
썸네일이미지 출처: https://www.christiantoday.co.kr/news/341295
오늘은 기술블로그 느낌이 나도록 웹크롤링 예제를 보여주려고 한다. CGV 홈페이지에서 특정 영화의 댓글들을 크롤링하는 예제이다. k-digital training 에서는 'Toy 프로젝트'라는 이름으로 개인 프로젝트로 진행하였다.
개발자들이나 웹 관련 종사자들이 보기에는 어린아이들이 가지고 놀만한 장난감같은 예시에 불과하기에 'Toy 프로젝트' 라고 명명한 것 같다. 부족하지만, 그래도 파이썬을 이용한 크롤링의 작은 예제를 보여주려고 한다.
들어가기 앞서서
- 유의사항1) 이 포스팅은 스압이 좀 있을 것이다.
- 유의사항2) 이 포스팅에 기재한 코드들은 비록 구글링 & 공부를 하면서 작성했다. 포스팅을 하고 있는 지금도 잘 실행이 되지만, CGV 홈페이지의 구조가 바뀌면, '무용지물'이 되는 일회용의 한계가 있다. 이 시기가 당장 내일이 될 수도 있다.
- 유의사항3) 필자의 코딩 레벨은 아직 미숙하다.
- 유의사항4) 셀레니움 설치하는 과정은 생략한다.
00 시작환경
필자의 환경은 다음과 같다.
miniforge3 - conda env(python@3.8)
Jupyter Notebook
python 3.8 - datetime, time
pandas - DataFrame
requests - requests.get()
BeautifulSoup4 - beautifulSoup(resp, 'lxml')
Selenium - Webdriver(webdriver.Chrome()), keys, WebDriverWait, EC, By
import datetime as dt
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# 필자의 경우, 00-first.py 세팅에
# 아래 명령어들이 포함되어있기 때문에
# 즉, 주피터에서 입력하여 import 안 해도 되기 때문에
# 주석처리를 하였다. 필자처럼 세팅을 한 것이 아니라면
# import 하자.
#from bs4 import BeautifulSoup
#import requests
#import pandas as pd
#import numpy as np01 필자의 전략
1) CGV 영화 상세 url
: CGV 영화 상세 페이지 url을 보면, url 뒤의 마지막 숫자 5자리가 각 영화마다 다르다. '블랙위도우'의 경우, '82986'으로 끝난다. 예를 들면, CGV 영화 '블랙위도우'의 상세 페이지 url은 다음과 같다. http://www.cgv.co.kr/movies/detail-view/?midx=82986

이러한 형태의 url은 CGV의 특정 영화의 상세 페이지 주소를 나타내며, 이 url의 마지막 숫자 5자리는 각 영화가 가지는 고유값을 가지는 것이다. 쉽게 말하면, CGV 내에서의 각 영화의 주민등록번호 같은 숫자인 것이다.
2) CGV 영화 검색
: 크롤링을 공부하면서, 웹에 대한 기초나 구조나 공부가 전혀없이 하다보니 많이 힘들었다. 하지만, 영화를 검색했을 때, url을 넘기는 구조를 조금이라도 구현하고 싶었다.
CGV 내에서 영화 혹은 배우를 검색을 할 때, '영화 상세 페이지로 링크'가 나타나는 '위치'가 다 다르다. xpath도 다 달라진다. CGV에서 '블랙위도우'를 검색하면, 바로 '블랙위도우' 페이지로 바로 연결되지만, '스칼렛 요한슨'으로 검색하면, '블랙위도우'를 포함하여 다른 영화 목록까지 같이 나온다. 배우 '플로렌스 퓨'로 검색을 해도 마찬가지이다.
프로그램으로 만든 것은 아니지만, 사용자가 영화를 검색했을 때, 바로 url을 뽑아내거나, 이동하려면, 영화 검색 결과시, '영화 상세 url' 링크가 특정한 곳에만 나타나도록 규칙을 찾아야한다. 시간을 투자하여 고민하고 실험한 결과, CGV 페이지에서 '특정배우 + 영화명'으로 검색을 하면, '영화 상세 url' 링크가 특정한 위치에서 고정되어 나타난다.
다음 스크린샷처럼 말이다.
