소 이 크기만큼의 프레임을 할당
▶️ 페이지 폴트 빈도(PFF: Page-Fault Frequency) 기반 프레임 할당
페이지 폴트 빈도 기반 프레임 할당은 아래 2개의 전제 조건으로부터 파생된 아이디어입니다.
- 페이지 폴트율이 높으면, 그 프로세스는 적은 프레임을 갖고 있는 것이다.
- 페이지 폴트율이 낮으면, 그 프로세스는 많은 프레임을 갖고 있는 것이다.
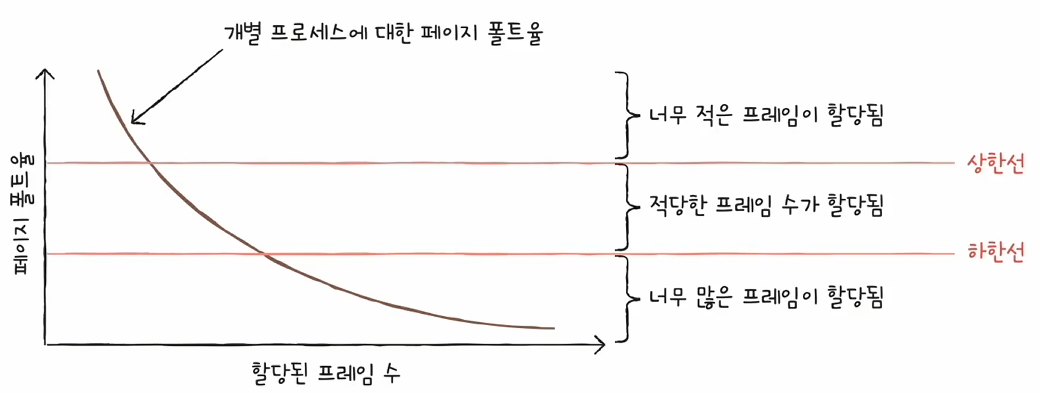
따라서 프로세스의 페이지 폴트율을 계산하여 일정 임계값을 넘으면 프레임 수를 증가시키고, 임계 값보다 낮으면 프레임 수를 감소시킵니다.
-
장점
- 작업 집합 모델 기반 방식과 마찬가지로 스래싱 방지와 자원 최적화에 유리합니다.
- 구현이 단순합니다.
- 오버헤드가 낮습니다.
- 페이지 폴트율 증감에 따라 빠르게 반응할 수 있습니다.
-
단점
- 단기적인 페이지 폴트율에 따라 과잉 반응하게 될 가능성이 있습니다.
- 프레임 증감이 과하면 성능 변동 폭이 커질 수 있습니다.
- 임계값을 적절하게 선택해야 하는 문제가 있습니다.
- 작업 집합 기반 모델보다 정확도는 떨어집니다.
❓ 파일은 무엇인가요? 파일 속성, 유형, 연산에 대해 설명해주세요.
의미가 있는 정보를 담는 논리적인 단위
✅ 파일 속성 (Linux 기준)
| 속성 | 설명 |
|---|---|
| 위치 | 파일의 보조기억장치 상의 현재 위치 |
| 크기 | 파일의 바이트 단위 크기 |
| 접근 권한 | 읽기/쓰기/실행 권한 |
| 타입 | 일반파일, 디렉토리, 심볼릭 링크 등 |
| 소유자(Owner) | 파일을 소유한 사용자 |
| Change Time (ctime) | inode 정보가 마지막으로 변경된 시간. 메타데이터가 바뀐 시간. ex. 권한, 소유자, 링크 수 등의 변화 |
| Modification Time (mtime) | 파일 내용이 마지막으로 수정된 시간 ex. write() 시스템 콜 호출 시 갱신 |
| Access Time (atime) | 파일에 마지막으로 접근한 시간 ex. open(), read() 시스템 콜 호출 시 갱신 |
# 파일 생성
touch hello.txt
# mtime, ctime이 같음
# 파일 내용 수정
echo "hi" >> hello.txt
# mtime, ctime 모두 갱신
# 권한 변경
chmod 000 hello.txt
# mtime은 그대로, ctime만 갱신됨
# 읽기
cat hello.txt
# atime만 갱신됨✅ 파일 유형 (Linux 기준)
| 유형 | 기호 (ls -l 기준) | 설명 |
|---|---|---|
| 일반 파일 (Regular File) | - | 텍스트, 바이너리, 실행파일 등 일반 파일 |
| 디렉터리 (Directory) | d | 다른 파일들의 목록을 관리하는 파일 |
| 심볼릭 링크 (Symbolic Link) | l | 다른 파일의 경로를 참조하는 파일 |
| 블록 장치 파일 (Block Device) | b | 저장장치(HDD, SSD, USB 등)와 커널이 블록 단위 스트림을 주고 받기 위한 파일 |
| 문자 장치 파일 (Character Device) | c | 입출력장치(키보드, 마우스, 직렬 포트 등)와 커널이 바이트 단위 스트림을 주고 받기 위한 파일 |
| FIFO (Named Pipe) | p | 로컬 환경에서 두 프로세스 간 IPC 통신을 하기 위한 파일 |
| 소켓 (Socket) | s | 클라이언트-서버 간 IPC 통신을 하기 위한 파일 |
✅ 파일 연산 (Linux 기준)
▶️ 파일 열기: open()
int open(const char *pathname, int flags, mode_t mode);int fd = open("test.txt", O_WRONLY | O_CREAT, 0644);
if (fd == -1) {
perror("open failed");
exit(1);
}📌 open() 주요 플래그들
| Flag | 의미 |
|---|---|
O_RDONLY | 읽기 전용 |
O_WRONLY | 쓰기 전용 |
O_RDWR | 읽기, 쓰기 모두 가능 |
O_CREAT | 파일이 없으면 생성 |
O_TRUNC | O_WRONLY 또는 O_RDWR로 open시에 이미 존재하는 파일이면 파일의 내용을 삭제하고 크기를 0으로 만들어 open |
O_APPEND | 파일 중간에 write 금지. 파일 끝에만 write 가능한 open. |
▶️ 파일 닫기: close()
int close(int fd);close(fd);▶️ 파일 읽기: read()
ssize_t read(int fd, void *buf, size_t count);char buffer[64];
int n = read(fd, buffer, sizeof(buffer));▶️ 파일 쓰기: write()
ssize_t write(int fd, const void *buf, size_t count);write(fd, "Hello\n", 6);▶️ 파일 오프셋 이동: lseek()
off_t lseek(int fd, off_t offset, int whence);lseek(fd, 0, SEEK_SET); // 파일 처음으로 이동❓ 디렉터리는 무엇인가요? 디렉터리 경로, 연산에 대해 설명해주세요.
