INTRO
: 처음에 가장 부담없는 REGRESSION 문제를 풀어보려고 한다.
- SCIKIT-LEARN에서 CALIFORNIA HOUSING 데이터를 사용해보도록 한다.
- EDA, PREPROCESSING 모두 생략 -> BASIC FLOW에 익히는 것이 목적
- [가장 중요] 데이터의 Shape 추적은 반드시 해야한다.
- 에러를 막을 수 있고 의미 파악하는 가장 빠른 지름길
- 혹시라도 잘못된 부분이 있다면 꼭 알려줬으면 한다.
Code
- 실습코드 - Colab에서뿐만 아니라, M1에서도 잘 돌아간다.
- 처음이라 설명이 좀 길다. 이후의 포스트에서는 중복 설명은 생략할 것이다.
순서
: Import -> Data -> Dataset -> DataLoader -> Model -> Loss Function and Optimizer -> train_one_epoch() and valid_one_epoch() -> run_train()
01 IMPORT
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader1) import torch.nn as nn
: nn을 이용해서 nn.Module을 상속받아서 다음 예시처럼 Model을 빌드한다. 그래서 필요하다.
class Model(nn.Module):
def __init__(self, input_dim = 8, output_dim = 1):
super().__init__()
self.fc1 = nn.Linear()
...2) from torch.utils.data import Dataset, DataLoader
: Dataset과 DataLoader는 데이터를 배치 단위로 학습할 데이터(x)와 정답 데이터(y)를 묶어서 뱉어주는 역할을 한다.
02 DATA
: SCIKIT-LEARN에서 CALIFORNIA HOUSING 데이터이다. EDA, PREPROCESSING 모두 생략한다.
- 20640개의 row들과 9개의 컬럼이 존재
- label 컬럼(y): 'target'
- 학습할 컬럼들(x): 'MedInc' ~ 'Longtitude'
from sklearn.datasets import fetch_california_housing
ch = fetch_california_housing()
df = pd.DataFrame(ch.data, columns = ch.feature_names)
df['target'] = ch.target
print(df.shape)
df.head()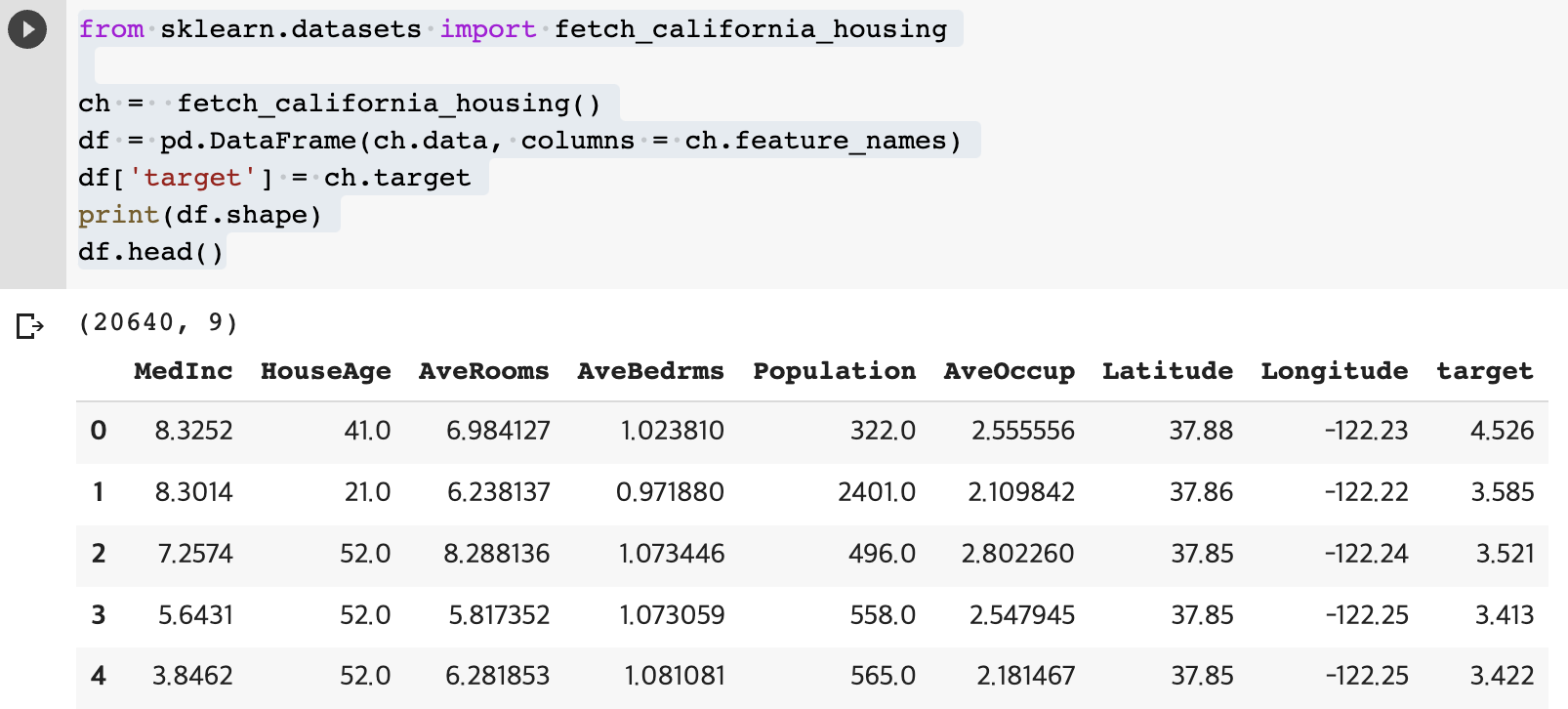
03 Dataset
: Dataset을 상속받아서 MyDataset 클래스를 만들어준다.
class MyDataset(Dataset):
