
주어진 테이블과 액세스 패턴
# board.rb
class Board < ApplicationRecord
ALL = "all".freeze
has_many :posts
end
create_table "boards", force: :cascade do |t|
t.string "name"
t.string "path"
t.string "description"
end# post.rb
class Post < ApplicationRecord
include Post::QueryMethods
belongs_to :user
belongs_to :board
default_scope { where(is_deleted: false).order(created_at: :desc) }
end
create_table "posts", force: :cascade do |t|
t.string "title"
t.string "content"
t.boolean "is_deleted", default: false
t.datetime "created_at", null: false
t.datetime "updated_at", null: false
t.bigint "board_id", null: false
t.bigint "user_id", null: false
t.index ["board_id"], name: "index_posts_on_board_id"
t.index ["user_id"], name: "index_posts_on_user_id"
end# user.rb
class User < ApplicationRecord
has_many :posts
end
create_table "users", force: :cascade do |t|
t.string "username"
t.string "nickname"
t.string "description"
t.datetime "created_at", null: false
t.datetime "updated_at", null: false
end# like.rb
class Like < ApplicationRecord
LIKE = "L".freeze
DISLIKE = "D".freeze
enum type: { like: LIKE, dislike: DISLIKE }
belongs_to :user
belongs_to :post
end
create_table "likes", force: :cascade do |t|
t.string "type", limit: 1, null: false
t.bigint "user_id", null: false
t.bigint "post_id", null: false