디렉터리 또한 파일입니다. 다른 파일이나 디렉터리에 대한 메타데이터(UNIX에서는 inode 번호) 목록을 담고 있는 특수한 목적의 파일입니다.
✅ 디렉터리 경로
경로는 디렉터리를 이용해 파일 위치, 파일 이름을 특정 짓는 정보입니다.
✅ 디렉터리 연산
▶️ 디렉터리 열기
DIR *opendir(const char *name); // 새 디렉터리 생성DIR *dp = opendir(".");▶️ 디렉터리 닫기
int closedir(DIR *dirp);closedir(dp);▶️ 디렉터리 생성
int mkdir(const char *pathname, mode_t mode);mkdir("newdir", 0755); // Owner, Group, Others 권한: rwx r-x r-x▶️ 디렉터리 삭제
int rmdir(const char *pathname); // 비어있는 디렉터리 삭제rmdir("newdir");▶️ 디렉터리 읽기
struct dirent *readdir(DIR *dirp); // 열려있는 디렉터리에서 항목 하나 읽기struct dirent *ep = readdir(dp);📌struct dirent: 디렉터리 내의 개별 엔트리 정보
struct dirent {
ino_t d_ino; // inode 번호
off_t d_off; // 다음 dirent 오프셋
unsigned short d_reclen; // 전체 레코드 길이
unsigned char d_type; // 파일 타입: DT_REG(일반 파일), DT_DIR(디렉터리), DT_LNK(심볼릭 링크)
char d_name[256]; // 파일/디렉터리 이름
};❓ 파티셔닝과 포매팅에 대해 설명해 주세요.
| 용어 | 설명 |
|---|---|
| 디스크 | 데이터를 저장하기 위한 물리적 저장장치 (ex. HDD, SSD) |
| 파티션 | 디스크를 논리적으로 나눈 구역 |
| 파티셔닝 | 디스크를 여러 개의 파티션으로 나누는 작업 |
| 파일 시스템 | 저장장치에 파일을 효율적으로 저장하고 관리하는 방법 |
| 포매팅 | 파티션에 특정 파일 시스템을 생성하여, 운영체제가 파일을 저장하고 읽을 수 있도록 초기화하는 작업 |
▶️ 운영체제 별 기본 파일 시스템
-
Windows: NTFS(New Technology File System)
- 파일/디렉터리 단위 접근 권한 제어(ACL) 기능을 통해 강력한 보안 제공
- 고성능 I/O 캐시
-
MacOS: APFS(Apple File System)
- 파일 복사 시 clone 처리(Copy on Write 처리)
- SSD 최적화 알고리즘 사용
- 파일 및 디렉터리 단위 스냅샷 기능
-
Linux: ext4(Fourth Extended File System), XFS
- ext4
- 지연 할당 기능 제공
- 안정성 높음
- XFS
- 저널링 기반 고속 메타데이터 처리 가능
- 대용량 파일 처리 성능이 뛰어남
- SSD, 서버 환경에 적합
- ext4
-
Android OS: ext4
-
번외: FAT32
- USB, SD 카드, 이동식 디스크에서 사용
- 다양한 운영체제에서 잘 호환됨
❓ 파일 할당 방법들에 대해 설명해 주세요.
운영체제는 파일과 디렉터리를 블록 단위로 읽고 씁니다. 하드 디스크의 가장 작은 저장 단위는 섹터지만, 운영체제는 하나 이상의 섹터를 블록이라는 단위로 묶어 블록 단위로 파일을 관리합니다.
