학원에서 학습한 내용을 개인정리한 글입니다.
수업
집계 함수
- GROUP BY 절에 사용하는 그룹함수
ROLLUP()
--ROLLUP 집계: 3가지
--1. 전체 매개변수 컬럼 DEPT_CODE, JOB_CODE 기준으로 집계
--SELECT AVG(SALARY) FROM EMPLOYEE GROUP BY DEPT_CODE, JOB_CODE;
--2. 첫번째 매개변수(DEPT_CODE)에 있는 컬럼으로 집계
--SELECT AVG(SALARY) FROM EMPLOYEE GROUP BY DEPT_CODE
--3. 전체집계(TOTAL)
--SELECT AVG(SALARY) FROM EMPLOYEE
SELECT NVL(DEPT_CODE, 'TOTAL'), AVG(SALARY)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY ROLLUP(DEPT_CODE);
CUBE()
--CUBE 집계
--4가지 집계
--1. 첫번째 매개변수(DEPT)기준으로 집계
--2. 두번째 매개변수(JOB)
--3. 전체 매개변수(DEPT, JOB)
--4. 전체기준 전체기준
SELECT NVL(DEPT_CODE, 'TOTAL'), AVG(SALARY)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY CUBE(DEPT_CODE);데이터 정렬하기
--데이터 정렬하기
--ORDER BY 절
--SELECT CALNAME,
--FROM TABLENAME
--[WHERE] CONDITION
--GROUP BY
--HAVING
--ORDER BY CALNAME/ INDEXNUM [ARRAY (ASC(DEFAULT)/DESC)]
ORDER BY () → DEFAULT(ASC)
--사원 명을 내림차순으로 정렬해서 출력하기
SELECT EMP_NAME
FROM EMPLOYEE
ORDER BY EMP_NAME;ORDER BY (DESC)
--급여가 높은 순으로 사원정보 출력
SELECT *
FROM EMPLOYEE
ORDER BY SALARY DESC;--정렬기준 여러개 설정
--DEPT_CODE 기준으로 내림차순 정렬하고 같은 값이면 SALARY가 높은 순으로 정렬
SELECT EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
ORDER BY DEPT_CODE, SALARY DESC;정렬 컬럼을 인덱스 번호로 불러오기
SELECT EMP_NAME, --1
DEPT_CODE,--2
SALARY--3
FROM EMPLOYEE
ORDER BY 2 DESC, 3;null 값 정렬
--desc null 맨 위
--asc null 맨 아래
--null 정렬 설정 -> Null first/last
SELECT BONUS
FROM EMPLOYEE
ORDER BY BONUS desc nulls last;가상 컬럼을 기준으로 정렬할수있을까?
- 가능! 별칭도 사용할 수 있다
- order by는 가장 마지막 처리라서 다 계산 가능
SELECT EMP_NAME,
SALARY,
SALARY * 12 AS YEAR_SAL
FROM EMPLOYEE
ORDER BY YEAR_SAL;GROUPING
- 어떤 값으로 집계를 했는지 알려주는 함수
- 매개변수 컬럼으로 집계한 결과면 0 아니면 1
SELECT
CASE
WHEN GROUPING(DEPT_CODE) = 1 AND GROUPING(JOB_CODE) = 1
THEN 'TOTAL'
WHEN GROUPING(DEPT_CODE) = 0 AND GROUPING(JOB_CODE) = 1
THEN 'DEPT-TOTAL'
WHEN GROUPING(DEPT_CODE) = 1 AND GROUPING(JOB_CODE) = 0
THEN 'DEPT-TOTAL'
WHEN GROUPING(DEPT_CODE) = 0 AND GROUPING(JOB_CODE) = 0
THEN 'DEPT-JAB-TOTAL'
END AS DIV,
DEPT_CODE,
JOB_CODE,
COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY CUBE(DEPT_CODE, JOB_CODE)
ORDER BY DIV;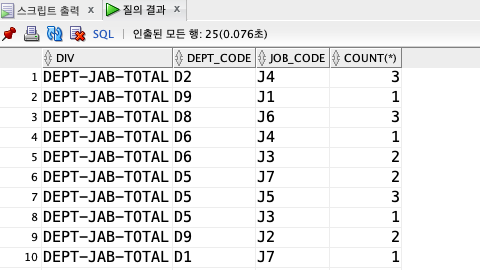
집합 연산자
- 여러개의 select문을 한개의 결과로 출력해주는 연산자
- 첫번째 select문의 컬럼수가 기준이됨
- 집합연산할 다른 select문은 집합연산할 다른 select문은 첫번째 select문의 컬럼수와 컬럼타입을 맞춰줘야 연산이 가능
--select calname, calname
--from tablename
--집합 연산자(union, unionAll, intersect, minus) **집합연산자
--select calname, calname
--from tablename
--집합 연산자(union, unionAll, intersect, minus)
--select calname, calname
--from tablename
--집합 연산자(union, unionAll, intersect, minus)
...union으로 큐브만들기
SELECT DEPT_CODE, JOB_CODE, COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY DEPT_CODE, JOB_CODE
UNION
SELECT DEPT_CODE, NULL, COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY DEPT_CODE
UNION
SELECT NULL, JOB_CODE, COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY JOB_CODE
UNION
SELECT NULL, NULL, COUNT(*)
FROM EMPLOYEE;
--INTERSECT -> 중복값을 가져오기
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
INTERSECT
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY >= 3000000;--MINUS -> 중복값 가져오기
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
MINUS
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY >= 3000000;join
- 두개 이상의 테이블을 특정컬럼을 기준으로 ROW를 연결하는것
inner join
- 특정 컬럼과 일치하는 row 들만 연결하는것 , 일치하는 값이 없는 Row는 생략
- 제거하고 출력. 디비에서 제거하는건 아님..