t.datetime "created_at", null: false
t.datetime "updated_at", null: false
t.index ["post_id"], name: "index_likes_on_post_id"
t.index ["user_id", "post_id"], name: "index_likes_on_user_id_and_post_id", unique: true
t.index ["user_id"], name: "index_likes_on_user_id"
end우선 주어진 테이블에 대해 다음과 같은 액세스 패턴이 있다고 해 보자.
- 게시판 하나에 대한 접근
- 모든 게시판에 대한 접근 (한 게시판만 제외해야함)
- HotArticle에 대한 접근 (통계 DB 이용)
초기 쿼리
우선 이 글에서는 1번 패턴, 주어진 게시판 하나에 대한 접근을 고려하도록 하자. 게시글 약 120만개에 대해 다음과 같은 쿼리가 발생한다.
EXPLAIN (ANALYSE, BUFFERS)
SELECT "posts".*,
"b".*,
"u".*,
(select count(*) from "likes" where "likes"."post_id" = "posts"."id" and type = 'L') as "likes"
FROM "posts"
JOIN boards b on b.id = posts.board_id
JOIN users u on u.id = posts.user_id
WHERE "posts"."is_deleted" = false
AND "posts"."board_id" = 13
ORDER BY "posts"."created_at" DESC
LIMIT 10 OFFSET 9990;위 쿼리의 실행계획을 확인해보자.
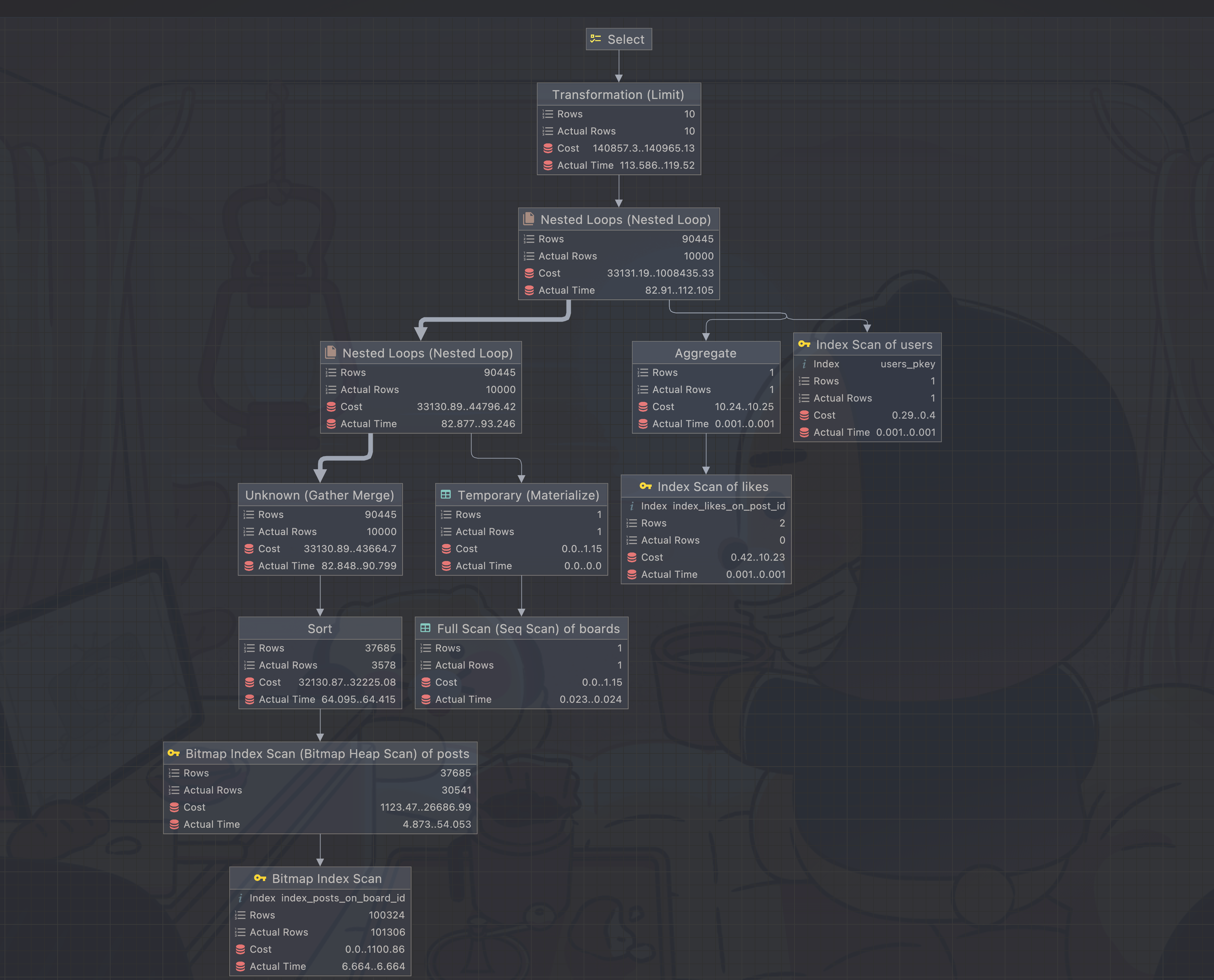
시각화한 실행계획은 위와 같다.

보면 대부분 인덱스를 타지만 그다지 효율적이지는 않은 모습이다. 대략 개선할 점은 세 가지 정도로 보인다.
1. limit, offtset 기반의 페이지네이션 전략 -> covering index를 활용한 페이지네이션
2. 조건절의 비효율적인 인덱스 -> 효율적인 인덱스 설계
3. likes 테이블의 비효율적인 count query -> 커버링 인덱스를 활용한 카운트
개선
이제 위 세 가지를 개선할 것이다. 우선 가장 간단해보이는 3번 부터 해결해보자.
Likes count 개선
위 복잡한 쿼리에서 likes 테이블 관련된 부분만 떼어내 보면 다음과 같다.
select count(*)
from "likes"
where "post_id" = 1001923
AND type = 'L';위 쿼리의 실행계획은 다음과 같다.
