INTRO
: 두 번째로 기본적인 CLASSIFICATION 문제를 풀어보려고 한다.
- Torchvision에서 CIFAR10 데이터를 사용해보도록 한다.
- EDA, PREPROCESSING 모두 생략 -> BASIC FLOW에 익히는 것이 목적
- [가장 중요] 데이터의 Shape 추적은 반드시 해야한다.
- 에러를 막을 수 있고 의미 파악하는 가장 빠른 지름길
- 혹시라도 잘못된 부분이 있다면 꼭 알려줬으면 한다.
Code
- 실습코드 - Colab에서뿐만 아니라, M1에서도 잘 돌아간다.
- 처음이라 설명이 좀 길다. 이후의 포스트에서는 중복 설명은 생략할 것이다.
순서
: Import -> Data -> Dataset -> DataLoader -> Model -> Loss Function and Optimizer -> train_one_epoch() and valid_one_epoch() -> run_train()
01 IMPORT
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# torchvision - CIFAR10 데이터를 사용하기 위해서
import torchvision
from torchvision import transforms, datasets1) import torch.nn as nn
: nn을 이용해서 nn.Module을 상속받아서 다음 예시처럼 Model을 빌드한다. 그래서 필요하다.
class Model(nn.Module):
def __init__(self, input_dim = 8, output_dim = 1):
super().__init__()
self.fc1 = nn.Linear()
...2) from torch.utils.data import Dataset, DataLoader
: Dataset과 DataLoader는 데이터를 배치 단위로 학습할 데이터(x)와 정답 데이터(y)를 묶어서 뱉어주는 역할을 한다.
02 DATA: CIFAR10
: Torchvision의 CIFAR10 데이터를 사용한다. EDA, PREPROCESSING 모두 생략한다.
-
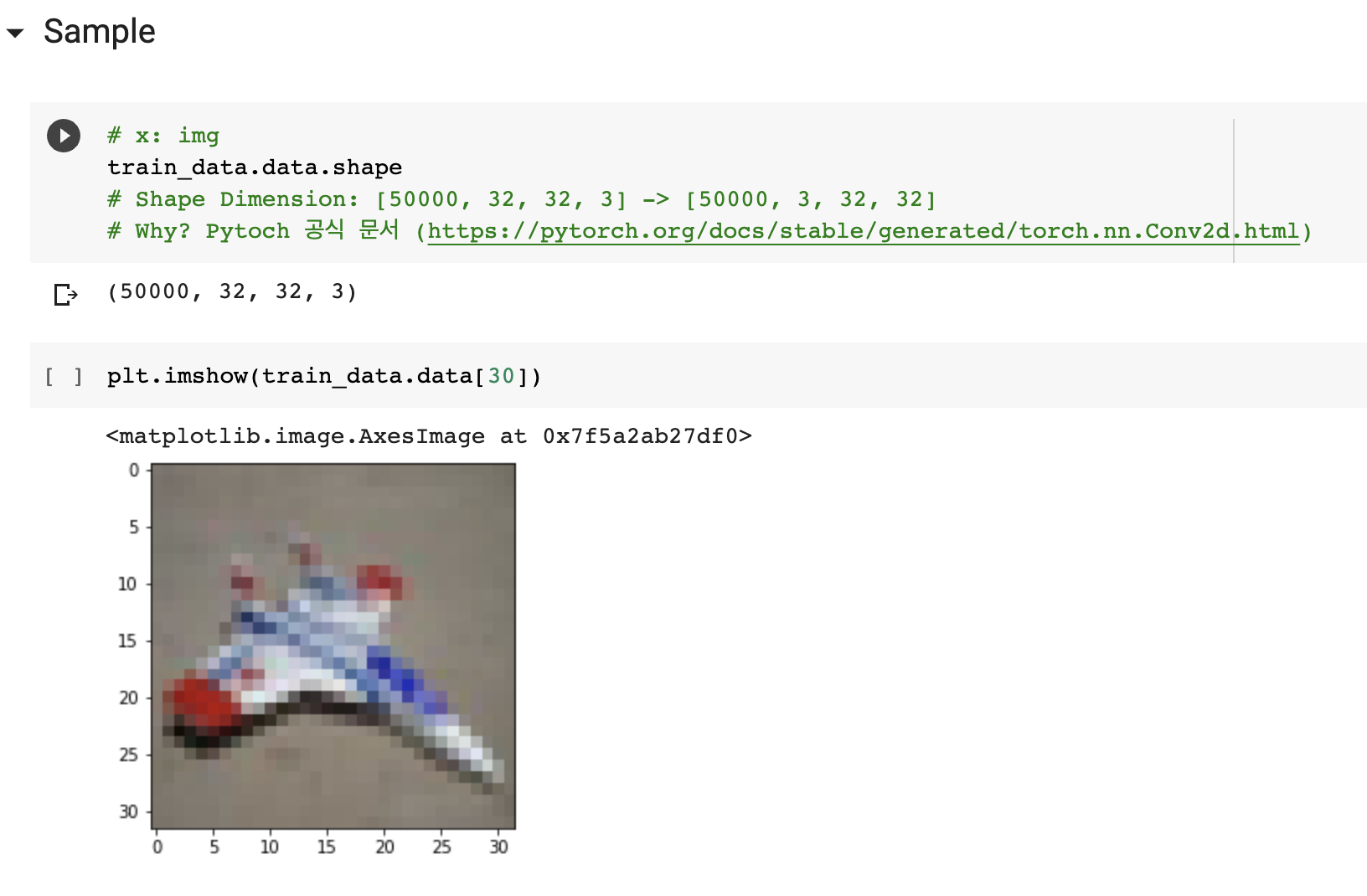
X: train_data.data
- 50000장의 IMG 데이터
- SHAPE: [50000, 32, 32, 3]
- 가로, 세로 = 32, 32
- 채널 = 3 (RGB)
- DTYPE: INT
- CH 정보가 배치 바로 뒤에 있는 것이 아닌, 맨 뒤에 있다.
-
Y: train_data.targets
- Class Int(0 ~ 9)가 담긴 리스트
