
INTRO
2022년 11월 22일쯤에 우연히 BetterTransformer, Out of the Box Performance for Hugging Face Transformers이 포스트를 발견하였다. 들뜬 마음에, 링크부터 저장하였다. 원래는 무언가 실험을 하고 싶었으나, '토치의 호흡' 강의하드캐리하느라 시간이 없어서 다소곳하게 SLACK 한 구석에다가 링크만 저장해두었다가, 이제서야 보면서 실험을 해보았다.
그런데... 문제는 BetterTransformer을 목적을 아직 잘 모르겠다는 것이다. (아마 필자의 내공이 아직 부족해서 그럴 것이다.) 이유는 이제부터 차차 말해보겠다.
- 실습은 필자의 경우, M1에서 진행하였고, Pytorch 2.0과 transformers 4.21.1 버전이 설치된 conda 환경에서 진행했다. (M2도 가능) 혹시 모르니 다음을 참고하길 바란다.
- 중요! BetterTransformer의 경우 Pytorch 1.13이상의 버전에서 호환이 된다.
- M1 Part6 - '니들이 mps를 아느냐?' Install Pytorch(GPU) on M1 ver.220624
: 아무 것도 안 깔려있다면, 위 링크 방법대로 설치했을 때, PYTORCH 2.0으로 설치가 될 것이다. - M1 Part10 - '니들이 Pytorch 2.0을 아느냐?' Install Pytorch(GPU) on M1 ver.221230
- M1 Part7 - "Hugging Face Transformers Installation on M1"
- 참고한 링크들
- A BetterTransformer for Fast Transformer Inference
: BetterTransformer, Out of the Box Performance for Hugging Face Transformers와 비슷한 내용의 링크라고 보면 된다. 설명이 좀 더 구체적으로 되어있다.- Thanks to 내 (전 직계제자이자) 팀멭
- Colab Link: 다양한 실습 예제들이 나와있다.
- https://huggingface.co/docs/optimum/bettertransformer/overview
: 대략적인 정보를 볼 수 있다. - https://huggingface.co/docs/optimum/bettertransformer/tutorials/convert
: 튜토리얼 느낌 - https://huggingface.co/docs/optimum/bettertransformer/tutorials/contribute
: 구조적인 부분을 더 잘 볼 수 있다.
- A BetterTransformer for Fast Transformer Inference
Need to Know
: BetterTransformer로 model을 변환한 뒤, 학습에 쓰려고 하면 ... 다음과 같이 에러가 난다. (상세하게 말해보자면) 개인적으로 학습에 써보려고 Text Classification 에 쓰려고 roberta-base 모델에 적용하려고 했는데 다음과 같이 에러가 났다. 보고 "응...? Training 지원 안 된다고...?" 하는 생각에 10초 이상 멍 때렸던 것 같다.
결론부터 말하면, BetterTransformer는 Inference 전용이다. 필자는 이에 대해서 간과하고 (+ 위 링크의 글들을 제대로 주의깊게 안 읽고) 돌려봤으니 당연한 결과이다.
ValueError: ('Training is not supported for `BetterTransformer` integration.', ' Please use `model.eval()` before running the model.') 
- A BetterTransformer for Fast Transformer Inference에 의하면, BetterTransformer의 존재 목적 자체는 빠른 연산에 있다. 트랜스포머의 Encoder, EncoderLayer, MultiHeadAttention 부분을 다음 대표적인 두 가지 방법으로 가속화시킨다고 표현한다.
- (1) fused kernel
: 이 부분은 잘 모르겠는데, 독립적인 operator들을 잘 조합했다는 것 같다. 즉, 코드를 잘 짜서, 효율성을 극대화한 것으로 보인다.- fused kernels combine multiple individual operators normally used to implement Transformers to provide a more efficient implementation
- (2) Exploiting(?) sparsity in the inputs
: 연산에 불필요한 pad_token 부분을 이용한다고 표현되어있는데, 아마 이 부분을 건너뛰는 것 같다.- BetterTransformer exploits sparsity by simply avoiding unnecessary computation of padding tokens using nested tensors. - 출처
- (1) fused kernel
- BetterTransformer는 HuggingFace뿐만 아니라, torchtext와 호환성도 좋다고 한다.
- NLP뿐만 아니라 ViT에도 적용 가능하기도 하다. .
- "그런데, 왜 나(=필자)는 와닿지 않을까?"