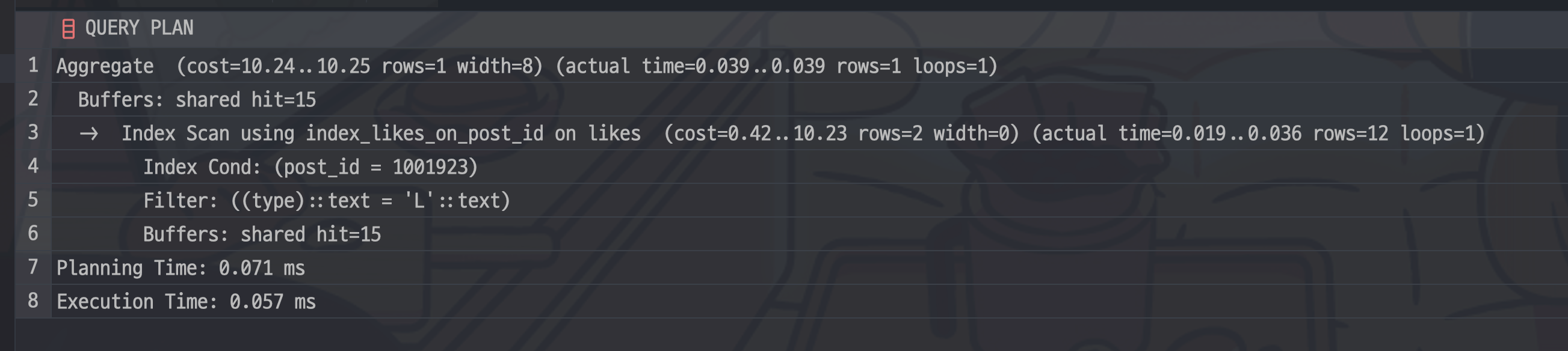
post_id인덱스를 이용해서 찾은 다음, type = 'L'을 이용해서 필터링을 한다. 두 조건을 동시에 이용하도록 인덱스를 설계하면 다음과 같다. 카디널리티가 post_id가 훨씬 높으므로 다음과 같이 설계하자.
CREATE INDEX "ix_likes_postid_type" ON "likes" ("post_id", "type");이제 새로운 인덱스가 생겼으니 vaccum을 한 번 돌려주자. 다음과 같이 하면 된다.
VACUUM ANALYZE "likes";앞으로는 vaccum 과정을 글에 적는 건 생략하겠다.
이제 새로운 인덱스가 생긴채로 똑같은 쿼리를 실행하면 다음과 같다.

새로 만든 인덱스 ix_likes_postid_type를 이용하며 cost도 50% 이상 감소한 것을 확인할 수 있다. 실행 시간은 0.057ms에서 0.036ms으로 줄어들었다. 간단한 인덱스 설계로 훨씬 효율적인 결과를 얻었다.
Limit, Offset 패턴 개선
위 패턴의 정확한 개선은 Django Pagination 성능 개선 - (1) SQL을 참고하자. 짧게 짚고 넘어가면 다음과 같다.
초기 쿼리의 explain 결과는 다음과 같다. 그런데, limit 10 offset 9990을 limit 10000으로 바꾸면 어떻게 될까?

하단은 limit 10000의 결과이다.

놀랍게도 아주 크게 다르지는 않다. 왜 이런 결과가 발생하는가? OFFSET은 단순히 읽어서 버리기 때문이다. 따라서 이 쿼리를 개선하기 위해서는 다음과 같이 두 과정으로 긴 쿼리를 쪼개야 한다.
- 인덱스 등을 활용하여 빠르게 where, order, limit-offset에 해당하는 pk를 읽어옴
- 1의 결과로 얻은 Pk를 이용해 힙에 접근해서 데이터를 읽어온다.
자세한 접근은 생략하고 이 튜닝 과정을 거쳐 나온 쿼리는 다음과 같다.