- len(train_data.targets) # 50000train_data = datasets.CIFAR10('./data', download= True, # 다운받을래 말래? train = True, # Train 데이터 쓸 거니? transform = transforms.ToTensor() # transform의 경우, Augmentation할 때 쓰이는 옵션인데... 아직은 위처럼 쓴다고 해서 적용되는 건 못 봄... # torchvision의 CIFAR10의 Dataset Class에 바로 적용(?)하는 게 있는데 그 때 쓰이는 것 같음 ) # 우리는 슬프게도 시간이 많지 않으므로 train_data를 train, valid로 쪼개서 진행할 예정 # 즉, test_data는 여기서 안 쓸 예정 # test_data = datasets.CIFAR10('./data', download= True, train = False, transform = transforms.ToTensor())Sample
03 Dataset
: Dataset을 상속받아서 MyDataset 클래스를 만들어준다.
-
두 가지 버전을 소개하는 데, 둘 중 이해가 되는 것으로 진행해도 된다.
1) 초보자 버전
## 초보자 버전 class MyDataset(Dataset): def __init__(self, data = train_data.data, # [50000, 3, 32, 32] label = train_data.targets # [50000] ): self.x = data / 255. # Data Type: int -> Float by (/ 255.) self.x = np.transpose(self.x, (0, 3, 1, 2)) # Shape Dimension: [50000, 32, 32, 3] -> [50000, 3, 32, 32] # self.x: numpy array, float self.y = label # list of Int # [6, 9, 9, 4, 1, ..] def __len__(self): # 전체 길이 정보 반환 return self.x.shape[0] # len(self.y) def __getitem__(self, index): # index 로 row 하나를 특정하고, x, y를 뱉어줍니다. x = self.x[index] # img 한 장 -> Shape: [3, 32, 32] y = self.y[index] # 숫자 하나 -> Shape: [] # 예시1) y: 5 -> Shape: [] # 예시2) y: [5] -> Shape: [1] # return x, y # numpy return torch.tensor(x, dtype = torch.float), torch.tensor(y, dtype = torch.long)- def __init__(self)
- 생성자 함수에서는 전체 데이터셋에서의 X, Y를 선언
- self.x: train_data.data를 Float으로 바꿔주고, Shape을 [50000, 32, 32, 3] 에서 [50000, 3, 32, 32]로 변환해준다.
- self.y: train_data.targets 그대로 받아준다.
- def __len__(self)
- 여기서는 전체 데이터의 길이 정보를 반환한다.
- def __getitem__(self)
- 여기서는 'index'로 인덱싱하여, row 하나를 특정한다.
- 이게 잘 안 와닿으면, KFold 생각하면 될 것이다.
