[토치의 호흡] 08 About Transformer PART 02 "Positional Encoding Layer"
Torch's Breath
INTRO
누군가가 내게 트랜스포머에서 가장 중요한 부분을 몇 가지 말해보라고 한다면, Positional Encoding Layer를 빼놓지 않을 것이다. RNN 계열의 모델에서 벗어나 더 빠르고 그 이상의 성능을 내게 된 계기 중 하나는 바로 Positional Encoding Layer 이기 때문이다.
- 썸네일 이미지 출처
- 적어도 05 NLP Basic "Text to Tensor" 이 내용을 숙지하고 오도록 하자.
: 05 NLP Basic "Text to Tensor"의 예제로 이어서 진행할 예정 - References
- wandb 트랜스포머(Transformer) 심층 분석
- bentrevett/pytorch-seq2seq/attention_is_all_you_need.ipynb
: Seq2Seq부터 트랜스포머 공부할 때, 여기를 많이 참고했다. - 고현웅님의 트랜스포머 구현 깃허브
- 오늘의 Colab 실습코드 : 새로운 탭에서 열릴 것이다
Embed
: Positional Encoding Layer 직전에 Embed를 지난다. 하지만, 다행스럽게도 이 부분은 05 NLP Basic "Text to Tensor"의 예제와 거의 다를 게 없다고 봐도 무방하다. [bs, sl]로 들어오는 데이터를 [bs, sl, hid_dim]의 3차원 텐서로 뱉어준다.
- 여기서부터는 05 NLP Basic "Text to Tensor"의 예제가 이어진다고 봐도 무방하다.
- self.scale은 상수인데, 이를 곱해주는 연유는 모델 초기화 및 정규화 때문으로 알고는 있는데, 정확하게는 아직 모른다. (참고: wandb 트랜스포머 심층분석)
# Colab
# device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
# M1
device = torch.device('mps') if torch.backends.mps.is_available() else torch.device('cpu')
class Embed(nn.Module):
def __init__(self, input_dim = len(korbow.keys()), hid_dim = 8,
device = device, dropout = .1):
super().__init__()
self.device = device
self.dropout = nn.Dropout(dropout)
self.embed = nn.Embedding(input_dim, hid_dim)
# [bs, sl] ->[bs, sl, hid_dim]
self.scale = torch.sqrt(torch.Tensor([hid_dim])).to(device)
def forward(self, x):
# x: [bs, sl]
return self.scale * self.embed(x)
# [bs, sl, hid_dim] shape으로 return04 NLP Basic "Text to Tensor"의 예제였던 '커피가 맛이 좋네요'라는 문장이 토크나이징 된 후, torch int로 바뀌어 [bs, sl] Shape인 sample1_tensor가 Embed()를 통과했을 때 후의 Shape을 보자. (hid_dim은 논문에서 d_model과 같다.)