📌 디스크 단위의 종류
| 단위 | 설명 |
|---|---|
| 섹터 (Sector) | 디스크에서 데이터를 읽고 쓸 수 있는 가장 작은 단위. 전통적인 디스크에서는 1섹터=512 bytes를 사용하고, Advanced Format을 사용하는 고용량 HDD/SDD에서는 1섹터 = 4096 bytes(4KB)를 사용합니다. |
| 블록 (Block) or 클러스터(Cluster) | 파일 입출력의 최소 단위. 블록과 클러스터는 개념적으로는 동일합니다. UNIX 계열에서 블록이라는 용어를 사용하고, Windows에서 클러스터라는 용어를 사용합니다. |
| 파티션 (Partition) | 하나의 물리 디스크를 논리적으로 나눈 구역. 각 파티션은 서로 독립적인 파일 시스템을 가질 수 있습니다. |
| 볼륨 (Volume) | OS에서 인식하는 하나의 저장 장치 단위. 보통 하나의 파티션 = 하나의 볼륨이지만 RAID, LVM 등 특수한 경우 여러 파티션이 하나의 볼륨이 될 수도 있습니다. |
그리고 파일을 보조기억장치에 할당하는 방법은 연속 할당과 불연속 할당 두 가지가 있습니다. 이 둘에 대해 살펴보겠습니다.
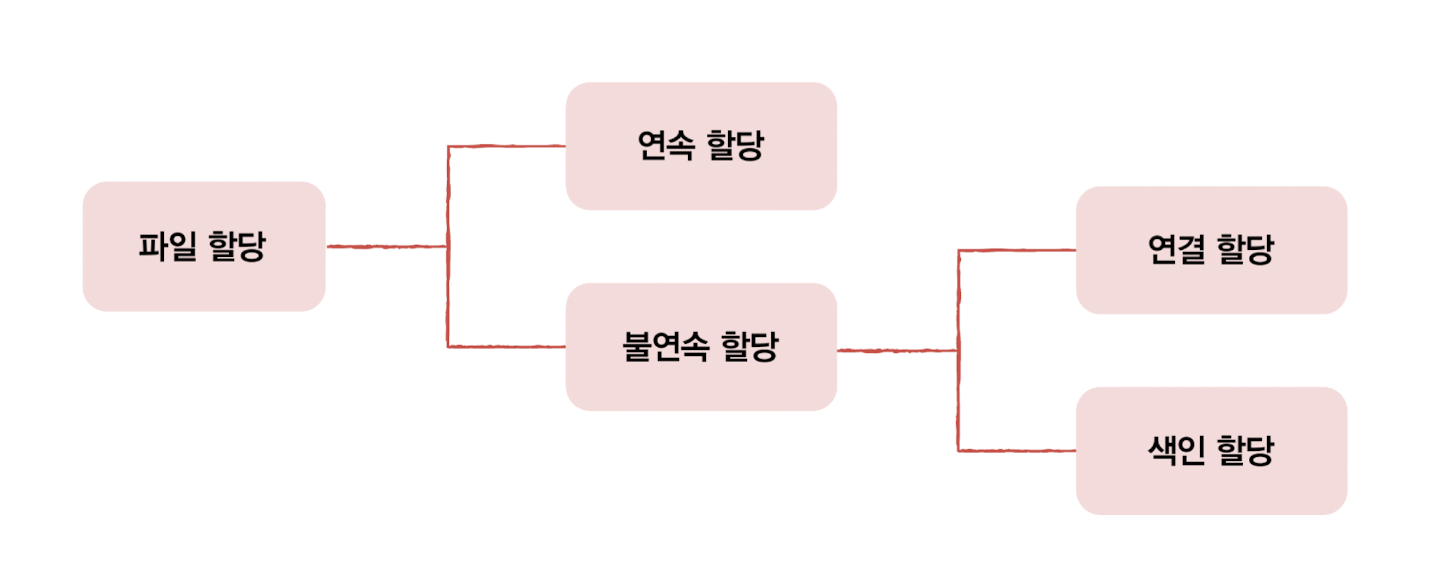
✅ 연속 할당(Contiguous Allocation)
보조기억장치 내 연속적인 블록에 파일을 할당하는 방법입니다.
연속으로 할당된 파일에 접근하기 위해 파일의 첫 번째 블록 주소와 블록 단위의 길이만 알면 됩니다.
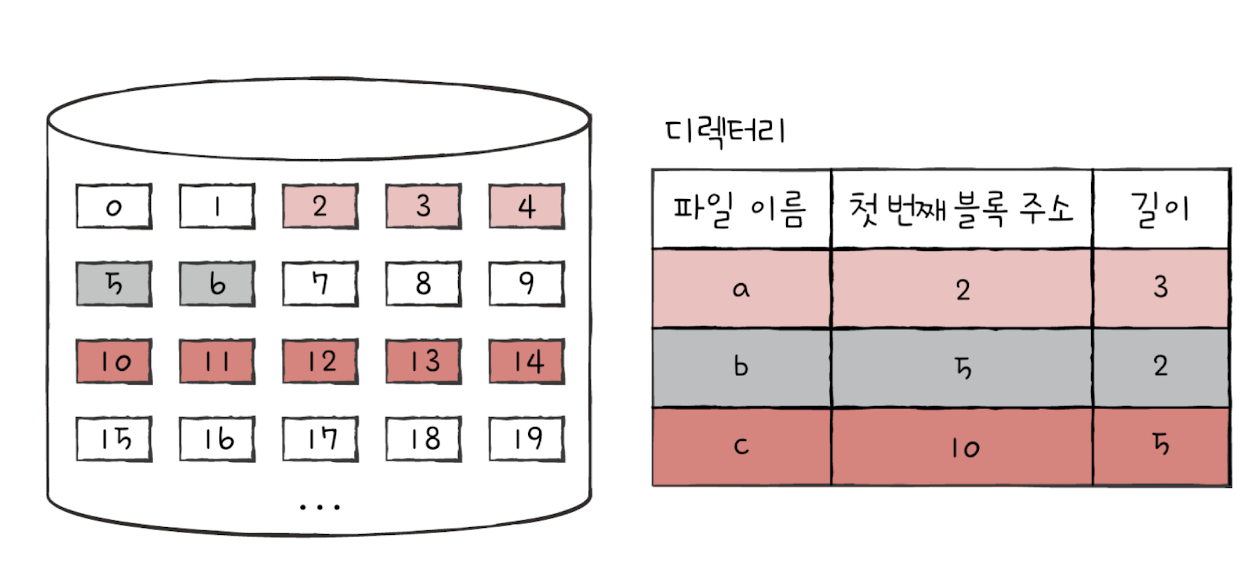
- 단점
- 외부 단편화를 발생시키는 방법입니다.
