
여러 페이지네이션들
기획이나 디자인 단의 이유로 반드시 페이지 기반 (전통적인 Limit, Offset기반 페이지네이션)을 사용해야 되는 경우가 아니라면 커서 기반의 페이지네이션을 추천한다. 앞의 row들을 조회하는 경우에는 성능차이가 크지 않지만, 그렇지 않을 경우 매우 큰 성능 차이가 발생하게 된다. 하지만 이 글은 그럼에도 불구하고 전통적인 페이지네이션을 사용해야하는 이들을 위한 글이다.
Page 기반의 페이지네이션
페이지 기반의 페이지네이션의 경우 대략 다음과 같은 Url을 가지게 될 것이다.
https://api.heka1024.com/boards/free/posts/?page=12이 때 날라가는 SQL은 대략 다음과 같이 될 것이다.
select *
from board_post p
where p.board_id = 1
and p.is_deleted = false
order by p.issued_date desc
limit 20 offset 50000;이 때 Offset이 커지면 커질수록 아주 느리게 된다. 왜 그럴까?
바로 데이터 블록에 접근한 후에 그 Row들을 버리기 때문이다. 따라서 데이터블록에 접근하는 것을 최소화한다면 성능 개선을 꾀할 수 있다. 인덱스가 걸린 것들만 select 해 오면 되는 것이다. 이렇게 select 하는 것들까지 모두 들어가 있는 Index를 Covering Index라 부르고, 이 커버링 인덱스를 이용하는 스캔을 Index Only Scan이라 부른다.
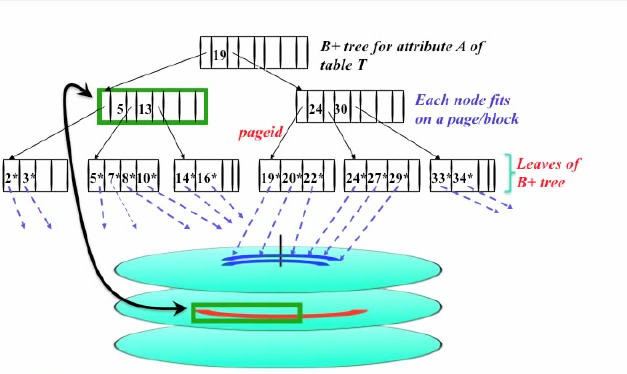
Index Only Scan
PostgreSQL에서 인덱스는 테이블의 heap이라 불리는 주 데이터 저장소와 다른 곳에 저장된다. 인덱스와 달리 데이터는 힙의 아무 곳에나 있을 수 있기 때문에 주 데이터 저장소를 접근하는 것은 매우 느리다. 비트맵 스캔 등으로 최적화를 하려고 한다고 해도 말이다.
이 문제를 해결하기 위해 PostgreSQL은 힙 접근 없이 인덱스에서만 필요한 정보를 가져오는 Index Only Scan을 지원한다. (대략 9.2버전부터 지원하는 것 같다)
예시와 함께 살펴보자. tab이라는 테이블이 x, y, z라는 칼럼을 가지고 있고 x, y에는 인덱스가 걸려있다고 해보자. 그렇다면 다음과 같은 쿼리는 Index Only Scan`이다.
SELECT x, y FROM tab WHERE x = 'key';
SELECT x FROM tab WHERE x = 'key' AND y < 42;다음과 같은 쿼리는 그렇지 못하다.
SELECT x, z FROM tab WHERE x = 'key';
SELECT x FROM tab WHERE x = 'key' AND z < 42;물론 단순히 index를 건다고 되는 것은 아니고, 좀 더 복잡한 규칙이 있으나 대부분의 경우는 문제가 없다. 또한 인덱스 타입에 따라서도 달라진다. B-Tree는 언제나 가능하고,GiST and SP-GiST는 어떤 연산을 이용하냐에 따라 달라지고 다른 종류의 인덱스는 지원하지 않는다. 자세한 건 참고문헌의 공식 문서를 참고하자.
이 때 where절에 사용되지 않지만 단순히 Index only scan을 위해 특정 칼럼들을 인덱스에 놓고 싶을 수 있다.
아래와 같은 경우 x가 탐색의 조건으로 사용되었고, y를 읽어들이고 있다. 단순히 생각하면 y에도 인덱스를 걸면 된다. 하지만 y가 검색의 조건으로 사용되지 않는다는 점에서는 비효율적이다.
SELECT y FROM tab WHERE x = 'key';그래서 PostgreSQL에서는 다음과 같이 include 키워드를 이용해서 인덱스를 생성하면 된다.
CREATE INDEX tab_x_y ON tab(x) INCLUDE (y);페이지네이션 성능 개선
그럼 위 covering index를 이용해서 어떻게 페이지네이션 성능을 개선할 수 있는가? 바로 limit offset과정을 빠르게 진행함으로써 성능을 올릴 수 있다.
select a.*
from board_post a
order by a.id
offset 400000 limit 100;위와 같은 쿼리를
select p.id
from board_post p
join (
select pp.id
from board_post pp
limit 100 offset 400000
) as tmp on tmp.id = p.id;위와 같은 쿼리로 바꿈으로서 성능 향상을 꾀할 수 있다.
첫 쿼리의 경우
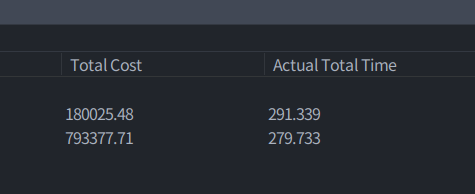
위와 같은 비용 / 시간이 들지만 두번째 (커버링 인덱스)의 경우
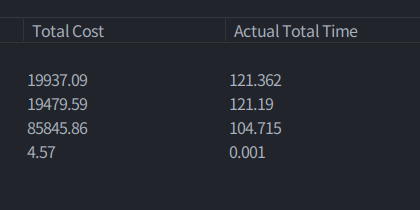
시간과 비용이 훨씬 줄어든 것을 확인할 수 있다.
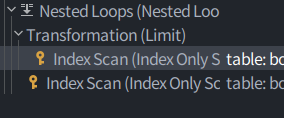
또한 Index Only Scan이라고 Explain되는 것이 보인다.
다음 글에서는 실제 Django의 ORM 상에서 위 개념을 어떻게 구현하여 속도 향상을 꾀할지 살펴보자.
참고문헌
