INTRO
이 포스트에서는 텍스트 데이터를 torch tensor까지 어떻게 바꾸는 지에 관해서 다룰 예정이다. 사실 이러한 방법에는 Word2Vec, FastText, Torchtext 등 여러가지 방법이 존재한다. 이 포스트에서는 Simple한 방법을 소개해보려고 한다. 오늘은 모델을 돌리거나 헤비한 태스크를 돌리지 않는다. 금방 끝날 것이다. (그렇다고 스압이 없는 것은 아니다.)
Code
- 실습코드
- 로컬로 실습한다면, Mecab이 설치되어 있다면 매우 좋을 것이다.
01 Sample Texts
원하는 텍스트 한 문장을 적어보자. 필자도 한 두 문장을 적어두었다. ('이 족팡매야' 같은 문장은 적지 않았다.)
sample1 = "커피가 맛이 좋네요"
sample2 = "금방 낫지를 않네요."02 Tokenizer = Mecab()
이제 토크나이저로 토큰화를 진행해보자. 필자는 일단 위 두 문장 중 sample1만으로 진행해보겠다. mecab.morphs로 토크나이징을 진행하겠다.
from konlpy.tag import Mecab
mecab = Mecab()
# Tokenizing
mecab.morphs(sample1)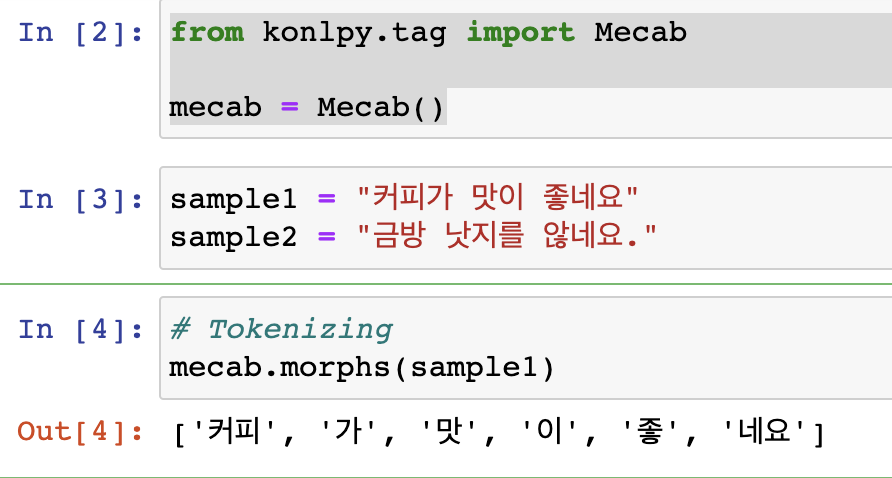
03 Build Bag-of Words
: 전체 문장을 토크나이징한 후, 각 고유 토큰마다 고유(?) int를 부여해줄 것이다. 이는 nn.Embedding()에서 필요하기 때문이다.
3-1) corpus
: 전체 문장을 리스트에 담아준다.
corpus = [sample1, sample2]
corpus 
3-2) getbow()
: Bag-of-Words를 만들어주는 함수이다. corpus를 통해서 전체 문장들을 리스트 형태로 받고, bow라는 Dictionary를 미리 만들어둔다. '<PAD>', '<BOS>', '<EOS>' key를 미리 넣어두고, 순서대로 value로 0, 1, 2를 먼저 부여해준다. 이중for문을 돌며 각 문장을 mecab.morphs()로 토크나이징하는데 각 토큰들이 bow의 key에 없다면, 그 토큰을 key로 그리고 value로 고유 넘버(len(bow.keys()))를 부여하면서 bow에 등록해준다. 그리고 for문을 다 돌면, 마지막에 bow를 return 해준다.
- 이 방법은 [Must Have] 텐초의 파이토치 딥러닝 특강 에서 얻은 방법인데, Simple하고 괜찮아보인다.