def __init__(self, df = df):
self.df = df
self.x = df.iloc[:, :-1].values
# numpy
# df.loc[:, "MedInc":"target"]
self.y = df.iloc[:, -1:].values
# numpy
def __len__(self):
# 전체 데이터의 길이 정보(총 row 수) 반환
return self.x.shape[0]
def __getitem__(self, index):
# index로 row 하나를 특정합니다.
x = self.x[index] # numpy # Shape: [8]
y = self.y[index] # numpy # Shape: [1]
## 우리는 토치의 민족이기 때문에 위 x, y를 토치 텐서로 반환하여 반환해준다.
return torch.tensor(x, dtype = torch.float), torch.tensor(y, dtype = torch.float)
# Shape: [8] # Shape: [1]- def __init__(self)
- 생성자 함수에서는 전체 데이터셋에서의 X,Y를 선언
- self.x = df.iloc[:, :-1].values
- 'MedInc' ~ 'Longtitude'까지 인덱싱
- .values 붙여서 pandas DataFrame에서 numpy array로 변환
- def __len__(self)
- 여기서는 전체 데이터의 길이 정보를 반환한다.
- def __getitem__(self)
- 여기서는 'index'로 인덱싱하여, row 하나를 특정한다.
- 이게 잘 안 와닿으면, KFold 생각하면 될 것이다.
## 다른 데서 코드 가져옴 for fold, ( _, val_) in enumerate(skf.split(X=df, y=df['target'])): df.loc[val_ , "kfold"] = int(fold) # _, val_ : index 넘버 - x = self.x[index] 이런 식으로 인덱싱을 한다.
- self.x는 'MedInc' ~ 'Longtitude' 에 대한 전체 row의 데이터
- 여기서 x, y는 index로 특정된 row 한 줄에서의 x, y이다. 즉, x는 8개의 숫자로 이루어져있고, y는 1개의 target 숫자로 이루어져있다. 그렇기에 여기서 x, y의 Shape은 [8], [1]로 나온다.
- 이게 잘 안 와닿으면, KFold 생각하면 될 것이다.
- 우리는 토치의 민족이기 때문에 x, y를 토치 텐서로 반환하여 반환해준다.
return torch.tensor(x, dtype = torch.float), torch.tensor(y, dtype = torch.float)
- 여기서는 'index'로 인덱싱하여, row 하나를 특정한다.