✅ 불연속 할당 - 연결 할당(Linked Allocation)
연속된 데이터 블록을 연결 리스트로 관리하는 방법입니다. 각 블록이 다음 블록의 주소를 저장하고 있습니다.
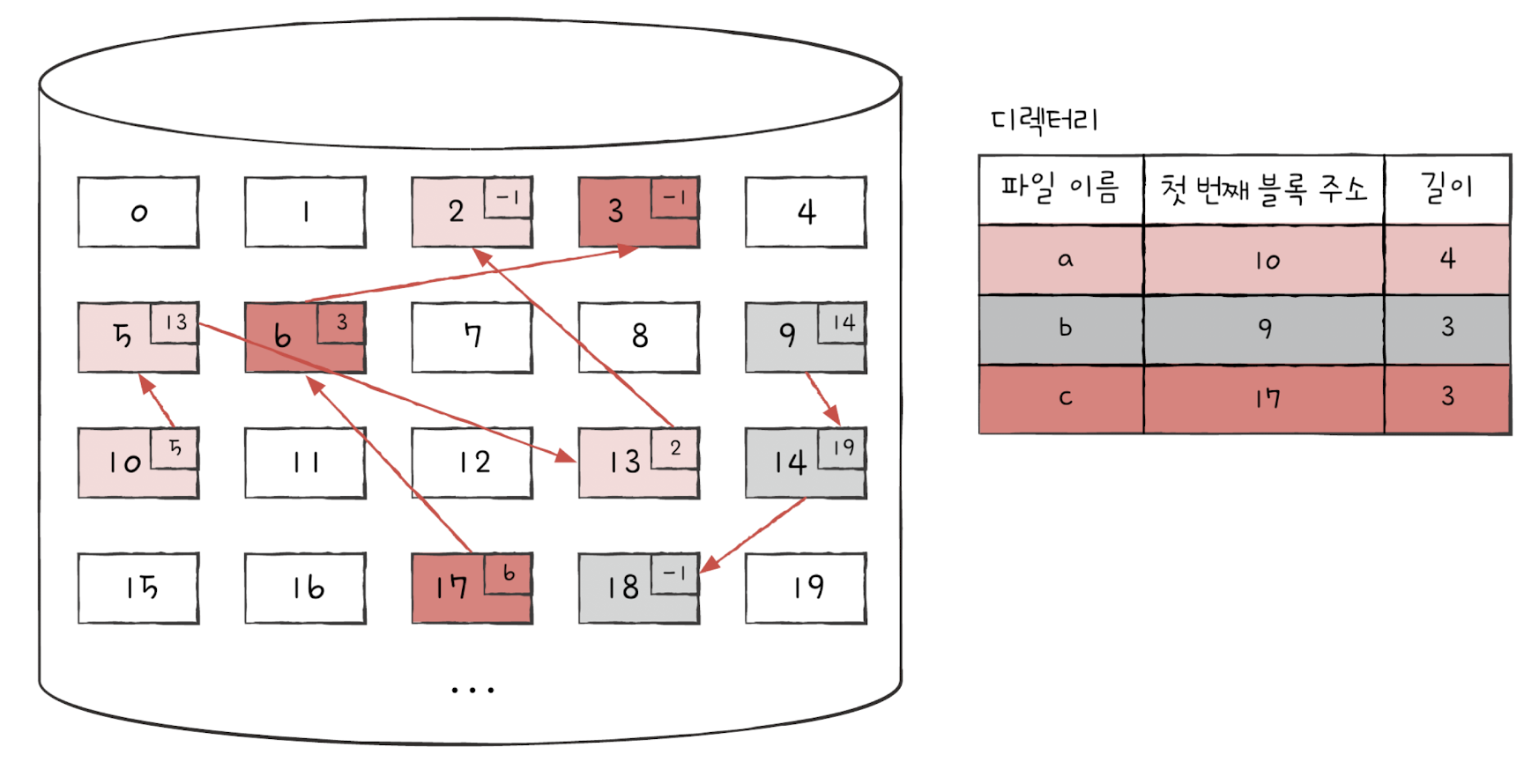
- 장점
- 외부 단편화 문제를 발생시키지 않습니다.
- 단점
- 연결 리스트의 단점을 그대로 갖고 있습니다.
- 파일을 전부 로드, 스왑하기 위해서는 연결 리스트 전체를 순회해야 합니다.
- 하드웨어 고장이나 오류로 인해 연결 리스트의 중간 포인터에 문제가 생기면, 그 이후 블록에 더 이상 접근할 수 없습니다. -> 데이터 복원에 있어서 리스크가 큰 방식입니다.
