
INTRO
1) 지난 시간에 이어서 시계열 데이터 예측을 다른 모델과 다른 방법으로 진행해보려 한다.
2) RNN에 대한 기본적인 개념과 지식은 어느 정도 알고 있다고 가정하고 시작하겠다.
- Kaggle에 Bitcoin Historical Data 라는 데이터셋을 사용한다.
- EDA, PREPROCESSING 모두 생략 -> BASIC FLOW에 익히는 것이 목적
- X columns:Open, High, Low
- y column: Close
- 361370의 Row가 존재하는 데, 이 중 1%만 사용
: 좀 오래 걸리기 때문 (원한다면 100% 써서 사용해보자.)
- [가장 중요] 데이터의 Shape 추적은 반드시 하자.
- 혹시라도 잘못된 부분이 있다면 꼭 알려줬으면 한다.
참고할 Colab
- 03 RNN.ipynb
: [토치의 호흡] 03 RNN and his firends PART 01 의 실스코드 링크 - LSTM 모델을 베이스로 2 가지 방법으로 예측한 실습코드
- 05_GRU.ipynb
: RNN 모델에서 GRU 모델로 변경해서 진행 - 06 BiRNN.ipynb
: bidirectional = True 로 양방향 학습이 가능한 모델로 학습 진행한 실습코드
01 RNN vs Bi-RNN (bidirectional = True)
- nn.RNN 레이어 파라미터 중 bidecrectional = True로 놓으면, 양방향 학습을 한다.
- AutoRegressive vs Non-AutoRegressive
: 양방향 학습에 적합한 경우는 주가 예측보다는 Sentence에 적합하다.
- AutoRegressive vs Non-AutoRegressive
- 아래 Model 코드를 비교할 수 있도록 작성해두었다. 한 번 보도록 하자.
- sl을 비롯한 일부 변수의 숫자는 조금씩 다를 것이다.
1) RNN Model (Basic)
- 코드 중 Build Model 부분을 보자.
- 참고: 03 RNN.ipynb
class RNNModel(nn.Module):
def __init__(self,
input_size = 3, # open, high, low
hidden_size = 100,
num_layers= 3,
sequence_length = sl,
device = device
):
super().__init__()
self.num_layers = num_layers
self.sequence_length = sequence_length
self.hidden_size = hidden_size
self.device = device
# RNN 레이어
# https://pytorch.org/docs/stable/generated/torch.nn.RNN.html
self.rnn = nn.RNN(input_size = input_size,
hidden_size = hidden_size,
num_layers = num_layers,
batch_first = True,
bidirectional = False)
# input(=x)'s shape: [bs, sl, input_size]
# input_h0 = [num_layers, bs, hidden_size]
# output(=y)'s shape: [bs, sl, hidden_size]
# output_h = [num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
k = self.sequence_length * self.hidden_size