04 prepare_loaders: Dataset -> DataLoader
: 여기서는 학습에 사용할 데이터와 성능 검증에 필요한 데이터로 쪼개준다. 그리고 각 데이터에 대해서 배치 단위로 뱉어줄 수 있도록 DataLoader 객체를 각각 만들어준다. 이 과정을 prepare_loaders() 함수에 담았다.
def prepare_loaders(df = df, index_num = 14000, bs =256):
# train, valid split - 학습을 위한 train과 성능 검증을 위한 valid로 쪼개준다.
train = df[:index_num].reset_index(drop = True)
valid = df[index_num:].reset_index(drop = True) # 혹시 몰라서 하는 index 초기화
# train_ds, valid_ds
# 위애서 선언한 MyDataset으로 train, valid에 대한 Pytorch Dataset 객체를 만든다.
# --> train_ds, valid_ds
train_ds = MyDataset(df = train)
valid_ds = MyDataset(df = valid)
# train_loader, valid_loader
# Batch 단위로 데이터들을 묶어서 뱉어주는 DataLoader로 train_loader, valid_loader 객체를 만든다.
train_loader = DataLoader(train_ds, # Pytorch Dataset
shuffle = True, # 섞을래 말래?
batch_size = bs, # 배치 단위 사이즈 크기 현재 256으로 디폴트
# pin_memory = True, num_workers = 2,
# > 필자는 '내 컴이 아니면 쓴다.'라는 공식으로 사용여부를 결정한다.
)
# 이 외에도 drop_last, collate_fn, sampler 등 여러 아규먼트들이 있다.
valid_loader = DataLoader(valid_ds, shuffle = False, batch_size = bs)
return train_loader, valid_loader
train_loader, valid_loader = prepare_loaders()train_loader에서 나오는 배치의 Shape을 확인해보자.
: Data의 Shape 추적이 가장 중요하다. 그래서 여기서도 확인해볼 필요가 있다. 아마 x에 해당하는 부분의 Shape은 [256, 8], y에 해당하는 부분의 Shape은 [256, 1] 으로 나올 것이다.
## train_loader가 뱉는 배치 크기 확인해보자
data = next(iter(train_loader))
data[0].shape, data[1].shape
05 device
: torch.tensor를 비롯해서 train_loader, valid_loader에서 나오는 배치들과 Model의 layer들을 모두 GPU로 보내기 위한 코드이다. M1, Colab에서 적용할 수 있는 코드이며, '지금 GPU 쓸 수 있니? 없니?' 라고 확인 후, if else 조건문을 통해 GPU로 보내는 코드이다.
# Colab
# device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
# M1 버전
device = torch.device("mps") if torch.backends.mps.is_available() else torch.device("cpu")06 Model
: nn.Module을 상속받아서 Model 클래스를 빌드한다.
class Model(nn.Module):
def __init__(self,):
super().__init__()
# nn.Module 상속시 반드시 같이 해야 에러가 나지 않음
# nn.Module에서 선언된 변수들이 선언되어있는데 땡겨오는 것
# 참고: https://velog.io/@minchoul2/nn.Module-init시-super.init-해야하는-이유
# input data(=x)'s shape: [bs, 8]
# input data(=x)는 배치단위로 들어오는 배치 덩어리. bs는 배치단위의 크기를 의미
# Feature Extraction 과정
# : [bs, 8] -> [bs, 3] -> [bs, 1]
self.fc1 = nn.Linear(8, 3)
# [bs, 8] -> [bs, 3]
self.relu = nn.ReLU()
# [bs, 3] -> [bs, 3]
# 활성화 함수를 지날 때에는 Shape 변화가 없다. (단순히 비선형만 만들기 때문)
self.fc2 = nn.Linear(3, 1)
# [bs, 3] -> [bs, 1]
# [bs, 1]이 최종적으로 model이 예측한 y_pred(=predicted)가 된다.
def forward(self, x):
# x: input_data - batch 단위
# 실질적으로 연산이 이루어지는 곳 (함수 형태로 엮어줌(= 넣어줌))
# x: [bs, 8]
x = self.fc1(x) # [bs, 8] -> [bs, 3]
x = self.relu(x) # [bs, 3] -> [bs, 3]
y_pred = self.fc2(x) # [bs, 3] -> [bs, 1]
return y_pred
# y_pred's shape: [bs, 1]
model = Model().to(device) # GPU로 보내준다.- 이 곳에서 Feature Extraction 과정이 일어난다.
- 데이터가 배치 단위로 들어온다.
- x가 배치단위로 묶여서 [bs, 8] Shape으로 들어온다. (bs: 배치단위크기)
- model의 최종값(y_pred)는 Predicted 값이며, Shape은 [bs, 1]로 나온다.