- 연결 리스트의 단점을 그대로 갖고 있습니다.
✅ 불연속 할당 - 색인 할당(Indexed Allocation)
색인 블록에 특정 파일의 모든 블록 주소를 배열로 저장하는 방법입니다.
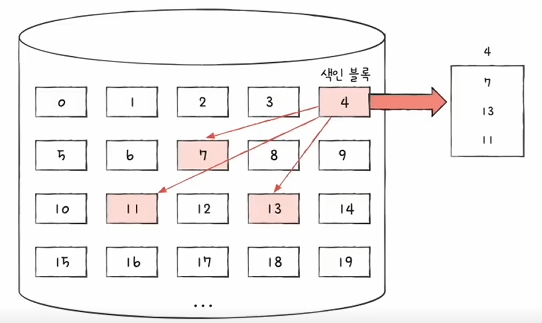
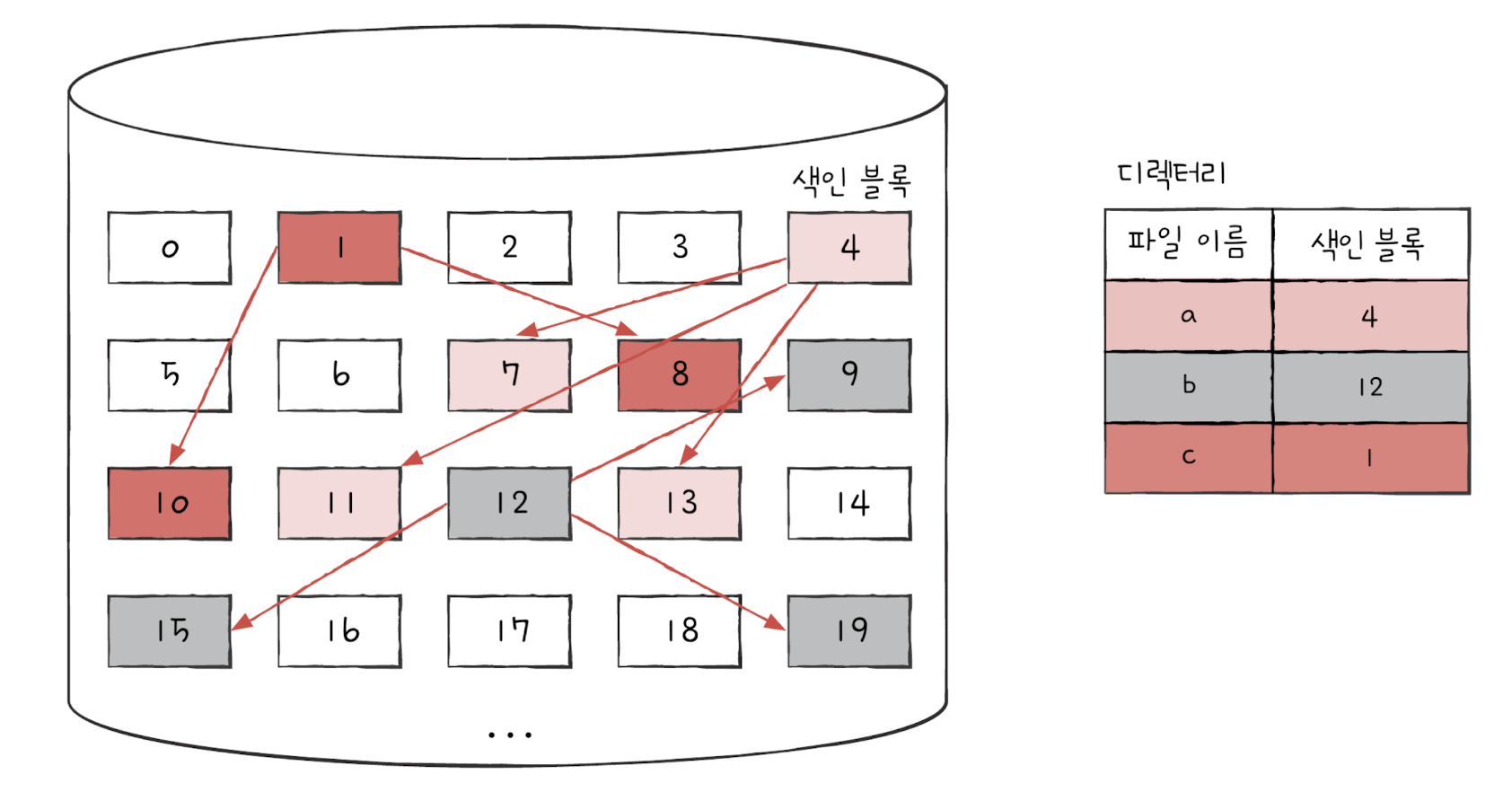
배열로 관리하기 때문에 블록 인덱스를 이용해서 임의의 블록 위치에 접근하기 쉽습니다. 특정 파일의 i번째 블록에 접근하고 싶다면 색인 블록의 i번째 항목이 가리키는 블록에 접근하면 됩니다. UNIX 파일 시스템은 이 색인 할당 방법을 사용하고 있습니다.
❓ FAT 파일 시스템에 대해 설명해 주세요.