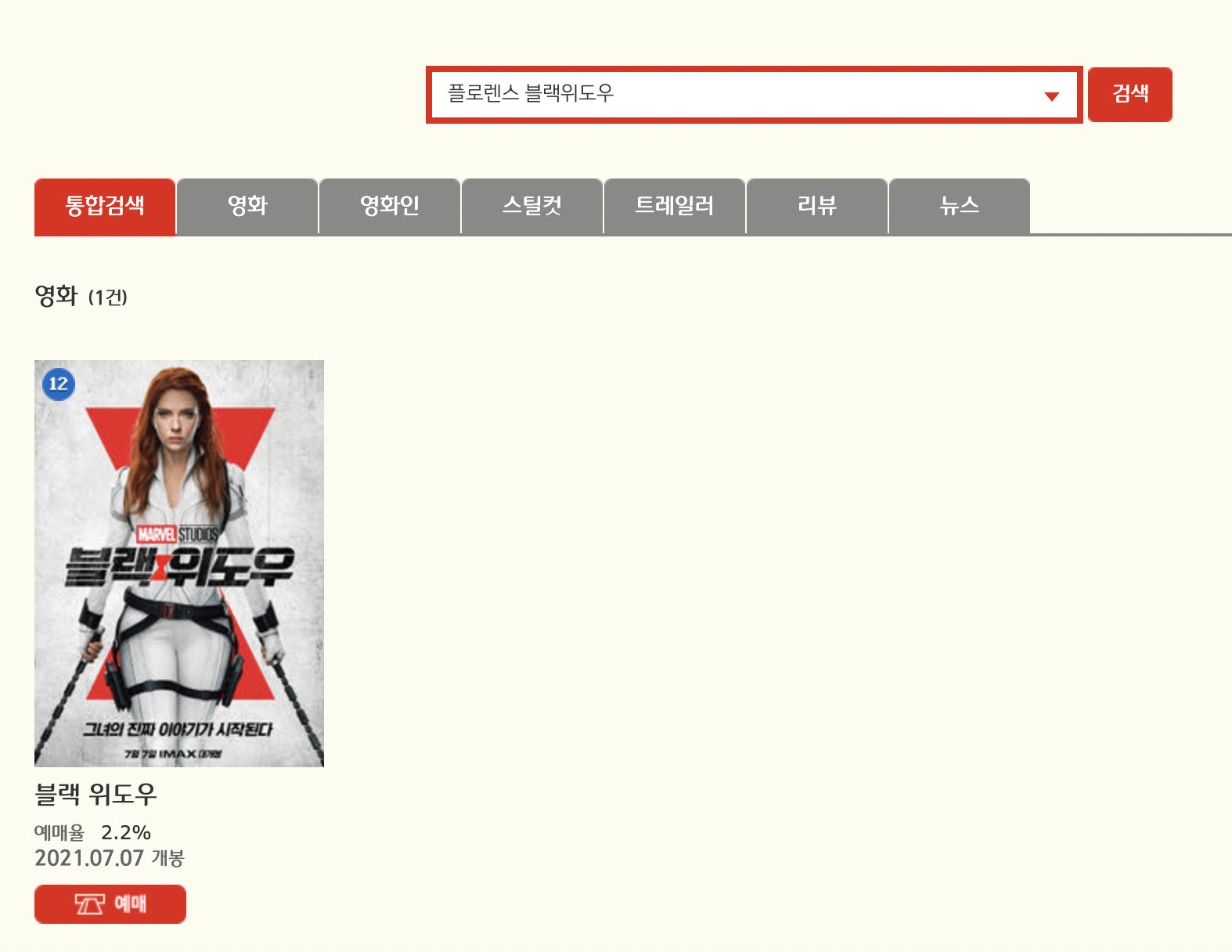
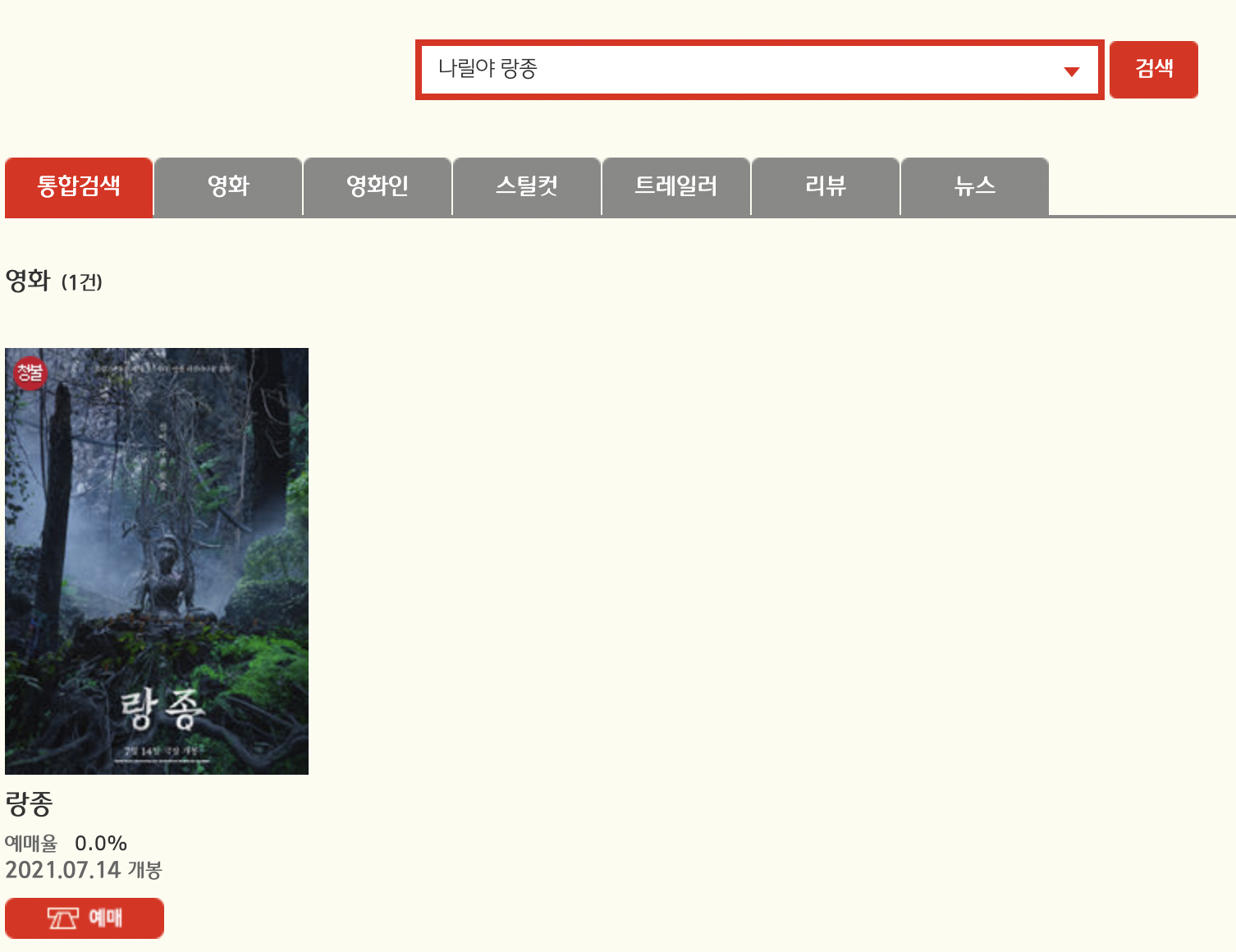
그래서 사용자가 영화를 검색했을 때, 자동으로 특정 배우명 과 같이 검색이 되도록하여, 영화 상세 url로 넘어갈 수 있도록 리스트화할 것이다.
3) CGV 영화 상세 페이지 내 댓글
: CGV 영화 페이지 내 댓글은 다음 스크린샷처럼 페이지당 6개씩 있다.