- CS 지식이 아직은 부족해서 그렇겠지만, 'Fine-tuning' 때문에 그럴 것이다. 필자의 경우, 보통 pretrained Model을 가져와서 Fine-tuning을 많이 하는데, 'train은 고려하지 않은 것일까?' 하는 생각 때문에 와닿지 않는 것이다. 나중에 시간 될 때, 조금 더 알아봐야겠다
How to
01 INSTALL
: 필자의 경우, Pytorch 2.0과 transformers 4.21.1 버전이 설치된 conda 환경에서 진행했다. 그래서 다음 코드로 BetterTransformer에 필요한 라이브러리만 설치하였다.
- 중요! BetterTransformer의 경우 Pytorch 1.13이상의 버전에서 호환이 된다.
pip install accelerate optimum02 버전 확인
: 혹시 모르니, 버전을 확인해보자.
torch.__version__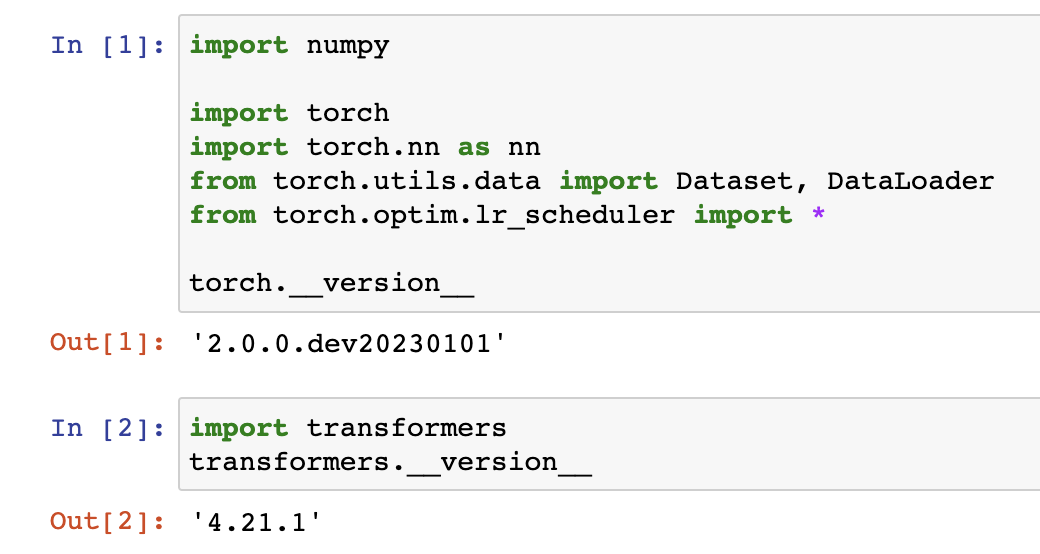
03 AutoModel, AutoTokenizer
: 먼저, AutoModel, AutoTokenizer를 import해보자.
: 'klue/roberta-base'의 모델과 토크나이저를 다운받아보자.
from transformers import AutoModel, AutoTokenizer
name = 'klue/roberta-base'
tokenizer = AutoTokenizer.from_pretrained(name)
model = AutoModel.from_pretrained(name)
04 Sample
: 예시로는 이전 포스팅의 예시 문장을 들어보자.
: 이번에는 'klue/roberta-base'의 AutoTokenizer로 토크나이징('encode_plus'로) 해보자.