- y가 배치단위로 묶여서 [bs, 1] Shape으로 나타나는데, 이 때의 Shape과 동일
- def __init__(self) 에서는 'Frame만 선언'해준다고 생각하면 된다.
- Linear Layer(예시: nn.Linear() )들이 이 곳에서 변수 형태로 담긴다.
- def forward(self, x) 에서는 '실질적으로 위에서 선언한 Frame들을 함수형태로 넣어주며 엮어주는 곳'이라고 생각한 된다.
- 그렇지만, def __init__(self) 와 def forward(self, x) 에서 모두 Shape 추적을 하면서 코드를 짜야한다. 그래야 오류가 안 나고 어떤 일이 일어나는 지 상세하게 알 수 있다.
07 Loss Function and Optimizer
: Loss Function과 Optimizer를 선언한다.
- MSELoss
- Adam
# loss_fn도 to(device)가 가능하다. (= GPU로 보내줄 수 있다.)
loss_fn = nn.MSELoss().to(device)
# optimizer는 to(device)가 불가능하다. (= GPU로 보내줄 수 없다.)
optimizer = torch.optim.Adam(model.parameters(), lr = 5e-3) # 수강생분이 이걸로 하자고 하셔서 이걸로 해 보았다.08 train_one_epoch()
: model이 한 epoch를 도는 동안, model이 학습되는 과정과 train_epoch_loss(=epoch당 평균 train loss)를 return 시키는 함수이다.
- model이 학습을 진행 (Back-Prop)
- train 데이터 -> train_loader
def train_one_epoch(model = model,
dataloader = train_loader,
loss_fn = loss_fn,
optimizer = optimizer,
device = device):
# model을 학습시키겠다고 선언
model.train()
train_loss = 0
for data in dataloader:
# train_loader = [([bs, 8], [bs, 1]), ([bs, 8], [bs, 1]), .... ]
x = data[0].to(device) # [bs, 8] # GPU로 보내준다.
y = data[1].to(device) # [bs, 1] # GPU로 보내준다.
y_pred = model(x) # [bs, 1] # model을 통해 예측한 값
loss = loss_fn(y_pred, y) # MSE Loss
optimizer.zero_grad() # Gradient 초기화
loss.backward() # 역전파할 Gradient 구함
optimizer.step() # 역전파할 Gradient 토대로 Weight 업데이트
train_loss += loss.item()
train_epoch_loss = train_loss / len(dataloader) # epoch 당 train loss 평균값
return train_epoch_loss09 valid_one_epoch()
: model이 한 epoch를 도는 동안, valid_epoch_loss(=epoch당 평균 valid loss)를 return 시키는 함수이다.
- 여기서는 model이 학습되지 않는다.
- 오직 성능 평가만 한다.
- valid 데이터 -> valid_loader
# @torch.no_grad() : 데코레이터 형태의 'model을 학습 시키지 않겠다는 필수 의지 표명 2'
# --> 근데 함수형일 때 쓸 수 있는 것으로 알고 있다.
# --> model을 학습 시키지 않겠다는 필수 의지 표명 1과 2 중 하나만 써도 무방하다.
@torch.no_grad()
def valid_one_epoch(model = model,
dataloader = valid_loader,
loss_fn = loss_fn,
device = device):
# 여기서는 optimizer가 필요없다. 학습을 하지 않기 때문
# model을 학습 안 시키겠다고 선언
model.eval()
valid_loss = 0
# model을 학습 시키지 않겠다는 필수 의지 표명 1
with torch.no_grad():
for data in dataloader:
# valid_loader = [([bs, 8], [bs, 1]), ([bs, 8], [bs, 1]), .... ]
x = data[0].to(device) # [bs, 8] # GPU로 보내준다.
y = data[1].to(device) # [bs, 1] # GPU로 보내준다.
y_pred = model(x) # [bs, 1] # model을 통해 예측한 값
loss = loss_fn(y_pred, y) # MSE Loss - 성능평가
valid_loss += loss.item()
valid_epoch_loss = valid_loss / len(dataloader) # epoch 당 valid loss 평균값
return valid_epoch_loss10 run_train()
: 여기서는 전반적인 train 과정을 담았다.