--select 컬럼명
--from 테이블명a
--join 테이블명b on 조건식 -> 조건식이 true인 row와 연결
--오라클 전용 표현 (비추천인데 알고있어야할 것 같아서 알려줌)
--from 테이블 명a, 테이블명b
--where 테이블 명a.컬럼 = 테이블명b.컬럼
--[where]
--[group by]
--[order by]--사원명, 급여, 부서명 조회
SELECT DEPT_TITLE, DEPT_ID
FROM DEPARTMENT;
--연결 기준되는 컬럼명이 동일할때 USING() 을 이용할 수 있다
SELECT JOB_CODE, EMP_NAME, JOB_NAME
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE);
--오라클 방식으로 조인하기
SELECT *
FROM EMPLOYEE, DEPARTMENT
WHERE DEPT_CODE = DEPT_ID;outer join
- 특정 컬럼과 일치하는 row가 없는 것도 연결해서 출력하는 것
--기준 테이블의 모든 row를 가져오고 다른 테이블과 일치하는 값이 있으면 일치하는 row를 연결하고 없으면 null값으로 처리
--left join: 왼쪽 기준 정렬
--right join: 오른쪽 기준. ㅓㅇ렬SELECT *
FROM EMPLOYEE LEFT JOIN DEPARTMENT ON DEPT_CODE = DEPT_ID;
SELECT *
FROM EMPLOYEE RIGHT JOIN DEPARTMENT ON DEPT_CODE = DEPT_ID;적재적소 Join
- 언제 inner join을 사용하고 -> 필수관계일 때
- 언제 outer join 사용하는지 -> 선택관계일때
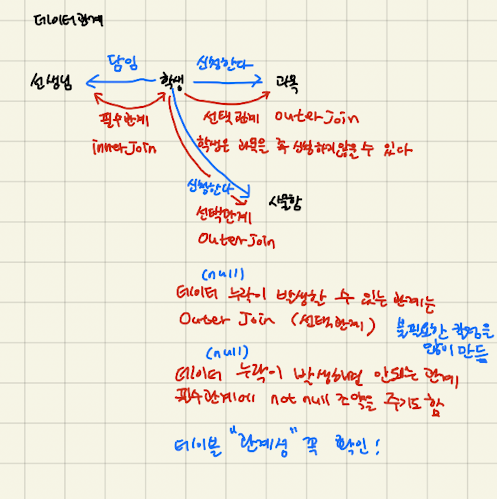
self join
--한개의 테이블을 이용해서 조인을 하는 것
--동일한 값을 갖는 컬럼이 두개가 있어야함--사원의 매니저 정보 조회하기
SELECT MANAGER_ID, EMP_ID
FROM EMPLOYEE E JOIN EMPLOYEE M ON E.MANAGER_ID = M.EMP_ID;QNA
Temi: Join에서 참조하는 테이블은 enum으로 보기엔 어려운지? 상속으로 봐야하는지? 자바에서의 예시와 디비에서의 예시 차이?