SELECT "posts".*,
"b".*,
"u".*,
(select count(*) from "likes" where "likes"."post_id" = "posts"."id" and type = 'L') as "likes"
FROM "posts"
JOIN boards b on b.id = posts.board_id
JOIN users u on u.id = posts.user_id
JOIN (
(SELECT "p"."id"
FROM "posts" p
WHERE "p"."is_deleted" = false
AND "p"."board_id" = 13
ORDER BY "p"."created_at" DESC
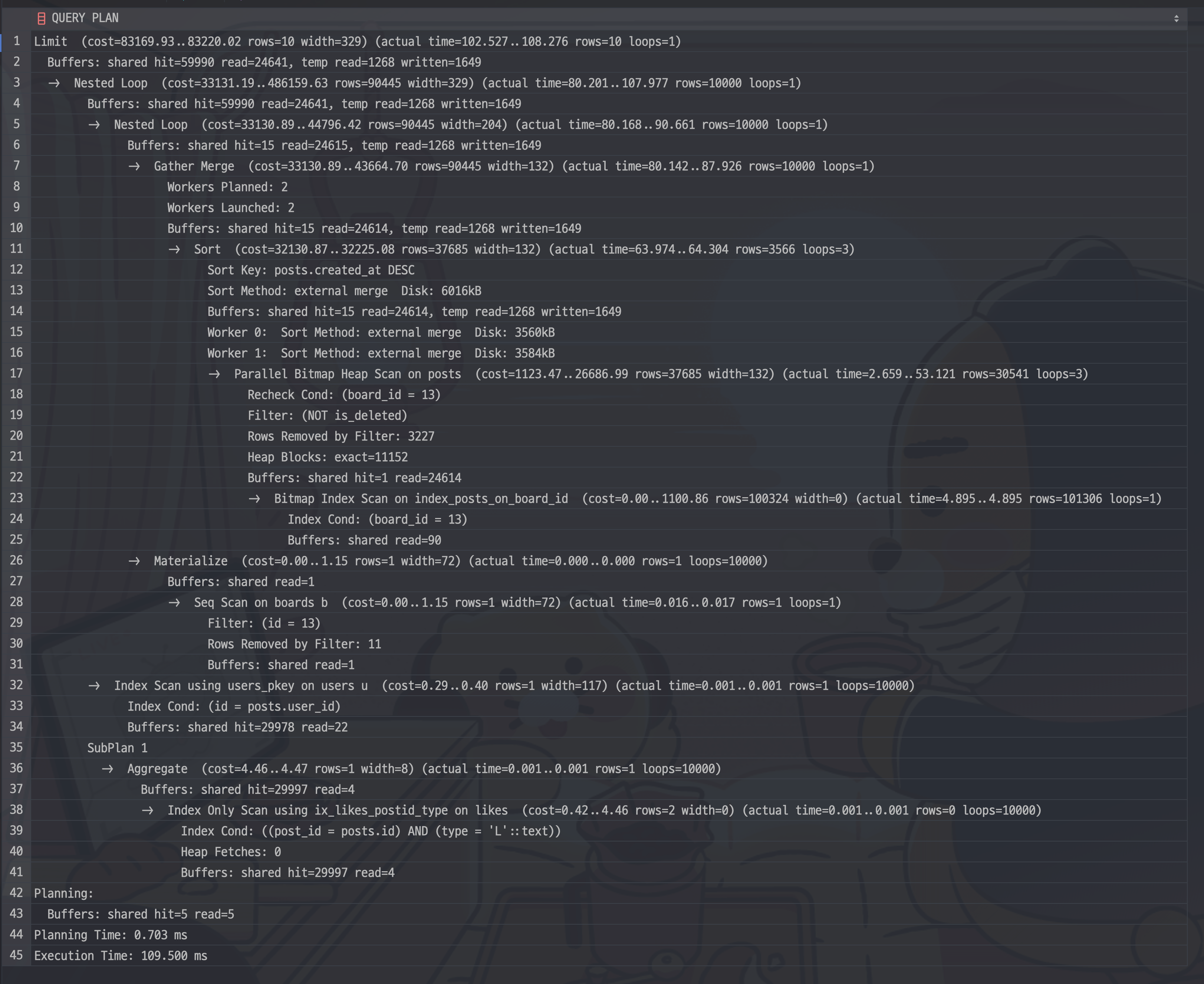
LIMIT 10 OFFSET 9990)) as "inner_posts" ON "inner_posts"."id" = "posts"."id";기존 쿼리의 실행계획과 비교해보자.