embed = Embed().to(device)
out1 = embed(sample1_tensor.to(device)) # GPU
out1 # [bs, sl, hid_dim]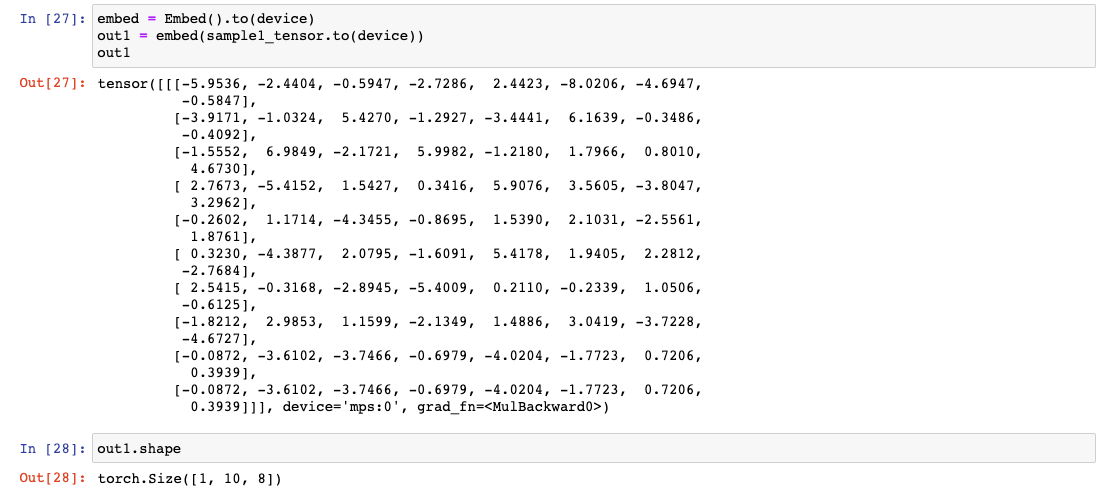
Positional Encoding Layer
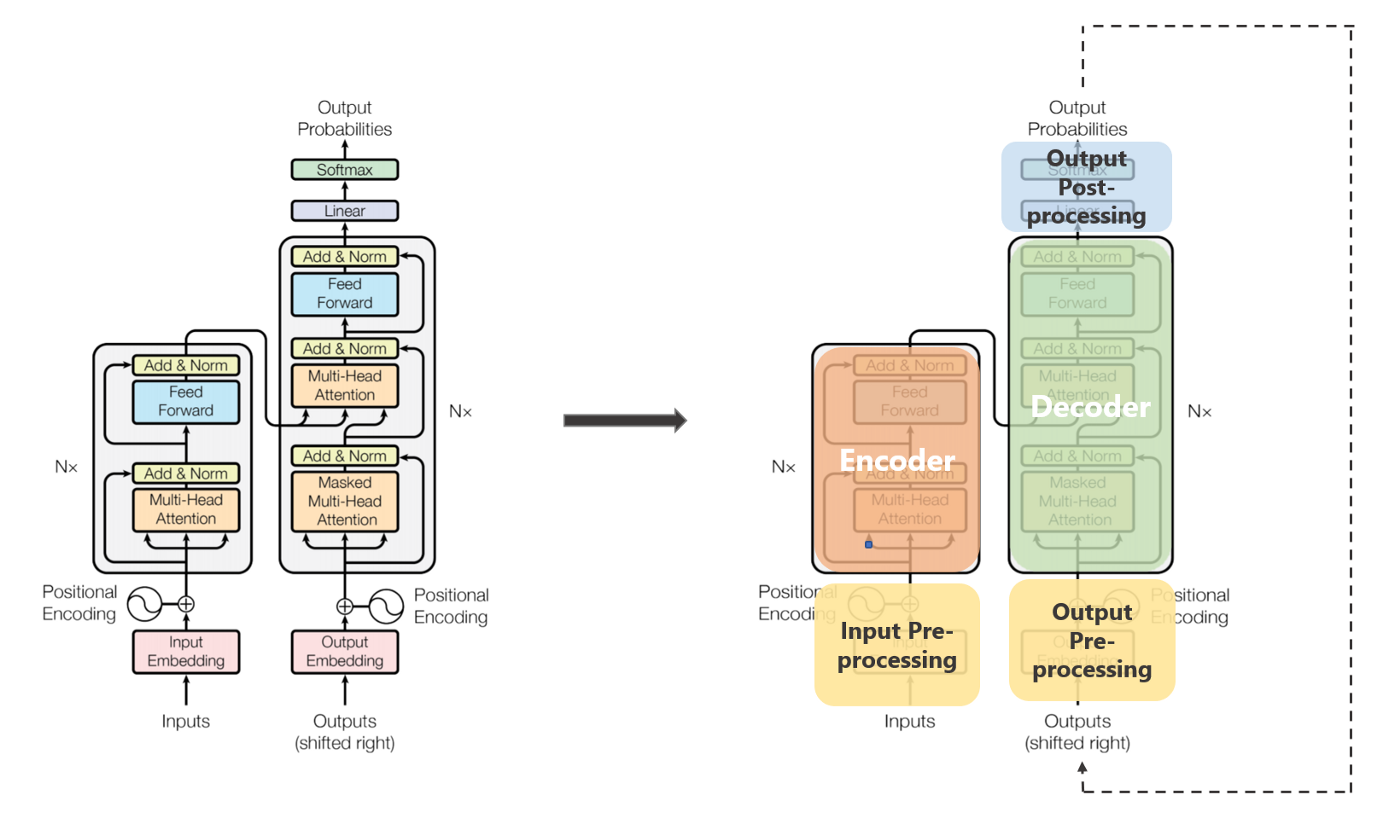
: 트랜스포머는 Seq2Seq 구조에서 당연하게 쓰이던, RNN계열 모델을 없앴지만, 그 이상의 처리 속도와 성능을 자랑한다. 그것을 가능하게 해준 것으로는 'Multi-Head Attetion', 'Scale Dot Product' 가 있다. 그리고 (필자 개인적으로 생각할 때) 'Positional Encoding Layer' 도 빼놓을 수 없다. RNN 계열 모델에서는 데이터(= 각 토큰)에 부여했던 time-step 정보를 Positional Encoding Layer 가 부여한다. 그리고 이를 기반으로 트랜스포머에서는 '병렬적으로 한 번에' 모든 정보를 처리할 수 있다. ( 자세하게 알고 싶다면 여기 를 참고하자. )
- Positional Encoding Layer는 논문에서 제안된 수식을 따른다.
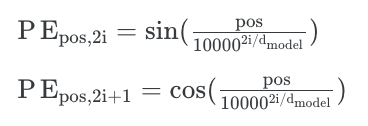
- '커피가 맛이 좋네요'라는 문장이 sample1_tensor로 되었다가, Embed()를 거쳐서 나온 out1이 PostionalEncodingLayer를 통과하여 EncoderLayer 혹은 DecoderLayer에 들어가게 된다.
(1) Code
Positional Encoding Layer 코드는 wandb 트랜스포머(Transformer) 심층 분석을 많이 참고하여 공부를 했다.
- 오늘의 Colab 실습코드를 참고하자.
from torch.autograd import Variable
class PositionalEncodingLayer(nn.Module):
def __init__(self,
max_len = 15, # max_length,
