INTRO
NLP에 발을 담근 이상, 트랜스포머는 마주해야한다. 그런데 슬프게도 필자는 무엇부터 봐야할 지 알 수 없었다. 고민 끝에 밤 10시까지 사무실에 남아서 Seq2Seq부터 공부를 하기 시작했다. 시간이 없었다고, 가르쳐주지 않았다고 해서 모른다고 누군가 친절하게 나타나서 알려주지 않기 때문이다. 차근차근 Seq2seq, Seq2seq with Attention, Transformer 구현까지 차근차근 공부했고, 당시 토치의 호흡 세션을 통해서 Transformer 구현에 관한 강의까지 할 수 있을 정도로 진화했다.
- References
- wandb 트랜스포머(Transformer) 심층 분석
- bentrevett/pytorch-seq2seq/attention_is_all_you_need.ipynb
: Seq2Seq부터 트랜스포머 공부할 때, 여기를 많이 참고했다. - 고현웅님의 트랜스포머 구현 깃허브
필자의 틈새시장전략(?)
: 필자의 글을 많이 본 이들이라면 조금은 알 것이다. 필자의 포스트는 사실 약간 코드 위주이다. 개념은 구글링을 하면 무지하게 많다. 그것도 엄청 다양하고 많이 있다. 그런데 코드 위주는 많이 없다. 그렇다고 필자의 코드가 기가 막히게 좋은 것도 아니다. 오히려 부족할 것이다. 그치만 이해하기 쉽게 짜려고 하는 편이다. 부족하지만 잘 부탁한다.
BackGround
필자는 기계번역이나 Summarization Task에 관심이 많다. 하지만, 무작정하기 보다 기본이 되는 Task 부터 차근차근 해보는 스타일이라서, 이제까지는 NLU Task 먼저 공부하고 PJT나 Competition에 참여해왔다.
-
History
: Transformer의 기원(?)을 거슬러 올라가면, 기계번역 태스크에서 시작된다. 처음에 기계번역을 Seq2Seq로 시도를 했었지만, 성능이 좋지 않았다. 그러다가 Attention이 탑재된 Seq2Seq 모델이 나오면서, 성능이 엄청 향상된다. 여기서 그치지 않고, 2017년에 Attention is all you need 논문이 나오면서 트랜스포머 아키텍처를 제안하게 되고, 이로 인해 NLP 분위기가 바뀌게 되고, 이제는 이를 Computer Vision에도 적용하여 ViT(Vision Transformer)도 나오게 된다. -
필자 체감 성능
: 필자는 Seq2Seq부터 공부를 하긴 했었다. 데이터를 구해서 Seq2Seq 코드를 코드필사하면서 공부했는데 약 2주 정도 걸렸다. 2주 정도의 긴 시간이 걸린 이유는 단순했다. '성능이 안 나와서' 였다. 성능이 너무 안 나와서 '이 길이 아닌가?' 싶을 정도였다. 그래서 김용담 강사님께 문의를 했었다. 강사님의 답변은 다음과 같았다."원래 (Seq2Seq) 성능이 나오려면, 10000 Epoch 이상을 학습해야 그나마 좀 괜찮게 나옵니다"
그래서 이 답변을 듣고 쿨하게 Seq2Seq with Attention로 넘어갔고, Seq2Seq with Attention 에서는 확실히 100에폭만 돌려도 확실히 성능이 괜찮게 나왔다. 그리고 Transformer 구현 코드를 찾아서 진행한 결과, 50에폭만 돌려도 잘 나왔다. (필자가 가진 데이터셋은 매우 귀여운 데이터셋이다.)
간단하게(?) 보는 트랜스포머 구조
: 정말 가볍게 보길 바란다. 정말로.