## 다른 데서 코드 가져옴 for fold, ( _, val_) in enumerate(skf.split(X=df, y=df['target'])): df.loc[val_ , "kfold"] = int(fold) # _, val_ : index 넘버 - 여기서 x는 이미지 한 장, y는 Int 하나이다. 이 x, y의 Shape은 [3, 32, 32], []로 나온다.
- Int 하나만 나온다면, 즉, [ ] 없이 Int 하나의 Shape은 [] 으로 나온다.
- Int 하나가 []안에 같이 나온다면(예시: [5]), Shape은 [1] 으로 나온다.
- 이게 잘 안 와닿으면, KFold 생각하면 될 것이다.
- 우리는 토치의 민족이기 때문에 x, y를 토치 텐서로 반환 하여 반환해준다.
return torch.tensor(x, dtype = torch.float), torch.tensor(y, dtype = torch.long)
- 여기서는 'index'로 인덱싱하여, row 하나를 특정한다.
2) 좀 있어보이는 버전: 시크하고 간결해보이는 버전
## 좀 있어보이는 버전: 시크하고 간결해보이는 버전 class MyDataset(Dataset): def __init__(self, data = train_data.data, # [50000, 3, 32, 32] label = train_data.targets # [50000] ): self.x = torch.tensor( data / 255. , dtype = torch.float).permute(0, 3, 1, 2) # self.x: Float + Shape Dimension 수정 + Torch Tensor로 self.y = torch.tensor(label, dtype = torch.long) # self.y: list + Torch Tensor로 def __len__(self): # 전체 길이 정보 반환 return self.x.shape[0] # len(self.y) def __getitem__(self, index): # index 로 row 하나를 특정하고, x, y를 뱉어줍니다. return self.x[index], self.y[index]- def __init__(self)
- 생성자 함수에서는 전체 데이터셋에서의 X, Y를 선언
- self.x: train_data.data를 Float으로 바꿔주고, Shape을 [50000, 32, 32, 3] 에서 [50000, 3, 32, 32]로 변환하고 Torch Tensor로까지 변환해준다.
- self.y: train_data.targets 그대로 받아주고 Torch Tensor로까지 변환해준다.
- def __len__(self)
- 여기서는 전체 데이터의 길이 정보를 반환한다.
- def __getitem__(self)
- 여기서는 'index'로 인덱싱하여, row 하나를 특정한다.
- 우리는 토치의 민족이기 때문에 x, y를 토치 텐서로 반환 되어있기에 그대로 반환해준다.
- def __init__(self)
04 prepare_loaders: Dataset -> DataLoader
: 여기서는 학습에 사용할 데이터와 성능 검증에 필요한 데이터로 쪼개준다. 그리고 각 데이터에 대해서 배치 단위로 뱉어줄 수 있도록 DataLoader 객체를 각각 만들어준다. 이 과정을 prepare_loaders() 함수에 담았다.
def prepare_loaders(datas = train_data.data,
labels = train_data.targets,
index_num = 30000,
bs = 128*2):
# train, valid split
train = datas[:index_num]#.reset_index(drop = True) # numpy array 라서 할 필요 없음
# train: 30000 imgs
valid = datas[index_num:]#.reset_index(drop = True)
# valid: 20000 imgs
train_label = labels[:index_num] # 30000 labels
valid_label = labels[index_num:] # 20000 labels
# train_ds, valid_ds by MyDataset
train_ds = MyDataset(data = train, label = train_label)
valid_ds = MyDataset(data = valid, label = valid_label)
# train_loader, valid_loader
# DataLoader에서 batch단위 크기로 row들을 묶어서 뱉어줌
train_loader = DataLoader(train_ds, batch_size = bs, shuffle = True)
valid_loader = DataLoader(valid_ds, batch_size = bs, shuffle = False)
return train_loader, valid_loader
train_loader, valid_loader = prepare_loaders()train_loader에서 나오는 배치의 Shape을 확인해보자.
: Data의 Shape 추적이 가장 중요하다. 그래서 여기서도 확인해볼 필요가 있다. 아마 x에 해당하는 부분의 Shape은 [256, 3, 32, 32], y에 해당하는 부분의 Shape은 [256] 으로 나올 것이다.
## train_loader가 뱉는 배치 크기 확인해보자
data = next(iter(train_loader))
data[0].shape, data[1].shape
# [bs, 3, 32, 32] [bs]
05 device
: torch.tensor를 비롯해서 train_loader, valid_loader에서 나오는 배치들과 Model의 layer들을 모두 GPU로 보내기 위한 코드이다. M1, Colab에서 적용할 수 있는 코드이며, '지금 GPU 쓸 수 있니? 없니?' 라고 확인 후, if else 조건문을 통해 GPU로 보내는 코드이다.