hid_dim = 8,
device = device,
dropout = .1):
super().__init__()
self.device = device
self.dropout = nn.Dropout(dropout)
# 1) # Shape
pe = torch.zeros(max_len, hid_dim) # [max_len, hid_dim]
# 2)
position = torch.arange(0, max_len).unsqueeze(1) # [max_len, 1]
# 3)
_2i = torch.arange(0, hid_dim, 2)
# _2i's Shape: [ int(hid_dim / 2) ]
# 4)
div_term = torch.exp( _2i * (-torch.log( torch.Tensor([10000.0]) ) / hid_dim ))
# div_term's Shape: [ int(hid_dim / 2) ]
pe[:, 0::2] = torch.sin(position * div_term) # 5)
pe[:, 1::2] = torch.cos(position * div_term) # 6)
# 7)
pe = pe.unsqueeze(0).to(device) # [max_len, hid_dim] -> [1, max_len, hid_dim]
# 8) 매개 변수로 간주되지 않는 버퍼를 등록하는 데 사용
self.register_buffer('pe', pe)
def forward(self, x):
# 9) forward
# return x + Variable(self.pe[:, :x.shape[1]], requires_grad = False)
return x + torch.Tensor(self.pe[:, :x.shape[1]]).requires_grad_(False)'커피가 맛이 좋네요'라는 문장이 sample1_tensor로 되었다가, Embed()를 거쳐서 나온 out1이 PostionalEncodingLayer를 통과하여 나오는 값을 out2라고 하자.
- out1, out2의 Shape을 한 번 보자. 동일할 것이다.
