
이 글의 예제코드는 Github에서 확인할 수 있습니다.
앞선 글에서 SQL 단에서 어떻게 해야 페이징 성능이 개선될지를 확인했다. 그러면 이것을 어떻게 장고로 잘 번역할 것인가? 그에 앞서 간단히 테스팅 환경을 준비해보자.
모델링
# post/models.py
from django.db import models
from enumfields import EnumField
class Post(TimeMixin, models.Model):
title = models.CharField(max_length=25)
content = models.TextField()
status = EnumField(Status, default=Status.DRAFT)
class Meta:
ordering = ["-id"]위와 같은 파일을 준비하자. 테스트를 원활히 하기 위해 테이블에 미리 데이터를 적재해두자. 테스트의 용이성을 위하여 factory_boy를 이용하였다.
# post/factories.py
_tokens = """텍스트...""".split()
def _words(n: int):
random_words = [choice(_tokens) for _ in range(n)]
return LazyFunction(lambda: " ".join(random_words))
class PostFactory(DjangoModelFactory):
class Meta:
model = Post
title = _words(4)
content = _words(1000)
status = LazyFunction(Status.random)그리고 아래 커맨드를 만들어서 DB를 준비했다.
class Command(BaseCommand):
def handle(self, *args, **options):
size = 2000
for i in range(size):
print(i, "/", size)
posts = PostFactory.build_batch(1000)
Post.objects.bulk_create(posts)쿼리 작성 및 성능 확인
그러면 이제 실제 ORM을 이용해 쿼리를 짜보자.
# post/models.py
class PostQuerySet(models.QuerySet):
def paginated(self, page: int, page_size: int = 20):
"""단순한 페이지네이션 구현"""
limit = (page - 1) * page_size
return self[limit : limit + page_size]
def paginated_v2(self, page: int, page_size: int = 20):
"""커버링 인덱스를 이용"""
index_only_scan = self.paginated(page, page_size)
return self.filter(id__in=index_only_scan)
class Post(TimeMixin, models.Model):
# ...
objects = PostQuerySet.as_manager()
class Meta:
ordering = ["-id"]위와 같이 구현해볼 수 있다. paginated의 경우 단순한 구현, 그리고 v2의 경우 인덱스 온리 스캔을 이용한 구현이다. Django에서 join절에 조건을 사용할 수 없기 때문에 위와 같이 in을 이용해서 구현했다. 실제 성능은 얼마나 차이가 날까? DB에 약 200만개 정도의 row를 적재한 상태로 실험을 진행했다.
Post.objects.paginated(100000)위 문장은 아래와 같이 번역된다.
SELECT "post_post"."id",
"post_post"."created_at",
"post_post"."updated_at",
"post_post"."title",
"post_post"."content",
"post_post"."status"
FROM "post_post"
ORDER BY "post_post"."id" DESC
LIMIT 20 OFFSET 1999980;
390ms 정도가 걸렸다.
이제 커버링 인덱스를 살펴보자.
Post.objects.paginated_v2(100000)Django는 위 구문을 아래와 같이 변환한다.
SELECT "post_post"."id",
"post_post"."created_at",
"post_post"."updated_at",
"post_post"."title",
"post_post"."content",
"post_post"."status"
FROM "post_post"
WHERE "post_post"."id" IN
(SELECT "post_post"."id" FROM "post_post"
ORDER BY "post_post"."id" DESC LIMIT 20 OFFSET 1999980)
ORDER BY "post_post"."id" DESC
LIMIT 21;explain한 결과는 다음과 같다.
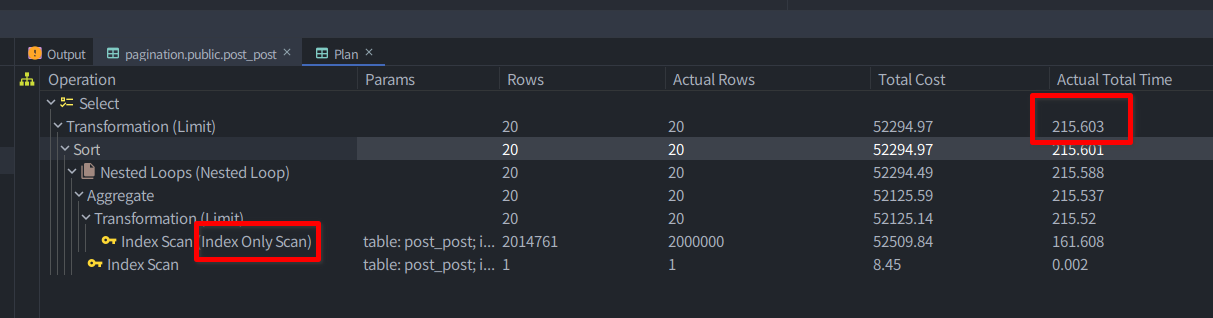
215ms정도가 걸렷다. 또한 가장 안쪽에서 Index only scan을 타는 것을 볼 수 있다.
SELECT "post_post"."id"
FROM "post_post"
ORDER BY "post_post"."id" DESC
LIMIT 20 OFFSET 1999980;안쪽에 있는 이 구문인데, order_by와 select절에 사용되는 id에 인덱스가 걸려있으므로 당연한 결과이다. DB에 200만개밖에 없어서 1.8배 정도의 차이가 난 것이고 더 많은 row가 있으면 있을수록 성능 차이는 커질 것이다.
테이블에 여러 칼럼이 생길수록, 또 칼럼 하나하나의 길이가 길어질수록, 디스크의 성능이 나쁠수록 이 차이는 더욱 커지게 된다. 메모리와 디스크 사이의 차이 속도 차이가 근본적인 성능 차이를 불러오기 때문이다.
단순한 구현과 커버링 인덱스를 사용한 경우의 성능 차이는 매우 크다. 커서 기반의 페이지네이션을 사용할 수 없으며 DB에 많은 양의 row가 있는 경우 꼭 커버링 인덱스를 활용하여 페이지네이션 성능을 개선해보자.
참고 문헌

정말 유익해요