FAT는 연결 할당의 단점을 보완한 파일 시스템입니다. 색인 할당 방법과 비슷한데요. 파일 할당 테이블(FAT:File Allocation Table)이라는 전역 테이블에 다음 블록들의 주소 정보를 테이블 하나에 전부 모아 놓은 방식을 사용합니다.
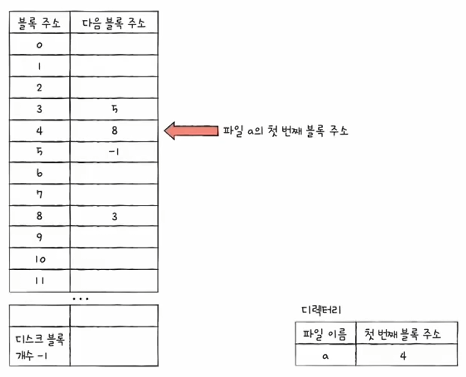
다음 블록이 없는 경우는 보통 EOF(-1 = 0xFFFF)로 표시합니다.
✅ FAT로 포매팅된 파티션의 물리 메모리 영역
FAT로 포매팅된 파티션은 물리적으로 메모리 공간이 아래 그림과 같이 4개의 영역으로 구분되어 사용됩니다.
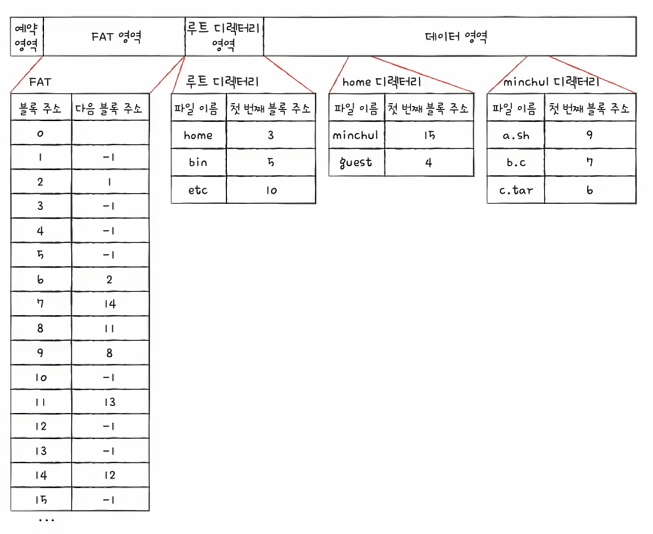
- 예약 영역 (Reserved Area)
- 파티션에 설정된 파일 시스템의 메타데이터를 저장하고 있는 영역입니다.
- VBR(Volume Boot Record), 부트 섹터(Boot Sector)
- 부트 섹터는 VBR에 포함되는 개념이고, VBR의 크기가 1섹터인 경우 VBR=부트 섹터입니다.
- VBR은 BPB, 부트 코드(부트 가능한 파티션인 경우 포함합니다.)를 포함하여 파일 시스템 구조에 대한 메타데이터를 저장하는 영역입니다.
📌 BPB(BIOS Parameter Block)?
BPB는 특정 파티션의 파일 시스템 구조 정보를 담고 있는 영역으로 파티션의 첫 번째 섹터에 존재합니다. 해당 파티션의 목차 같은 역할이라 생각하면 됩니다.
-
FAT 영역
- FAT 테이블이 존재하는 영역입니다.
-
루트 디렉터리 영역(FAT12/16에 존재)
- 루트 디렉터리 엔트리들의 정보가 위치한 영역입니다.
- 하위 디렉터리 엔트리는 데이터 영역에 파일과 같이 저장되고, 그 안에 다시 하위 디렉터리 엔트리 목록 정보를 가지는 재귀적 구조를 가집니다.
📌 FAT32
FAT32에서는 고정된 루트 디렉터리 영역이 따로 존재하지 않습니다. 루트 디렉터리 엔트리도 일반 디렉터리처럼 데이터 영역에 위치하고 있습니다.
루트 디렉터리의 시작 클러스터 번호만 BPB의 Root Directory Cluster 필드에 저장되고, 루트 디렉터리 엔트리의 내용은 데이터 영역에 위치합니다.
- 데이터 영역
- 실제 파일/디렉터리 엔트리의 내용이 저장되는 영역입니다.
❓ UNIX 파일 시스템에 대해 설명해 주세요.
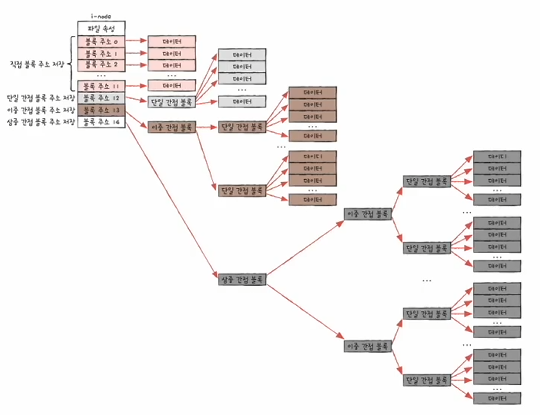
UNIX 파일 시스템에서는 색인 할당 방식을 사용하고 있고, 색인 블록을 inode라고 부릅니다. 각 파일마다 고유한 inode가 존재합니다. inode는 고유한 번호가 부여되어있고, inode 정보는 파티션 내 inode 영역이라는 특정 영역에 모여 있습니다.

그리고 이 inode에는 파일 속성 정보와 15개의 블록 주소가 저장될 수 있습니다.