# Colab
# device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
# M1 버전
device = torch.device("mps") if torch.backends.mps.is_available() else torch.device("cpu")06 Model
: nn.Module을 상속받아서 Model 클래스를 빌드한다.
class Model(nn.Module):
def __init__(self):
super().__init__()
## Frame만 선언
## Shape 추적: 주석으로 Shape 쓰면서
## x(=input)'s shape: [bs, 3, 32, 32]
self.conv1 = nn.Conv2d(in_channels = 3, out_channels = 16,
kernel_size = 3, stride = 1, padding = 1)
# [bs, 3, 32, 32] -> [bs, 16, 32, 32]
self.conv2 = nn.Conv2d(in_channels = 16, out_channels = 32,
kernel_size = 7, stride = 1, padding = 0)
# [bs, 16, 32, 32] -> [bs, 32, 26, 26]
# h' = {(h + padding * 2 - kernel_size) / stride} + 1
self.pool = nn.MaxPool2d(2, 2)
# [bs, 32, 26, 26] -> [bs, 32, 13, 13]
# [bs, 32, 13, 13] -> [bs, k] # 3차원 -> 2차원
k = 32*13*13
# [bs, k] -> [bs, 512] -> [bs, 10]: 각 클래스별 확률값이 나오게 된다.
# 10: 10개의 클래스(0 ~ 9)
self.seq = nn.Sequential(
nn.Linear(k, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.LogSoftmax(dim=-1),
# nn.Softmax(dim=-1)
)
def forward(self, x):
# 함수 형태로 엮어주는 곳(실질적인 연산)
# x(=input)'s shape: [bs, 3, 32, 32]
x = self.conv1(x) # [bs, 3, 32, 32] -> [bs, 16, 32, 32]
x = self.conv2(x) # [bs, 16, 32, 32] -> [bs, 32, 26, 26]
x = self.pool(x) # [bs, 32, 26, 26] -> [bs, 32, 13, 13]
y = torch.flatten(x, start_dim = 1)
# [bs, 32, 13, 13] -> [bs, k] # 차원 축소
y = self.seq(y) # [bs, k] -> [bs, 512] -> [bs, 10]
return y
# y: [bs, 10]
model = Model().to(device) # GPU로 보내준다.- 데이터가 배치 단위로 들어온다.
- x가 배치단위로 묶여서 [bs, 3, 32, 32] Shape으로 들어온다. (bs: 배치단위크기)
- model의 최종값(y_pred)는 Predicted 값이며, Shape은 [bs, 10]으로 나온다.
- y가 배치단위로 묶여서 [bs] Shape으로 나타나는데, 이는 y_pred의 Shape과 다르다.
- 이는 CrossEntropyLoss 혹은 NLLLoss 등 Classification에서의 Loss Function 때문에 그렇다.
- 여기서는 딥하게 설명하지 않는다. 추후 다른 포스트를 통해 설명할 기회가 있다면 설명해보려고 한다.
- def __init__(self) 에서는 'Frame만 선언'해준다고 생각하면 된다.
- nn.Conv2d(), nn.MaxPool2d() 가 나오는데, 기본적으로 개념을 알고 있을 것이라고 생각한다.
- def forward(self, x) 에서는 '실질적으로 위에서 선언한 Frame들을 함수형태로 넣어주며 엮어주는 곳'이라고 생각한 된다.
- def __init__(self) 와 def forward(self, x) 에서 모두 Shape 추적을 하면서 코드를 작성해보자. 꼭!
07 Loss Function and Optimizer
: Loss Function과 Optimizer를 선언한다.
- NLLLoss
- Adam
# loss_fn도 to(device)가 가능하다. (= GPU로 보내줄 수 있다.)
# loss_fn = nn.CrossEntropyLoss() --- Softmax : 둘이 세트!
loss_fn = nn.NLLLoss() # --- LogSoftmax: 둘이 세트!
# optimizer는 to(device)가 불가능하다. (= GPU로 보내줄 수 없다.)
optimizer = torch.optim.Adam(model.parameters())08 train_one_epoch()
: model이 한 epoch를 도는 동안, model이 학습되는 과정과 train_epoch_loss(=epoch당 평균 train loss)와 train_acc(=epoch당 평균 train accuracy)를 return 시키는 함수이다.
