
썸네일이미지 출처: https://star.ytn.co.kr/_sn/0117_201905101300086622
마지막 파트다.
part 01, part 02 순서대로 모두 이어지는 내용이다.
이 포스팅은 part 03 으로 마지막 파트이다.
- '블랙위도우'로 예시를 들고 있다.
- part 01, part 02 들이 실행된 상태여야한다.
02 본격적인 코드
8) 이전 과정들을 합해보자.
: 이전 과정의 모든 것을 합치는 과정은 아니지만, 다소 코드가 길 것이다. 이전에 설명과 중복되는 내용은 생략할 것이다.
- 주의 사항: 이전 과정에서 작성한 함수들이 선언되어있어야 한다.
def cgv_final(end_page_num):
moc = end_page_num //10
rest = end_page_num % 10
print("end_page_num 입력 후 moc과 rest 정의 완료")
if moc == 1:
# 몫이 1일 경우
print("end_page_num이 11이상 20이하일때")
# 1 ~ 10 페이지의 날짜, 사용자, 댓글을 먼저 크롤링
# cgv_rep_duc 함수 이용
m11_d, m11_u, m11_c = cgv_rep_duc(1, 10)
print("먼저 10페이지까지 먼저 긁기 완료")
# 11 페이지부터 end_page_num까지 날짜, 사용자, 댓글을 크롤링
# cgv_rep_duc1 함수 이용
m12_d, m12_u, m12_c = cgv_rep_duc1(1, rest)
print("11페이지부터 end_page_num까지 긁기 완료")
# 날짜별로, 사용자별로, 댓글별로 리스트끼리 더 하자.
# [1, 2, 3] + [4, 5] -> [1, 2, 3, 4, 5]가 된다.
# 날짜 리스트 합치기
m1_d = m11_d + m12_d
# 사용자 리스트 합치기
m1_u = m11_u + m12_u
# 댓글 리스트 합치기
m1_c = m11_c + m12_c
# 합한 리스트로 DataFrame 생성
print("날짜, 율저, 댓글 별 리스트 통합")
df1 = pd.DataFrame({"날짜":m1_d, "유저":m1_u, "댓글" :m1_c})
print("DataFrame으로 묶기 및 반환")
# 생성한 DataFrame으로 반환
return df1
elif moc >=2:
# 몫이 2이상일 때
print("end_page_num이 11이상 20이하일때")
# 1 ~ 10 페이지의 날짜, 사용자, 댓글을 먼저 크롤링
# cgv_rep_duc 함수 이용
m21_d, m21_u, m21_c = cgv_rep_duc(1, 10)
print("먼저 10페이지까지 먼저 긁기 완료")
# 11 ~ 20 페이지의 날짜, 사용자, 댓글을 크롤링
# cgv_rep_duc1 함수 이용
m22_d, m22_u, m22_c = cgv_rep_duc1(1, 10)
print("11페이지부터 20페이지까지 긁기 완료")
# 21 ~ moc*10 페이지의 날짜, 사용자, 댓글을 크롤링
# cgv_rep_duc_moc 함수 이용
m23_d, m23_u, m23_c = cgv_rep_duc_moc(moc)
print(f"21페이지부터 {moc*10}페이지까지 긁기 완료")
# moc*10 ~ moc*10+rest 페이지의 날짜, 사용자, 댓글을 크롤링
# cgv_rep_duc_rest함수 이용
m24_d, m24_u, m24_c = cgv_rep_duc_rest(moc, 1, rest)
print(f"{moc*10 +1}페이지부터 {moc*10+rest}페이지까지 긁기 완료")
# 날짜 리스트 합치기
m2_d = m21_d + m22_d + m23_d + m24_d
# 사용자 리스트 합치기
m2_u = m21_u + m22_u + m23_u + m24_u
# 댓글 리스트 합치기
m2_c = m21_c + m22_c + m23_c + m24_c
print("날짜, 율저, 댓글 별 리스트 통합")
# 합한 리스트로 DataFrame 생성
df2 = pd.DataFrame({"날짜":m2_d, "유저":m2_u, "댓글" :m2_c})
print("DataFrame으로 묶기 및 반환")
# 생성한 DataFrame으로 반환
return df2
else:
if moc == 0:
# 몫이 0일 때
print("end_page_num이 10이하일때")
# 이하 설명 생략
m0_d, m0_u, m0_c = cgv_rep_duc(1, end_page_num)
print("1페이지부터 end_page_num까지 긁기 완료")
print("날짜, 율저, 댓글 별 리스트 통합")
df = pd.DataFrame({"날짜":m0_d, "유저":m0_u, "댓글" :m0_c})
print("DataFrame으로 묶기 및 반환")
return df자 이제 테스트를 해보자.
이전에 예를 들었던, 56 페이지까지 댓글 크롤링을 시도해보려한다.
- 56 페이지까지면, 336(=56x6)개의 댓글이 수집되었을 것이다.
- 이전과정에서는 함수의 반환값이 list 였으나, 이번에는 pandas DataFrame이다.