# 2) Use output's Last Sequence Length
# k = 1 * self.hidden_size
# Fully Connected Layer
self.seq = nn.Sequential(
# [bs, sl, hidden_size] -> [bs, sl * hidden_size]
nn.Linear(k, 256),
nn.LeakyReLU(),
nn.Linear(256, 1)
# [bs, k] -> [bs, 256] -> [bs, 1]
)
def forward(self, x):
# x: [bs, sl, input_size]
bs = x.shape[0]
h0 = torch.zeros(self.num_layers, bs, self.hidden_size).to(self.device)
# h0: [num_layers, bs, hidden_size]
output, h_n = self.rnn(x, h0)
# output's shape: [bs, sl, hidden_size]
# h_n = [num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
output = output.reshape(bs, -1) # [bs, sl, hidden_size] -> [bs, sl * hidden_size]
# 2) Use output's Last Sequence Length
# output = output[:, -1] # [bs, hidden_size]
# [bs, k] -> [bs, 256] ->[bs, 1]
y_pred = self.seq(output)
# y_pred: [bs, 1]
return y_pred위 모델로 실제값과 예측값 비교를 시각화
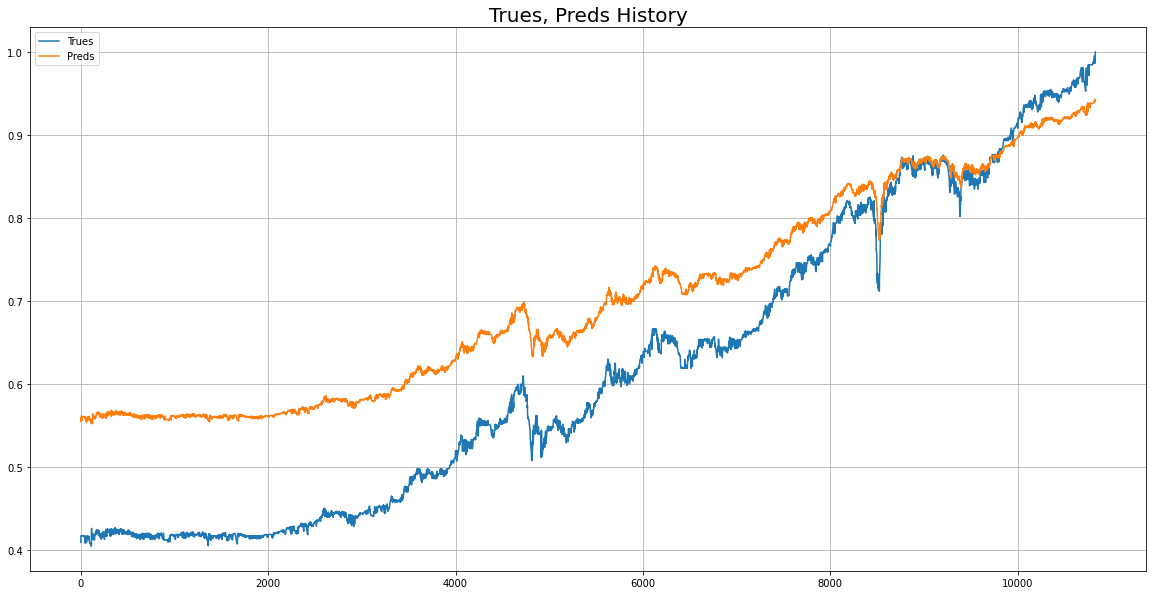
2) Bi-RNN Model
- bidirectional = True 일 때의 Model
- 코드 중 Build Model 부분을 보자.
- 참고: 06 BiRNN.ipynb
class BiRNNModel(nn.Module):
def __init__(self,
input_size = 3, # open, high, low
hidden_size = 100,
num_layers= 3,
sequence_length = sl,
device = device
):
super().__init__()
self.num_layers = num_layers
self.sequence_length = sequence_length
self.hidden_size = hidden_size
self.device = device
# RNN 레이어
self.rnn = nn.RNN(input_size = input_size, hidden_size = hidden_size,
num_layers = num_layers,
batch_first = True, bidirectional = True)
# input(=x)'s shape: [bs, sl, input_size]
# input_h0 = [2*num_layers, bs, hidden_size]
# output(=y)'s shape: [bs, sl, 2*hidden_size]
# output_h = [2*num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
k = self.sequence_length * 2 * self.hidden_size
# 2) Use output's Last Sequence
# k = 1 * 2 * self.hidden_size
# Fully Connected Layer
self.seq = nn.Sequential(