- model이 학습을 진행 (Back-Prop)
- train 데이터 -> train_loader
- [New] tqdm 간지
: 실시간 train_epoch_loss, train_acc를 Progress Bar와 같이 나타내주도록 하였다.- 학습 목적으로 Accuracy를 구현했지만, torchmetrics를 이용해서 간편하게 사용해도 된다.
- 실제로 프로젝트 할 때, F1 Score 등 기타 Metric이 필요할 때, torchmetrics부터 쏘쿨하게 쓴다.
from tqdm import tqdm
def train_one_epoch(model = model, dataloader = train_loader,
loss_fn = loss_fn, optimizer = optimizer,
device = device, epoch = 1):
model.train()
train_loss, dataset_size = 0, 0 # train loss, accuracy를 실시간으로 구현
preds, trues = [], []
bar = tqdm(dataloader, total= len(dataloader))
for data in bar:
x = data[0].to(device) # shape: [bs, 3, 32, 32]
bs = x.shape[0]
y_true = data[1].to(device) # shape: [bs]
y_pred = model(x) # y_pred: [bs, 10]
loss = loss_fn(y_pred, y_true)
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 실시간 train_loss
dataset_size += bs # 실시간으로 크기가 update
train_loss += (loss.item() * bs) # batch 단위 loss가 누적
train_epoch_loss = train_loss / dataset_size # 실시간 train loss
# 실시간 Accuracy - 다음 시간에 :)
preds.append(y_pred) # preds: [ [bs, 10], [bs, 10], ...]
trues.append(y_true) # trues: [ [bs], [bs], [bs], ...]
preds_cat = torch.cat(preds, dim = 0) # preds_cat: [total_bs, 10]
trues_cat = torch.cat(trues, dim = 0) # trues_cat: [total_bs]
# torch.argmax(preds_cat, dim=1) # [total_bs]
train_acc = 100 * (trues_cat == torch.argmax(preds_cat, dim=1)).sum().detach().cpu().item() / dataset_size # 전체 맞은 개수
bar.set_description(f"EP:[{epoch:02d}]|TL:[{train_epoch_loss:.3e}]|ACC:[{train_acc:.2f}]")
return train_epoch_loss, train_acc
09 valid_one_epoch()
: model이 한 epoch를 도는 동안, valid_epoch_loss(=epoch당 평균 valid loss)와 valid_acc(=epoch당 평균 valid accuracy)를 return 시키는 함수이다.
- 여기서는 model이 학습되지 않는다.
- 오직 성능 평가만 한다.
- valid 데이터 -> valid_loader
- [New] tqdm 간지
: 실시간 valid_epoch_loss, valid_acc를 Progress Bar와 같이 나타내주도록 하였다.
# @torch.no_grad() : 데코레이터 형태의 'model을 학습 시키지 않겠다는 필수 의지 표명 2'
# --> 근데 함수형일 때 쓸 수 있는 것으로 알고 있다.
# --> model을 학습 시키지 않겠다는 필수 의지 표명 1과 2 중 하나만 써도 무방하다.
@torch.no_grad()
def valid_one_epoch(model = model, dataloader = valid_loader,
loss_fn = loss_fn,
device = device, epoch = 1):
model.eval()
valid_loss, dataset_size = 0, 0 # valid loss, accuracy를 실시간으로 구현
preds, trues = [], []
bar = tqdm(dataloader, total= len(dataloader))
with torch.no_grad():
for data in bar:
x = data[0].to(device) # shape: [bs, 3, 32, 32]
bs = x.shape[0]
y_true = data[1].to(device) # shape: [bs]
y_pred = model(x) # y_pred: [bs, 10]
loss = loss_fn(y_pred, y_true)
# 실시간 valid loss
dataset_size += bs # 실시간으로 크기가 update
valid_loss += (loss.item() * bs) # batch 단위 loss가 누적
valid_epoch_loss = valid_loss / dataset_size # 실시간 valid_loss
# 실시간 valid Accuracy
preds.append(y_pred) # preds: [ [bs, 10], [bs, 10], ...]
trues.append(y_true) # trues: [ [bs], [bs], [bs], ...]
preds_cat = torch.cat(preds, dim = 0) # preds_cat: [total_bs, 10]
trues_cat = torch.cat(trues, dim = 0) # trues_cat: [total_bs]
# torch.argmax(preds_cat, dim=1) # [total_bs]
val_acc = 100 * (trues_cat == torch.argmax(preds_cat, dim=1)).sum().detach().cpu().item() / dataset_size # 전체 맞은 개수
bar.set_description(f"EP:[{epoch:02d}]|VL:[{valid_epoch_loss:.3e}]|ACC:[{val_acc:.2f}]")
return valid_epoch_loss, val_acc10 run_train()
: 여기서는 전반적인 train 과정을 담았다.