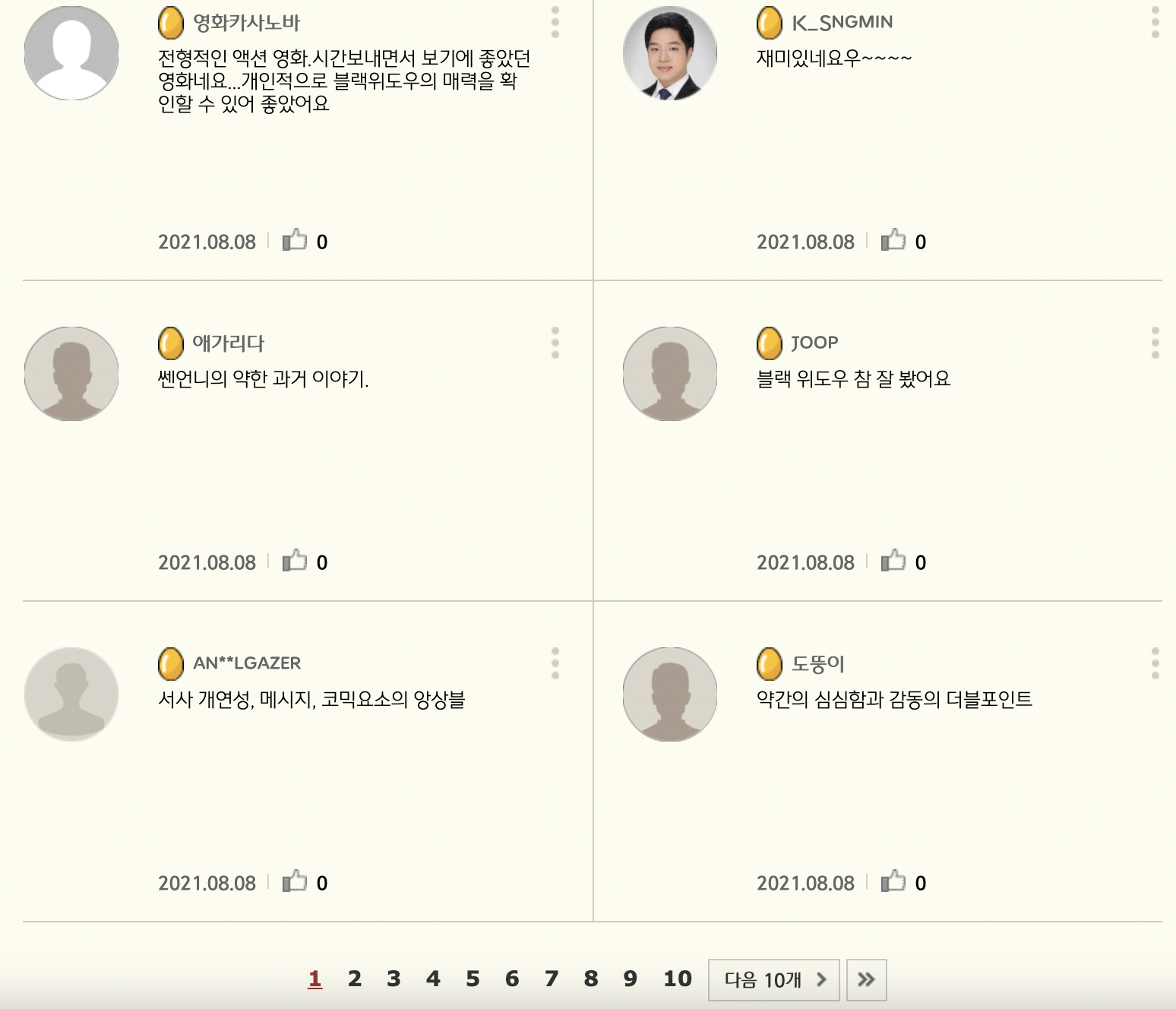
이 댓글은 별도의 프레임소스가 존재하지 않고, 한 번에 불러지지 않는 비동기식 호출이라서, WebdriverWait, time.sleep() 명령어를 사용할 것이다.
또한, 1 페이지부터 사용자가 원하는 페이지(end_page_num)까지의 모든 댓글들을 크롤링할 수 있도록 코드를 짤 것이다. 보면 알겠지만,
moc = end_page_num // 10
rest = end_page_num % 10
이런 코드들이 보일 것이다. 10페이지 단위로 나뉘어져있고, '다음 10개' 버튼이 있다. 그래서, 사용자가 원하는 페이지 숫자를 10으로 나눴을 때의 몫을 'moc'이라는 변수로 지정하고, 나머지는 'rest' 라는 변수로 지정하였다.
상세한 것은 차차 보면서 알려주겠다.