: PostionalEncodingLayer는 time-step을 부여하는 역할을 하기 때문이다.
pelayer = PositionalEncodingLayer()
out2 = pelayer(out1)
out2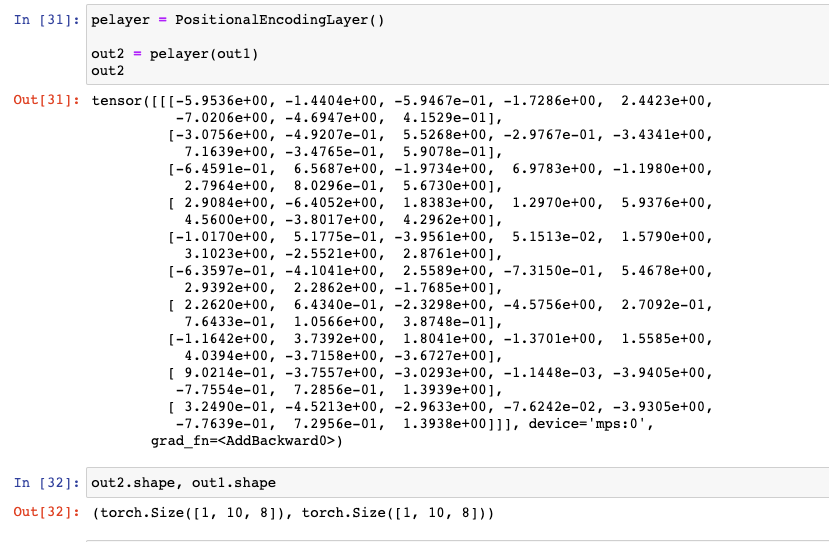
(2) 조금 상세하게
: 위 코드에서 1), 2) ... 8) 까지 주석으로 되어있는 것을 볼 수 있다. 간단한 예제로 한 줄씩 살펴보려고 한다. 임의로 max_len을 15로 두고, hid_dim을 8로 두고 진행한다.
1) self.pe = torch.zeros(max_len, hid_dim)
: 0으로 채워진 '틀'만 만들어주는 단계
max_len = 15
hid_dim = 8
# 1) self.pe = torch.zeros(max_len, hid_dim)
pe =torch.zeros(max_len, hid_dim)
pe.shape # [max_len, hid_dim]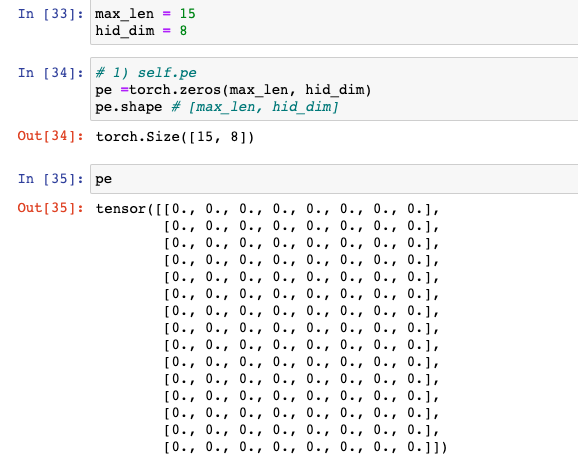
2) position = torch.arange(0, max_len).unsqueeze(1)
: 논문 수식에 나온 postion에 해당하는 부분이다. 문장 길이에 해당하는 부분이며, arange로 0부터 끝까지 index만 늘어놓고 unsqueeze(0)로 [max_len, 1] Shape으로 만들어두었다. (max_len은 max_length을 의미)
# 2) position
position = torch.arange(0, max_len).unsqueeze(1)
position.shape # [max_len, 1]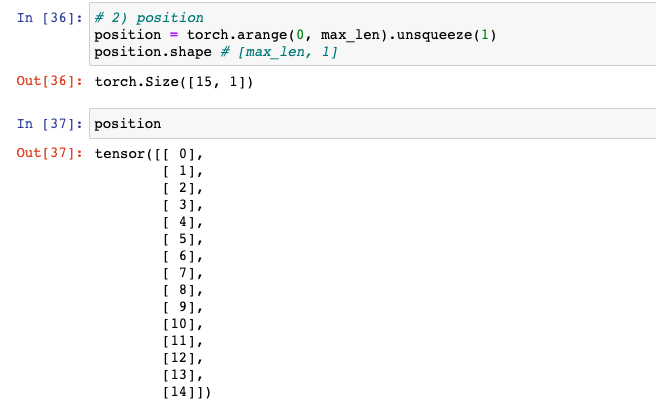
3) _2i = torch.arange(0, hid_dim, 2)
: 논문 수식에 나온 2i에 해당하는 부분이다. Embed를 지났을 때 가장 마지막 차원, 즉, 각 토큰을 hid_dim의 차원의 벡터로 표현했을 때, 그 벡터에 해당하는 부분이다. 여기서 2i는 이 벡터에서 0부터 시작하여 2칸씩 건너뛰어서 나오는 값만 선택한다.