# [bs, sl, hidden_size] -> [bs, sl * hidden_size]
nn.Linear(k, 256), nn.LeakyReLU(), nn.Linear(256, 1)
# [bs, k] -> [bs, 256] -> [bs, 1]
)
def forward(self, x):
# x: [bs, sl, input_size]
bs = x.shape[0]
h0 = torch.zeros(2 * self.num_layers, bs, self.hidden_size).to(self.device)
# h0: [2*num_layers, bs, hidden_size]
output, h_n = self.rnn(x, h0)
# output's shape: [bs, sl, 2*hidden_size]
# h_n = [2*num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
output = output.reshape(bs, -1)
# 2) Use output's Last Sequence
# output = output[:, -1]
# output's shape: [bs, 2*hid_dim]
# [bs, k] -> [bs, 256] ->[bs, 1]
y_pred = self.seq(output)
# y_pred: [bs, 1]
return y_pred위 모델로 실제값과 예측값 비교를 시각화
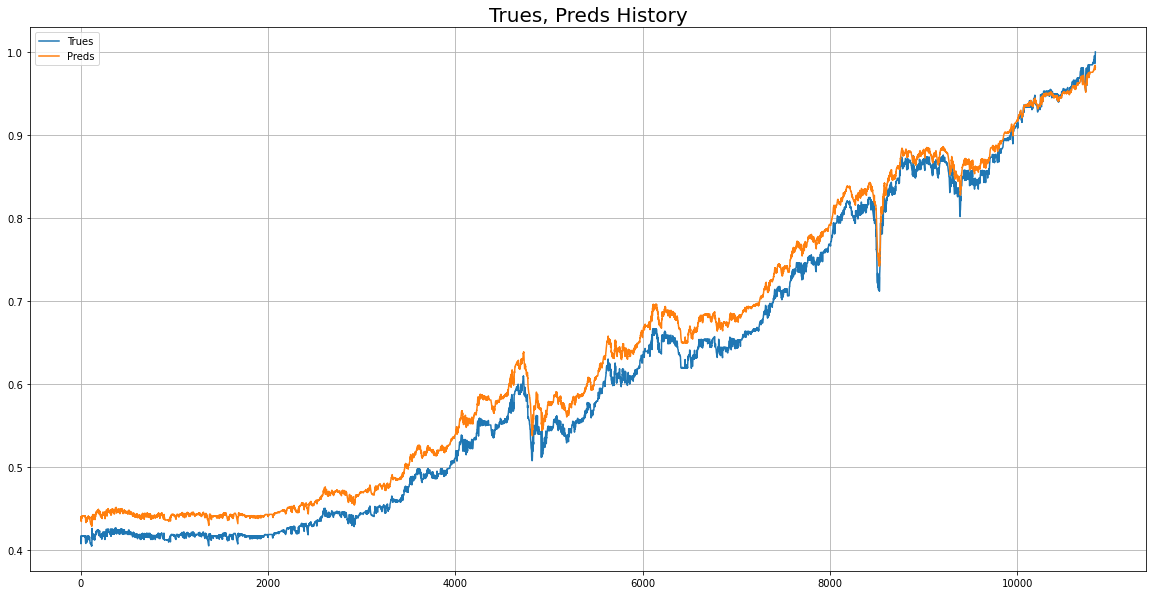
02 LSTM
- (간략한 한 줄 설명) LSTM 모델은 RNN의 한계를 개선하기 위해 고안이 되었다. (참고)
- LSTM 모델로 두 가지의 예측 방법(?)을 보여주도록 하겠다.
: 여거시 소개하는 두 가지 방법에 대한 장단점 혹은 성능에 어떤 영향을 끼치는 지 한 번 생각해보자.
1) OUTPUT : 3차원을 2차원으로 Reshape 해서 예측
- 코드 중 Build Model 부분을 보자.
- 참고: 04 LSTM PART 1) 3차원에서 2차원으로.ipynb
class LSTMModel(nn.Module):
def __init__(self,
input_size = 3, # open, high, low
hidden_size = 80,
num_layers= 3,
sequence_length = sl, # sl = 7
device = device
):
super().__init__()
self.num_layers = num_layers
self.sequence_length = sequence_length
self.hidden_size = hidden_size
self.device = device
# LSTM 레이어
# https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html
self.rnn = nn.LSTM(input_size = input_size, hidden_size = hidden_size,
num_layers = num_layers,
batch_first = True, bidirectional = False)
# input(=x)'s shape: [bs, sl, input_size]
# input_h0 = [num_layers, bs, hidden_size]
# input_c0 = [num_layers, bs, hidden_size]
# output(=y)'s shape: [bs, sl, hidden_size]
# output_h = [num_layers, bs, hidden_size]
# output_c = [num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
k = self.sequence_length * self.hidden_size
