
ArrayField?
PostgreSQL은 다양한 형태의 필드를 지원한다. 특히 편리한 기능 중 하나는 ArrayField를 지원한다는 것이다. Django는 이러한 형태의 필드를 지원한다. 다음과 같이 사용하면 된다.
# board/models.py
from django.contrib.postgres.fields import ArrayField
from django.db import models
class Post(models.Model):
title = models.CharField(max_length=50)
content = models.TextField(blank=True)
tags = ArrayField(models.CharField(max_length=20), blank=True)
def __str__(self):
return f"Post({self.id}, {self.title})"위 구문에서 tags = ArrayField(models.CharField(max_length=20), blank=True)이 ArrayField의 선언이다. 실제 DDL을 확인해보면 다음과 같다.
create table board_post
(
id bigserial primary key,
title varchar(50) not null,
content text not null,
tags varchar(20)[] not null
);사용법
간단히 사용례를 테스트코드와 함꼐 살펴보면 다음과 같다.
# tests/board/models/test_post.py
from django.test import TestCase
from board.models import Post
class PostTest(TestCase):
def test_생성시에_태그를_넣을수있다(self):
post = Post.objects.create(title="title", content="content", tags=["a", "b"])
assert Post.objects.count() == 1
assert post.tags == ["a", "b"]
def test_태그로_필터를_할_수_있다(self):
Post.objects.create(title="title", content="content", tags=["a", "b", "c"])
Post.objects.create(title="title", content="content", tags=["a", "b"])
Post.objects.create(title="title", content="content", tags=["a"])
assert Post.objects.count() == 3
assert Post.objects.filter(tags__contains=["a"]).count() == 3
assert Post.objects.filter(tags__contains=["b"]).count() == 2
assert Post.objects.filter(tags__contains=["c"]).count() == 1
def test_태그의_길이를_알_수_있다(self):
Post.objects.create(title="title", content="content", tags=["a", "b", "c"])
Post.objects.create(title="title", content="content", tags=["a", "b"])
Post.objects.create(title="title", content="content", tags=["a", "c"])
Post.objects.create(title="title", content="content", tags=["a"])
qs = Post.objects.filter(tags__len=2)
assert qs.count() == 2- 생성 및 쿼리
- 태그 기반 필터 (
contains) - 태그 길이 기반 필터 (
<name>__len)
에 대한 학습 테스트 케이스다. 위와 같이 작성하면 내용 이해에는 문제가 없을 것이다.
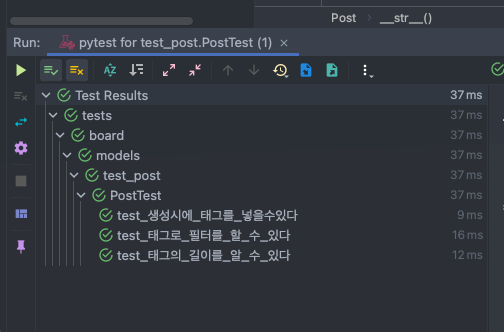
세 가지 경우 모두 잘 실행되는 것을 확인할 수 있다.
인덱싱
팩토리 선언
아무리 표현력이 좋아도 성능이 안 좋으면 쓸 수가 없다. 기존 원시 데이터 타입의 경우는 B-Tree같은 일반적인 인덱싱을 통해 성능 문제를 해결했다. 그렇다면, ArrayField는 어떻게 인덱싱을 해야할까? 우선 성능 검증을 위해 실험을 준비해보자.
# tests/board/factories.py
import random
import faker
from factory import Faker, LazyFunction
from factory.django import DjangoModelFactory
from board.models import Post
def _random_tags():
_faker = faker.Faker()
return _faker.words(nb=random.randrange(1, 10), unique=True)
class PostFactory(DjangoModelFactory):
class Meta:
model = Post
title = Faker('text', max_nb_chars=20)
content = Faker('text', max_nb_chars=100)
tags = LazyFunction(_random_tags)위와 같이 Factory를 만들자.
def _random_tags():
_faker = faker.Faker()
return _faker.words(nb=random.randrange(1, 10), unique=True) 이렇게 _random_tags를 분리하지 않으면 한번의 create_batch에서 같은 길이의 배열들만 생성이 된다. nb에 random.randrange(1, 10)등을 넘겨줄 경우에는 그 시점에 평가가 일어나 결국 Faker('words', nb=5와 같은 구문이 전달되어 버리기 때문이다. 따라서 함수를 만들어 LazyFunction으로 감싸 주어야 한다.
하지만 대량의 Post를 만들 때는 위 구문이 심각하게 느려서
class PostFactory(DjangoModelFactory):
class Meta:
model = Post
title = Faker('text', max_nb_chars=20)
content = Faker('text', max_nb_chars=100)
tags = Faker('words', nb=random.randrange(1, 10), unique=True)위와 같은 간단한 구현으로 다시 돌아갔다.