- train_one_epoch() / valid_one_epoch()
- 시각화를 위한 epoch당 평균 train_loss, valid_loss, train_acc, valid_acc 담기
- monitoring: 특정주기마다 loss들 체크
- Lowest Loss가 갱신될 때, model 저장
- 오버피팅 방지를 위한 early_stop
def run_train(model = model,
n_epochs = 150,
train_loader = train_loader,
valid_loader = valid_loader,
loss_fn = loss_fn,
optimizer = optimizer,
device = device):
# 시각화를 위해서 줍줍할 list - [LOSS, ACCURACY] * [TRAIN, VALID]
train_hs, valid_hs, train_accs, valid_accs = [], [], [], []
# monitoring을 위한 주기
print_iter= 10
# Lowest Loss 갱신할 때 필요
lowest_loss, lowest_epoch = np.inf, np.inf
# 오버 피팅 방지
early_stop = 20
for epoch in range(n_epochs):
# epoch 당 평균 train loss: train_epoch_loss
train_loss, train_acc = train_one_epoch(model = model,
optimizer = optimizer,
dataloader = train_loader,
loss_fn = loss_fn,
device = device,
epoch = epoch)
# epoch 당 평균 valid loss: valid_epoch_loss
valid_loss, valid_acc = valid_one_epoch(model = model,
dataloader = valid_loader,
loss_fn = loss_fn,
device = device,
epoch = epoch)
# 시각화를 위해서 위에서 선언한 빈 리스트 4개에 줍줍한다.
# Train, Valid 각각에 대해서 Loss와 Accuracy의 추이를 시각화할 예정
train_hs.append(train_loss)
train_accs.append(train_acc)
valid_hs.append(valid_loss)
valid_accs.append(valid_acc)
# monitoring
# : 특정 주기(=print_iter)마다 Train Loss, Valid Loss, Lowest Loss를 찍어준다.
if (epoch + 1) % print_iter == 0:
print(f"Epoch{epoch}|TL:{train_loss:.3e}|VL:{valid_loss:.3e}|LL:{lowest_loss:.3e}|")
# Lowest Loss 갱신 - Valid Loss 기준
if valid_loss < lowest_loss:
# = valid loss가 기존의 Lowest Loss보다 작을 때
# = Lowest Loss가 갱신되었을 때
lowest_loss = valid_loss # 이 때 valid loss를 Lowest loss로 새로 재임명
lowest_epoch= epoch # Lowest Loss가 갱신되었을 때의 epoch를
# lowest_epoch 변수에 저장
# Lowest Loss가 갱신되었을 때의 model 저장
torch.save(model.state_dict(), './model_classification.bin')
# pth, pt 확장자로도 저장 가능!
else:
# else: valid loss가 기존의 Lowest Loss보다 여전히 커서, Lowest Loss가 갱신되지 않는 상황
if early_stop > 0 and lowest_epoch+ early_stop < epoch +1:
# Lowest Loss가 나왔던 지점(lowest_epoch) 보다
# early_stop만큼의 epoch 수만큼 train이 진행되었는데도 여전히 같은 상황이라면
print("삽질중")
# 원래는 print("There is no improvement during %d epochs" % early_stop)
break
# 중단
print()
print("The Best Validation Loss=%.3e at %d Epoch" % (lowest_loss, lowest_epoch))
# model load : Lowest Loss가 마지막으로 갱신되 지점에서 저장된 모델을 불러온다.
model.load_state_dict(torch.load('./model_classification.bin'))
result = dict()
# train_epoch_loss가 담긴 train_hs와
# valid_epoch_loss가 담긴 valid_hs를
# result라는 dictionary에 담아서 깔끔하게 반환
result["Train Loss"] = train_hs
result["Valid Loss"] = valid_hs
result["Train Accs"] = train_accs
result["Valid Accs"] = valid_accs
return model, result11 train 시작!