# 2) Use output's Last Sequence
# k = 1 * self.hidden_size
# Fully Connected Layer
self.seq = nn.Sequential(
# [bs, sl, hidden_size] -> [bs, sl * hidden_size]
nn.Linear(k, 256), nn.LeakyReLU(), nn.Linear(256, 1)
# [bs, k] -> [bs, 256] -> [bs, 1]
)
def forward(self, x):
# x: [bs, sl, input_size]
bs = x.shape[0]
h0 = torch.zeros(self.num_layers, bs, self.hidden_size).to(self.device)
# h0: [num_layers, bs, hidden_size]
c0 = torch.zeros(self.num_layers, bs, self.hidden_size).to(self.device)
# c0: [num_layers, bs, hidden_size]
output, (h_n, c_n) = self.rnn(x, (h0, c0))
# output's shape: [bs, sl, hidden_size]
# h_n = [num_layers, bs, hidden_size]
# c_n = [num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
output = output.reshape(bs, -1)
# 2) Use output's Last Sequence
# output = output[:, -1]
# output's shape: [bs, hid_dim]
# [bs, k] -> [bs, 256] ->[bs, 1]
y_pred = self.seq(output)
# y_pred: [bs, 1]
return y_pred위 모델로 실제값과 예측값 비교를 시각화
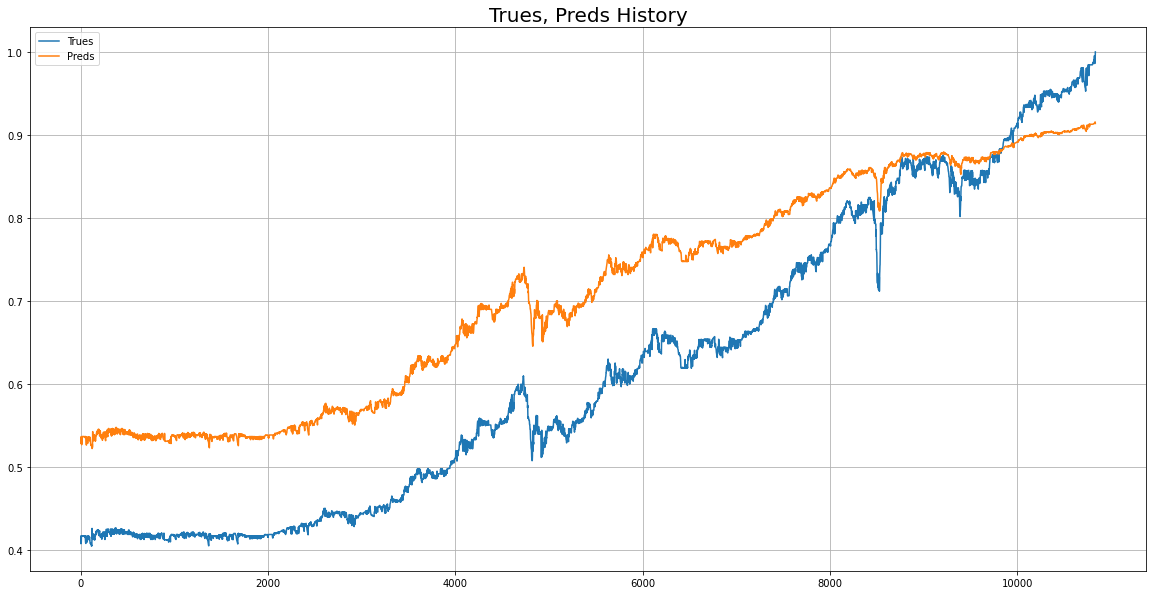
2) OUTPUT의 Sequence Length 마지막 Index만 선택하여 예측
- 코드 중 Build Model 부분을 보자.
- 참고: 04 LSTM PART 2) Use output's Last Sequence.ipynb
class LSTMModel(nn.Module):
def __init__(self,
input_size = 3, # open, high, low
hidden_size = 80,
num_layers= 3,
sequence_length = sl, # sl = 3
device = device
):
super().__init__()
self.num_layers = num_layers
self.sequence_length = sequence_length
self.hidden_size = hidden_size
self.device = device
# LSTM 레이어
# https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html
self.rnn = nn.LSTM(input_size = input_size, hidden_size = hidden_size,
num_layers = num_layers,
batch_first = True, bidirectional = False)