## 2) getbow
## bow: Bag of Words
def getbow(corpus):
bow = {"<PAD>" : 0, "<BOS>" : 1, "<EOS>" : 2}
for sentence in corpus:
for token in mecab.morphs(sentence):
if token not in bow.keys():
bow[token] = len(bow.keys())
return bowgetbow(corpus)를 실행하며 korbow를 만들어준다. 코드와 결과물을 보자.
korbow = getbow(corpus)
len(korbow), korbow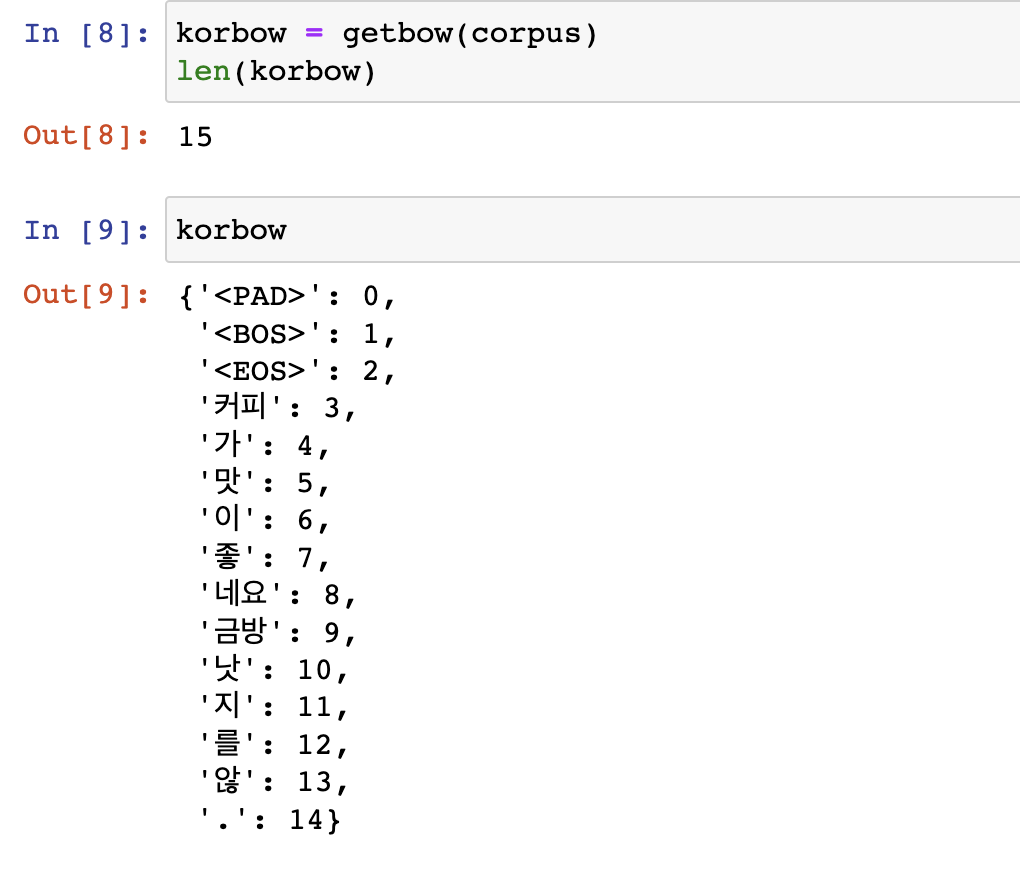
04 Text to Tensor
위에서 sample1 문장을 토크나이징한 결과를 sample1_tokens에 담자.
# Tokenizing
sample1_tokens = mecab.morphs(sample1)
sample1_tokens
05 '<BOS>', '<EOS>' Token
: 문장의 시작과 끝을 컴퓨터에게 알려주기 위해 문장의 시작과 끝에 '<BOS>', '<EOS>'을 붙여준다.
- TASK에 따라서 붙이지 않는다고도 한다.