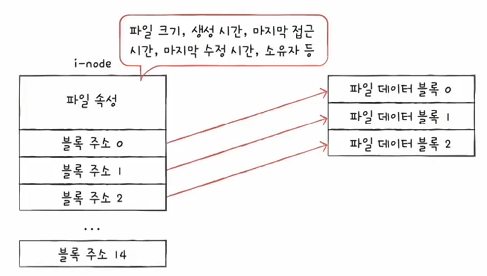
그런데 한 파일의 크기가 15개의 블록 크기보다 큰 경우는 어떻게 할까요?
- 12개의 블록 주소에는 실제 파일 데이터가 저장된 직접 블록 주소를 저장합니다.
- 12개의 블록으로 충분하지 않다면, 13번째 블록 주소에 단일 간접 블록 주소를 저장합니다.
- 단일 간접 블록은 색인 블록의 역할을 합니다. 실제 데이터가 저장된 디스크 상의 블록의 번호들을 저장하고 있습니다.
- 단일 간접 블록의 크기가 4KB(4 * 1024bytes)고, 32비트(4bytes) 주소 체계 위에서 동작한다고 하면, 단일 간접 블록에는 1024개의 직접 블록 주소를 저장 가능 합니다.
- 2번까지의 내용으로도 충분하지 않다면, 14번째 블록 주소에 이중 간접 블록 주소를 저장합니다.
- 3번까지의 내용으로도 충분하지 않다면, 15번째 블록 주소에 삼중 간접 블록 주소를 저장합니다.
💡 Deep Dive - 부팅 방식(BIOS, UEFI)과 파티션 형식(MBR, GPT)
메인보드에 따라 BIOS로 부팅이 시작되는 컴퓨터가 있고, UEFI로 부팅이 시작되는 컴퓨터가 있습니다. 그리고 부팅 가능한 디스크는 파티션 형식을 MBR 방식과 GPT 방식 중 하나를 반드시 선택해야 합니다.
그래서 부팅 방식과 파티션 형식의 총 4가지의 조합이 존재할 수 있는데요. 각 부팅 방식과 파티션 형식에 대해 간략하게 학습해 보았습니다.
- BIOS + MBR
- BIOS + GPT
- UEFI + MBR
- UEFI + GPT
✅ MBR(Master Boot Record)
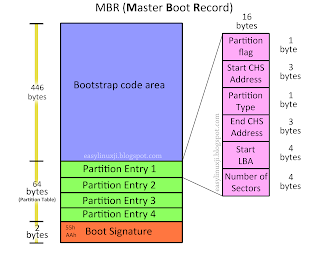
- 특징
- MBR은 디스크 전체에서 부팅 가능한 파티션을 찾고, 그 파티션의 부트 섹터로 제어를 넘기는 부트 코드와 파티션 테이블 정보가 기록된 영역입니다.
- 디스크 전체에서 첫 번째 섹터(0번 섹터)에 위치합니다.
- 부팅 시, 어떤 파티션으로 부팅 할지 결정하는 역할을 합니다.
✅ GPT(GUID Partition Table)
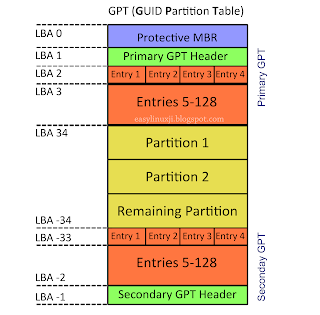
-
특징
- GPT는 MBR을 대체하기 위한 더 안전하고 확장된 구조를 갖고 있습니다.
- 기존 MBR 기반 시스템과의 호환을 위해 디스크 첫 섹터에 Protective MBR을 포함하고 있습니다. Protective MBR은 "나는 GPT 방식의 디스크야"를 알리는 목적의 더미 영역입니다.
- MBR 방식은 디스크의 첫 섹터에만 정보가 존재하지만, GPT 방식은 디스크 시작과 끝의 여러 섹터에 걸쳐서 위치하고 있습니다.
-
MBR보다 나은 점
- GPT 헤더와 파티션 엔트리를 통해 손상 복구가 용이한 구조를 갖고 있습니다. (안전성)
- MBR은 최대 4개의 파티션만 지원하는 반면, GPT는 128개 이상의 파티션을 지원합니다. (확장된 구조)
- Windows에서는 128개의 파티션으로 제한하고 있습니다.
✅ BIOS(Basic Input/Output System)
- 특징
- 컴퓨터 부팅 시 하드웨어 초기화 및 운영체제 로딩을 준비하는 역할을 하는 펌웨어입니다.
- BIOS는 MBR 디스크와의 조합이 일반적입니다.
- Linux에서는 BIOS Boot Partition를 이용해 BIOS + GPT 부팅이 가능하긴 하지만 일반적인 방법은 아닙니다.
- 약 2TB 이상의 디스크에서는 부팅할 수 없습니다.
✅ UEFI(Unified Extensible Firmware Interface)
-
특징
- BIOS를 대체하기 위해 등장한 차세대 BIOS 표준입니다. 기존 BIOS와 완전히 호환됩니다.
- UEFI 셋업 설정에서 부팅 시 동작 방식을 UEFI 모드과 legacy BIOS 모드를 선택할 수 있습니다.
- CSM(Compatibility Support Module)을 통해 BIOS + MBR 방식으로 실행 가능합니다.