Teacher : 상속…아님 enum도 아님! has a 관계로 생각할 것? 사원은 부서가 될 수 없고 부서에 속해있다. 같은 관계를 생각할 것. 그리고 자바와 디비는 아예 다르다 각자의 존재로 생각하기
SUBQUERY
- Select문에 다른 Select문을 작성하는 것
- 주 Select(Main), 보조 Select(Sub)
- 서브쿼리는 반드시 괄호로 묶어서 표현
- 컬럼, from 절, where 절에 사용이 가능
- Insert,Update,Delete,Create 문 사용가능
단일행 서브쿼리
- 서브쿼리의 결과(Result set)이 1개열, 1개행인 경우
- 컬럼 작성부, where절에 비교 대상값으로 사용
--전체 사원의 평균급여보다 많은 급여를 받는 직원의 이름 급여 평균급여 조회하기
SELECT EMP_NAME, SALARY, TO_CHAR((SELECT AVG(SALARY) FROM EMPLOYEE), 'L999,999,999') AS SAL_AVG
FROM EMPLOYEE
WHERE SALARY > (SELECT AVG(SALARY) FROM EMPLOYEE);--부서가 총무부인 사원을 조회 join 말고 서브쿼리 사용
SELECT *
FROM EMPLOYEE
WHERE DEPT_CODE = (SELECT DEPT_ID FROM DEPARTMENT WHERE DEPT_TITLE = '총무부');
--직책이 과장인 사원 조회
SELECT *
FROM EMPLOYEE
WHERE JOB_CODE = (SELECT JOB_CODE FROM JOB WHERE JOB_NAME = '과장');다중행 서브쿼리
- 서브 쿼리의 결과가 1개 컬럼, 1개 이상의 행을 갖는것
--직책이 과장, 부장인 사원 조회
SELECT *
FROM EMPLOYEE
WHERE JOB_CODE IN (SELECT JOB_CODE FROM JOB WHERE JOB_NAME IN('과장', '부장'));다중행 비교연산자
- ANY()
- 행의 값을 or 묶어서 연산
--컬럼 <[=] any(): 다중행 서브쿼리의 값 중 최댓값보다 작으면 참
--컬럼 >[=] any(): 다중행 서브쿼리의 값 중 최솟값보다 크면 참
--D5, D6 사원들의 급여보다 많이 받는 사원
SELECT EMP_NAME, SALARY
FROM EMPLOYEE
WHERE SALARY > ANY(SELECT SALARY FROM EMPLOYEE WHERE DEPT_CODE IN('D5', 'D6'));- ALL()
- 행의 값을 and로 묶어서 연산
--컬럼 >(=) All(): 다중행 서브쿼리의 값 중 최대값보다 크면 참
--컬럼 <(=) All(): 다중행 서브쿼리의 값 중 최솟값보다 작으면 참
SELECT EMP_NAME, SALARY
FROM EMPLOYEE
WHERE SALARY > ALL(SELECT SALARY FROM EMPLOYEE WHERE DEPT_CODE IN('D5', 'D6'));
다중열 서브쿼리
- 서브쿼리의 결과가 1개행 다수컬럼인 경우
--퇴직한 여사원과 같은 부서 같은 직급인 사원 조회
SELECT DEPT_CODE, JOB_CODE FROM EMPLOYEE WHERE ENT_YN = 'Y';
--기술 지원부이고 급여가 200만원인 사원을 찾아 사원명 부서코드 급여로 조회하기
SELECT *
FROM EMPLOYEE
WHERE(DEPT_CODE, SALARY) = (SELECT DEPT_ID, 2000000 FROM DEPARTMENT WHERE DEPT_TITLE = '기술지원부');다중행 다중열 서브쿼리
- 여러행 여러컬럼을 가지는 서브쿼리
- 테이블을 생성할 때. 가상테이블(inline, view, stored view)를 만들때
SELECT E.*, DECODE(SUBSTR(EMP_NO, 8, 1), '1', 'M', '2', 'F') AS GENDER, SALARY*12 AS YEAR_SAL
FROM EMPLOYEE E;
SELECT *
FROM(
SELECT E.*,
DECODE(SUBSTR(EMP_NO, 8, 1), '1', 'M', '2', 'F') AS GENDER, SALARY*12 AS YEAR_SAL
FROM EMPLOYEE E
)
WHERE GENDER = 'F';상관서브쿼리(스칼라 서브쿼리)
- 서브쿼리를 작성할때 메인쿼리의 특정 값을 가져와 사용하는것
- e.g. 본인이 속한 부서의 사원수 조회
- e.g.상품에 작성된 댓글 수, 좋아요 수
--사원이 속한 부서의 사원수가 3명이상인 사원만 조회하기
SELECT E.DEPT_CODE, (SELECT COUNT(DEPT_CODE) FROM EMPLOYEE WHERE DEPT_CODE = E.DEPT_CODE) AS COUNT_3
FROM EMPLOYEE E
WHERE DEPT_CODE IS NOT NULL AND (SELECT COUNT(DEPT_CODE) FROM EMPLOYEE WHERE DEPT_CODE = E.DEPT_CODE) > 3;
--GROUP BY E.DEPT_CODE;exist 연산자
--서브쿼리의 row가 있으면(row 1개이상) true, 없으면(row 0개) False
--매니저인 사원 조회하기
SELECT *
FROM EMPLOYEE E
WHERE EXISTS (SELECT 1 FROM EMPLOYEE WHERE MANAGER_ID = E.EMP_ID);실습
--최고 급여 받는 사원 조회하기
SELECT *
FROM EMPLOYEE
WHERE SALARY = (SELECT MAX(SALARY) FROM EMPLOYEE);
--자신이 속한 직급의 평균 급여보다 급여를 많이 받는 사원의 사원명, 직책, 급여 조회
SELECT EMP_NAME, JOB_NAME , SALARY, (SELECT AVG(SALARY) FROM EMPLOYEE WHERE E.JOB_CODE = JOB_CODE) as avg
FROM EMPLOYEE E
JOIN JOB J ON E.JOB_CODE = J.JOB_CODE
WHERE SALARY > (SELECT AVG(SALARY) FROM EMPLOYEE WHERE E.JOB_CODE = JOB_CODE);
미리 준비
- 개인 프로젝트 수정!
- 이전 실습, 이번 실습 과제
느낀점
- 디비는 정말..신기하게 생긴것같다.
- 자바 다시 돌아가면 헷갈릴것같다..

250304~