- HuggingFace의 Tokenizer의 경우, add_speical_tokens = True
# <BOS>, <EOS> 를 양 끝에 붙임
sample1_tokens = ['<BOS>'] + sample1_tokens + ['<EOS>']
sample1_tokens
06 Max_length & '<PAD>' Token
- DataLoader에서 나오는 배치 단위의 데이터를 생각해보자.
: 보통 DataLoader에서 뱉어주는 데이터 형태는 주로 [bs, CH, H, W], [bs, N] 등 일정한 형태이다. 그렇다면, 여기서는 어떤 형태로 뱉어주게 될까? 결론적으로는 [bs, sl] 형태로 뱉어주게 된다. bs는 문장의 개수를 의미하고 sl은 최대문장길이(=토큰의 개수)를 의미한다. - 문장길이는 다 다르다.
: 문장 길이는 다 다르기 때문에, 데이터셋 중 가장 긴 문장 길이를 기준으로 짧은 문장들을 최대길이에 맞출 수 있도록, '<PAD>' 토큰들을 붙여(=패딩) 준다. 가령 최대 문장길이가 10인데, 한 문장의 길이가 7이라고 한다면, 3개의 '<PAD>' 토큰들을 붙여주는 형태이다.- HuggingFace의 DataCollatorWithPadding를 사용하면, 배치 내에서 가장 긴 문장을 토대로 패딩이 가능하다.
> sl = 10 & '<PAD>' Token
: 현재 Sequence Length(=max_length)를 10 으로 하자
# <PAD>: Padding
# 현재 Sequence Length = 10 이라고 하자
sl = 10
sample1_tokens = sample1_tokens + ['<PAD>'] * (sl - len(sample1_tokens))
sample1_tokens
07 Token to Torch Tensor & Batch Size
: 위에서 만들었던 korbow 로 토큰들을 'int'로 바꾸어보자.
## Text to Int by korbow
sample1_ints = np.array([korbow[token] for token in sample1_tokens])