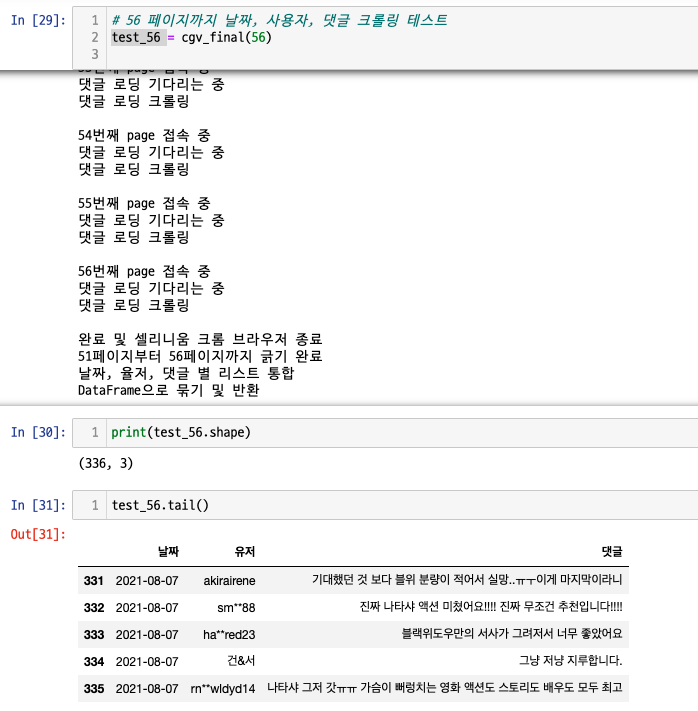
test_56.tail() 명령어로 마지막 5개의 댓글을 뽑아보았다.
이제 잘 되었는지 CGV '블랙위도우' 상세 페이지에서 댓글 56 페이지로 가서 확인해보자
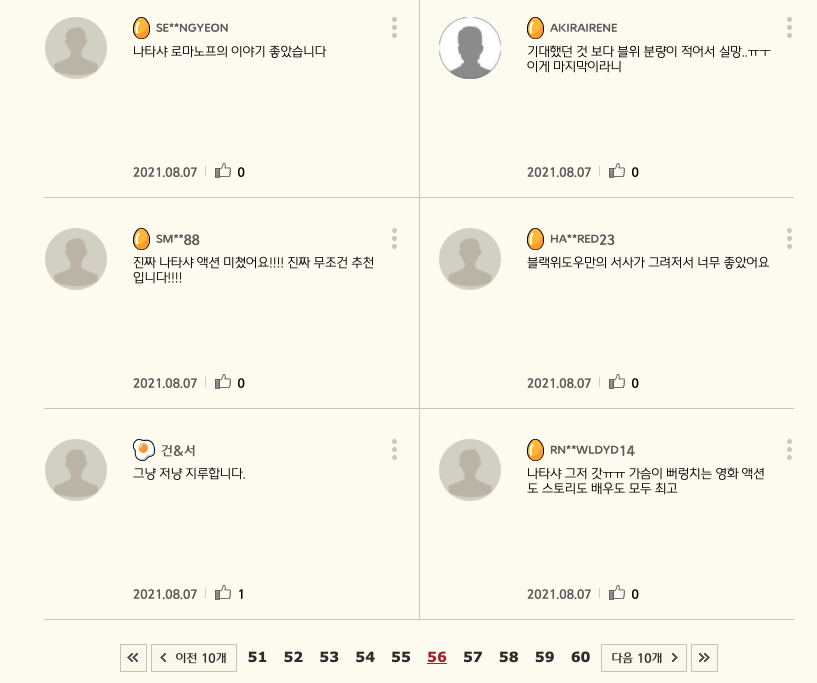
매우 잘 된 것을 확인할 수 있다.
크롤링에 관한 포스팅의 내용은 여기까지다.
긴 내용을 읽어줘서 고맙다.
쉽지 않았을텐데...
고민 & 후속포스팅
1) 포스팅 글이 너무 긴 거 아닌가?
: 자세하게 쓰려다 보니 길어지는 것 같은데, 너무 긴 것 같기도 하고... 그렇다고 간결하면, 구체적인 느낌이 죽지 않나... 고민이다.
2) 후속 글 주제
: M1 JDK 설치, M1 PYTORCH 설치, 기타 다른 주제 몇 가지 중에서 고민 중이다.
- JDK
: 파이썬 라이브러리 중 Konlpy (Korean NLP in Python - https://konlpy.org/en/latest/ )라고 있는데, JDK가 필요하다. 그런데, oracle JDK는 아직 M1을 지원하지 않고 있다. (eclipse 도 아직 미지원) 반면, openJDK(zulu)는 현재 M1을 지원하고 있다.(IntelliJ, VSCODE도 M1 지원) - Pytorch
: 최근 글들을 보면, Pytorch가 M1을 지원하기 시작한 것 같다. 아직, GPU까지 지원하는 단계는 아닌 것 같다. 아마 k-digital training 과정에서는 Google-Colab에서 pytorch를 쓸 것 같은 느낌이긴 한데, 아직 잘 모르겠다. - 기타
: EDA, AWS EC2, GOORM.io, Pycharm 등 관련 있는 다른 주제도 다루어볼까 고민 중이다.

weird