: 다음 코드로 학습 시작!
model, result = run_train()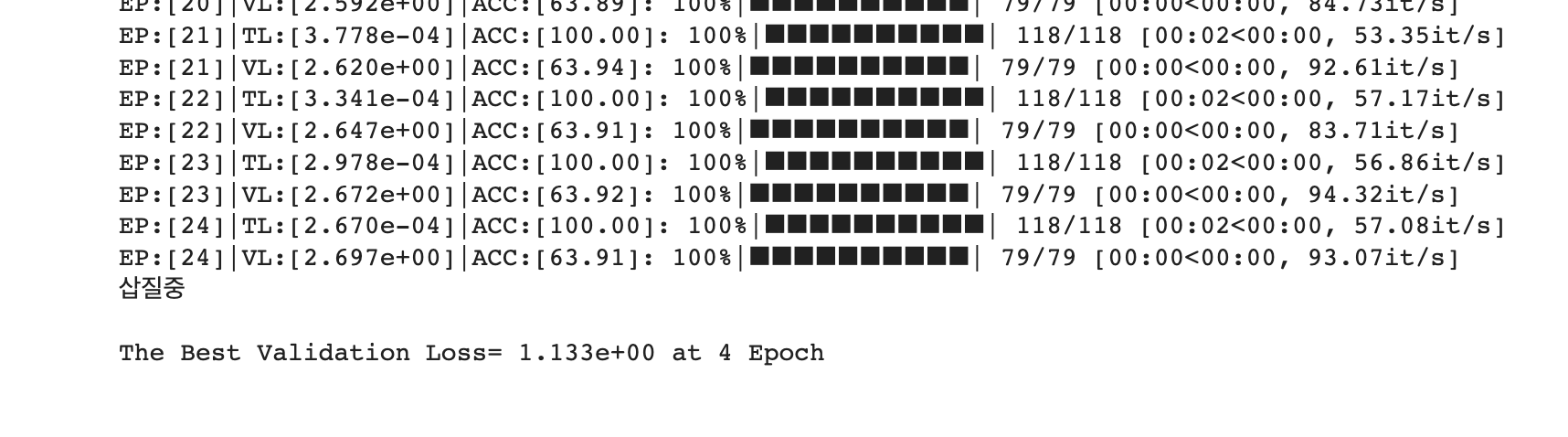
-
"삽질중"이라는 문구가 떴다. early stop이 적용된 것을 알 수 있다.
- 4 Epoch에서 최저의 Valid Loss가 발생하였고, 4Epoch부터 24 Epoch까지의 Loss 중 4 Epoch에서의 Loss보다 작은 Loss가 없어서(=Lowest Loss 갱신이 안 되서) "삽질중" 문구를 print하고 break 되서 train이 종료된 것이다.
12 시각화 - Loss, Accuracy
: train, valid 각각의 epoch에 따른 LOSS와 ACCURACY 추이를 보려고 한다.
## Train/Valid Loss History Visualization
plot_from = 0
plt.figure(figsize=(20, 10))
plt.title("Train/Valid Loss History", fontsize = 20)
plt.plot(
range(0, len(result['Train Loss'][plot_from:])),
result['Train Loss'][plot_from:],
label = 'Train Loss'
)
plt.plot(
range(0, len(result['Valid Loss'][plot_from:])),
result['Valid Loss'][plot_from:],
label = 'Valid Loss'