# input(=x)'s shape: [bs, sl, input_size]
# input_h0 = [num_layers, bs, hidden_size]
# input_c0 = [num_layers, bs, hidden_size]
# output(=y)'s shape: [bs, sl, hidden_size]
# output_h = [num_layers, bs, hidden_size]
# output_c = [num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
# k = self.sequence_length * self.hidden_size
# 2) Use output's Last Sequence
k = 1 * self.hidden_size
# Fully Connected Layer
self.seq = nn.Sequential(
# [bs, sl, hidden_size] -> [bs, sl * hidden_size]
nn.Linear(k, 256), nn.LeakyReLU(), nn.Linear(256, 1)
# [bs, k] -> [bs, 256] -> [bs, 1]
)
def forward(self, x):
# x: [bs, sl, input_size]
bs = x.shape[0]
h0 = torch.zeros(self.num_layers, bs, self.hidden_size).to(self.device)
# h0: [num_layers, bs, hidden_size]
c0 = torch.zeros(self.num_layers, bs, self.hidden_size).to(self.device)
# c0: [num_layers, bs, hidden_size]
output, (h_n, c_n) = self.rnn(x, (h0, c0))
# output's shape: [bs, sl, hidden_size]
# h_n = [num_layers, bs, hidden_size]
# c_n = [num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
# output = output.reshape(bs, -1)
# 2) Use output's Last Sequence
output = output[:, -1]
# output's shape: [bs, hid_dim]
# [bs, k] -> [bs, 256] ->[bs, 1]
y_pred = self.seq(output)
# y_pred: [bs, 1]
return y_pred위 모델로 실제값과 예측값 비교를 시각화
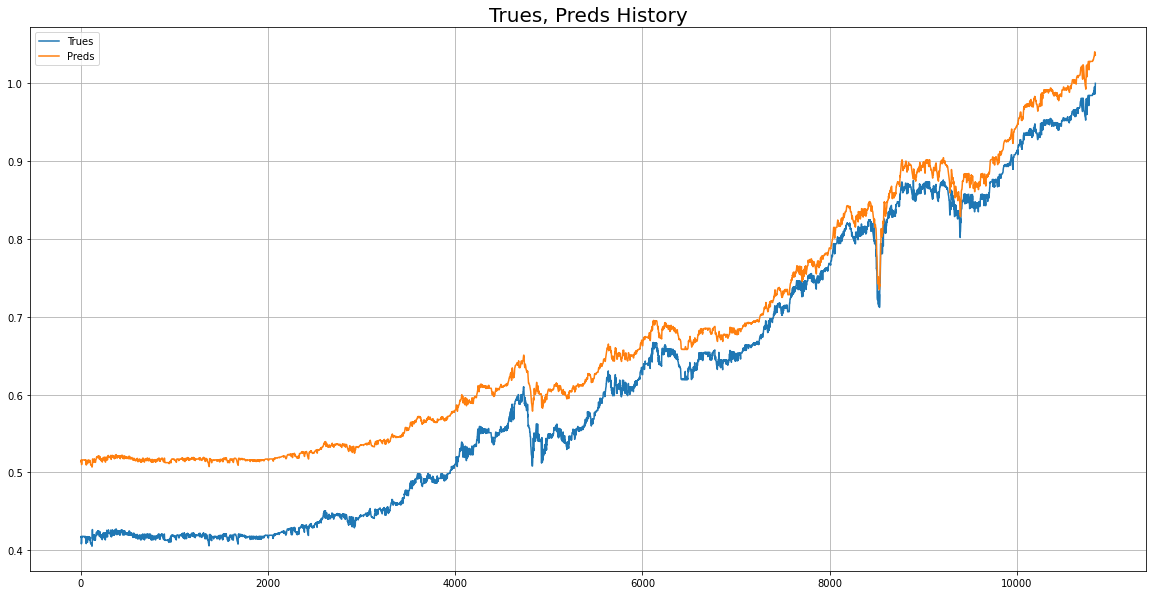
03 GRU
: GRU 모델은 LSTM 모델을 경량화시킨 모델이고, 한국인 조경현 박사님으로부터 제안된 모델이다. (참고)
- LSTM보다 성능은 떨어지지만, 미미한 정도로 알고 있다.
- GRU는 RNN과 똑같은 방법으로 사용하면 된다.
- 아래 RNN, LSTM GRU 순으로 코드와 예측 결과를 보여주겠다.
- OUTPUT의 3차원을 2차원으로 Reshape 해서 진행
- 실제로 코드에서 보면 sl 등 일부 변수와 모델 파라미터로 준 값은 조금 다를 것이다.
- 제대로 된 비교를 하려면, 동일한 조건에서 진행해야하는 것이 맞지만, 그렇게 했으나 (아직 필자의 내공이 부족하여) 원하는 그림이나 실험으로 나오지 않았기에(아예 학습이 안 되는 경우도 있었다.) 조금 다르게 줘서 진행했다.
1) RNN Model
- 코드 중 Build Model 부분을 보자.