-
기존 쿼리의 실행계획
-
튜닝한 쿼리의 실행 계획
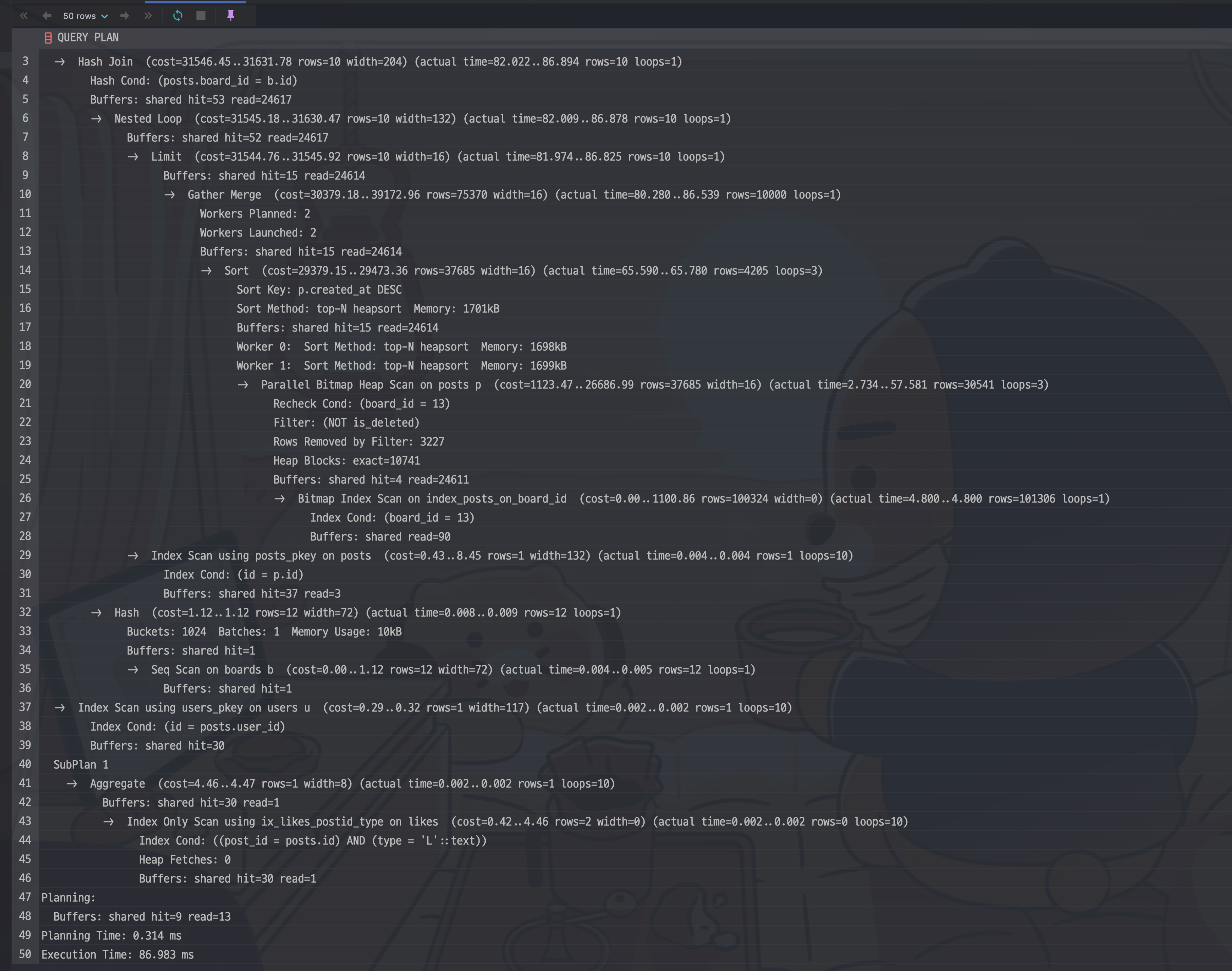
total cost가 확연히 차이나는 걸 확인할 수 있다.
내부 쿼리 최적화
위 과정에서 얻은 내부 쿼리를 인덱스를 이용해 좀 더 최적화해보자. 내부의 쿼리는 다음과 같다.
SELECT "p"."id"
FROM "posts" p
WHERE "p"."is_deleted" = false
AND "p"."board_id" = 13
ORDER BY "p"."created_at" DESC
LIMIT 10 OFFSET 9990;실행계획은 다음과 같다.