- hid_dim은 임의로 8로 했는데, 0부터 시작하여 짝수만 나온다.
- Shape 또한 8이 아닌 4( =int( hid_dim / 2) )가 나온다.
# 3) 2i
_2i = torch.arange(0, hid_dim, 2)
_2i
4) div_term
: wandb 트랜스포머 심층분석 여기를 많이 참고하긴 했지만, 처음에 파악하는 데 오래걸렸던 부분이다. 논문 수식 중 일부를 log로 바꾼 것이다.
- div_term 은 어떻게 보면 상수에 해당하는 부분이다.
- Shape은 4( =int( hid_dim / 2) )가 나온다.
- numerical overflow 방지를 위해 로그 공간(log space)에서 연산하
- 그래서 처음에 코드가 직관적이지는 않다. (참고: wandb 트랜스포머 심층분석)
# 4)
div_term = torch.exp( _2i * (-torch.log( torch.Tensor([10000.0]) ) / hid_dim ))
# 논문 수식을 그대로 쓰자면, 다음과 같이 표현이 가능하다.
# div_term = 1 / (10000 ** (_2i / hid_dim))
div_term # Shape: [ int(hid_dim / 2) ]
그리고 혹시라도 수학적인 이해가 필요하다면 참고하기를 (노션처럼 접는 거 없나....)
-
아래 수식 풀이에서 log는 밑이 자연상수 e인 log이다.
-
원래 ln으로 쓰는 것이 맞다. (가끔 기억을 못 하시는 분들도 계셔서 일단 log로 작성)
-
torch에서 torch.log 또한 밑이 자연상수 e인 log이다. (참고)
-
수식풀이 보려면 펼쳐보고 다 보면 접기
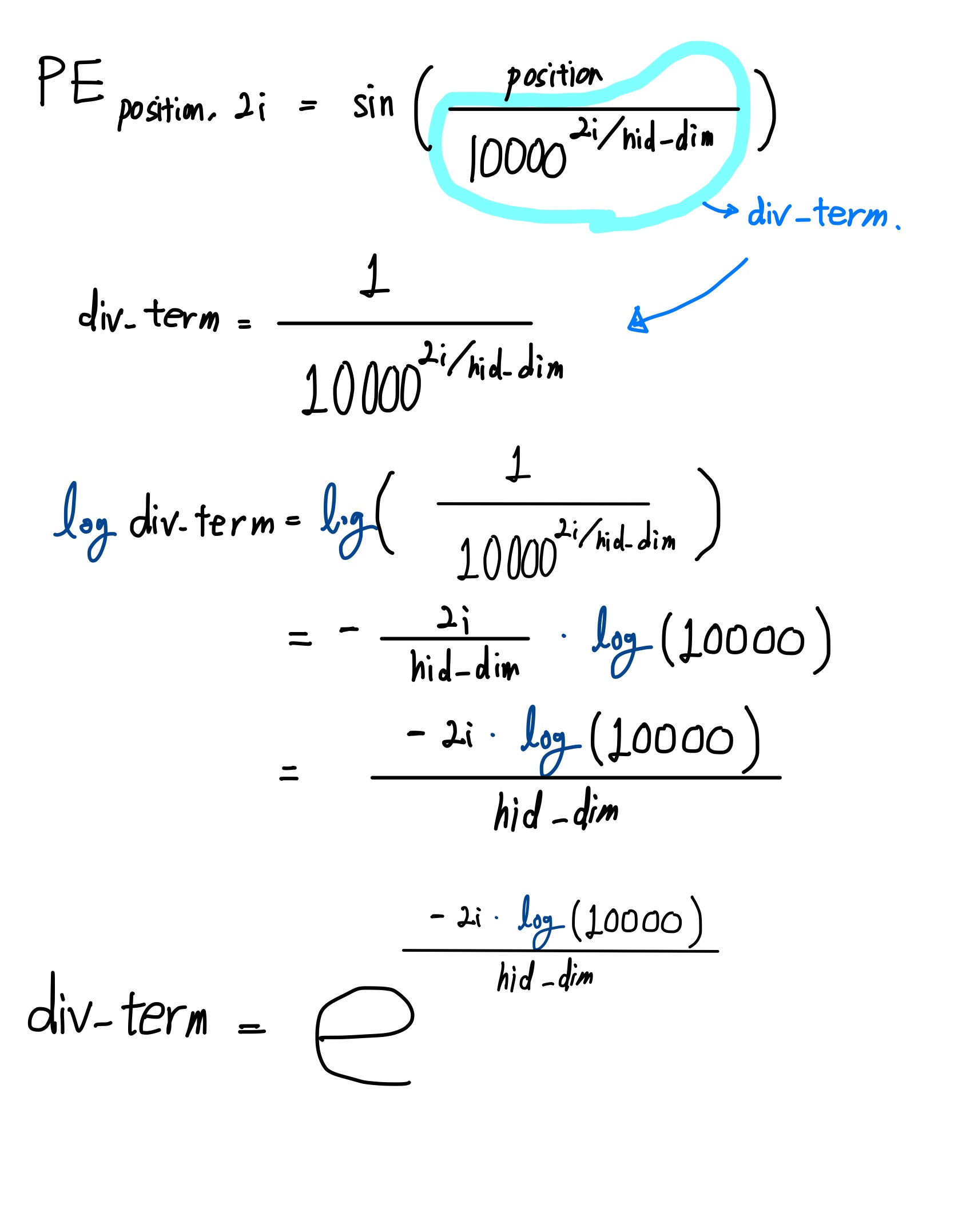
-
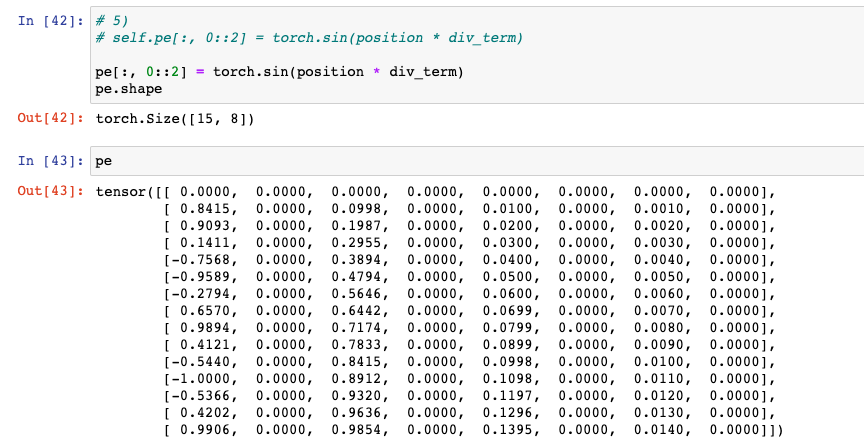
5) self.pe[:, 0::2] = torch.sin(position * div_term)
: pe 중에서 hid_dim 차원에 위치 정보를 넣어주는 때이다. index 기준으로 0부터 시작하여 2칸씩 건너뛰어 위치정보( torch.sin(position * div_term) )를 넣어준다. 수식으로 표현하자면 다음과 같다.