- 참고: 03 RNN.ipynb
class RNNModel(nn.Module):
def __init__(self,
input_size = 3, # open, high, low
hidden_size = 100,
num_layers= 3,
sequence_length = sl,
device = device
):
super().__init__()
self.num_layers = num_layers
self.sequence_length = sequence_length
self.hidden_size = hidden_size
self.device = device
# RNN 레이어
# https://pytorch.org/docs/stable/generated/torch.nn.RNN.html
self.rnn = nn.RNN(input_size = input_size,
hidden_size = hidden_size,
num_layers = num_layers,
batch_first = True,
bidirectional = False)
# input(=x)'s shape: [bs, sl, input_size]
# input_h0 = [num_layers, bs, hidden_size]
# output(=y)'s shape: [bs, sl, hidden_size]
# output_h = [num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
k = self.sequence_length * self.hidden_size
# 2) Use output's Last Sequence Length
# k = 1 * self.hidden_size
# Fully Connected Layer
self.seq = nn.Sequential(
# [bs, sl, hidden_size] -> [bs, sl * hidden_size]
nn.Linear(k, 256),
nn.LeakyReLU(),
nn.Linear(256, 1)
# [bs, k] -> [bs, 256] -> [bs, 1]
)
def forward(self, x):
# x: [bs, sl, input_size]
bs = x.shape[0]
h0 = torch.zeros(self.num_layers, bs, self.hidden_size).to(self.device)
# h0: [num_layers, bs, hidden_size]
output, h_n = self.rnn(x, h0)
# output's shape: [bs, sl, hidden_size]
# h_n = [num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
output = output.reshape(bs, -1) # [bs, sl, hidden_size] -> [bs, sl * hidden_size]
# 2) Use output's Last Sequence Length
# output = output[:, -1] # [bs, hidden_size]
# [bs, k] -> [bs, 256] ->[bs, 1]
y_pred = self.seq(output)
# y_pred: [bs, 1]
return y_pred위 모델로 실제값과 예측값 비교를 시각화
2) LSTM Model
- 코드 중 Build Model 부분을 보자.
- 참고: 04 LSTM PART 1) 3차원에서 2차원으로.ipynb
class LSTMModel(nn.Module):
def __init__(self,
input_size = 3, # open, high, low
hidden_size = 80,
num_layers= 3,
sequence_length = sl, # sl = 7
device = device
):
super().__init__()
self.num_layers = num_layers
self.sequence_length = sequence_length
self.hidden_size = hidden_size
self.device = device
# LSTM 레이어
# https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html
self.rnn = nn.LSTM(input_size = input_size, hidden_size = hidden_size,
num_layers = num_layers,
batch_first = True, bidirectional = False)
# input(=x)'s shape: [bs, sl, input_size]
# input_h0 = [num_layers, bs, hidden_size]
# input_c0 = [num_layers, bs, hidden_size]
# output(=y)'s shape: [bs, sl, hidden_size]
# output_h = [num_layers, bs, hidden_size]
# output_c = [num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
k = self.sequence_length * self.hidden_size
# 2) Use output's Last Sequence
# k = 1 * self.hidden_size
# Fully Connected Layer
self.seq = nn.Sequential(
# [bs, sl, hidden_size] -> [bs, sl * hidden_size]
nn.Linear(k, 256), nn.LeakyReLU(), nn.Linear(256, 1)
# [bs, k] -> [bs, 256] -> [bs, 1]
)
def forward(self, x):
# x: [bs, sl, input_size]
bs = x.shape[0]
h0 = torch.zeros(self.num_layers, bs, self.hidden_size).to(self.device)
# h0: [num_layers, bs, hidden_size]
c0 = torch.zeros(self.num_layers, bs, self.hidden_size).to(self.device)
# c0: [num_layers, bs, hidden_size]
output, (h_n, c_n) = self.rnn(x, (h0, c0))
# output's shape: [bs, sl, hidden_size]
# h_n = [num_layers, bs, hidden_size]
# c_n = [num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
output = output.reshape(bs, -1)
# 2) Use output's Last Sequence
# output = output[:, -1]
# output's shape: [bs, hid_dim]
# [bs, k] -> [bs, 256] ->[bs, 1]
y_pred = self.seq(output)
# y_pred: [bs, 1]
return y_pred위 모델로 실제값과 예측값 비교를 시각화
3) GRU Model
- 코드 중 Build Model 부분을 보자.