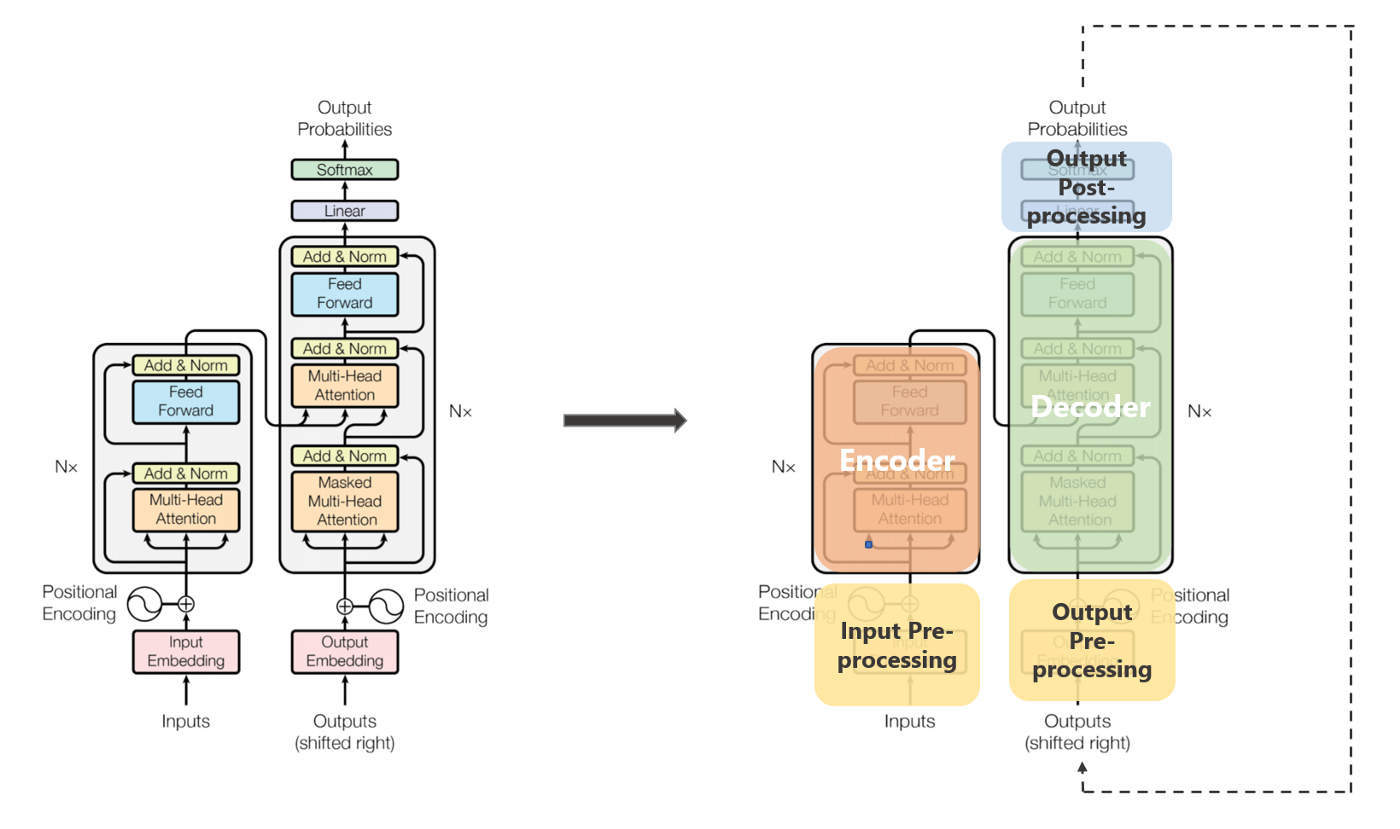
(1) BERT, Roberta와 같은 인코더 구조 모델
- Attention is all you need에서 말하는 트랜스포머 구조는 아니지만, Encoder 구조만 따와서 학습된 Pretrained Model이다. BERT, Roberta, Deberta 모두 여기에 속한다. Classification을 비롯하여 텍스트의 특정 속성을 파악하고 학습하거나 Inference 하는 TASK에서 적합하다. (Text Classificiation, NER, ... 등)
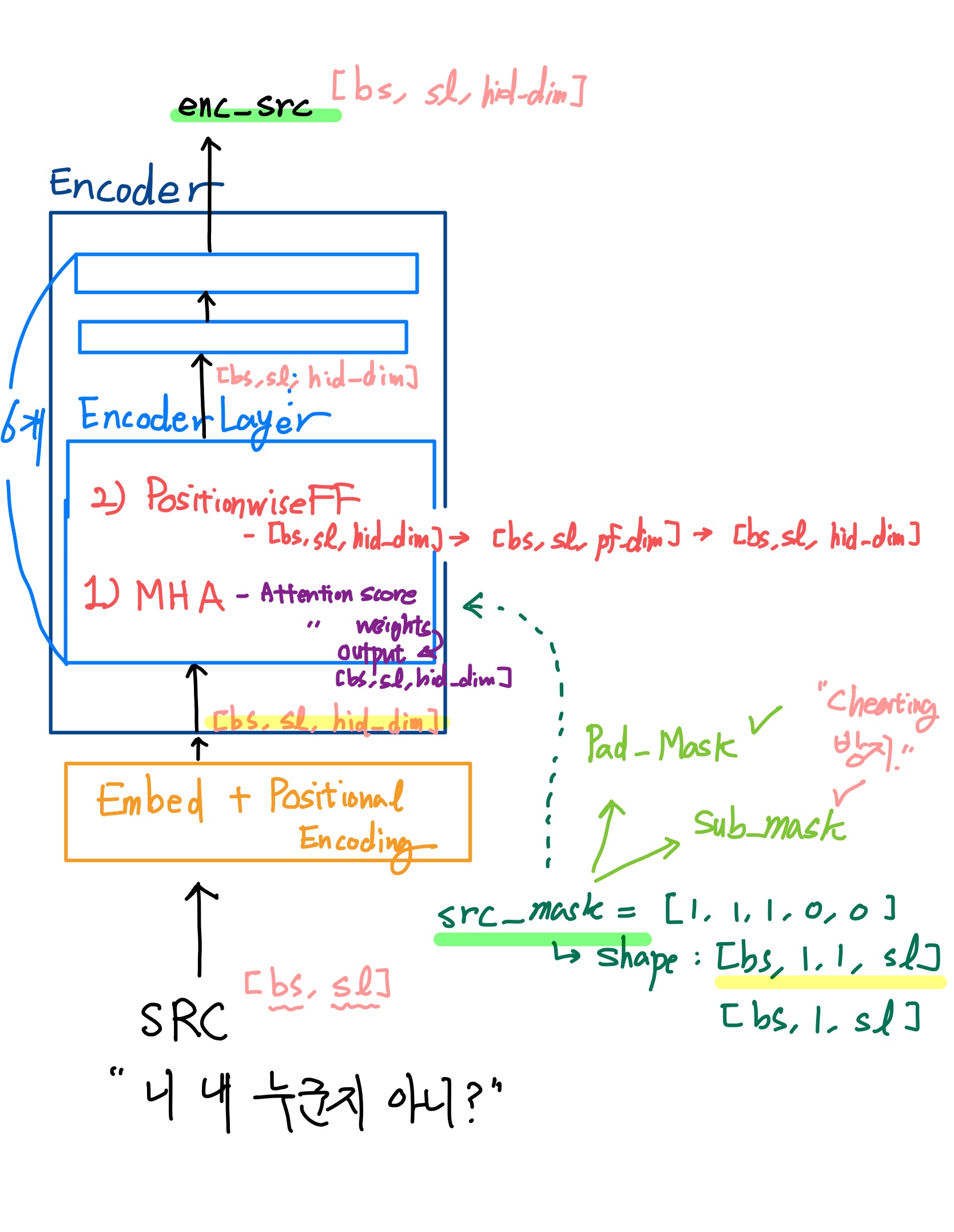
- 구조: Encoder에는 EncoderLayer가 (논문에 의하면) 6개가 존재한다. 각각의 EncoderLayer에는 MHA(Multi-Head Attention) 과 PositionwiseFF(PositionwiseFeedForwardLayer) 가 존재한다.
- Flow: 텍스트데이터가 토크나이징되고 숫자로 바뀐다음, (EncoderLayer를 지나기 전에) Embed와 PositionalEncodingLayer를 지난다. 지나면서 Shape이 [bs, sl, hid_dim] 등의 3차원으로 되고 위치정보를 부여받게 된다. 그리고 EncoderLayer 6개를 지나는 동안, Shape은 유지가 된다.
- 이 과정에서 문장의 각 토큰에 대한 관계도를 계산한다.(attention score) 그리고 이를 Softmax를 통해 가중치로 만들고 (attention weights) 가중치를 적용한 enc_src(attention output)을 뱉어내게 된다.
- mask에 관해서는 추후에 설명
(2) 오리지널 트랜스포머
-
Attention is all you need에서 말하는 트랜스포머의 구조이다. 기계번역 TASK에 적합하게 나왔다.
- SRC: 번역할 문장 (Source)
- TRG: 번역된 문장 (Target)
-