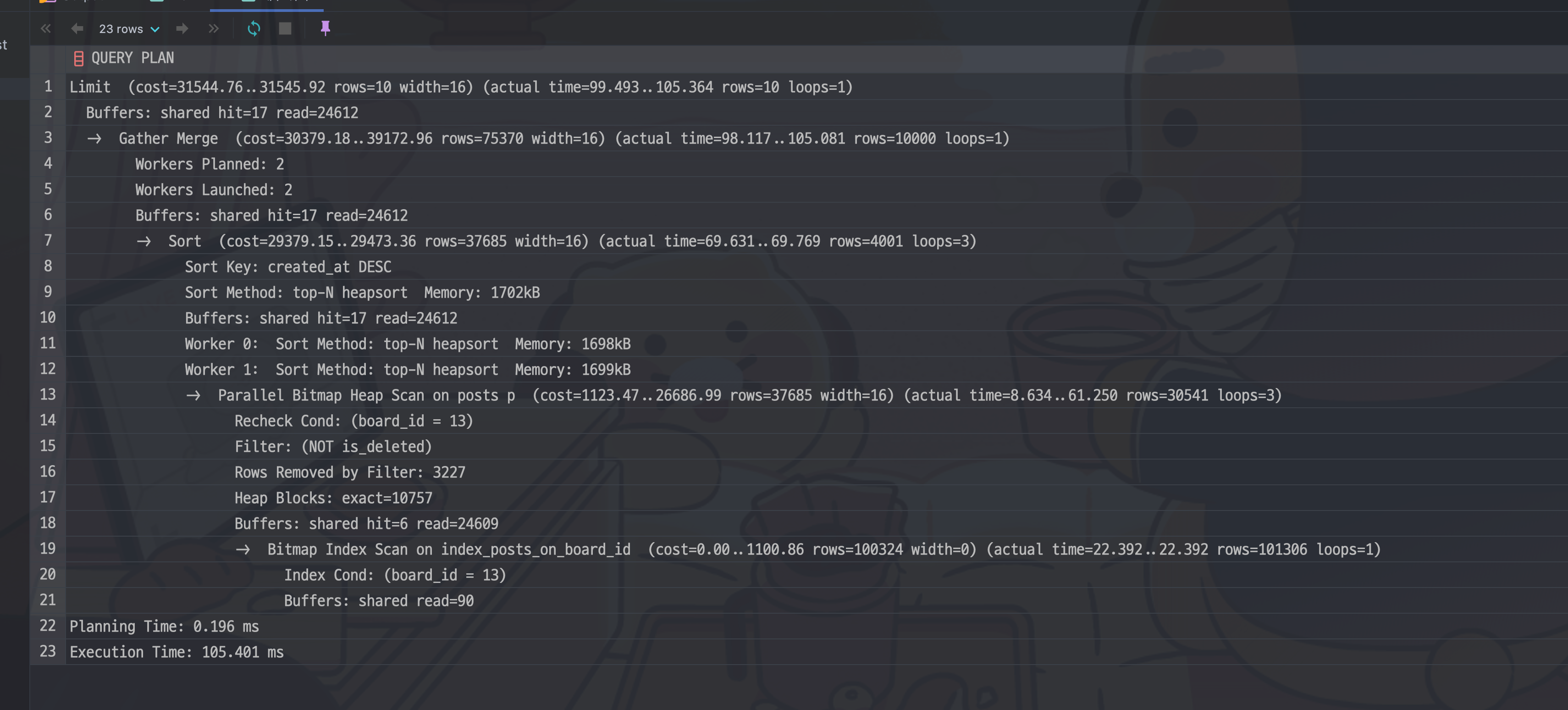
where 조건과 order by를 고려하면 다음과 같이 인덱스를 설계할 수 있을 거 같다.
CREATE INDEX 인덱스이름 ON "posts" ("board_id", "is_deleted", "created_at" desc);여기에 커버링 인덱스로 만들어주기 위해 id를 추가하자. PostgreSQL은 필터링에 사용되지는 않지만 커버링 인덱스를 위해 메모리는 올려놓고 싶을 때 INCLUDE를 이용할 수 있다. 참고
최종적으로 우리의 인덱스는 다음과 같이 된다.
CREATE INDEX "ix_posts_boardid_isdeleted_createdatdesc"
ON "posts" ("board_id", "is_deleted", "created_at" desc) INCLUDE ("id");이 인덱스가 생긴 이후 실행계획은 어떻게 바뀌었을까?