sample1_ints ## np.array
그리고 이번에는 Torch Tensor로 바꾸어보고 unsqueeze(0)으로 배치 차원의 정보를 만들어주자.
- 원래는 DataLoader 통해서 Batch Size 정보까지 나오지만, 현재는 DataLoader를 통한 것이 아니라서 인위적으로 만들어주는 것이다.
- 한 문장이니까 배치 사이즈는 1이다.
- torch.long은 Int이다.
## to Torch Tensor
sample1_tensor = torch.tensor(sample1_ints, dtype = torch.long)
# torch.long은 Int
sample1_tensor = sample1_tensor.unsqueeze(0)
# Batch Size = 1
sample1_tensor
# Shape: [1, 10]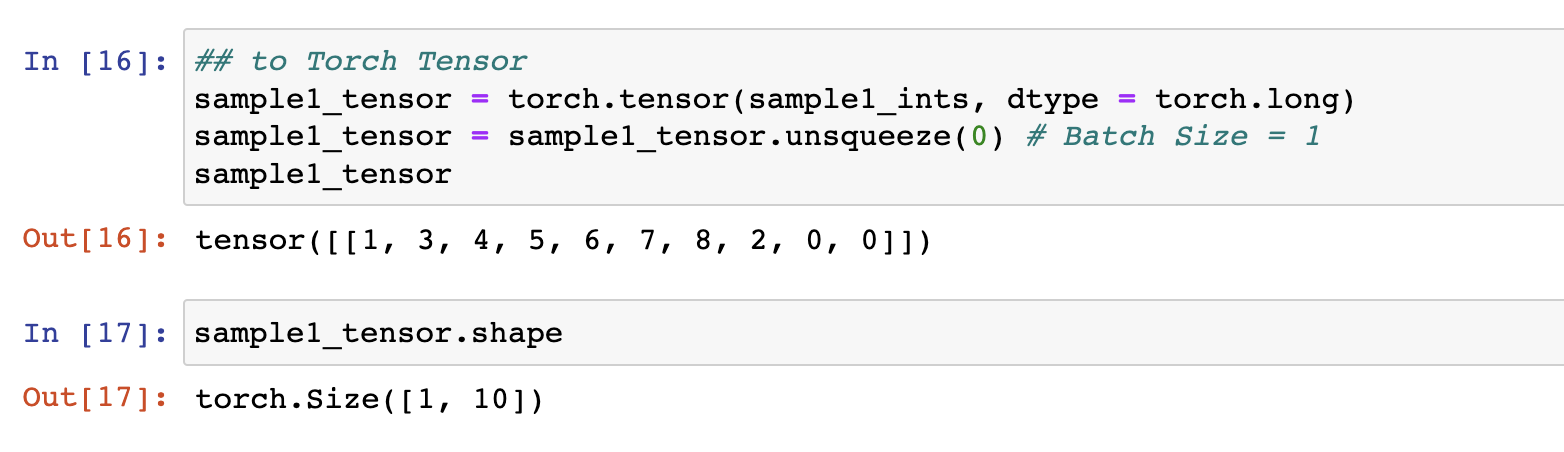
08 nn.Embedding()
- 전반적인 플로우를 그림으로 그려보자면 다음과 같다.
: Text -> Token -> Int -> Torch Tensor -> nn.Embedding()
- 직접 그림
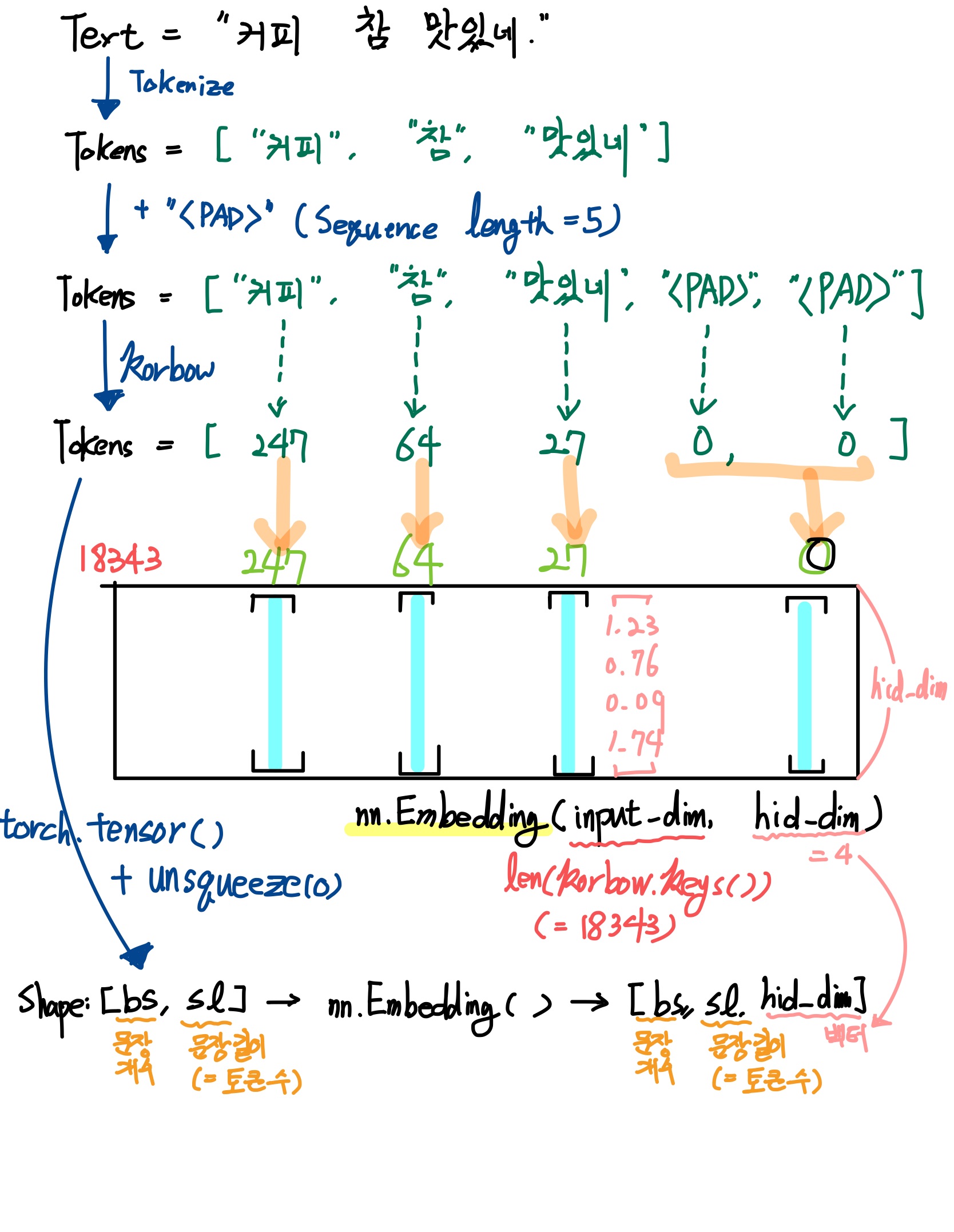
-
(위 플로우를 참고해서 보면) nn.Embedding() 은 korbow 로 각 token에 대해 부여된 고유 int 대해서 특정 차원의 벡터로 뱉어준다.
-
Shape: [bs, sl] -(nn.Embedding())-> [bs, sl, emb_dim]
-
korbow의 Values 값들은 Int로 구성되어있고, Key들은 Token으로 구성되어있다. nn.Embedding()은 모든 Int에 대해서(=각각의 Int마다) emb_dim 차원의 고유벡터를 가지고 있다. 마치 사전처럼. 그래서 Value값인 Int들이 nn.Embedding()을 통과하면, 각각 emb_dim 길이만큼의 실수로 이루어진 고유의 Vector로 반환되어지는 것이다.