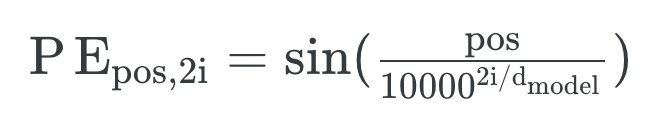
# 5)
# self.pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 0::2] = torch.sin(position * div_term)
pe.shape자세히 보면, index 기준으로 0, 2, 4, 6에 해당하는 부분에만 실수값이 존재한다.
- 첫 줄에는 모두 0인데, 이는 sin(0) = 0 이기때문.
- 직접 계산하여보자.
6) self.pe[:, 1::2] = torch.cos(position * div_term)
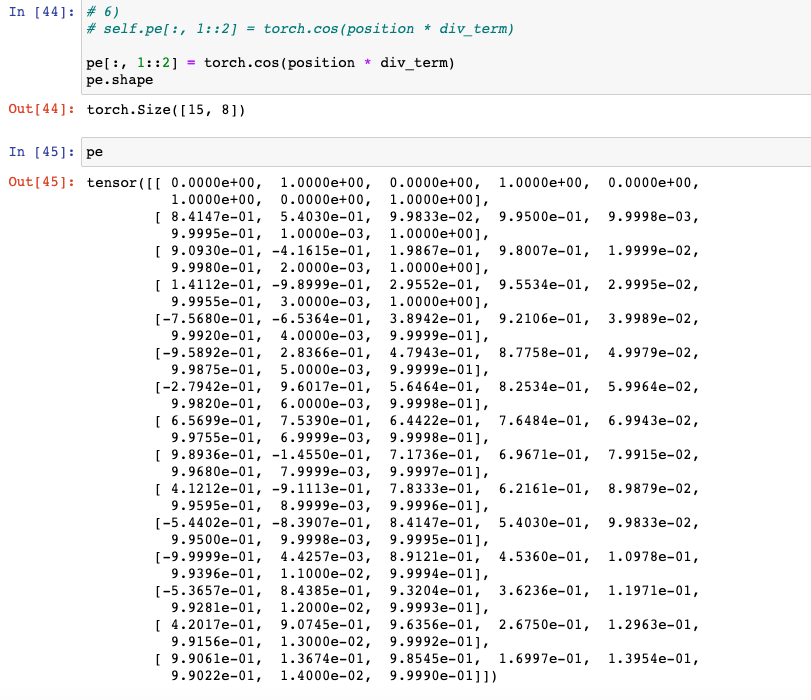
: 이번엔 pe에서 hid_dim 차원 중 index 기준으로 1부터 시작하여 2칸씩 건너뛰어서 위치정보( torch.cos(position * div_term) )를 넣어준다. 수식으로 표현하자면 다음과 같다.
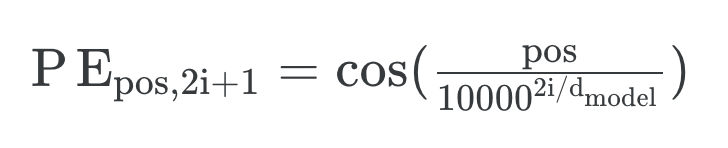
# 6)
# self.pe[:, 1::2] = torch.cos(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe.shape자세히 보면, 이제 index 기준으로 1, 3, 5, 7에 해당하는 부분에도 실수값이 존재한다.
- 직접 계산하여보자.
7) self.pe = self.pe.unsqueeze(0).to(device)
: 현재 pe의 shape은 [max_len, hid_dim]이다. 배치 차원의 정보를 주어서 [1, max_len, hid_dim] 로 만들어주고 GPU로 보내준다.
# 7)
pe = pe.unsqueeze(0).to(device)
pe.shape
8) register_buffer
: 매개 변수로 간주되지 않는 버퍼를 등록하는 데 사용된다. 다음과 같은 특징이 있다고 한다. (출처:https://dongdong93.tistory.com/22)
- optimizer가 update하지 않는다.
- state_dict에는 저장된다.