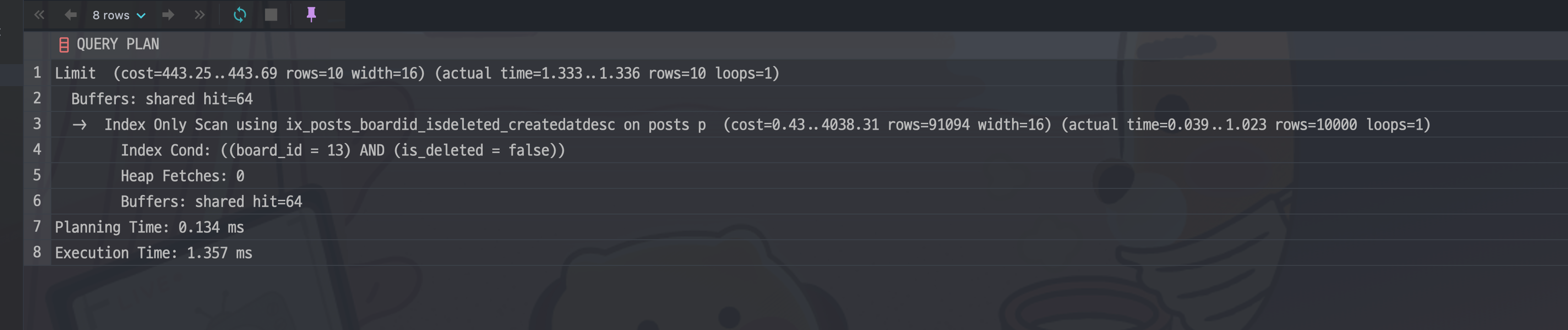
복잡다단했던 실행계획이 매우 단순하게 변했다. 실행 시간도 105ms에서 1.45ms으로 80배 가량 줄어들었다. (캐시에 한번 올린 이후) Heap Fetches: 0에서 볼 수 있듯 Index only scan으로 힙을 한 번도 접근하지 않는데다가 인덱스가 잘 정렬되어 있어 정확히 10,000개만 읽고도 정해진 개수를 채울 수 있기 때문이다.
비슷하지만 created_at을 ASC로 읽는 경우는 어떨까? 즉, 다음과 같은 쿼리에 대한 실행계획은 어떠할까?
SELECT "p"."id"
FROM "posts" p
WHERE "p"."is_deleted" = false
AND "p"."board_id" = 13
ORDER BY "p"."created_at" (ASC)
LIMIT 10 OFFSET 9990;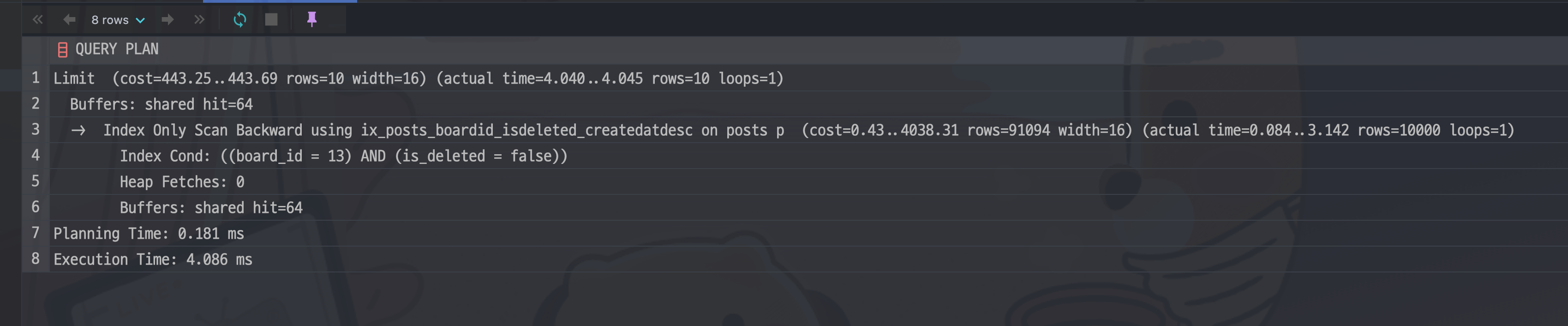
index only scan backward로 효율적이지만 위의 쿼리보다는 좀 더 비효율적으로 수행되는 걸 알 수 있다.
최종
이제 튜닝을 모두 마쳤다. 기존 쿼리의 실행계획을 다시 살펴보자.