-
비유를 하자면, 학급에서 각 학생마다 출석번호(Int)가 있고 담임선생님이 출석부(nn.Embedding())를 통해서 각 학생의 주민등록번호(Vector)가 담겨있어서 특정 학생들의 출석번호만 알면, 그 학생들의 주민번호를 쉽게 확인할 수 있다고 생각하면 편할 것이다.
-
LookUp-Table
- nn.Embedding()은 LookUp-Table의 역할을 한다. 각 토큰별로 특정 길이의 벡터로 표현된다. DataLoader를 통해서 뱉어지는 배치 단위의 데이터([bs, sl]) 에 있는 각 토큰들은 이 nn.Embedding()을 통해서 해당하는 고유 벡터들로 변환된다.
- nn.Embedding()은 Word2Vec, FastText 등으로 훈련한 Word Embedding 모델을 nn.Embedding()에 얹혀서 만들 수 있다. (torchtext 라이브러리에서 build_vocab으로 훈련하는 방법도 존재한다. - 참고1)
-
nn.Embedding()에 대해서 더 자세히 알고 싶다면 여기를 참고하면 된다.
-
-
nn.Embedding(input_dim, emb_dim)
: 코드로 보면, 다음과 같다.-
nn.Embedding('<마지막 정수(Int)>', '<벡터 차원의 길이>')
-
위에서 sample1_tensor을 통과시켜보자.
: 벡터 차원의 길이는 7로 하여서, 각 토큰별로 7개의 실수로 이루어진 고유벡터로 표현하게끔 해보자.## nn.Embedding() input_dim = len(korbow.keys()) # korbow의 길이 emb_dim = 7 # 표현할 벡터 차원의 수 embed = nn.Embedding(input_dim, emb_dim) # nn.Embedding() 레이어 sample1_vector = embed(sample1_tensor) # sample1_tensor를 통과한 결과

sample1_vector은 다음과 같다.