TC 다시쓰기
이왕 팩토리를 만들었으니 테스트코드도 리팩토링을 해 보자.
# tests/board/models/test_post.py
from django.test import TestCase
from board.models import Post
from tests.board.factories import PostFactory
class PostTest(TestCase):
def test_생성시에_태그를_넣을수있다(self):
post = PostFactory.create(tags=["a", "b"])
assert Post.objects.count() == 1
assert post.tags == ["a", "b"]
def test_태그로_필터를_할_수_있다(self):
PostFactory.create(tags=["a", "b", "c"])
PostFactory.create(tags=["a", "b"])
PostFactory.create(tags=["a"])
assert Post.objects.filter(tags__contains=["a"]).count() == 3
assert Post.objects.filter(tags__contains=["b"]).count() == 2
assert Post.objects.filter(tags__contains=["c"]).count() == 1
def test_태그의_길이를_알_수_있다(self):
PostFactory.create(tags=["a", "b", "c"])
PostFactory.create(tags=["a", "b"])
PostFactory.create(tags=["a", "c"])
PostFactory.create(tags=["a"])
qs = Post.objects.filter(tags__len=2)
assert qs.count() == 2기존 코드의 경우 Post의 선언에서 title이나 content같이 부수적인 정보들이 들어있어서 초점을 흐렸다. 하지만 이제 진짜 보고 싶은 부분인 tags에만 선언부가 집중되므로 훨씬 읽기 좋은 테스트코드가 되었다.
DB seeds
다시 실험으로 돌아와서, 100만개 정도의 row를 준비해보자.
# board/management/commands/seed_post.py
from django.core.management import BaseCommand
from board.models import Post
from tests.board.factories import PostFactory
class Command(BaseCommand):
help = "100만개의 Post 준비"
def handle(self, *args, **options):
for _ in range(1000):
ps = PostFactory.build_batch(1000)
Post.objects.bulk_create(ps)위와 같은 커맨드를 준비하고, python manage.py seed_post와 같이 실행해서 실험을 준비할 수 있다.
그런데 왜 굳이 build_batch와 bulk_create를 나누어서 실행했을까? 바로 create_batch가 비효율적으로 실행되기 때문이다.
build_batch의 경우 내부 구현은 다음과 같다.
@classmethod
def create_batch(cls, size, **kwargs):
"""Create a batch of instances of the given class, with overridden attrs.
Args:
size (int): the number of instances to create
Returns:
object list: the created instances """
return [cls.create(**kwargs) for _ in range(size)]위와 같이 단순히 create를 여러 번 호출하는 것임을 알 수 있다.
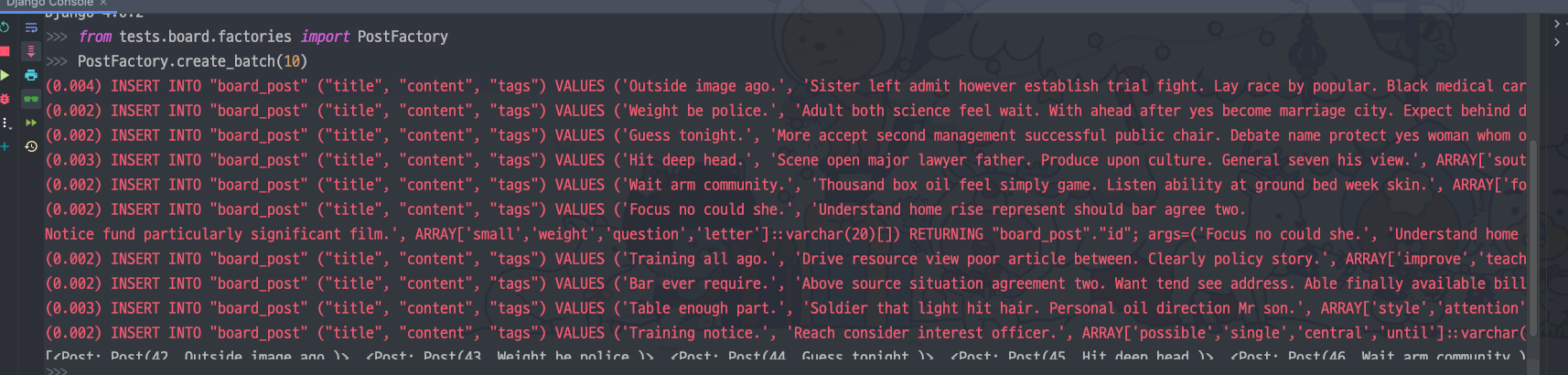
실제로 위와 같이 PostFactory.create_batch(10)을 실행하면 insert 구문이 10번 찍히는 걸 볼 수 있다. 따라서 build를 통해 객체의 어레이를 만들고, bulk_create를 하는 것이 효율적임을 알 수 있다.