- train_one_epoch() / valid_one_epoch()
- 시각화를 위한 epoch당 평균 train_loss, valid_loss 담기
- monitoring: 특정주기마다 loss들 체크
- Lowest Loss가 갱신될 때, model 저장
- 오버피팅 방지를 위한 early_stop
def run_train(model = model,
n_epochs = 150,
train_loader = train_loader,
valid_loader = valid_loader,
loss_fn = loss_fn,
optimizer = optimizer,
device = device):
# 시각화를 위해서 줍줍할 list
train_hs, valid_hs = [], []
# monitoring을 위한 주기
print_iter= 20
# Lowest Loss 갱신할 때 필요
lowest_loss, lowest_epoch = np.inf, np.inf
# 오버 피팅 방지
early_stop = 20
for epoch in range(n_epochs):
# epoch 당 평균 train loss: train_epoch_loss
train_loss = train_one_epoch(model = model,
dataloader = train_loader,
loss_fn = loss_fn,
optimizer = optimizer,
device = device)
# epoch 당 평균 valid loss: valid_epoch_loss
valid_loss = valid_one_epoch(model = model,
dataloader = valid_loader,
loss_fn = loss_fn,
device = device)
# train_epoch_loss, valid_epoch_loss를 위에서 선언한 빈 리스트들에 담아둔다. (시각화)
train_hs.append(train_loss)
valid_hs.append(valid_loss)
# monitoring
# : 특정 주기(=print_iter)마다 Train Loss, Valid Loss, Lowest Loss를 찍어준다.
if (epoch + 1) % print_iter == 0:
print(f"Epoch{epoch}|TL:{train_loss:.3e}|VL:{valid_loss:.3e}|LL:{lowest_loss:.3e}|")
# Lowest Loss 갱신 - Valid Loss 기준
if valid_loss < lowest_loss:
# = valid loss가 기존의 Lowest Loss보다 작을 때
# = Lowest Loss가 갱신되었을 때
lowest_loss = valid_loss # 이 때 valid loss를 Lowest loss로 새로 재임명
lowest_epoch= epoch # Lowest Loss가 갱신되었을 때의 epoch를
# lowest_epoch 변수에 저장
# Lowest Loss가 갱신되었을 때의 model 저장
torch.save(model.state_dict(), './model_regression.bin')
# pth, pt 확장자로도 저장 가능!
else:
# else: valid loss가 기존의 Lowest Loss보다 여전히 커서, Lowest Loss가 갱신되지 않는 상황
if early_stop > 0 and lowest_epoch+ early_stop < epoch +1:
# Lowest Loss가 나왔던 지점(lowest_epoch) 보다
# early_stop만큼의 epoch 수만큼 train이 진행되었는데도 여전히 같은 상황이라면
print("삽 질 중")
# 원래는 print("There is no improvement during %d epochs" % early_stop)
break
# 중단
print()
print("The Best Validation Loss=%.3e at %d Epoch" % (lowest_loss, lowest_epoch))
# model load : Lowest Loss가 마지막으로 갱신되 지점에서 저장된 모델을 불러온다.
model.load_state_dict(torch.load('./model_regression.bin'))
result = dict()
# train_epoch_loss가 담긴 train_hs와
# valid_epoch_loss가 담긴 valid_hs를
# result라는 dictionary에 담아서 깔끔하게 반환
result["Train Loss"] = train_hs
result["Valid Loss"] = valid_hs
return model, result11 train 시작!
: 다음 코드로 학습 시작!
model, result = run_train()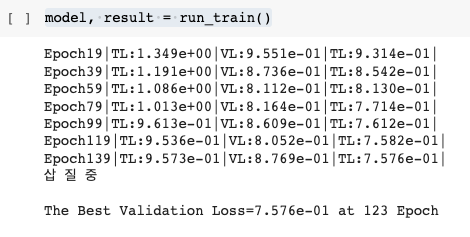
-
"삽 질 중"이라는 문구가 떴다면, early stop이 적용된 것을 알 수 있다.
- 123 Epoch에서 최저의 Valid Loss가 발생하였고, 123Epoch부터 143 Epoch까지의 Loss 중 123 Epoch에서의 Loss보다 작은 Loss가 없어서(=Lowest Loss 갱신이 안 되서) "삽 질 중" 문구를 print하고 break 되서 train이 종료된 것이다.