- GPU에서 작동한다.
# 8)
self.register_buffer('pes', pe)9) forward
: 생성자 함수에서 선언한 레이어들을 실제로 엮는 부분이다. 위치 정보를 주는 self.pe에 대해서 이미 완성이 되어있기 때문에 이 부분에서는 쉽다. 설명은 아래 코드에서 주석으로 대신한다.
# 9)
print(out1.shape)
# out1: Embed를 지났기 때문에 [bs, max_len, hid_dim] Shape
out3 = out1 + torch.Tensor(pe[:, :out1.shape[1]]).requires_grad_(False)
# pe[:, :out1.shape[1]] : out1의 sl은 10인데 이에 맞출 수 있도록 indexing
# .requires_grad_(False): 위치정보를 주는 부분은 학습되지 않도록 하기 위함이다.
# 그래서 이렇게 코드를 작성할 수도 있다. (출처: wandb 트랜스포머 심층 분석)
# out3 = out1 + Variable(pe[:, :out1.shape[1]], requires_grad = False)
## 사싱 위의 코드와 같은 코드이다. Variable 잘 안 쓴다는 글을 어디에서인가 보고 찾은 코드이다.
out3.shape
당연하지만, Broadcasting 된다.
: 위의 예저에서는 배치사이즈가 1이기 때문에 당연히 연산이 되지만, 2 이상의 수가 되면 계산이 안 되는 것으로 가끔 착각하신 분들이 계셨다. 짧은 기간동안, ML, DL을 공부하면서 있을 수 있다고 생각한다. Tensor 개념으로 넘어오면서 이에 대해서 혼동이 오는 분들이 계실 수 있기에 설명한다.
- BroadCasting이 되기 때문에 연산이 된다!
# 9)
# Batch Size가 3이라면?
x_ = torch.randn(3, 10, 8).to(device)
out3 = x_ + torch.Tensor(pe[:, :x_.shape[1]]).requires_grad_(False)
out3.shape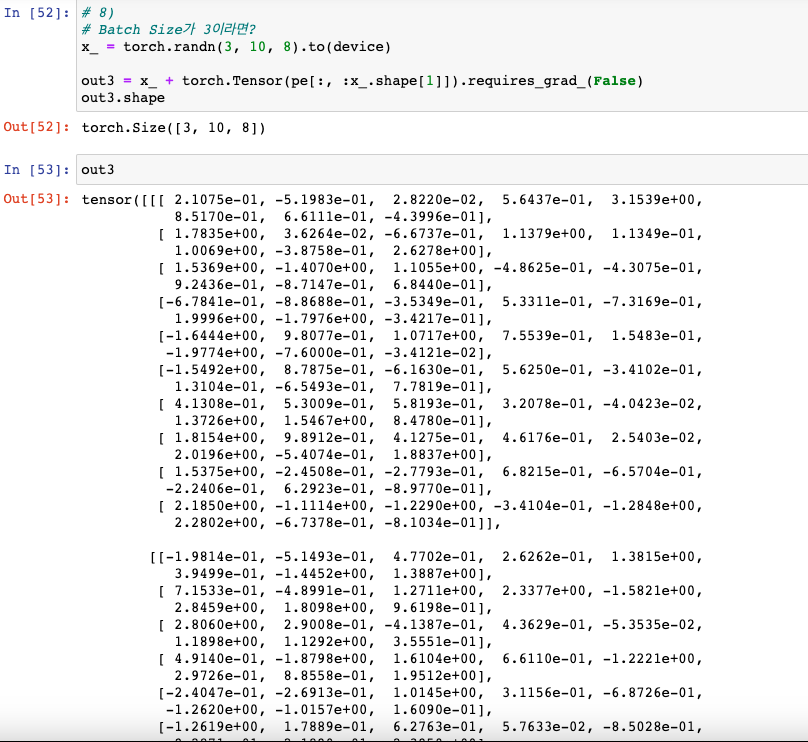
Positional Encoding Layer 완료
긴 글을 읽어주느라 고맙습니다!