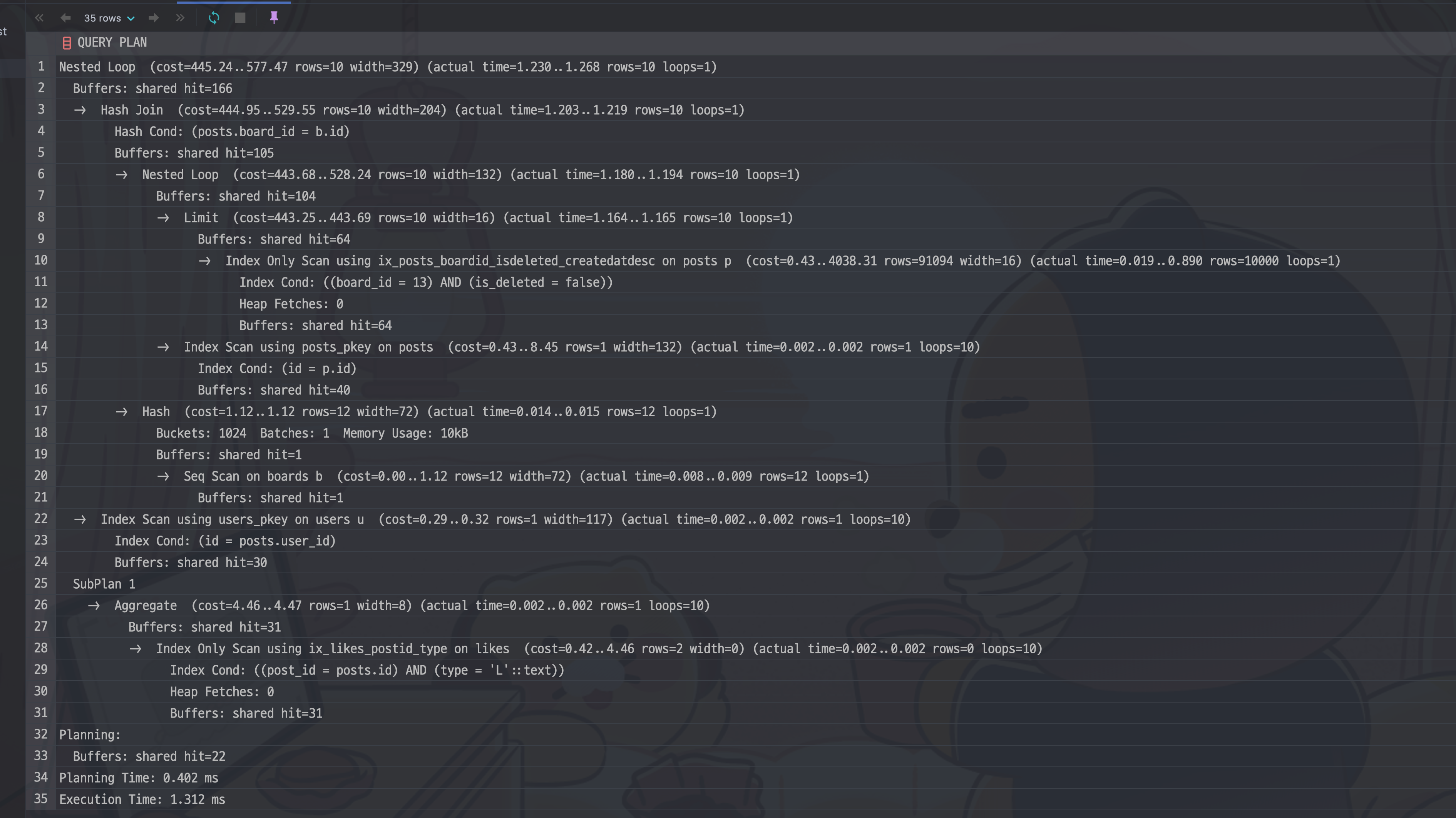
120ms정도가 걸리면 최초의 쿼리가 1.3ms정도 걸리는 쿼리로 변모했다.
이미 인덱스가 걸려있더라도 쿼리에 해당하는 더 좋은 인덱스를 설계한다면, 그리고 쿼리를 좀 더 튜닝한다면 성능 개선을 이끌어낼 수 있다.