실제 인덱싱
구현
class Post(models.Model):
# ...
class Meta:
indexes = [
GinIndex(fields=["tags"]),
]GinIndex를 추가하자. ArrayField의 경우 GinIndex를 추가해야 한다. 공식문서에서는 이러한 설계를 권장하지는 않는다.
Arrays are not sets
searching for specific array elements can be a sign of database misdesign.
Consider using a separate table with a row for each item that would be an array element.
This will be easier to search, and is likely to scale better for a large number of elements.
하지만 현실적인 이유로 ArrayField + Index를 사용해야하는 경우가 있다. 어쨌든 인덱싱을 해보자. 실제 운영중인 DB의 경우 인덱스로 인해 락을 잡는게 무리인 경우가 있다. 그런 경우 마이그레이션 파일을 다음과 같이 고치자.
import django.contrib.postgres.indexes
from django.contrib.postgres.operations import AddIndexConcurrently
from django.db import migrations
class Migration(migrations.Migration):
atomic = False
dependencies = [
('board', '0004_alter_post_tags'),
]
operations = [
AddIndexConcurrently(
model_name='post',
index=django.contrib.postgres.indexes.GinIndex(fields=['tags'], name='board_post_tags_59756a_gin'),
),
]평소와 달라진 점은 atomic = False와 migrations.AddIndex 대신 AddIndexConcurrently를 사용했다는 것이다. 평소보다 인덱스 생성에 걸리는 시간이 길지만 실제 운용시에는 훨씬 유용하다.
실험에는 다음과 같은 구문을 이용했다.
SELECT "board_post"."id", "board_post"."title", "board_post"."content", "board_post"."tags"
FROM "board_post"
WHERE "board_post"."tags" @> (ARRAY ['site', 'perform'])::varchar(20)[]
LIMIT 21;Before

풀 스캔을 돈다.
After

인덱스를 잘 활용하는 것을 볼 수 있다.
하단 표에 정리해두었다. 인덱스를 두는 쪽이 확실히 성능이 뛰어난 것을 볼 수 있다.
| ~Index | Index | |
|---|---|---|
| 걸린 시간(ms) | 130.818 | 0.904 |
| 비용 | 41299.93 | 95.27 |
인터페이스 노출하기
위와 같이 실제 인덱싱까지 살펴보았다. 하지만 실제로 위 코드를 프로덕션에서 쓰기에는 부족함이 있다. 바로 추상화이다. 위 ArrayField를 사용하려면 실제 구현에 대해 너무 많이 알아야 하기 때문이다. 가령, 태그를 더하고 빼는 과정을 생각해보자. ``
메소드 만들기
class Post(models.Model):
title = models.CharField(max_length=50)
content = models.TextField(blank=True)
tags = ArrayField(models.CharField(max_length=20), blank=True)
def has_tag(self, tag: str):
return tag in self.tags
def add_tag(self, tag: str):
if self.has_tag(tag):
return
self.tags.append(tag)
self.save(update_fields=["tags"])
return self.tags
def remove_tag(self, tag: str):
if not self.has_tag(tag):
return
self.tags.remove(tag)
self.save(update_fields=["tags"])
return self.tags
def __str__(self):
return f"Post({self.id}, {self.title})"위와 같이 has_tag, add_tag, remove_tag 세 개의 메소드로 setter를 대신할 수 있다. 이제 좀 더 의미있는 이름과 안정적인 인터페이스를 제공하게 된 것이다. 이제 극단적으로 내부에서 ArraryField대신 구분자와 CharField를 사용해도 문제가 되지 않는다.
다음과 같이 TC로 검증해보자.
from django.test import TestCase
from tests.board.factories import PostFactory
class PostTagTest(TestCase):
@classmethod
def setUpTestData(cls):
cls.post = PostFactory.create(tags=["a", "b"])
def test_태그가_있는지_검사할수있다(self):
assert self.post.has_tag("a")
assert not self.post.has_tag("nono")
def test_태그를_추가할_수_있다(self):
self.post.add_tag("word")
assert self.post.tags == ["a", "b", "word"]
def test_태그를_삭제할_수_있다(self):
self.post.remove_tag("a")
assert self.post.tags == ["b"]클래스 도입
하지만 위와 같이 쓰다보면 의문이 생긴다. 정말 이게 다 Post의 책임일까? 맞는 거 같기도 하고... 아닌 거 같기도 하다. 만약 Post가 아니라면, 누가 책임을 져야 하나? 바로 Tag 자신이 지면 되지 않을까? 다음과 같이 작성해보자.