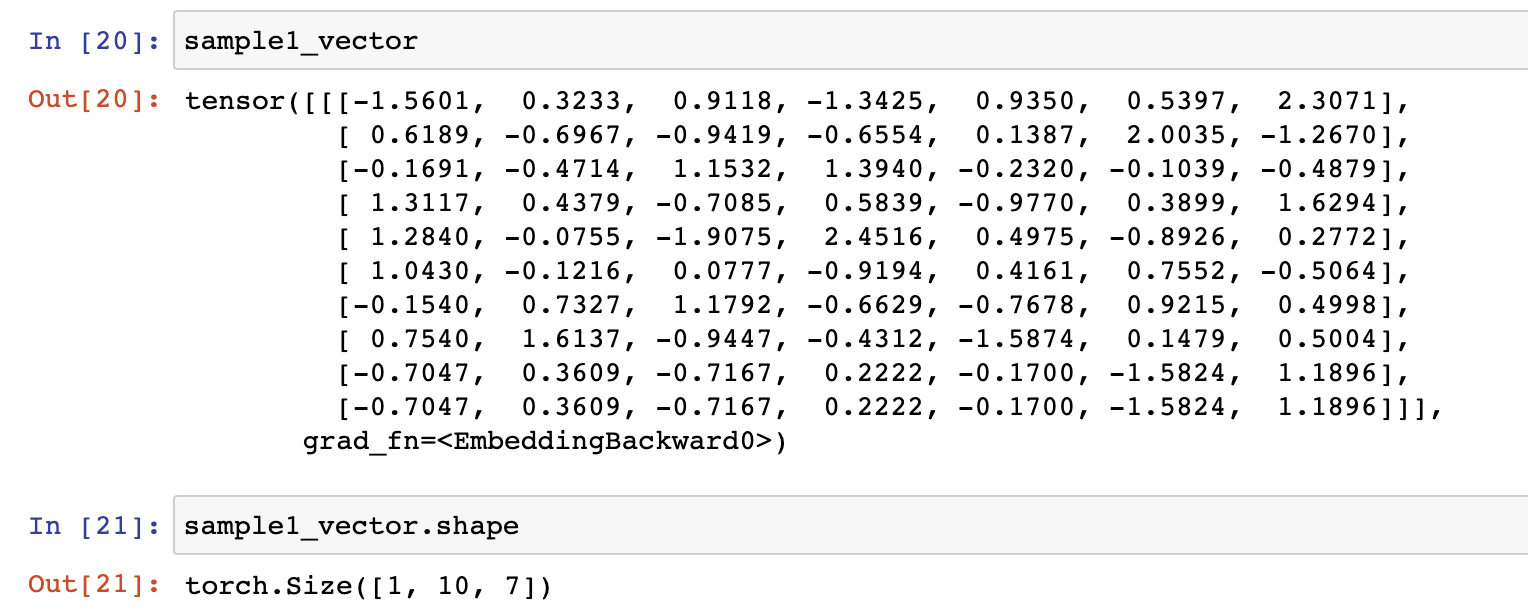
-
09 Embedding 통과한 OUTPUT
: nn.Embedding()을 통해서 나온 3차원 입력데이터(sample1_vector)를 GRU에 넣어보자. (물론, 이 때 h0가 필요하다.)
- LSTM, RNN, GRU 등을 이용해서 Text Classification Task를 진행할 수 있다.
- Transformer Model을 Pytorch로 구현할 때 등장하기도 한다.