12 시각화 - train_loss, valid_loss
## Train/Valid History
plot_from = 0
plt.figure(figsize=(20, 10))
plt.title("Train/Valid Loss History", fontsize = 20)
plt.plot(
range(0, len(result['Train Loss'][plot_from:])),
result['Train Loss'][plot_from:],
label = 'Train Loss'
)
plt.plot(
range(0, len(result['Valid Loss'][plot_from:])),
result['Valid Loss'][plot_from:],
label = 'Valid Loss'
)
plt.legend()
plt.yscale('log')
plt.grid(True)
plt.show()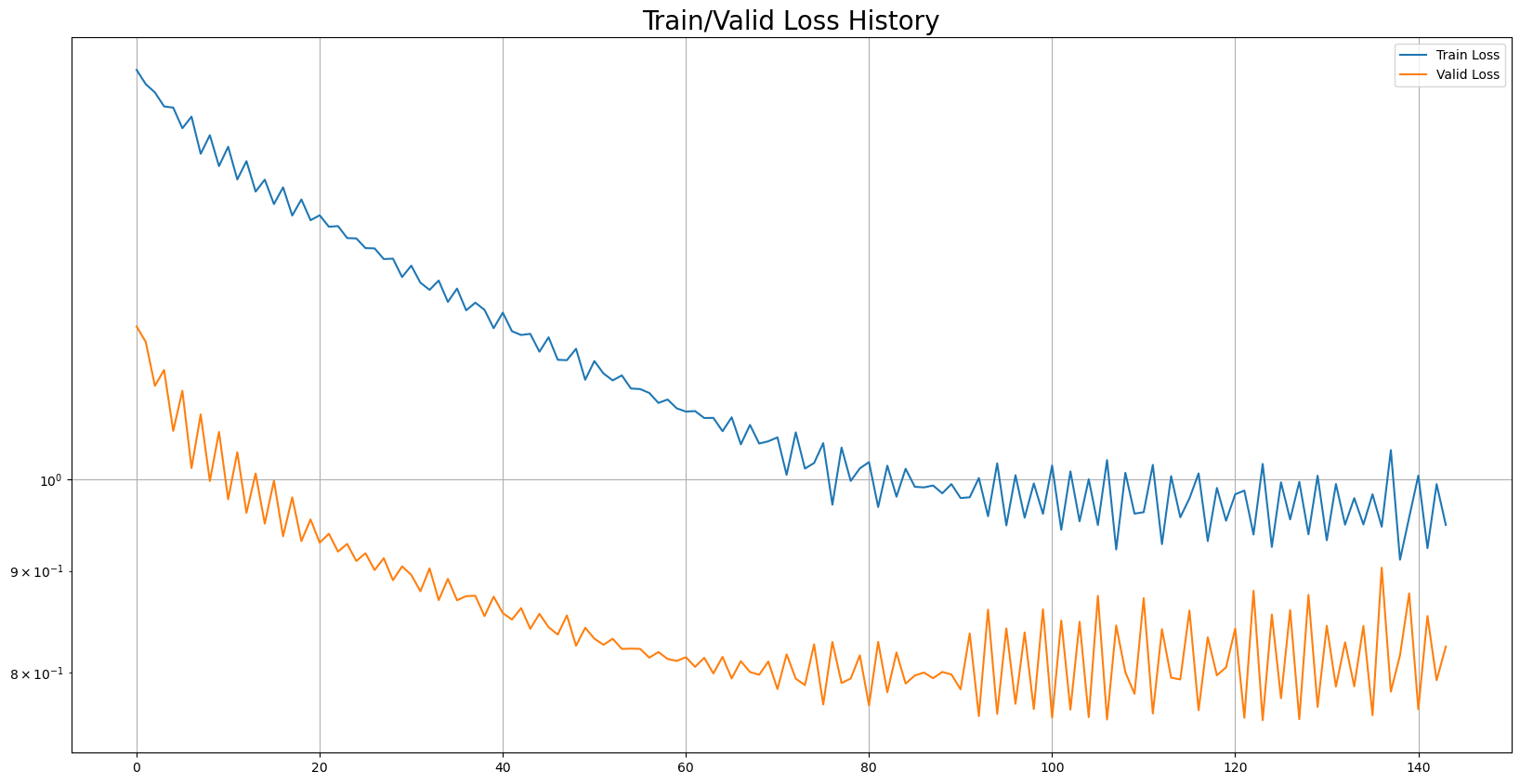
이로서 01 Regression이 끝났다.
- 처음이라 설명이 길었다. 나중에는 설명 안 할 것이다.
- 공유한 실습코드는 M1에서도 잘 돌아간다.