class Tags:
def __init__(self, tags: List[str], post: "Post"):
self.tags = set(tags)
self._post = post
@property
def set(self) -> Set[str]:
return self.tags
def contains(self, tag: str):
return tag in self.tags
def add(self, tag: str):
self.tags.add(tag)
self._commit()
def remove(self, tag: str):
if not self.contains(tag):
return
self.tags.remove(tag)
self._commit()
def _commit(self):
self._post._tags = list(self.tags)
self._post.save(update_fields=["_tags"])위와 같이 파이썬 객체를 하나 만들어보자. 영속성과 관련된 부분은 프라이빗 필드 post와 _commit에서만 알고 있다. 그리고 Post 본문은 아래와 같이 고쳐보자.
class Post(models.Model):
title = models.CharField(max_length=50)
content = models.TextField(blank=True)
_tags = ArrayField(models.CharField(max_length=20), blank=True, db_column="tags")
_tag = None
@property
def tags(self):
self._tag = self._tag or Tags(self._tags, self)
return self._tag필드가 변경되었기 때문에 migrate를 해줘야 한다. DB에는 변화가 없다. 실제로는 파이썬 객체의 변경일 뿐이기 때문이다. 이제 다음과 같이 좀 더 유창하게 사용할 수 있다.
from django.test import TestCase
from tests.board.factories import PostFactory
class PostTagTest(TestCase):
@classmethod
def setUpTestData(cls):
cls.post = PostFactory.create(tags=["a", "b"])
def test_태그가_있는지_검사할수있다(self):
assert self.post.tags.contains("a")
assert not self.post.tags.contains("nono")
def test_태그를_추가할_수_있다(self):
self.post.tags.add("word")
assert self.post.tags.set == {"a", "b", "word"}
def test_태그를_삭제할_수_있다(self):
self.post.tags.remove("a")
assert self.post.tags.set == {"b"}그런데, 사실 생각해보니 위 과정은 필드를 커스텀한 게 아닐뿐인가 하는 의문이 든다. 실제로 그렇다. 아예 명시적으로 위 과정을 Field로 만들어버리자.
필드로 만들기
from typing import Set, List
from django.contrib.postgres.fields import ArrayField
class Tags:
def __init__(self, tags: List[str]):
self.tags = set(tags)
@property
def set(self) -> Set[str]:
return self.tags
def contains(self, tag: str):
return tag in self.tags
def add(self, tag: str):
self.tags.add(tag)
def remove(self, tag: str):
if not self.contains(tag):
return
self.tags.remove(tag)
class TagField(ArrayField):
def from_db_value(self, value, expression, connection):
if value is None:
return None
return Tags(value)
def to_python(self, value):
if isinstance(value, Tags):
return value
if value is None:
return Tags([])
return Tags(value)
def get_db_prep_value(self, value, connection, prepared=False):
if isinstance(value, Tags):
return list(value.set)
return value위와 같이 쓰면 아예 새로운 Field로 만들어버릴 수 있다. 그리고 Tags도 영속성 관리에서 벗어나 순수한 파이썬 객체로 변했다. 하지만 이제 다시 명시적인 save의 책임을 가지게 된다. 아래와 같이 테스트케이스를 작성할 수 있다.
class PostTagTest(TestCase):
@classmethod
def setUpTestData(cls):
cls.post = PostFactory.create(tags=Tags(["a", "b"]))
def test_태그가_있는지_검사할수있다(self):
assert self.post.tags.contains("a")
assert not self.post.tags.contains("nono")
def test_태그를_추가할_수_있다(self):
self.post.tags.add("word")
self.post.save(update_fields=["tags"])
assert Post.objects.first().tags.set == {"a", "b", "word"}
def test_태그를_삭제할_수_있다(self):
self.post.tags.remove("a")
self.post.save(update_fields=["tags"])
assert self.post.tags.set == {"b"}결론
공식 문서에서 나왔듯 ArrayField는 좋지 못한 설계일 수 있다. 하지만 편리한 것도 사실이고 무책임한 말이지만 좋은 곳에 쓰면 좋다. 나쁜 점만 있다면, PostgreSQL이 지원할 이유가 없지 않겠는가. 기본적인 사용법과 인덱싱, 그리고 객체지향적인 설계에 대한 고민도 함께 해보았다. 설계는 보였던 세 개 (model의 메소드, 영속성 관리 책임을 갖는 클래스로 분리, CustomField) 중에 고민해보면 좋을 것이다. 각각 장단점이 있으며 물론 save를 직접 호출하는 것도 하나의 방법이 될 수 있다.


덕분에 많이 배우고 있습니다. 감사합니다:)