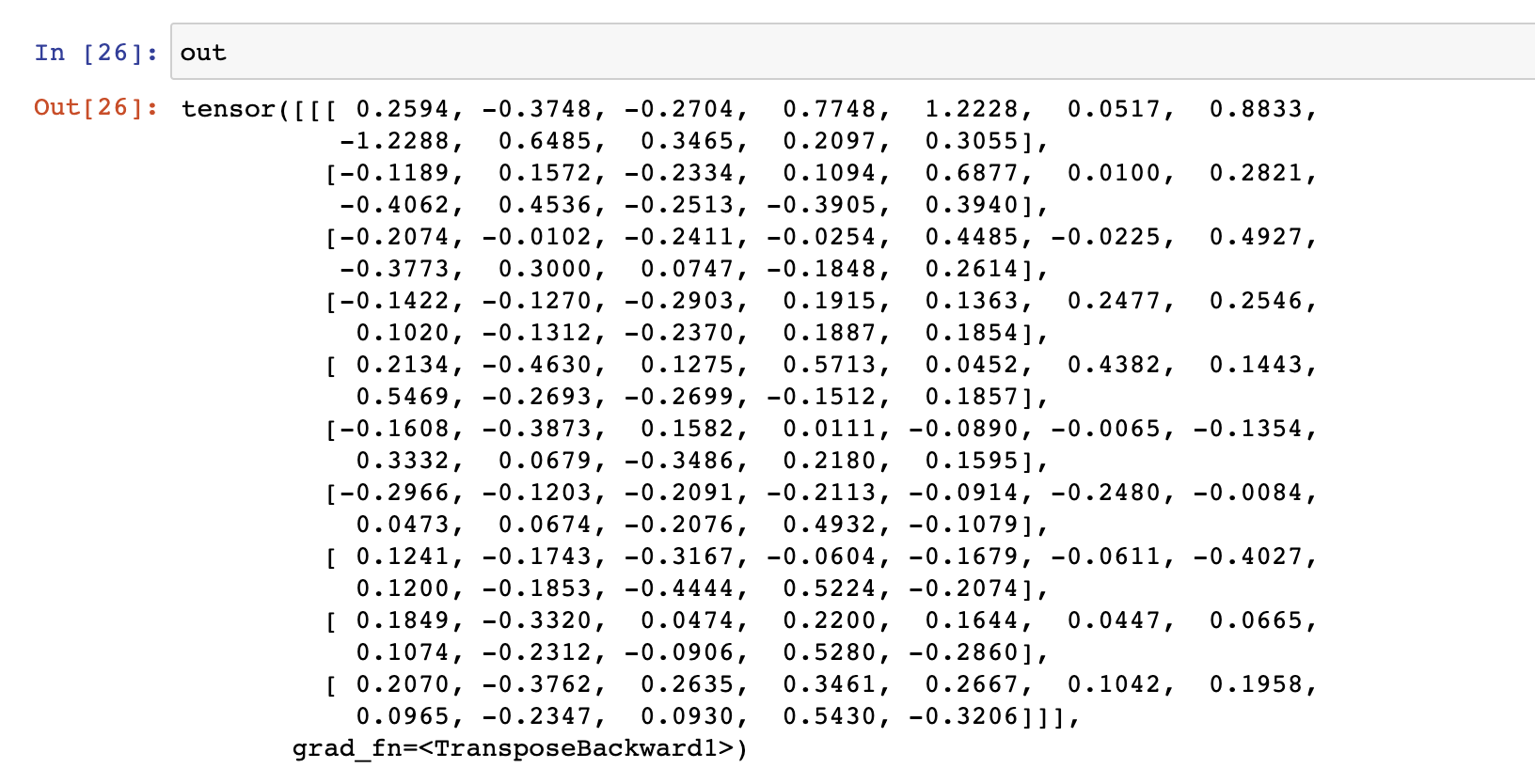
## nn.GRU
gru = nn.GRU(input_size = emb_dim,
hidden_size= 12,
num_layers = 1,
bidirectional = False,
batch_first = True)
h0 = torch.randn(1, 1, 12)
# num_layers, batch_size, hidden_size
out, h_n = gru(sample1_vector, h0)
out.shape, h_n.shape
여기까지
- 다음시간에는 이를 기반으로 한 RNN계열 모델을 이용한 Text Classification을 해보려고 한다.