구조: Encoder와 Decoder가 존재하는데, Encoder는 위와 동일하다. Decoder 또한 Encoder 와 거의 비슷하다. (논문에 의하면) Decoder 안에 DecoderLayer 또한 6개가 존재한다. (아래 그림에서는 왜 8개로 했는지 기억이 나지 않는다.) 각각의 EncoderLayer에는 MHA(Multi-Head Attention) 과 PositionwiseFF(PositionwiseFeedForwardLayer) 가 존재하는데, Decoder에는 MHA(Multi-Head Attention) 가 2개 존재한다.
- MHA 중 첫 번째는 TRG(번역된 문장, label 문장)에서의 각 토큰간의 관계도를 계산하기 위함이고, 두 번째는 앞의 MHA로 계산하여 나온 TRG Attention output에 대하여, enc_src(Encoder의 Output, SRC의 관계도를 계산한 Attention output)을 토대로 번역하는(?) 과정이다. (= SRC의 문장의 문맥을 참고하는 과정)
- Decoder Layer가 6개가 존재하므로, enc_src는 이 6개의 DecoderLayer의 연산에 참여(?)한다.
-
Flow:
-
SRC, TRG 모두 각각 Embed와 Postional Encoding Layer를 지난다.
-
먼저, SRC가 Encoder를 통과하여 enc_src를 뱉어낸다.
-
TRG가 Decoder를 통과한다.(이 때 enc_src가 참여) 그 결과물이 output이다.
- output을 Softmax(dim=-1)를 하게 되면, 번역되는 문장이 나온다.
- 구조도는 사실 썸네일 이미지를 참고해도 된다. 내가 그린 이미지보다 훨씬 깔끔하긴 하다.

추후 방향
: Positional Encoding Layer 부터 시작하여 Encoder까지는 확실하게 할 예정이다.
: 하지만, Decoder 부분까지는 아직 고민 중이다.
: 다음 포스트는 Positional Encoding Layer이다. -