02 본격적인 코드
1) 영화 제목 검색
# 영화 제목부터 검색
def cgv_search_movie(movie_name):
if movie_name in ('블랙위도우', '블랙 위도우', \
'Black Widow', 'BlackWidow'):
movie_url= 'http://www.cgv.co.kr/movies/detail-view/?midx=82986'
movie = '플로렌스 블랙위도우'
return movie
elif movie_name in ('The Medium', '량종' , '랑종', '뢍종', \
'랑종', '랑 종', '나홍진'):
movie_url= 'http://www.cgv.co.kr/movies/detail-view/?midx=84776'
movie = '나릴야 랑종'
return movie
else:
print("검색을 다시해보겠습니까?")먼저 코드상에는 예시로, '랑종'과 '블랙위도우'로만 작성하였고, 위 코드는 프로그램으로 만들었을 때를 가정하여, 사용자가 특정 영화를 검색할 때, 띄어쓰기, 배우, 영어로 검색했을 때를 감안하였다.
위 코드로 짠 함수로 테스트해보면 다음과 같다.

2) 영화 제목 검색 결과로 url 추출
: 위 코드에서 보면 알겠지만, 사실 return값을 'movie_url'이 아닌 'movie'로'만' 하였다. movie_url로 바로 연결할 수 있었으나, 프로그램이나 웹페이지 서비스를 만든다는 가정으로, 위 전략에서 말했던 것처럼, 특정 영화 검색시, 영화 상세 url로 이어질 수 있도록 코드를 짜보았다.
movie = cgv_search_movie('블랙위도우') 이런 형태로 받았을 때를 가정하여, 그 이후의 코드를 짠 것이다. 다음과 같다. 자세한 설명은 코드 중간중간의 주석을 참고하자.
중간중간에 상황을 보여주는 듯한 print 함수가 곳곳에 있을 것이다. try exception 구문을 잘 모르기 때문에, 코드 실행시, 진행상황을 알 수 있도록 print 함수를 중간중간에 많이 심어두었다.
# 위에서 검색한 영화제목으로 cgv에서 해당 영화 정보 페이지 url 가져오기
def search_cgv(movie_name):
driver = webdriver.Chrome()
# Selenium으로 cgv 접속
driver.get('https://www.cgv.co.kr/')
print("connected - page 접속")
# CGV 페이지 내에서 검색창 클릭하는 부분, xpath로 찾아서 클릭
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="header_keyword"]')))
search = driver.find_element_by_xpath('//*[@id="header_keyword"]')
# 이전 함수의 결과값을 받는다고 가정
#movie = cgv_search_movie('블랙위도우')
movie = movie_name
# 검색
# movie 변수로 검색
search.send_keys(movie)
print("영화 검색어 입력")
# 비동기식 호출이라, 시간이 필요하다.
# 그렇다고 많이 줄 수 없기 때문에, 0.03초를 주는 것
time.sleep(0.03)
# 검색어 입력 후 Enter키 입력
search.send_keys(Keys.RETURN)
print("영화 검색어 입력 후 Enter 입력")
time.sleep(0.03)
# 특정배우명 + 영화명으로 검색시, 우리가 원하는 영화 상세 url 위치가
# 항상 아래와 같은 특정 xpath에 고정적으로 뜬다.
# //*[@id="contents"]/div/div[2]/div[1]/div/div/ul/li/div[2]/a/strong 플로렌스 블랙위도우
# //*[@id="contents"]/div/div[2]/div[1]/div/div/ul/li/div[2]/a/strong 엄지원 재차의
# //*[@id="contents"]/div/div[2]/div[1]/div/div/ul/li/div[2]/a/strong 드웨인 정글크루즈
# //*[@id="contents"]/div/div[2]/div[1]/div/div/ul/li/div[2]/a/strong 알렉 보스베이비2
# //*[@id="contents"]/div/div[2]/div[1]/div/div/ul/li/div[2]/a/strong 로날드 피닉스
# //*[@id="contents"]/div/div[2]/div[1]/div/div/ul/li/div[2]/a/strong 나릴야 랑종
# 이 xpath를 wanted_result 라는 변수에 저장
wanted_result = '//*[@id="contents"]/div/div[2]/div[1]/div/div/ul/li/div[2]/a/strong'
# 원하는 검색결과를 클릭하기까지 기다리고 찾기
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, wanted_result)))
searchs = driver.find_element_by_xpath(wanted_result)
print("검색결과")
# 검색결과가 우리 눈에 보일지라도 클릭할 수 있는데에는, 좀 시간이 살짝 필요
# 그래서 위에서 WebDriverWait로 clickable을 준 것이고,
# 바로 밑에 0.03초 대기 시간을 준 것도 같은 이유다.
time.sleep(0.03)
# 검색결과 클릭
searchs.click()
print("검색결과 클릭")