- UEFI는 GPT 디스크와의 조합이 일반적입니다.
-
BIOS보다 나은 점
- 부팅 속도가 훨씬 빠릅니다.
- Secure Boot 기능을 제공합니다.
- 설정 화면 인터페이스가 훨씬 세련되고 편리합니다.
- BIOS 설정 환경은 흑백/청색 화면의 텍스트 기반 UI를 제공하고, 키보드만 사용 가능 합니다.
- UEFI 설정 환경은 그래픽 기반의 세련된 GUI를 제공하고, 마우스도 사용 가능 합니다.
- 2TB 이상의 크기를 가진 디스크를 지원합니다.
🚀 BIOS + MBR 부팅 과정
- BIOS 단계
- POST(Power On Self Test)를 수행합니다. 메모리, 키보드, 디스크 등 하드웨어를 검사합니다.
- 부팅 시퀀스에서 설정된 우선순위 순서대로 부팅할 장치를 탐색합니다. (ex. HDD1 -> HDD2 -> USB)
- 부팅 디스크의 0번 섹터(MBR)를 메모리에 로드합니다.
- MBR의 부트 코드를 실행합니다.
- MBR 부트 코드 실행 단계
- 부팅 대상이 될 파티션을 탐색합니다. (파티션 테이블에서 Active 상태의 파티션 탐색)
- 해당 파티션의 첫 번째 섹터(VBR)로 점프합니다.
- VBR 부트 코드 실행 단계
- VBR 내의 부트 코드를 실행합니다. MBR의 부트 코드와는 다른 부트 코드입니다.
- VBR 내의 부트 코드는 부트 로더(ex. GRUB)를 메모리에 로드해서 실행하는 역할을 합니다.
- 부트 로더는 커널 이미지를 메모리에 로드하여 실행합니다.
🚀 UEFI + GPT 부팅 과정
UEFI + GPT는 BIOS + MBR보다 부팅 방식이 단순해졌습니다.
- UEFI 단계
- POST를 수행합니다. (BIOS와 동일)
- UEFI에 내장된 부트 매니저가 부팅할 장치를 우선순위 순서대로 탐색합니다.
- 각 장치에 EFI(Extensible Firmware Interface) System Partition이 존재하는지 검사합니다.
- EFI System Partition에 실행 가능한
.efi파일(ex.bootx64.efi,shim.efi)이 존재하면 메모리에 로드하여 실행합니다.
.efi실행 단계
- 부트 로더(ex. GRUB)를 메모리에 로드해서 실행합니다. Secure Boot가 활성화된 경우, 부트 로더의 서명을 검증하고 검증이 통과해야 부트 로더를 실행합니다.
- 부트 로더가 커널 이미지를 로드하여 실행합니다.
❓ 마운트가 무엇인가요?
한 저장 장치의 파일 시스템에서 다른 저장 장치의 파일 시스템에 접근할 수 있도록 파일 시스템을 편입시키는 작업을 마운트라고 부릅니다.
별첨 - Linux File System Structure
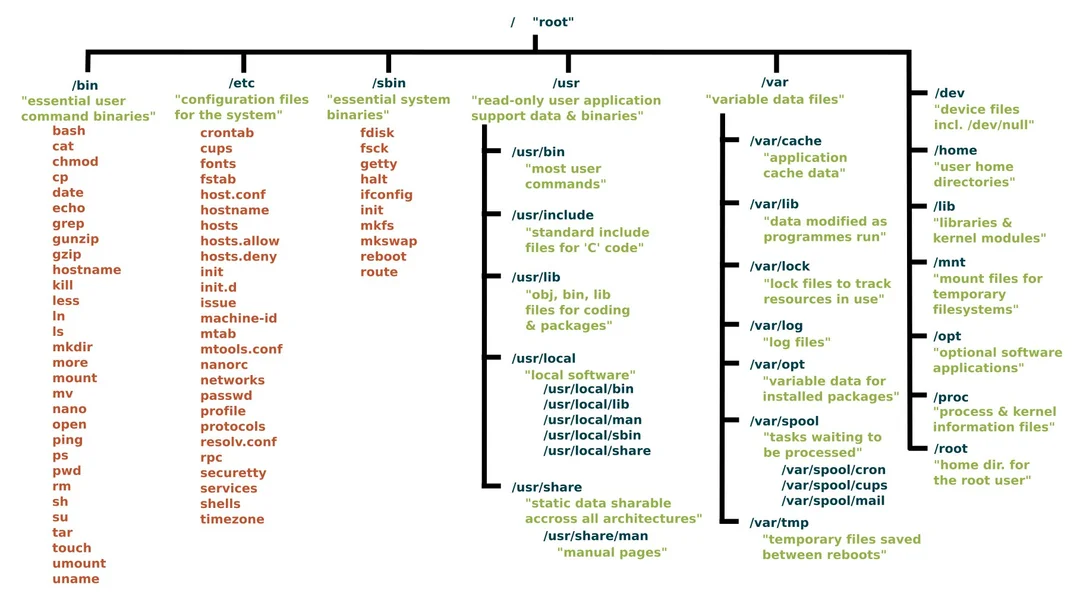
Reference
- 혼자 공부하는 컴퓨터 구조+운영체제, 강민철
- Working Set in Paging
- Computer file
- Disk Partitioning: MBR vs GPT
- BIOS
- UEFI
- Filesystem Hierarchy Standard
- A refresher on the Linux File system structure