)
plt.legend()
plt.yscale('log')
plt.grid(True)
plt.show()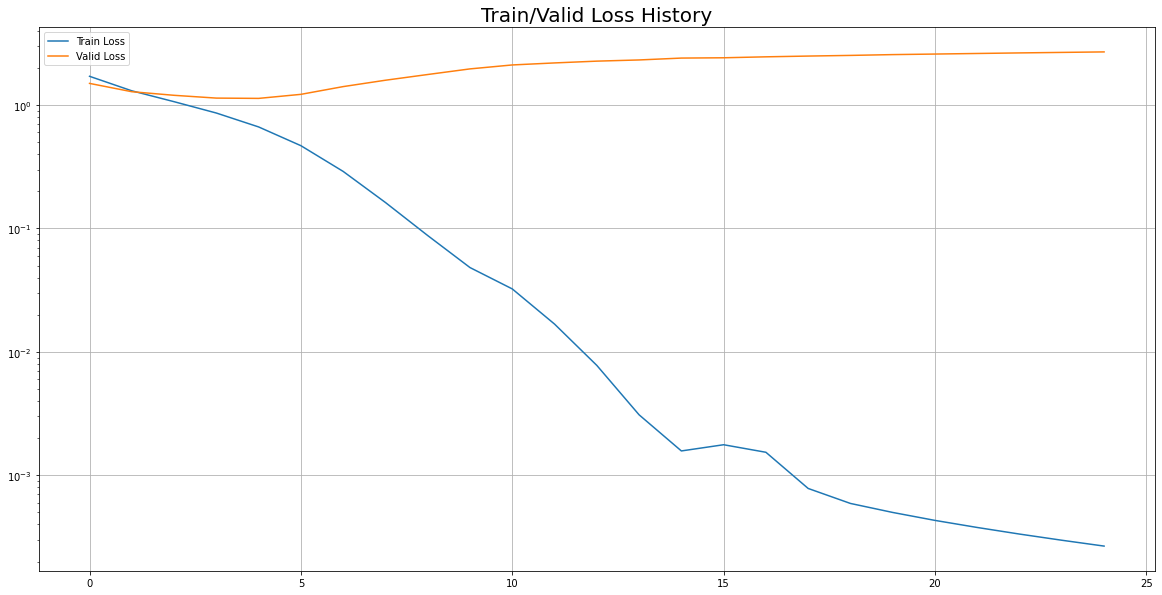
# Train/Valid Accuracy History Visualization
plot_from = 0
plt.figure(figsize=(20, 10))
plt.title("Train/Valid Accuracy History", fontsize = 20)
plt.plot(
range(0, len(result['Train Accs'])),
result['Train Accs'],
label = 'Train Accs'
)
plt.plot(
range(0, len(result['Valid Accs'])),
result['Valid Accs'],
label = 'Valid Accs'
)
plt.legend()
# plt.yscale('log')
plt.grid(True)
plt.show()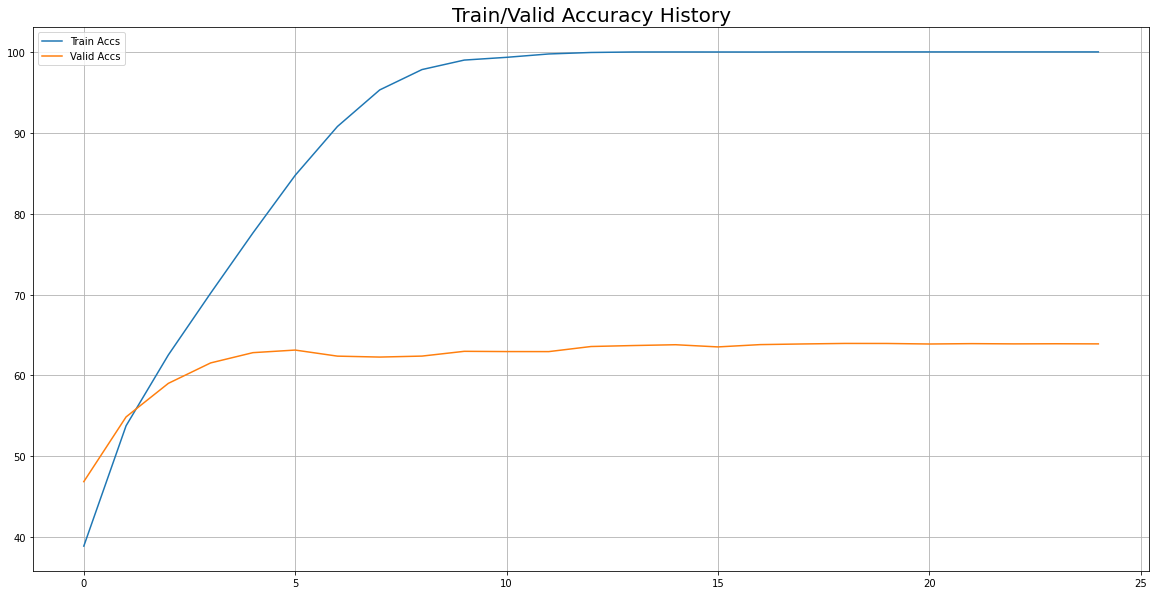
02 Classification이 끝났다.
- 실습코드는 이미 알겠지만, ipynb 파일로 다운받아서 M1에서 돌려도 잘 돌아간다.
- 여기 내용들이나 코드는 사실, M1 Part10 - '니들이 Pytorch 2.0을 아느냐?' Install Pytorch(GPU) on M1 에서의 새로운 실험코드와 거의 동일코드이다.
- 심심하면 성능체감해봐도 된다.