# 그럼 우리가 원하는 영화 상세 페이지로 넘어간 것이다.
# 그러면, 이 함수의 목적인 url을 담아보자.
# 아래 driver.current_url 을 이용한다.
movie_url = driver.current_url
print("현재 url 주소 긁고 브라우저 종료 중")
# driver (크롬드라이버)종료
# 사실 여기서 말고도 계속 selenium 드라이버의 활동이
# 이후에도 계속 필요하다. 그러나, 필자의 경우,
# connection creates connection 에러 메세지가 뜨는 경우가
# 많았기 때문에, 함수마다 열었다가 종료하는 구조로 코드를 작성하였다.
driver.quit()
return movie_url그래서 이 코드로 실행을 하면 다음과 같은 결과가 나올 것이다.
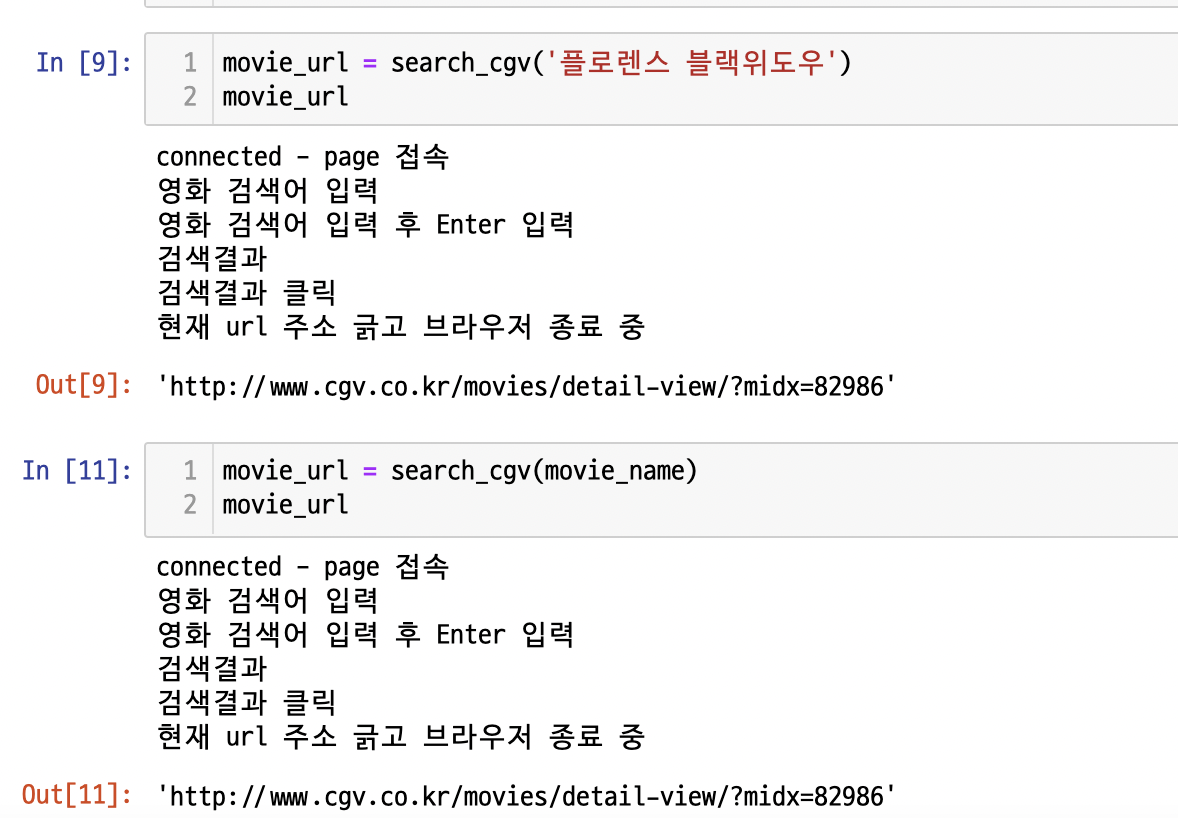
위 코드들을 실행해보면 알 것이다.
Chrome 브라우저가 갑자기 뜨면서
휘리릭 페이지 이동하고
종료되는 것을 보게 될 것이다.
너무 글이 길어질 것 같으니, 우선 여기까지.