- 참고: 05 GRU.ipynb
class GRUModel(nn.Module):
def __init__(self,
input_size = 3, # open, high, low
hidden_size = 100,
num_layers= 2,
sequence_length = sl,
device = device
):
super().__init__()
self.num_layers = num_layers
self.sequence_length = sequence_length
self.hidden_size = hidden_size
self.device = device
# GRU 레이어
# https://pytorch.org/docs/stable/generated/torch.nn.GRU.html
self.rnn = nn.GRU(input_size = input_size, hidden_size = hidden_size,
num_layers = num_layers,
batch_first = True, bidirectional = False)
# input(=x)'s shape: [bs, sl, input_size]
# input_h0 = [num_layers, bs, hidden_size]
# output(=y)'s shape: [bs, sl, hidden_size]
# output_h = [num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
k = self.sequence_length * self.hidden_size
# 2) Use output's Last Sequence
# k = 1 * self.hidden_size
# Fully Connected Layer
self.seq = nn.Sequential(
# [bs, sl, hidden_size] -> [bs, sl * hidden_size]
nn.Linear(k, 256), nn.LeakyReLU(), nn.Linear(256, 1)
# [bs, k] -> [bs, 256] -> [bs, 1]
)
def forward(self, x):
# x: [bs, sl, input_size]
bs = x.shape[0]
h0 = torch.zeros(self.num_layers, bs, self.hidden_size).to(self.device)
# h0: [num_layers, bs, hidden_size]
output, h_n = self.rnn(x, h0)
# output's shape: [bs, sl, hidden_size]
# h_n = [num_layers, bs, hidden_size]
# 1) 3차원 -> 2차원
output = output.reshape(bs, -1)
# 2) Use output's Last Sequence
# output = output[:, -1]
# output's shape: [bs, hid_dim]
# [bs, k] -> [bs, 256] ->[bs, 1]
y_pred = self.seq(output)
# y_pred: [bs, 1]
return y_pred위 모델로 실제값과 예측값 비교를 시각화
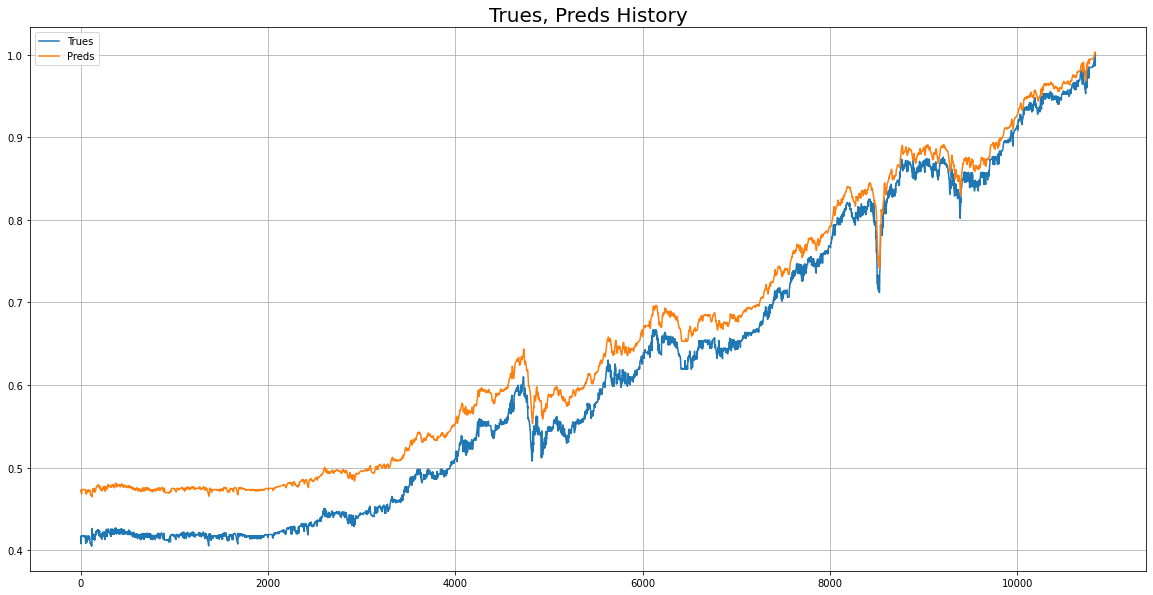
RNN and his friends PART 02 끝
: 이로써 여기까지 RNN과 다른 모델들 그리고 예측 방법을 소개하였다. 이것들을 토대로 다양하게 실험을 진행해보고 공부해보는 것 또한 방법이다. 나머지는 여러분께 맡기겠다.

weird