text ="이 족팡매야"
tokenizer.encode_plus(text)
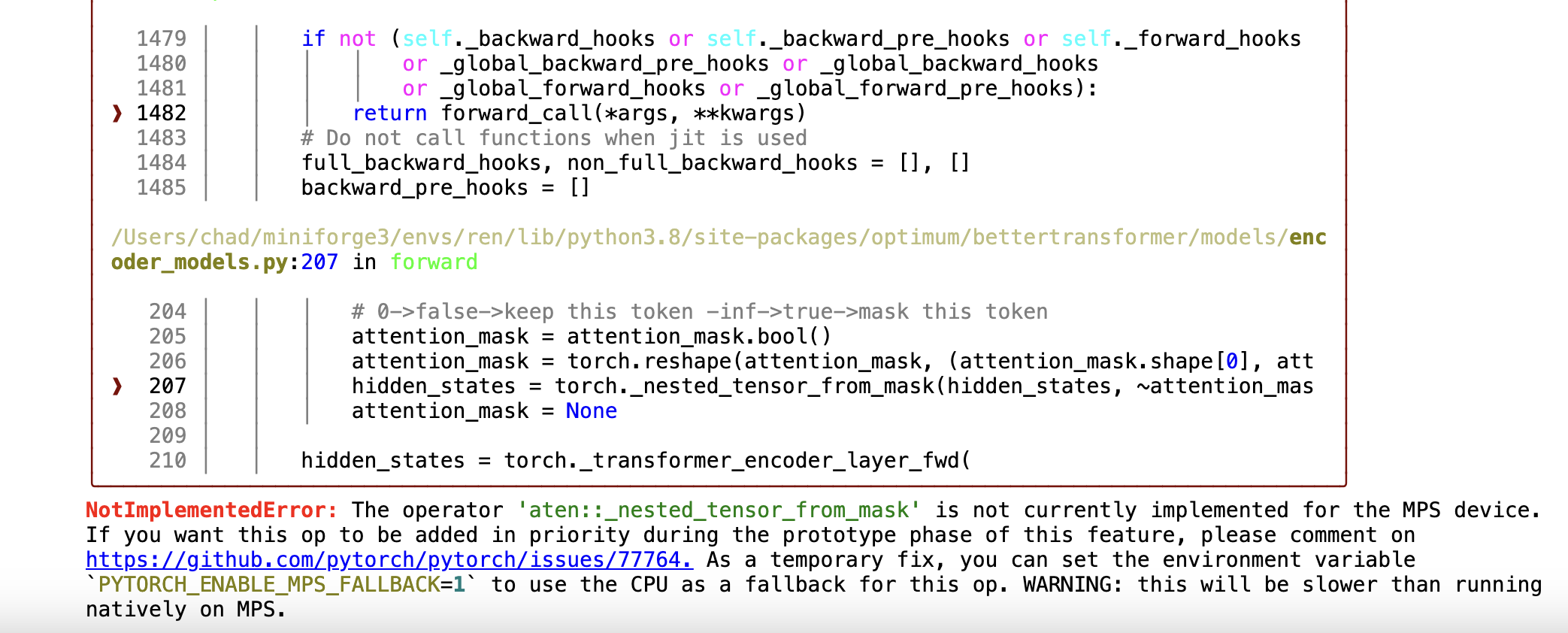
05 device
: 다음과 같이 device를 설정해야하는데... 문제는 최적화 문제인지 모르겠지만, mps로 하면 에러가 난다. 그래서 cpu에서 진행했다.
# device = torch.device('mps') if torch.backends.mps.is_available() else torch.device('cpu')
# 위처럼 진행하면, 에러 난다.
device = torch.device('cpu')
device
mps로 진행하면 다음처럼 컬러풀한 에러를 만날 수 있다.
06 Sample 문장을 torch.tensor로
: 다음과 같이 torch.tensor로 바꿔보자.
print(text)
inputs = tokenizer.encode_plus(text)
data = dict()
data['input_ids'] = torch.tensor(inputs['input_ids'], dtype = torch.long).unsqueeze(0)
data['attention_mask'] = torch.tensor(inputs['attention_mask'], dtype = torch.long).unsqueeze(0)
data['input_ids'].shape, data['attention_mask'].shape 
07 위 아이들을 model에 넣어보자 :)
: 위 data 아이들을 model에 다음과 같이 넣고, 나오는 결과물을 'out1'이라고 하자.
out1 = model(data['input_ids'].to(device), data['attention_mask'].to(device), return_dict = False)
# shape을 찍어보자.
# out1[0]: last_hidden_state -> [bs, sl, hid_dim] : 토큰별 임베딩
# out1[1]: pooler_output -> [bs, hid_dim] : 문장 레벨 임베딩
out1[0].shape, out1[1].shape
08 model 구조도 한 번 살펴보자

09 이번엔 BetterTransformer로 만들어보자.
: 다음 코드처럼 BetterTransformer를 import하고 better_model을 만들어보자.
from optimum.bettertransformer import BetterTransformer
model_name = "roberta-base"
model = AutoModel.from_pretrained(model_name).to(device)
better_model = BetterTransformer.transform(model, keep_original_model=True)
10 동일하게 모델에 torch.tensor들을 넣어보자.
: better_model을 통해 나오는 결과를 'out2' 라고 해보자.
out2 = better_model(data['input_ids'].to(device), data['attention_mask'].to(device), return_dict = False)
# shape을 찍어보자.
# out2[0]: last_hidden_state -> [bs, sl, hid_dim] : 토큰별 임베딩
# out2[1]: pooler_output -> [bs, hid_dim] : 문장 레벨 임베딩
out2[0].shape, out2[1].shape
11 여기까지 좋지만, 문제는 ... out1과 out2를 보면
: out1과 out2는 shape은 동일하지만, 값이 다르다. (어쩌면, BetterTransformer니까 당연)

- 그런데 이에 대한 해답은 둘의 구조의 차이에 있다. better_model의 구조를 살펴보면 다음과 같다.
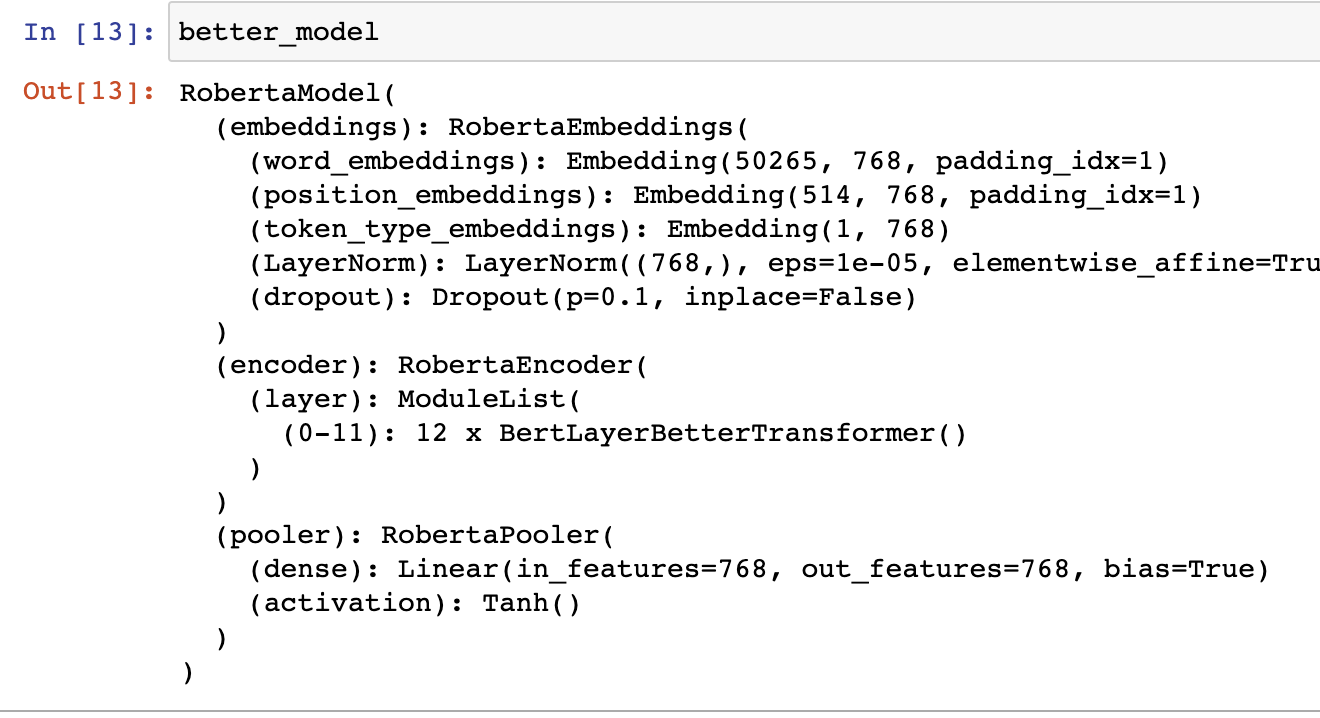
: 위 08의 AutoModel의 구조와 확연히 다를 것이다.- model에서의'RobertaLayer()' 부분이 better_model에서는 'BertLayerBetterTransformer()'로 바뀐 것을 볼 수 있다.
- 이에 대해서 구체적으로 알고 싶다면 다음 링크들을 참고해보자.
- model에서의'RobertaLayer()' 부분이 better_model에서는 'BertLayerBetterTransformer()'로 바뀐 것을 볼 수 있다.
여기까지
: 여기서 맺도록 하겠다. 개인적으로 BetterTransformer의 목적이 잘 와닿지 않았기에 쓰면서도 좀 갈등이 많았다. (개인적으로 train 방법이 하나 떠오르기는 하는데 ... 안 해봐서 제대로 될 지도 모르겠다.)
긴 글을 읽어주느라 고맙습니다.

잘 보고 갑니다